wikisearch
1.0.0
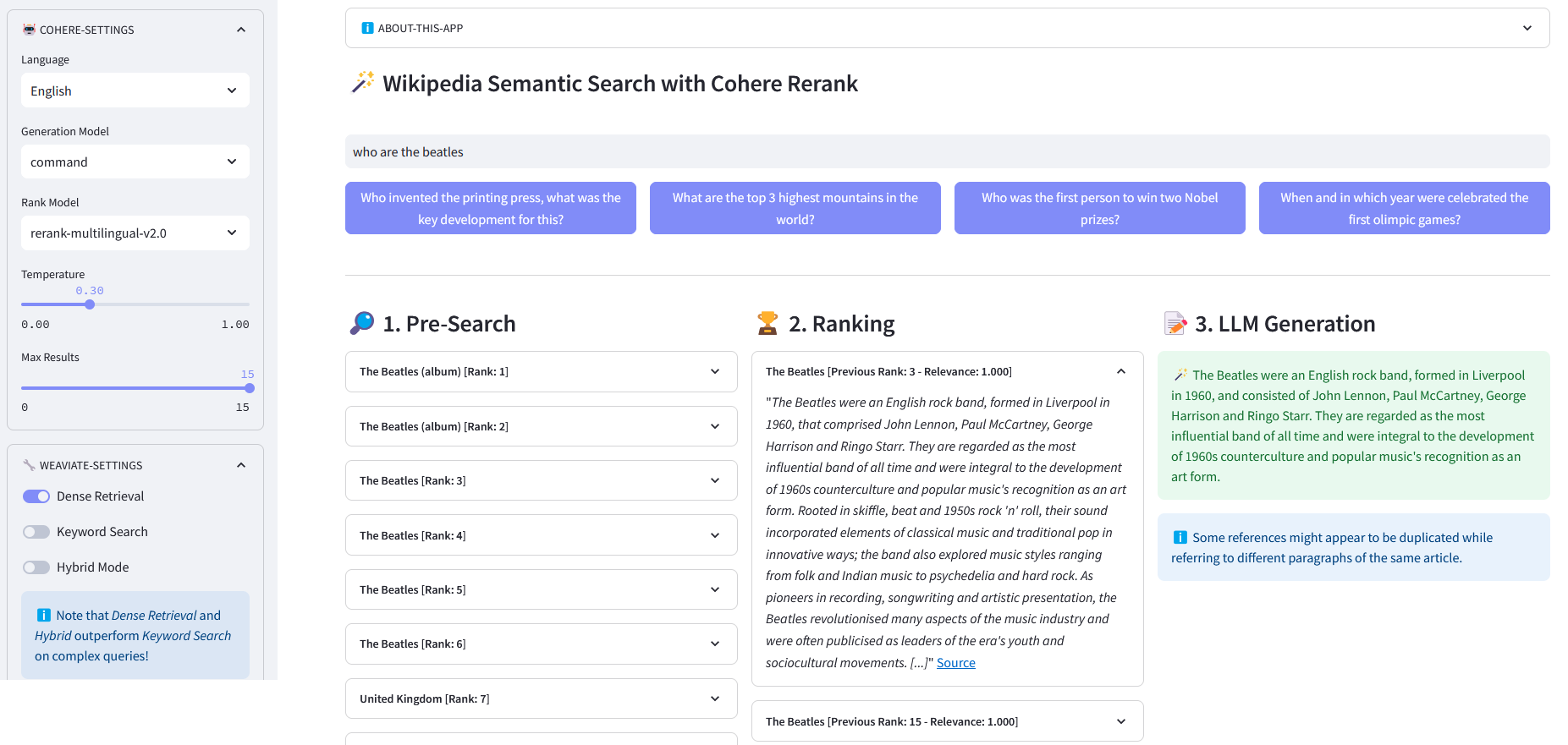
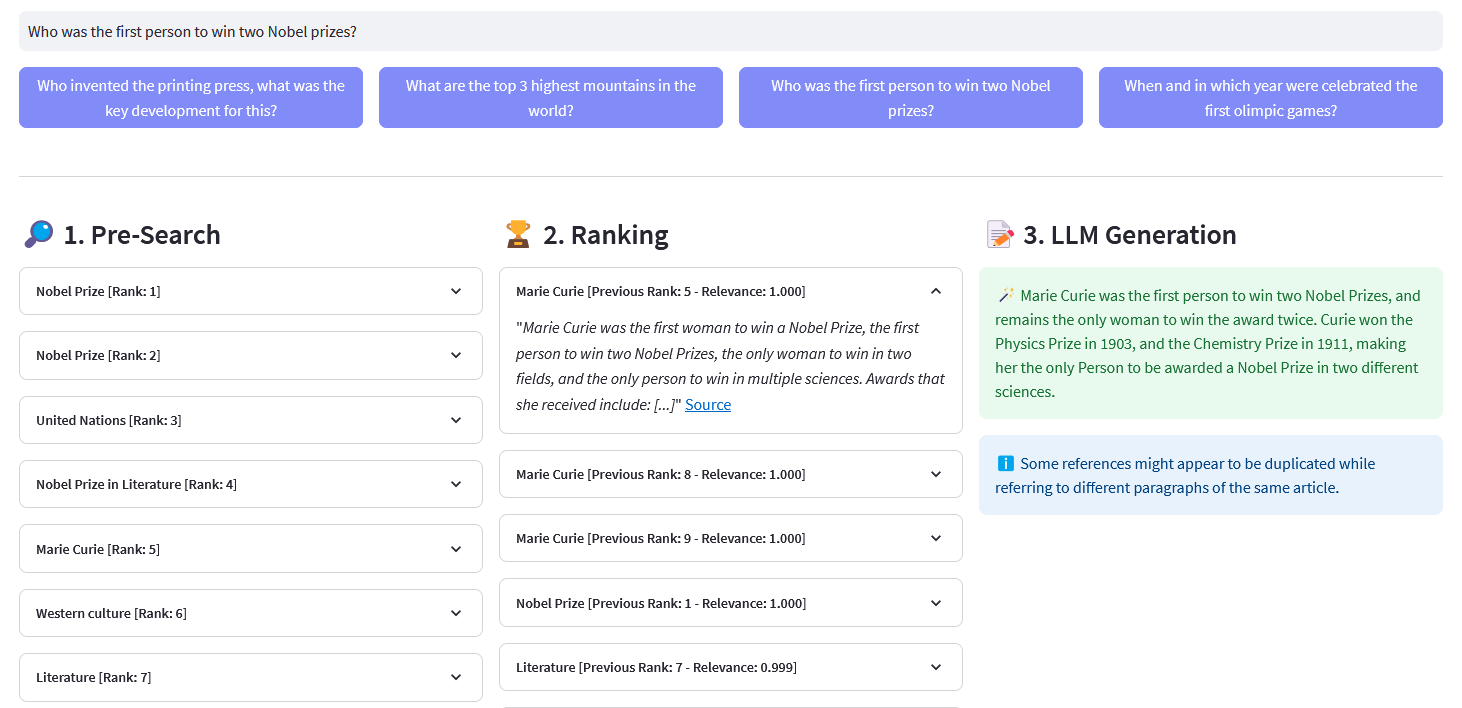
Weaviate によって埋め込みでベクトル化された 1,000 万以上の Wikipedia ドキュメントに対する多言語セマンティック検索のための Streamlit アプリ。この実装は、Cohere のブログ「Using LLMs for Search」とそれに対応するノートブックに基づいています。これにより、Wikipedia データセットをクエリするためのキーワード検索、高密度検索、およびハイブリッド検索のパフォーマンスを比較できます。さらに、Cohere Rerank を使用して結果の精度を向上させ、Cohere Generate を使用してランク付けされた結果に基づいて応答を提供することも示しています。
セマンティック検索とは、キーワードの一致のみに焦点を当てるのではなく、結果を生成するときに検索フレーズの意図と文脈上の意味を考慮する検索アルゴリズムを指します。クエリの背後にあるセマンティクスまたは意味を理解することで、より正確で関連性の高い結果が提供されます。
エンベディングは、単語、文章、ドキュメント、画像、音声などのデータを表す浮動小数点数のベクトル (リスト) です。前記数値表現は、データのコンテキスト、階層、および類似性を捕捉する。これらは、分類、クラスタリング、外れ値検出、セマンティック検索などの下流タスクに使用できます。
Weaviate などのベクター データベースは、埋め込み用のストレージとクエリ機能を最適化する目的で構築されています。実際には、ベクトル データベースは、近似最近傍 (ANN) 検索にすべて参加するさまざまなアルゴリズムの組み合わせを使用します。これらのアルゴリズムは、ハッシュ、量子化、またはグラフベースの検索を通じて検索を最適化します。
事前検索:キーワード一致、高密度検索、またはハイブリッド検索を使用した Wikipedia 埋め込みでの事前検索:
キーワード マッチング: プロパティに検索語を含むオブジェクトを検索します。結果は BM25F 関数に従ってスコア付けされます。
@retry(wait=wait_random_exponential(min=1, max=5), stop=stop_after_attempt(5))def with_bm25(self, query, lang='en', top_n=10) -> list:""" キーワードを実行しますWeaviate に保存された埋め込みを使用した Wikipedia 記事の検索 (スパース検索) パラメータ: - query (str): 検索クエリ。 (str、オプション): 記事の言語。デフォルトは「en」です。 - top_n (int、オプション): 返される上位の結果の数。デフォルトは 10 です。 戻り値: - list: BM25F に基づく上位の記事のリスト。 """logging.info("with_bm25()")where_filter = {"path": ["lang"],"operator": "Equal","valueString": lang}response = (self.weaviate.query.get("記事", self.WIKIPEDIA_PROPERTIES)
.with_bm25(クエリ=クエリ)
.with_where(where_filter)
.with_limit(top_n)
。する()
)return レスポンス["データ"]["取得"]["記事"]高密度検索: 生の (ベクトル化されていない) テキストに最も類似したオブジェクトを検索します。
@retry(wait=wait_random_exponential(min=1, max=5), stop=stop_after_attempt(5))def with_neartext(self, query, lang='en', top_n=10) -> list:""" セマンティックを実行しますWeaviate に保存された埋め込みを使用した Wikipedia 記事の検索 (高密度検索) パラメータ: - クエリ (str): 検索クエリ。 (str、オプション): 記事の言語。デフォルトは「en」です。 - top_n (int、オプション): 返される上位の結果の数。デフォルトは 10 です。 戻り値: - list: セマンティックに基づく上位の記事のリスト。類似性。"""logging.info("with_neartext()")nearText = {"concepts": [クエリ]
}where_filter = {"path": ["lang"],"operator": "Equal","valueString": lang}response = (self.weaviate.query.get("Articles", self.WIKIPEDIA_PROPERTIES)
.with_near_text(nearText)
.with_where(where_filter)
.with_limit(top_n)
。する()
)return レスポンス['データ']['取得']['記事']ハイブリッド検索: キーワード (bm25) 検索とベクトル検索の結果の重み付けされた組み合わせに基づいて結果を生成します。
@retry(wait=wait_random_exponential(min=1, max=5), stop=stop_after_attempt(5))def with_hybrid(self, query, lang='en', top_n=10) -> list:""" ハイブリッドを実行しますWeaviate に保存された埋め込みを使用して Wikipedia 記事を検索します。 パラメータ: - query (str): 検索クエリ。 - lang (str、オプション): 言語。デフォルトは「en」です。 - top_n (int、オプション): 返される上位の結果の数。 戻り値: - list: ハイブリッド スコアリングに基づく上位の記事のリスト。 with_hybrid()")where_filter = {"path": ["lang"],"operator": "Equal","valueString": lang}response = (self.weaviate.query.get("記事", self.WIKIPEDIA_PROPERTIES)
.with_hybrid(クエリ=クエリ)
.with_where(where_filter)
.with_limit(top_n)
。する()
)return レスポンス["データ"]["取得"]["記事"]ReRank : Cohere Rerankは、ユーザーのクエリを指定して各事前検索結果に関連性スコアを割り当てることにより、事前検索を再編成します。埋め込みベースのセマンティック検索と比較して、特に複雑なドメイン固有のクエリの場合に、より優れた検索結果が得られます。
@retry(wait=wait_random_exponential(min=1, max=5), stop=stop_after_attempt(5))def rerank(self,クエリ,ドキュメント,top_n=10,model='rerank-english-v2.0') -> dict:""" Cohere の再ランキング API を使用して、応答のリストを再ランク付けします。 パラメータ: - クエリ (str): 検索クエリ。 - ドキュメント (リスト): のリスト再ランク付けされるドキュメント - top_n (int、オプション): 返される上位再ランク付け結果の数。 - モデル: 再ランク付けに使用されるモデル。 戻り値: - dict: Cohere の API から再ランク付けされたドキュメント。 """return self.cohere.rerank(query=query,Documents=documents,top_n=top_n,モデル=モデル)
出典: コヒア
回答生成: Cohere Generate は、ランク付けされた結果に基づいて回答を作成します。
@retry(wait=wait_random_exponential(min=1, max=5), stop=stop_after_attempt(5))def with_llm(self, context, query, pressure=0.2, model="command", lang="english") -> list:prompt = f""" 以下に提供される情報を使用して、最後にある質問に答えてください。 / 文脈から抽出されたいくつかの興味深い事実や関連する事実を含めてください。 / 回答を次の言語で生成してください。クエリの言語を特定できない場合は、{lang} を使用します。/ 質問に対する答えが提供された情報に含まれていない場合は、「答えはコンテキストにありません」を生成します。 --- コンテキスト情報: { context} --- 質問: {query} """return self.cohere.generate(prompt=prompt,num_generations=1,max_tokens=1000,degrees=温度,model=model,
)リポジトリのクローンを作成します。
[email protected]:dcarpintero/wikisearch.git
仮想環境を作成してアクティブ化します。
Windows: py -m venv .venv .venvscriptsactivate macOS/Linux python3 -m venv .venv source .venv/bin/activate
依存関係をインストールします。
pip install -r requirements.txt
Web アプリケーションの起動
streamlit run ./app.py
デモ Web アプリは Streamlit Cloud にデプロイされ、https://wikisearch.streamlit.app/ で入手できます。
Cohereの再ランク
ストリームリットクラウド
埋め込みアーカイブ: 多くの言語で埋め込まれた何百万ものウィキペディア記事
高密度検索と再ランキングによる検索に LLM を使用する
ベクトルデータベース
ウィービエイト ベクトル検索
Weaviate BM25 検索
Weaviate ハイブリッド検索


