EasyDetect
1.0.0

MLLM 向けの使いやすいマルチモーダル幻覚検出フレームワーク
謝辞 · ベンチマーク · デモ · 概要 · ModelZoo · インストール · クイックスタート · 引用
了承
概要
統合されたマルチモーダル幻覚
データセット: MHalluBench 統計
フレームワーク: UniHD イラストレーション
モデル動物園
インストール
⏩クイックスタート
引用
2024-05-17 論文「マルチモーダル大規模言語モデルのための統合幻覚検出」が ACL 2024 メインカンファレンスに採択されました。
2024-04-21 デモ内のすべての基本モデルを独自のトレーニング済みモデルに置き換え、推論時間を大幅に短縮しました。
2024-04-21 オープンソースの幻覚検出モデル HalDet-LLAVA をリリースします。これは、huggingface、modelscope、wisemodel でダウンロードできます。
2024-02-10 EasyDetect デモをリリースしました。
2024-02-05 新しいベンチマーク MHaluBench を使用した論文「マルチモーダル大規模言語モデルのための統合幻覚検出」をリリースしました。このトピックに関するコメントや議論を楽しみにしています:)
2023-10-20 EasyDetect プロジェクトが開始され、開発中です。
このプロジェクトの実装の一部は、FactTool、Woodpecker などの関連幻覚ツールキットから支援され、インスピレーションを受けました。このリポジトリは、 mPLUG-Owl、MiniGPT-4、LLaVA、GroundingDINO、MAERec のパブリック プロジェクトからも恩恵を受けています。私たちはオープンソースに関しても同じライセンスに従っており、コミュニティへの貢献に感謝しています。
EasyDetect は、研究実験で GPT-4V、Gemini、LlaVA などのマルチモーダル大規模言語モデル (MLLM) 用の使いやすい幻覚検出フレームワークとして提案される体系的なパッケージです。
統合された検出の前提条件は、MLLM 内の幻覚の主要なカテゴリを一貫して分類することです。私たちの論文では、次の幻覚分類法を統一的な観点から表面的に検証しています。


図 1:統合されたマルチモーダル幻覚検出は、物体、属性、シーンテキストなどのさまざまなレベルでモダリティに矛盾する幻覚と、画像からテキストおよびテキストから画像の両方で事実に矛盾する幻覚を特定して検出することを目的としています。世代。
モダリティ矛盾幻覚。 MLLM は、他のモダリティからの入力と競合する出力を生成することがあり、その結果、不正なオブジェクト、属性、シーン テキストなどの問題が発生します。上の図 (a) の例には、アスリートのユニフォームを不正確に説明する MLLM が含まれており、きめ細かいテキストと画像の位置合わせを実現する MLLM の能力が限られているために、属性レベルの矛盾が示されています。
事実に反する幻覚。 MLLM からの出力は、確立された事実知識と矛盾する可能性があります。画像からテキストへのモデルは、無関係な事実を組み込むことによって実際のコンテンツから逸脱した物語を生成する可能性がありますが、テキストから画像へのモデルは、テキスト プロンプトに含まれる事実の知識を反映していないビジュアルを生成する可能性があります。これらの矛盾は、MLLM が事実の一貫性を維持しようと奮闘していることを強調しており、この分野における重大な課題を表しています。
マルチモーダル幻覚の統合検出には、各画像とテキストのペアa={v, x}のチェックが必要です。ここで、 v 、MLLM に提供される視覚入力、または MLLM によって合成される視覚出力のいずれかを示します。同様に、 x 、 vまたはvを合成するためのテキスト ユーザー クエリに基づいて MLLM が生成したテキスト応答を示します。このタスク内では、各x複数のクレームが含まれる場合があり、次のように表されます。 aを評価して、それが「幻覚性」であるか「非幻覚性」であるかを判断し、提示された幻覚の定義に基づいて判断の根拠を提供することです。 LLM からのテキスト幻覚検出は、この設定のサブケースを示します。ここで、 v null です。
この研究の軌跡を前進させるために、私たちはメタ評価ベンチマーク MHaluBench を導入します。これは、画像からテキストへの生成およびテキストから画像への生成までのコンテンツを網羅し、マルチモーダル幻覚検出器の進歩を厳密に評価することを目的としています。 MHaluBench に関する統計の詳細を以下の図に示します。
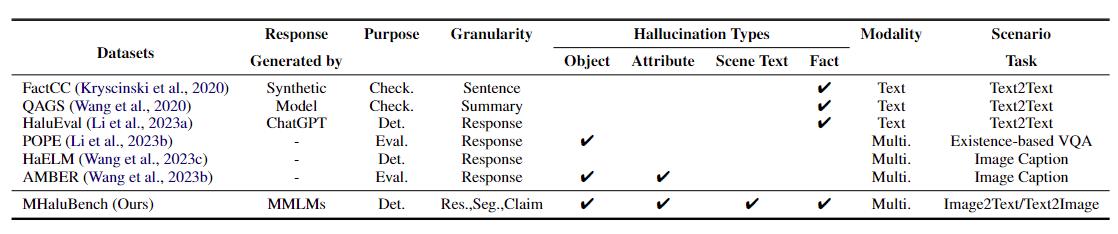
表 1:既存の事実確認または幻覚評価に関するベンチマークの比較。 "チェック。" 「Eval」は事実との整合性を検証することを示します。 「Det.」は、さまざまな LLM によって生成された幻覚を評価することを示し、その応答はテスト対象のさまざまな LLM に基づいています。幻覚を識別する検出器の能力の評価を具体化します。
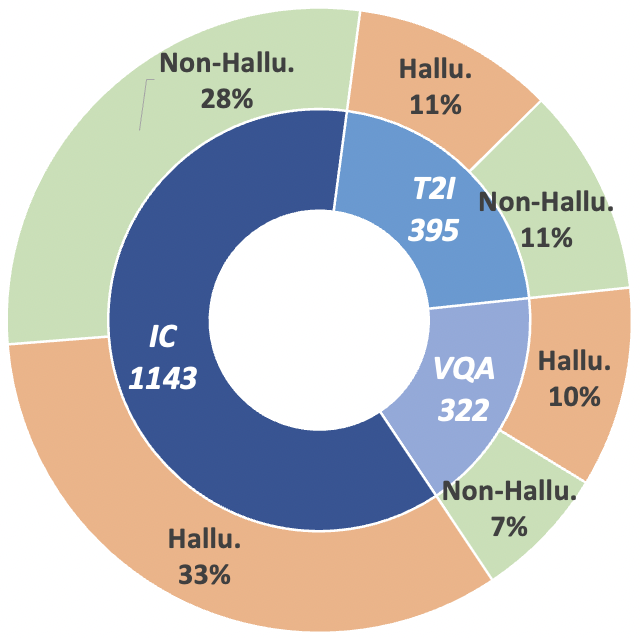
図 2: MHaluBench のクレームレベルのデータ統計。 「IC」は画像キャプションを、「T2I」はテキストから画像への合成をそれぞれ表します。
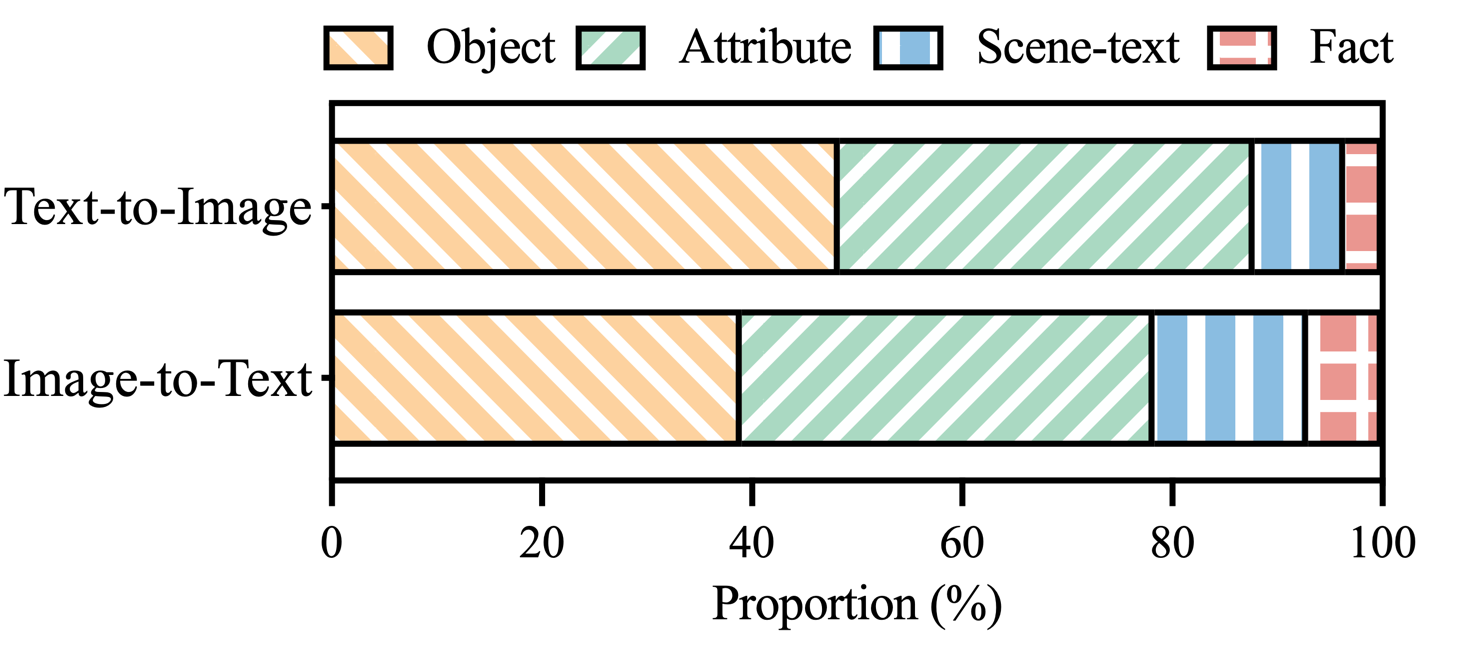
図 3: MHaluBench の幻覚ラベル付きクレーム内の幻覚カテゴリの分布。
幻覚検出における主要な課題に対処するために、画像からテキストへのタスクとテキストから画像へのタスクの両方についてマルチモーダル幻覚識別に体系的に取り組む統一フレームワークを図 4 に紹介します。私たちのフレームワークは、さまざまなツールのドメイン固有の強みを活用して、幻覚を確認するためのマルチモーダルな証拠を効率的に収集します。
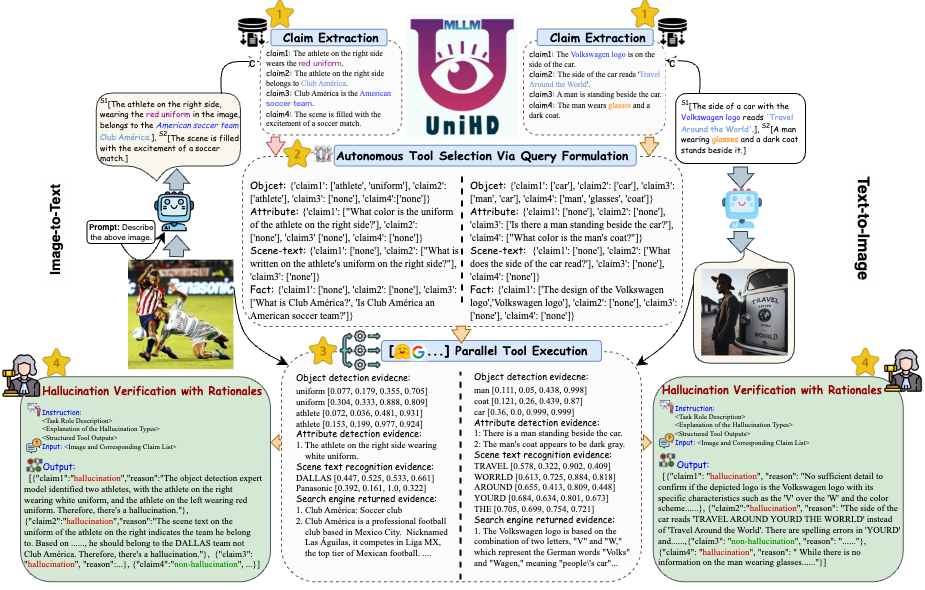
図 4:統合されたマルチモーダル幻覚検出のための UniHD の具体的な図。
HalDet-LLaVA の 2 つのバージョン、7b および 13b を、HuggingFace、ModelScope、および WiseModel の 3 つのプラットフォームでダウンロードできます。
| ハグ顔 | モデルスコープ | ワイズモデル |
|---|---|---|
| ハルデット-ラヴァ-7b | ハルデット-ラヴァ-7b | ハルデット-ラヴァ-7b |
| ハルデット-ラヴァ-13b | ハルデット-ラヴァ-13b | ハルデット-ラヴァ-13b |
クレームレベルは検証データセットに基づいて決定されます
セルフチェック(GPT-4V)とは、0または2件の場合にGPT-4Vを使用することを意味します
UniHD(GPT-4V/GPT-4o) は、GPT-4V/GPT-4o を 2 ショットとツール情報とともに使用することを意味します
HalDet (LLAVA) は、列車データセットでトレーニングされた LLAVA-v1.5 を使用することを意味します
| タスクの種類 | モデル | ACC | 平均精度 | 平均リコール | Mac.F1 |
| 画像からテキストへ | セルフチェック0ショット(GPV-4V) | 75.09 | 74.94 | 75.19 | 74.97 |
| セルフチェック2ショット(GPV-4V) | 79.25 | 79.02 | 79.16 | 79.08 | |
| ハルデット (LLAVA-7b) | 75.02 | 75.05 | 74.18 | 74.38 | |
| ハルデット (LLAVA-13b) | 78.16 | 78.18 | 77.48 | 77.69 | |
| UniHD(GPT-4V) | 81.91 | 81.81 | 81.52 | 81.63 | |
| UniHD(GPT-4o) | 86.08 | 85.89 | 86.07 | 85.96 | |
| テキストから画像へ | セルフチェック0ショット(GPV-4V) | 76.20 | 79.31 | 75.99 | 75.45 |
| セルフチェック2ショット(GPV-4V) | 80.76 | 81.16 | 80.69 | 80.67 | |
| ハルデット (LLAVA-7b) | 67.35 | 69.31 | 67.50 | 66.62 | |
| ハルデット (LLAVA-13b) | 74.74 | 76.68 | 74.88 | 74.34 | |
| UniHD(GPT-4V) | 85.82 | 85.83 | 85.83 | 85.82 | |
| UniHD(GPT-4o) | 89.29 | 89.28 | 89.28 | 89.28 |
HalDet-LLaVA と列車データセットの詳細については、Readme を参照してください。
ローカル開発用のインストール:
git clone https://github.com/zjunlp/EasyDetect.git cd EasyDetect pip install -r requirements.txt
ツールのインストール (GroundingDINO および MAERec):
# install GroundingDINO git clone https://github.com/IDEA-Research/GroundingDINO.git cp -r GroundingDINO pipeline/GroundingDINO cd pipeline/GroundingDINO/ pip install -e . cd .. # install MAERec git clone https://github.com/Mountchicken/Union14M.git cp -r Union14M/mmocr-dev-1.x pipeline/mmocr cd pipeline/mmocr/ pip install -U openmim mim install mmengine mim install mmcv mim install mmdet pip install timm pip install -r requirements/albu.txt pip install -r requirements.txt pip install -v -e . cd .. mkdir weights cd weights wget -q https://github.com/IDEA-Research/GroundingDINO/releases/download/v0.1.0-alpha/groundingdino_swint_ogc.pth wget https://download.openmmlab.com/mmocr/textdet/dbnetpp/dbnetpp_resnet50-oclip_fpnc_1200e_icdar2015/dbnetpp_resnet50-oclip_fpnc_1200e_icdar2015_20221101_124139-4ecb39ac.pth -O dbnetpp.pth wget https://github.com/Mountchicken/Union14M/releases/download/Checkpoint/maerec_b_union14m.pth -O maerec_b.pth cd ..
ユーザーが EasyDetect をすぐに使い始めることができるサンプル コードを提供します。
ユーザーは、yaml ファイルで EasyDetect のパラメータを簡単に設定することも、提供される設定ファイルのデフォルト パラメータをすぐに使用することもできます。構成ファイルのパスは EasyDetect/pipeline/config/config.yaml です。
openai: api_key: openai API キーを入力してください
base_url: 入力base_url、デフォルトはNoneです
温度: 0.2
max_tokens: 1024ツール:
detect:groundingdino_config: GroundingDINO_SwinT_OGC のパス。pymodel_path: groundingdino_swint_ogc.pthdevice のパス: cuda:0BOX_TRESHOLD: 0.35TEXT_TRESHOLD: 0.25AREA_THRESHOLD: 0.001
ocr:dbnetpp_config: dbnetpp_resnet50-oclip_fpnc_1200e_icdar2015.pydbnetpp_path: dbnetpp のパス.pthmaerec_config: maerec_b_union14m.pymaerec_path: maerec_b のパス.pthdevice: cuda:0content: word.numbercachefiles_path: 一時画像を保存するキャッシュファイルのパスBOX_TRESHOLD: 0.2TEXT_TRESHOLD: 0.25
google_serper:serper_api_key: serper API を入力します keysnippet_cnt: 10prompts:claim_generate: Pipeline/prompts/claim_generate.yaml
query_generate: パイプライン/プロンプト/query_generate.yaml
検証: パイプライン/プロンプト/verify.yamlコード例
from Pipeline.run_pipeline import *pipeline = Pipeline()text = "画像内のカフェの名前は "Hauptbahnhof""image_path = "./examples/058214af21a03013.jpg"type = "image-to-text"response,claim_list = Pipeline .run(テキスト=テキスト、イメージパス=イメージパス、 type=type)print(response)print(claim_list)
仕事で EasyDetect を使用する場合は、リポジトリを引用してください。
@article{chen23factchd、著者 = {Xiang Chen、Duanzheng Song、Honghao Gui、Chengxi Wang、Ningyu Zhang、Jiang Yong、Fei Huang、Chengfei Lv、Dan Zhang、Huajun Chen}、title = {FactCHD: 事実と矛盾する幻覚検出のベンチマーク}、ジャーナル = {CoRR}、ボリューム = {abs/2310.12086}、年 = {2023}、URL = {https://doi.org/10.48550/arXiv.2310.12086}、doi = {10.48550/ARXIV.2310.12086}、eprinttype = {arXiv}、eprint = {2310.12086 }、 biburl = {https://dblp.org/rec/journals/corr/abs-2310-12086.bib}、bibsource = {dblp コンピューター サイエンス参考文献、https://dblp.org}}@inproceedings{chen-etal- 2024-unified-hallucination,title = "マルチモーダル大規模言語モデルのための統合幻覚検出",author = "Chen、Xiang、ワン、チェンシーとシュエ、イーダとチャン、ニンユとヤン、シャオヤンとリー、チャンとシェン、ユエとリャン、レイとグー、ジンジエとチェン、ファジュン」、編集者 = 「クー、ルンウェイとマーティンズ、アンドレとSrikumar, Vivek",booktitle = "計算言語学協会第 62 回年次総会議事録 (巻) 1: ロングペーパー)"、月 = 8 月、年 = "2024"、住所 = "タイ、バンコク"、出版社 = "計算言語学協会"、url = "https://aclanthology.org/2024.acl-long .178"、ページ = "3235--3252"、
}バグ修正や問題解決、新たなご要望にお応えするための長期メンテナンスを行っております。何か問題がある場合は、私たちに問題を提出してください。


