大規模言語モデルコース
? Xでフォローしてください • ?顔を抱きしめる • ブログ • ?実践的な GNN
LLM コースは 3 つの部分に分かれています。
- ? LLM Fundamentals では、数学、Python、ニューラル ネットワークに関する重要な知識をカバーします。
- ?? LLM サイエンティストは、最新の技術を使用して可能な限り最高の LLM を構築することに重点を置いています。
- ? LLM エンジニアは、 LLM ベースのアプリケーションの作成と展開に重点を置きます。
このコースの対話型バージョンとして、質問に答え、パーソナライズされた方法で知識をテストする 2 つのLLM アシスタントを作成しました。
- ? HuggingChat Assistant : Mixtral-8x7B を使用した無料バージョン。
- ? ChatGPT アシスタント: プレミアム アカウントが必要です。
ノート
大規模言語モデルに関連するノートブックと記事のリスト。
ツール
| ノート | 説明 | ノート |
|---|
| ? LLM 自動評価 | RunPod を使用して LLM を自動的に評価する | |
| ?レイジーマーゲキット | MergeKit を使用すると、ワンクリックでモデルを簡単に結合できます。 | |
| ?レイジーアホロートル | Axolotl を使用してワンクリックでクラウド内のモデルを微調整します。 | |
| ⚡ オートクォント | ワンクリックで LLM を GGUF、GPTQ、EXL2、AWQ、および HQQ 形式で量子化します。 | |
| ?モデル家系図 | マージされたモデルの家系図を視覚化します。 | |
| ゼロスペース | 無料の ZeroGPU を使用して Gradio チャット インターフェイスを自動的に作成します。 | |
微調整
| ノート | 説明 | 記事 | ノート |
|---|
| QLoRA を使用して Llama 2 を微調整する | Google Colab で Llama 2 を監視付きで微調整するためのステップバイステップ ガイド。 | 記事 | |
| Axolotl を使用して CodeLlama を微調整する | 微調整のための最先端ツールのエンドツーエンドのガイド。 | 記事 | |
| QLoRA を使用して Mistral-7b を微調整する | TRL を使用した無料枠の Google Colab で、Mistral-7b の微調整を監督しました。 | | |
| DPO で Mistral-7b を微調整する | DPO を使用して、教師付き微調整モデルのパフォーマンスを向上させます。 | 記事 | |
| ORPO を使用して Llama 3 を微調整する | ORPO を使用すると、1 段階で低コストかつ迅速に微調整を行うことができます。 | 記事 | |
| Unsloth で Llama 3.1 を微調整する | Google Colab での非常に効率的な監視付き微調整。 | 記事 | |
量子化
| ノート | 説明 | 記事 | ノート |
|---|
| 量子化の概要 | 8 ビット量子化を使用した大規模言語モデルの最適化。 | 記事 | |
| GPTQを使用した4ビット量子化 | 独自のオープンソース LLM を量子化して、コンシューマ ハードウェアで実行します。 | 記事 | |
| GGUF と llama.cpp による量子化 | llama.cpp を使用して Llama 2 モデルを量子化し、GGUF バージョンを HF ハブにアップロードします。 | 記事 | |
| ExLlamaV2: LLM を実行する最速のライブラリ | EXL2 モデルを量子化して実行し、HF ハブにアップロードします。 | 記事 | |
他の
| ノート | 説明 | 記事 | ノート |
|---|
| 大規模言語モデルのデコード戦略 | ビームサーチから核サンプリングまでのテキスト生成のガイド | 記事 | |
| ナレッジグラフでChatGPTを改善する | ChatGPT の回答をナレッジ グラフで強化します。 | 記事 | |
| MergeKit を使用して LLM をマージする | 独自のモデルを簡単に作成でき、GPU は必要ありません。 | 記事 | |
| MergeKit を使用して MoE を作成する | 複数の専門家を単一の FrankenMoE に結合する | 記事 | |
| 削除による LLM の無検閲化 | 再トレーニングなしの微調整 | 記事 | |
? LLM の基礎
このセクションでは、数学、Python、ニューラル ネットワークに関する必須の知識を紹介します。ここから始める必要はないかもしれませんが、必要に応じて参照してください。
トグルセクション
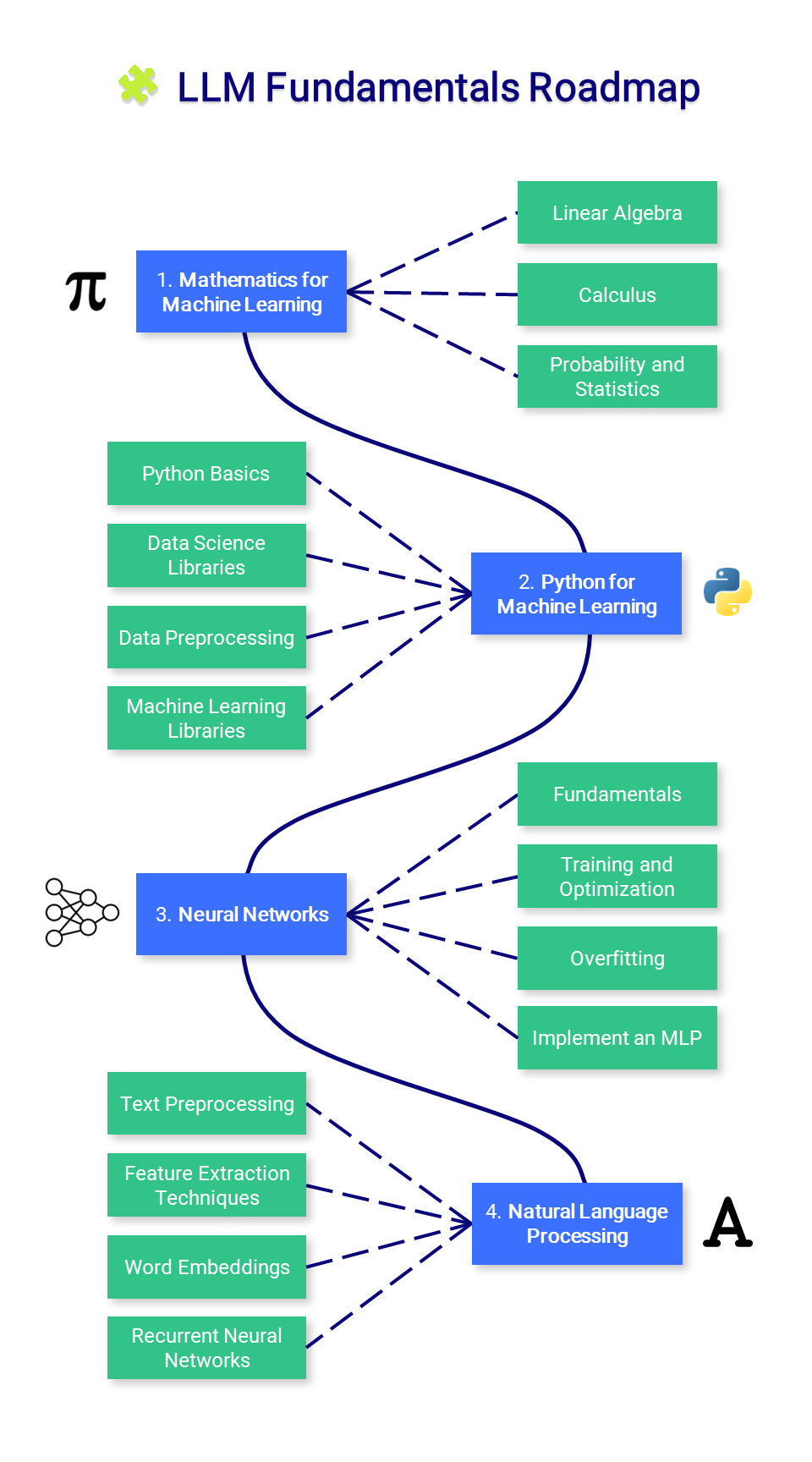
1. 機械学習のための数学
機械学習を習得する前に、これらのアルゴリズムを強化する基本的な数学的概念を理解することが重要です。
- 線形代数: これは、多くのアルゴリズム、特に深層学習で使用されるアルゴリズムを理解するために重要です。主要な概念には、ベクトル、行列、行列式、固有値と固有ベクトル、ベクトル空間、線形変換が含まれます。
- 微積分: 多くの機械学習アルゴリズムには連続関数の最適化が含まれており、これには微分、積分、極限、級数の理解が必要です。多変数微積分と勾配の概念も重要です。
- 確率と統計: これらは、モデルがデータからどのように学習して予測を行うかを理解するために重要です。主要な概念には、確率理論、確率変数、確率分布、期待値、分散、共分散、相関関係、仮説検定、信頼区間、最尤推定、ベイズ推論が含まれます。
リソース:
- 3Blue1Brown - 線形代数の本質: これらの概念に幾何学的直観を与える一連のビデオ。
- Josh Starmer による StatQuest - 統計の基礎: 多くの統計概念について簡単かつ明確に説明します。
- AP Statistics Intuition by Ms Aerin: あらゆる確率分布の背後にある直観を提供する Medium 記事のリスト。
- 没入型線形代数: 線形代数のもう 1 つの視覚的な解釈。
- Khan Academy - 線形代数: 非常に直感的な方法で概念を説明しているため、初心者に最適です。
- カーン アカデミー - 微積分: 微積分の基本をすべてカバーするインタラクティブなコースです。
- カーン アカデミー - 確率と統計: わかりやすい形式で資料を提供します。
2. 機械学習のための Python
Python は、読みやすさ、一貫性、データ サイエンス ライブラリの堅牢なエコシステムのおかげで、機械学習に特に適した強力で柔軟なプログラミング言語です。
- Python の基本: Python プログラミングには、基本的な構文、データ型、エラー処理、およびオブジェクト指向プログラミングをよく理解する必要があります。
- データ サイエンス ライブラリ: 数値演算のための NumPy、データ操作と分析のための Pandas、データ視覚化のための Matplotlib と Seaborn についての知識が含まれます。
- データ前処理: これには、特徴のスケーリングと正規化、欠損データの処理、外れ値の検出、カテゴリデータのエンコード、およびトレーニング、検証、およびテスト セットへのデータの分割が含まれます。
- 機械学習ライブラリ: Scikit-learn (教師ありおよび教師なし学習アルゴリズムの幅広い選択肢を提供するライブラリ) に習熟することが重要です。線形回帰、ロジスティック回帰、デシジョン ツリー、ランダム フォレスト、k 最近傍法 (K-NN)、K 平均法クラスタリングなどのアルゴリズムの実装方法を理解することが重要です。 PCA や t-SNE などの次元削減手法も、高次元データの視覚化に役立ちます。
リソース:
- Real Python: Python の初心者と上級者の両方の概念に関する記事とチュートリアルを含む包括的なリソースです。
- freeCodeCamp - Python を学ぶ: Python のすべての中心概念を完全に紹介する長いビデオ。
- Python データ サイエンス ハンドブック: パンダ、NumPy、Matplotlib、Seaborn を学習するための優れたリソースである無料のデジタル ブック。
- freeCodeCamp - 誰でも使える機械学習: 初心者向けのさまざまな機械学習アルゴリズムの実践的な入門書。
- Udacity - 機械学習の紹介: PCA およびその他のいくつかの機械学習の概念をカバーする無料コース。
3. ニューラルネットワーク
ニューラル ネットワークは、特にディープ ラーニングの領域において、多くの機械学習モデルの基本的な部分です。これらを効果的に活用するには、その設計と仕組みを包括的に理解することが不可欠です。
- 基礎: これには、層、重み、バイアス、活性化関数 (シグモイド、tanh、ReLU など) などのニューラル ネットワークの構造を理解することが含まれます。
- トレーニングと最適化: バックプロパゲーションと、平均二乗誤差 (MSE) やクロスエントロピーなどのさまざまな種類の損失関数について理解します。勾配降下法、確率的勾配降下法、RMSprop、Adam などのさまざまな最適化アルゴリズムを理解します。
- 過学習: 過学習 (モデルがトレーニング データでは良好に機能するが、未確認データではパフォーマンスが低下する) の概念を理解し、それを防ぐためのさまざまな正則化手法 (ドロップアウト、L1/L2 正則化、早期停止、データ拡張) を学びます。
- 多層パーセプトロン (MLP) を実装する: PyTorch を使用して、完全接続ネットワークとも呼ばれる MLP を構築します。
リソース:
- 3Blue1Brown - ニューラル ネットワークとは何ですか?: このビデオでは、ニューラル ネットワークとその内部動作について直感的に説明しています。
- freeCodeCamp - ディープ ラーニング クラッシュ コース: このビデオでは、ディープ ラーニングの最も重要な概念をすべて効率的に紹介します。
- Fast.ai - 実践的なディープ ラーニング: コーディング経験があり、ディープ ラーニングについて学びたい人向けに設計された無料コース。
- Patrick Loeber - PyTorch チュートリアル: 完全な初心者向けに PyTorch について学ぶためのビデオ シリーズ。
4. 自然言語処理 (NLP)
NLP は、人間の言語と機械の理解の間のギャップを埋める人工知能の魅力的な分野です。単純なテキスト処理から言語のニュアンスの理解まで、NLP は翻訳、感情分析、チャットボットなどの多くのアプリケーションで重要な役割を果たします。
- テキストの前処理: トークン化 (テキストを単語または文に分割する)、ステミング (単語を原形に戻す)、見出し語化 (ステミングに似ていますが、コンテキストを考慮します)、ストップワードの削除など、さまざまなテキストの前処理手順を学びます。
- 特徴抽出テクニック: テキスト データを機械学習アルゴリズムが理解できる形式に変換するテクニックを理解します。主な手法には、Bag-of-words (BoW)、Term Frequency-Inverse Document Frequency (TF-IDF)、および n-gram が含まれます。
- 単語の埋め込み: 単語の埋め込みは、類似した意味を持つ単語が類似した表現を持つことを可能にする単語表現の一種です。主なメソッドには、Word2Vec、GloVe、FastText などがあります。
- リカレント ニューラル ネットワーク (RNN) : シーケンス データを操作するように設計されたニューラル ネットワークの一種である RNN の動作を理解します。長期的な依存関係を学習できる 2 つの RNN バリアントである LSTM と GRU を調べてください。
リソース:
- RealPython - Python での spaCy を使用した NLP: Python での NLP タスク用の spaCy ライブラリに関する包括的なガイド。
- Kaggle - NLP ガイド: Python での NLP を実践的に説明するためのいくつかのノートブックとリソース。
- Jay Alammar - Word2Vec の図解: 有名な Word2Vec アーキテクチャを理解するための良い参考資料です。
- Jake Tae - ゼロからの PyTorch RNN: PyTorch での RNN、LSTM、および GRU モデルの実用的かつシンプルな実装。
- Colah のブログ - LSTM ネットワークについて: LSTM ネットワークに関するより理論的な記事。
?? LLM の科学者
コースのこのセクションでは、最新の技術を使用して可能な限り最高の LLM を構築する方法を学ぶことに重点を置きます。
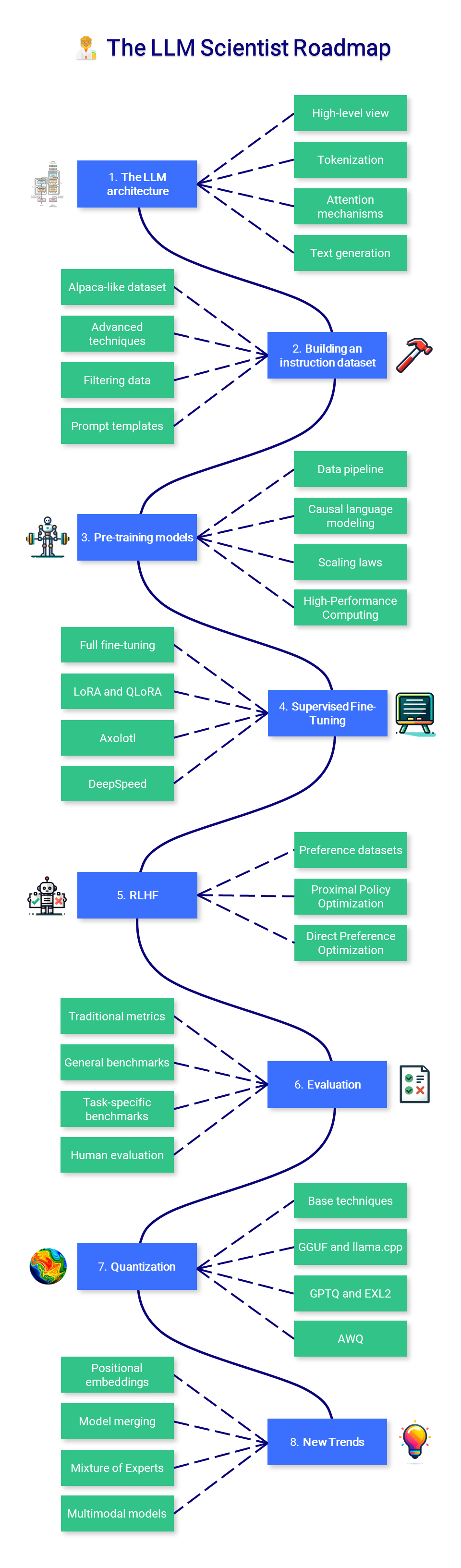
1. LLM アーキテクチャ
Transformer アーキテクチャに関する深い知識は必要ありませんが、その入力 (トークン) と出力 (ロジット) をよく理解することが重要です。バニラのアテンション メカニズムは、改良版が後で導入されるため、マスターする必要があるもう 1 つの重要なコンポーネントです。
- 概要: エンコーダー/デコーダーの Transformer アーキテクチャ、より具体的には、最新のすべての LLM で使用されているデコーダーのみの GPT アーキテクチャを再確認します。
- トークン化: 生のテキスト データをモデルが理解できる形式に変換する方法を理解します。これには、テキストをトークン (通常は単語またはサブワード) に分割することが含まれます。
- 注意メカニズム: 自己注意やスケーリングされたドット積注意など、注意メカニズムの背後にある理論を理解します。これにより、出力を生成するときにモデルが入力のさまざまな部分に焦点を当てることができます。
- テキスト生成: モデルが出力シーケンスを生成するさまざまな方法について学びます。一般的な戦略には、グリーディ デコーディング、ビーム サーチ、top-k サンプリング、および核サンプリングが含まれます。
参考文献:
- Jay Alammar による図解トランスフォーマー: トランスフォーマー モデルの視覚的かつ直観的な説明。
- Jay Alammar による図解 GPT-2: 前の記事よりもさらに重要なのは、Llama に非常に似ている GPT アーキテクチャに焦点を当てていることです。
- トランスフォーマーのビジュアル イントロ by 3Blue1Brown: トランスフォーマーのシンプルでわかりやすいビジュアル イントロ
- Brendan Bycroft による LLM の視覚化: LLM の内部で何が起こっているかを示す驚異的な 3D 視覚化。
- nanoGPT by Andrej Karpathy: GPT をゼロから再実装する 2 時間の YouTube ビデオ (プログラマー向け)。
- 注意?注意!リリアン・ウェン著: 注意の必要性をより正式な方法で紹介します。
- LLM のデコード戦略: コードを提供し、テキストを生成するためのさまざまなデコード戦略を視覚的に紹介します。
2. 命令データセットの構築
Wikipedia やその他の Web サイトから生データを見つけるのは簡単ですが、実際の説明と回答のペアを収集するのは困難です。従来の機械学習と同様、データセットの品質はモデルの品質に直接影響するため、微調整プロセスではデータセットが最も重要なコンポーネントになる可能性があります。
- アルパカのようなデータセット: OpenAI API (GPT) を使用して合成データを最初から生成します。シードとシステム プロンプトを指定して、多様なデータセットを作成できます。
- 高度なテクニック: Evol-Instruct を使用して既存のデータセットを改善する方法、Orca や phi-1 の論文のような高品質の合成データを生成する方法を学びます。
- データのフィルタリング: 正規表現を使用した従来の手法、重複に近いものを削除する、多数のトークンを含む回答に焦点を当てるなど。
- プロンプト テンプレート: 指示と回答をフォーマットする真の標準的な方法はありません。そのため、ChatML、Alpaca などのさまざまなチャット テンプレートについて知っておくことが重要です。
参考文献:
- Thomas Capelle による命令チューニングのためのデータセットの準備: Alpaca および Alpaca-GPT4 データセットの探索とそれらのフォーマット方法。
- Solano Todeschini による臨床指導データセットの生成: GPT-4 を使用して合成指導データセットを作成する方法に関するチュートリアル。
- Kshitiz Sahay によるニュース分類用の GPT 3.5: GPT 3.5 を使用して、ニュース分類用に Llama 2 を微調整するための命令データセットを作成します。
- LLM を微調整するためのデータセットの作成: データセットをフィルター処理して結果をアップロードするためのいくつかのテクニックを含むノートブック。
- Matthew Carrigan によるチャット テンプレート: プロンプト テンプレートに関する Hugging Face のページ
3. 事前トレーニングモデル
事前トレーニングは非常に時間と費用がかかるプロセスであるため、このコースでは焦点を当てません。事前トレーニング中に何が起こるかをある程度理解していることは良いことですが、実践的な経験は必要ありません。
- データ パイプライン: 事前トレーニングには、フィルタリング、トークン化、および事前定義された語彙との照合が必要な巨大なデータセット (たとえば、Llama 2 は 2 兆個のトークンでトレーニングされた) が必要です。
- 因果言語モデリング: 因果言語モデリングとマスク言語モデリングの違い、およびこの場合に使用される損失関数について学びます。効率的な事前トレーニングのために、Megatron-LM または gpt-neox について詳しく学習してください。
- スケーリング則: スケーリング則は、モデル サイズ、データセット サイズ、トレーニングに使用されるコンピューティング量に基づいて、予想されるモデルのパフォーマンスを記述します。
- ハイ パフォーマンス コンピューティング: ここでは範囲外ですが、独自の LLM (ハードウェア、分散ワークロードなど) を最初から作成する予定がある場合は、HPC に関するさらなる知識が基礎となります。
参考文献:
- Junhao Zhao による LLMDataHub: 事前トレーニング、微調整、および RLHF 用のデータセットの厳選されたリスト。
- Hugging Face による因果言語モデルを最初からトレーニングする: トランスフォーマー ライブラリを使用して GPT-2 モデルを最初から事前トレーニングします。
- Zhang らによる TinyLlama: このプロジェクトをチェックして、Llama モデルが最初からどのようにトレーニングされるかをよく理解してください。
- Hugging Face による因果言語モデリング: 因果言語モデリングとマスク言語モデリングの違い、および DistilGPT-2 モデルを迅速に微調整する方法について説明します。
- ノスタルジブリストによるチンチラのワイルドな意味: スケーリングの法則について議論し、一般に LLM にとってそれが何を意味するかを説明します。
- BLOOM by BigScience: BLOOM モデルがどのように構築されたかを説明する Notion ページ。エンジニアリング部分と発生した問題に関する多くの有益な情報が含まれています。
- OPT-175 メタによるログブック: 何がうまくいかなかったのか、何がうまくいったのかを示す調査ログ。非常に大規模な言語モデル (この場合は 175B パラメーター) を事前トレーニングする予定がある場合に役立ちます。
- LLM 360: トレーニングおよびデータ準備のコード、データ、メトリクス、モデルを備えたオープンソース LLM のフレームワーク。
4. 監視付き微調整
事前トレーニングされたモデルは次のトークンの予測タスクでのみトレーニングされるため、アシスタントとしては役に立ちません。 SFT を使用すると、指示に応答するようにそれらを調整できます。さらに、任意のデータ (プライベート、GPT-4 で認識されないデータなど) に基づいてモデルを微調整し、OpenAI のような API の料金を支払うことなくそれを使用することができます。
- 完全な微調整: 完全な微調整とは、モデル内のすべてのパラメーターをトレーニングすることを指します。これは効率的な手法ではありませんが、わずかに良い結果が得られます。
- LoRA : 低ランクのアダプターに基づくパラメーター効率化手法 (PEFT)。すべてのパラメーターをトレーニングするのではなく、これらのアダプターのみをトレーニングします。
- QLoRA : LoRA に基づく別の PEFT。これもモデルの重みを 4 ビットで量子化し、メモリ スパイクを管理するページ オプティマイザーを導入します。 Unsloth と組み合わせると、無料の Colab ノートブックで効率的に実行できます。
- Axolotl : 多くの最先端のオープンソース モデルで使用されている、ユーザーフレンドリーで強力な微調整ツールです。
- DeepSpeed : マルチ GPU およびマルチノード設定用の LLM の効率的な事前トレーニングと微調整 (Axolotl で実装)。
参考文献:
- Alpin による初心者向け LLM トレーニング ガイド: LLM を微調整する際に考慮すべき主な概念とパラメータの概要。
- Sebastian Raschka による LoRA の洞察: LoRA と最適なパラメーターの選択方法に関する実践的な洞察。
- 独自の Llama 2 モデルを微調整する: Hugging Face ライブラリを使用して Llama 2 モデルを微調整する方法に関する実践的なチュートリアル。
- 大規模言語モデルのパディング (Benjamin Marie 著): 因果 LLM のトレーニング例をパディングするためのベスト プラクティス
- LLM 微調整の初心者ガイド: Axolotl を使用して CodeLlama モデルを微調整する方法に関するチュートリアル。
5. 好みの調整
監視付き微調整の後、RLHF は、LLM の答えを人間の期待に合わせるために使用されるステップです。このアイデアは、人間の (または人工の) フィードバックから好みを学習し、それを使用してバイアスを軽減したり、モデルを検閲したり、モデルをより有用な方法で動作させたりすることができます。これは SFT よりも複雑で、多くの場合オプションとみなされます。
- 優先データセット: これらのデータセットには通常、何らかのランク付けを持つ複数の回答が含まれているため、指示データセットよりも生成が難しくなります。
- 近接ポリシーの最適化: このアルゴリズムは、特定のテキストが人間によって高くランク付けされているかどうかを予測する報酬モデルを活用します。この予測は、KL 発散に基づくペナルティを備えた SFT モデルの最適化に使用されます。
- 直接優先最適化: DPO は、プロセスを分類問題として再構成することでプロセスを簡素化します。報酬モデルの代わりに参照モデルを使用し (トレーニングは必要ありません)、必要なハイパーパラメーターは 1 つだけなので、より安定して効率的になります。
参考文献:
- Argilla の Distilabel: 独自のデータセットを作成するための優れたツール。特に優先データセット用に設計されていますが、SFT も実行できます。
- RLHF を使用した LLM のトレーニングの概要 (Ayush Thakur 著): LLM のバイアスを軽減し、パフォーマンスを向上させるために RLHF が望ましい理由を説明します。
- Hugging Face による RLHF の図: 報酬モデルのトレーニングと強化学習による微調整を含む RLHF の概要。
- 顔をハグすることによる LLM の好みの調整: 好みの調整を実行するための DPO、IPO、および KTO アルゴリズムの比較。
- LLM トレーニング: RLHF とその代替案 (Sebastian Rashcka 著): RLHF プロセスと RLAIF などの代替案の概要。
- DPO を使用した Mistral-7b の微調整: DPO を使用して Mistral-7b モデルを微調整し、NeuralHermes-2.5 を再現するチュートリアル。
6. 評価
LLM の評価はパイプラインの中で過小評価されている部分であり、時間がかかり、信頼性も中程度です。下流のタスクによって何を評価するかを指定する必要がありますが、「測定値が目標になると、それは適切な測定値ではなくなる」というグッドハートの法則を常に覚えておいてください。
- 従来のメトリクス: パープレキシティや BLEU スコアなどのメトリクスは、ほとんどのコンテキストで欠陥があるため、以前ほど人気がありません。これらを理解し、いつ適用できるかを理解することが依然として重要です。
- 一般的なベンチマーク: 言語モデル評価ハーネスに基づく、Open LLM Leaderboard は、汎用 LLM (ChatGPT など) の主要なベンチマークです。 BigBench、MT-Bench など、他にも人気のあるベンチマークがあります。
- タスク固有のベンチマーク: 要約、翻訳、質問応答などのタスクには、生物医学質問応答用の PubMedQA など、専用のベンチマーク、メトリクス、さらにはサブドメイン (医療、金融など) があります。
- 人間による評価: 最も信頼できる評価は、ユーザーによる承認率または人間による比較です。チャット トレースに加えてユーザー フィードバックを記録すると (例: LangSmith を使用)、改善の余地がある領域を特定するのに役立ちます。
参考文献:
- Hugging Face による固定長モデルの複雑さ: トランスフォーマー ライブラリを使用して実装するコードによる複雑さの概要。
- BLEU は自己責任で、Rachael Tatman 著: BLEU スコアとその多くの問題の概要と例。
- Chang らによる LLM の評価に関する調査: 何を評価するか、どこを評価するか、どのように評価するかについての包括的な論文。
- lmsys による Chatbot Arena Leaderboard: 人間による比較に基づく、汎用 LLM の Elo 評価。
7. 量子化
量子化は、より低い精度を使用してモデルの重み (およびアクティベーション) を変換するプロセスです。たとえば、16 ビットを使用して保存された重みは 4 ビット表現に変換できます。この手法は、LLM に関連する計算コストとメモリ コストを削減するためにますます重要になっています。
- 基本テクニック: さまざまなレベルの精度 (FP32、FP16、INT8 など) と、absmax およびゼロ点テクニックを使用して単純な量子化を実行する方法を学びます。
- GGUF と llama.cpp : llama.cpp と GGUF 形式は、もともと CPU 上で実行するように設計されており、コンシューマ グレードのハードウェアで LLM を実行するための最も人気のあるツールになりました。
- GPTQ および EXL2 : GPTQ、特に EXL2 形式は驚異的な速度を提供しますが、GPU でのみ実行できます。モデルの量子化にも時間がかかります。
- AWQ : この新しい形式は GPTQ よりも正確です (パープレキシティが低い) が、より多くの VRAM を使用するため、必ずしも高速であるとは限りません。
参考文献:
- 量子化の概要: 量子化、absmax およびゼロ点量子化、および LLM.int8() とコードの概要。
- llama.cpp を使用して Llama モデルを量子化する: llama.cpp と GGUF 形式を使用して Llama 2 モデルを量子化する方法に関するチュートリアル。
- GPTQ を使用した 4 ビット LLM 量子化: AutoGPTQ で GPTQ アルゴリズムを使用して LLM を量子化する方法に関するチュートリアル。
- ExLlamaV2: LLM を実行する最速のライブラリ: EXL2 形式を使用して Mistral モデルを量子化し、ExLlamaV2 ライブラリで実行する方法に関するガイド。
- FriendliAI によるアクティベーション対応重み量子化について: AWQ 手法の概要とその利点。
8. 新しいトレンド
- 位置埋め込み: LLM が位置をエンコードする方法、特に RoPE のような相対位置エンコード スキームを学びます。 YaRN (アテンション マトリックスに温度係数を乗算) または ALiBi (トークン距離に基づくアテンション ペナルティ) を実装して、コンテキストの長さを延長します。
- モデルのマージ: トレーニング済みモデルのマージは、微調整を行わずにパフォーマンスの高いモデルを作成する一般的な方法となっています。人気のあるマージキット ライブラリは、SLERP、DARE、TIES などの最も一般的なマージ メソッドを実装しています。
- 専門家の混合: Mixtral は、その優れたパフォーマンスのおかげで MoE アーキテクチャを再普及させました。並行して、より安価でパフォーマンスの高いオプションである Phixtral などのモデルを統合することにより、OSS コミュニティに一種の FrankenMoE が出現しました。
- マルチモーダル モデル: これらのモデル (CLIP、Stable Diffusion、LLaVA など) は、統合された埋め込みスペースで複数のタイプの入力 (テキスト、画像、オーディオなど) を処理し、テキストから画像への強力なアプリケーションを可能にします。
参考文献:
- EleutherAI による RoPE の拡張: さまざまな位置エンコーディング技術をまとめた記事。
- Rajat Chawla による YaRN の理解: YaRN の紹介。
- マージキットを使用して LLM をマージする: マージキットを使用したモデルのマージに関するチュートリアル。
- 顔を抱きしめて説明する専門家の混合: MoE とその仕組みに関する徹底的なガイド。
- Chip Huyen による大規模マルチモーダル モデル: マルチモーダル システムの概要とこの分野の最近の歴史。
? LLM エンジニア
コースのこのセクションでは、モデルの拡張とデプロイに重点を置き、運用環境で使用できる LLM を利用したアプリケーションを構築する方法を学習することに重点を置いています。
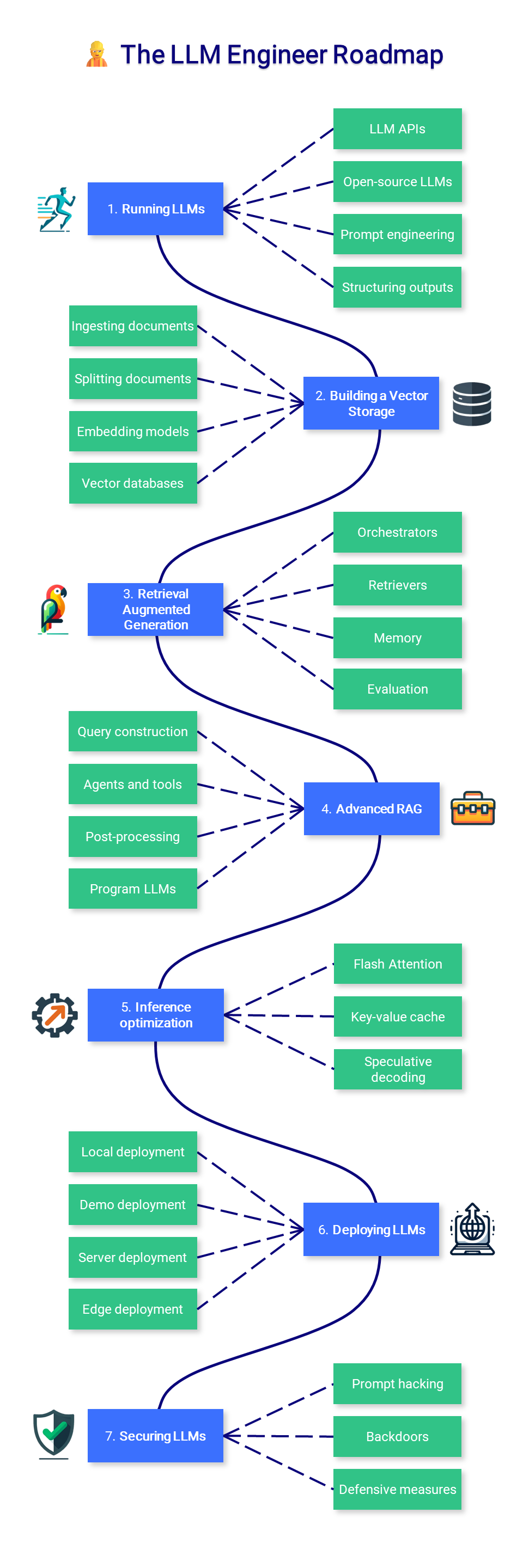
1. LLM の実行
LLM の実行は、ハードウェア要件が高いため困難になる場合があります。ユースケースに応じて、API (GPT-4 など) を介してモデルを単純に使用することも、ローカルで実行することもできます。いずれの場合でも、追加のプロンプトおよびガイダンス手法により、アプリケーションの出力を改善したり、制限したりできます。
- LLM API : API は、LLM をデプロイするための便利な方法です。このスペースは、プライベート LLM (OpenAI、Google、Anthropic、Cohere など) とオープンソース LLM (OpenRouter、Hugging Face、Togetter AI など) に分かれています。
- オープンソース LLM : Hugging Face Hub は、LLM を見つけるのに最適な場所です。これらの一部は Hugging Face Spaces で直接実行することも、LM Studio などのアプリでローカルにダウンロードして実行することも、llama.cpp または Ollama を使用して CLI 経由で実行することもできます。
- プロンプト エンジニアリング: 一般的な手法には、ゼロショット プロンプト、少数ショット プロンプト、思考の連鎖、および ReAct が含まれます。これらは大きなモデルでより適切に機能しますが、小さなモデルにも適応できます。
- 出力の構造化: 多くのタスクでは、厳密なテンプレートや JSON 形式などの構造化された出力が必要です。 LMQL、アウトライン、ガイダンスなどのライブラリを使用して、生成をガイドし、特定の構造を尊重できます。
参考文献:
- LM Studio を使用して LLM をローカルで実行する (Nisha Arya 著): LM Studio の使用方法に関する短いガイド。
- DAIR.AI によるプロンプト エンジニアリング ガイド: 例を含むプロンプト テクニックの網羅的なリスト
- アウトライン - クイックスタート: アウトラインによって有効になるガイド付き生成テクニックのリスト。
- LMQL - 概要: LMQL 言語の概要。
2. ベクターストレージの構築
ベクトル ストレージの作成は、検索拡張生成 (RAG) パイプラインを構築するための最初のステップです。ドキュメントはロードされ、分割され、関連するチャンクを使用してベクトル表現 (埋め込み) が生成され、推論中に将来使用するために保存されます。
- ドキュメントの取り込み: ドキュメント ローダーは、PDF、JSON、HTML、Markdown などの多くの形式を処理できる便利なラッパーです。また、一部のデータベースや API (GitHub、Reddit、Google Drive など) からデータを直接取得することもできます。
- ドキュメントの分割: テキスト スプリッターは、ドキュメントを意味的に意味のある小さなチャンクに分割します。 n文字以降のテキストを分割するのではなく、ヘッダーごとに分割するか、追加のメタデータを使用して再帰的に分割する方がよい場合がよくあります。
- 埋め込みモデル: 埋め込みモデルはテキストをベクトル表現に変換します。これにより、言語をより深く、より微妙に理解できるようになり、セマンティック検索を実行するために不可欠です。
- ベクトル データベース: ベクトル データベース (Chroma、Pinecone、Milvus、FAISS、Annoy など) は、埋め込みベクトルを保存するように設計されています。これらにより、ベクトルの類似性に基づいてクエリに「最も類似した」データを効率的に取得できます。
参考文献:
- LangChain - テキスト スプリッター: LangChain に実装されたさまざまなテキスト スプリッターのリスト。
- Sentence Transformers ライブラリ: 埋め込みモデル用の人気のあるライブラリ。
- MTEB Leaderboard: 埋め込みモデルのリーダーボード。
- Moez Ali によるトップ 5 ベクター データベース: 最高かつ最も人気のあるベクター データベースの比較。
3. 検索拡張生成
RAG を使用すると、LLM はデータベースからコンテキスト ドキュメントを取得して、回答の精度を向上させます。 RAG は、微調整を行わずにモデルの知識を増強する一般的な方法です。
- オーケストレーター: オーケストレーター (LangChain、LlamaIndex、FastRAG など) は、LLM をツール、データベース、メモリなどに接続し、その機能を強化するための一般的なフレームワークです。
- 取得者: ユーザーの指示は取得用に最適化されていません。さまざまな技術 (マルチクエリ リトリーバー、HyDE など) を適用して、それらを言い換え/拡張し、パフォーマンスを向上させることができます。
- メモリ: 以前の指示と回答を記憶するために、LLM や ChatGPT などのチャットボットはこの履歴をコンテキスト ウィンドウに追加します。このバッファは、要約 (たとえば、より小さい LLM の使用)、ベクトル ストア + RAG などによって改善できます。
- 評価: ドキュメントの検索 (コンテキストの精度と再現率) と生成段階 (忠実性と回答の関連性) の両方を評価する必要があります。 Ragas および DeepEval ツールを使用して簡素化できます。
参考文献:
- Llamaindex - 高レベルの概念: RAG パイプラインを構築する際に知っておくべき主な概念。
- 松ぼっくり - 取得拡張: 取得拡張プロセスの概要。
- LangChain - RAG に関する Q&A: 典型的な RAG パイプラインを構築するためのステップバイステップのチュートリアル。
- LangChain - メモリの種類: 関連する使用法を含むさまざまな種類のメモリのリスト。
- RAG パイプライン - メトリック: RAG パイプラインの評価に使用される主なメトリックの概要。
4. 高度な RAG
実際のアプリケーションでは、SQL データベースやグラフ データベースなどの複雑なパイプラインや、関連するツールや API の自動選択が必要になる場合があります。これらの高度な技術により、ベースライン ソリューションを改善し、追加機能を提供できます。
- クエリ構築: 従来のデータベースに保存されている構造化データには、SQL、Cypher、メタデータなどの特定のクエリ言語が必要です。クエリ構築を使用してデータにアクセスするために、ユーザーの指示をクエリに直接変換できます。
- エージェントとツール: エージェントは、回答を提供するために最も関連性の高いツールを自動的に選択することで LLM を強化します。これらのツールは、Google や Wikipedia を使用するような単純なものもあれば、Python インタープリターや Jira のようなより複雑なものもあります。
- 後処理: LLM に供給される入力を処理する最終ステップ。再ランキング、RAG 融合、および分類によって取得されたドキュメントの関連性と多様性が強化されます。
- プログラム LLM : DSPy のようなフレームワークを使用すると、プログラム的な方法で自動評価に基づいてプロンプトと重みを最適化できます。
参考文献:
- LangChain - クエリ構築: さまざまな種類のクエリ構築に関するブログ投稿。
- LangChain - SQL: Text-to-SQL とオプションの SQL エージェントを含む、LLM を使用して SQL データベースと対話する方法に関するチュートリアル。
- Pinecone - LLM エージェント: さまざまなタイプのエージェントとツールの紹介。
- LLM Powered Autonomous Agents by Lilian Weng: LLM エージェントに関する理論的な記事。
- LangChain - OpenAI の RAG: 後処理を含む、OpenAI によって採用されている RAG 戦略の概要。
- DSPy in 8 Steps: モジュール、シグネチャ、オプティマイザーを紹介する DSPy の汎用ガイド。
5. 推論の最適化
テキストの生成は、高価なハードウェアを必要とするコストのかかるプロセスです。量子化に加えて、スループットを最大化し、推論コストを削減するために、さまざまな手法が提案されています。
- フラッシュ アテンション: アテンション メカニズムを最適化して、その複雑さを二次関数から線形関数に変換し、トレーニングと推論の両方を高速化します。
- Key-Value キャッシュ: Key-Value キャッシュと、Multi-Query Attendance (MQA) および Grouped-Query Attendance (GQA) で導入された改善点について理解します。
- 投機的デコード: 小規模なモデルを使用してドラフトを作成し、その後、より大きなモデルでレビューしてテキスト生成を高速化します。
参考文献:
- 顔を抱きしめて GPU 推論: GPU で推論を最適化する方法を説明します。
- Databricks による LLM 推論: 運用環境で LLM 推論を最適化する方法のベスト プラクティス。
- 顔をハグすることによる速度とメモリのための LLM の最適化: 速度とメモリを最適化するための 3 つの主要な手法、つまり量子化、フラッシュ アテンション、およびアーキテクチャの革新について説明します。
- Assisted Generation by Hugging Face: HF バージョンの投機的デコーディング。これは、それを実装するコードとどのように連携するかについての興味深いブログ投稿です。
6. LLM の展開
LLM を大規模に展開するには、複数の GPU クラスターが必要となるエンジニアリング作業が必要です。他のシナリオでは、デモとローカル アプリははるかに低い複雑さで実現できます。
- ローカル展開: プライバシーは、オープンソース LLM がプライベート LLM に比べて持つ重要な利点です。ローカル LLM サーバー (LM Studio、Ollama、oababooga、kobold.cpp など) は、この利点を利用してローカル アプリを強化します。
- デモの展開: Gradio や Streamlit などのフレームワークは、アプリケーションのプロトタイプを作成し、デモを共有するのに役立ちます。また、たとえば、フェイススペースを抱きしめるなど、オンラインで簡単にホストすることもできます。
- サーバーの展開:LLMSを大規模に展開するには、クラウド(Skypilotも参照)またはONPREMインフラストラクチャが必要であり、TGI、VLLMなどの最適化されたテキスト生成フレームワークを活用します。
- エッジの展開:制約された環境では、MLC LLMやMNN-LLMなどの高性能フレームワークがWebブラウザー、Android、およびiOSにLLMを展開できます。
参考文献:
- Streamlit-基本的なLLMアプリを構築する:チュートリアルは、Streamlitを使用して基本的なChatGPTのようなアプリを作成します。
- HF LLM推論コンテナ:Amazon SagemakerにLLMを展開して、Faceの推論コンテナを使用します。
- Philipp SchmidによるPhilschmidブログ:Amazon Sagemakerを使用したLLM展開に関する高品質の記事のコレクション。
- ハメル・フサインによる最適化潜在:TGI、VLLM、Ctranslate2、およびMLCの比較スループットとレイテンシの観点から。
7。LLMSのセキュリティ
ソフトウェアに関連する従来のセキュリティの問題に加えて、LLMは、訓練と促された方法のために独自の弱点を持っています。
- 迅速なハッキング:迅速な噴射(モデルの回答をハイジャックするための追加の指示)、データ/プロンプトの漏れ(元のデータ/プロンプトの取得)、ジェイルブレイク(安全機能をバイパスするためのクラフトプロンプト)など、プロンプトエンジニアリングに関連するさまざまな手法。
- バックドア:攻撃ベクトルは、トレーニングデータ(誤った情報を使用して)を中毒するか、バックドアを作成することにより、トレーニングデータ自体をターゲットにします(推論中のモデルの動作を変更する秘密のトリガー)。
- 防御策:LLMアプリケーションを保護する最良の方法は、これらの脆弱性(たとえば、Garakのような赤いチーム化やチェックを使用する)に対してそれらをテストし、生産でそれらを観察することです(Langfuseのようなフレームワークを使用)。
参考文献:
- OWASP LLM Top 10 by Hego Wiki:LLMアプリケーションで見られる10の最も批評家の脆弱性のリスト。
- Joseph Thackerによる迅速な噴射プライマー:エンジニアの迅速な噴射専用のショートガイド。
- @LLM_SECによるLLMセキュリティ:LLMセキュリティに関連するリソースの広範なリスト。
- MicrosoftによるRed Teaming LLMS:LLMSでRed Teamingを実行する方法をガイドします。
謝辞
このロードマップは、ミラノ・ミラノビッチとロマノ・ロスの優れたDevOpsロードマップに触発されました。
特別な感謝:
- トーマス・セーレンは、私がロードマップを作成するように動機付けてくれました
- 最初のドラフトの入力とレビューのためのアンドレフレード
- LLMセキュリティに関するリソースを提供してくれたDino Dunn
- 「人間の評価」の部分を改善するためのマグダレナ・クーン
- 変圧器に関する3Blue1brownのビデオを提案するためのOdoverDose
免責事項:私はここにリストされている情報源とは関係ありません。


