LARS
v2.0-beta8:

LARS は、LLM (Large Language Model) をデバイス上でローカルに実行し、独自のドキュメントをアップロードして、アップロードされたコンテンツで LLM が応答する会話に参加できるようにするアプリケーションです。このグラウンディングは精度を向上させ、AI によって生成される不正確さまたは「幻覚」という一般的な問題を軽減するのに役立ちます。この技術は一般に「検索拡張生成」 (RAG) として知られています。
LLM をローカルで実行するためのデスクトップ アプリケーションは数多くありますが、LARS は究極のオープンソース RAG 中心の LLM アプリケーションを目指しています。この目的に向けて、LARS は RAG の概念をさらに進化させ、すべての回答に詳細な引用を追加し、特定の文書名、ページ番号、テキストの強調表示、質問に関連する画像を提供し、さらには文書内に文書リーダーを表示します。応答ウィンドウ。すべての応答にすべての引用が常に存在するわけではありませんが、RAG 応答ごとに少なくとも何らかの引用の組み合わせを提示するという考え方があり、一般にそのようになることがわかっています。
LARS 機能のデモビデオ
Python v3.10.x 以降: https://www.python.org/downloads/
パイトーチ:
GPU を使用して LLM を実行する予定の場合は、セットアップに応じて GPU ドライバーと CUDA/ROCm ツールキットをインストールしてから、以下の PyTorch セットアップに進んでください。
システムに適した PyTorch バージョンをダウンロードしてインストールします: https://pytorch.org/get-started/locally/
リポジトリのクローンを作成します。
git clone https://github.com/abgulati/LARS
cd LARS
GitHub Settings -> Developer settings (located on the bottom left!) -> Personal access tokensPython の依存関係をインストールします。
PIP 経由の Windows:
pip install -r .requirements.txt
PIP 経由の Linux:
pip3 install -r ./requirements.txt
Azure に関する注意: 一部の必要な Azure ライブラリは MacOS プラットフォームでは利用できません。したがって、次のライブラリを除く MacOS には別の要件ファイルが含まれています。
MacOS:
pip3 install -r ./requirements_mac.txt
目次に戻る
インストール後、以下を使用して LARS を実行します。
cd web_app
python app.py # Use 'python3' on Linux/macOS
ブラウザでhttp://localhost:5000/に移動します。
LARS に必要なすべてのアプリケーション ディレクトリがディスク上に作成されます。
HF-Waitress サーバーが自動的に起動し、初回実行時に LLM (Microsoft Phi-3-Mini-Instruct-44) をダウンロードします。インターネット接続速度によっては、時間がかかる場合があります。
最初のクエリで、埋め込みモデル (all-mpnet-base-v2) が HuggingFace Hub からダウンロードされます。これには少し時間がかかります。
目次に戻る
Windows の場合:
公式サイト「Tools for Visual Studio」から Microsoft Visual Studio Build Tools 2022 をダウンロードします。
注: 上記をインストールするときは、次のコンポーネントを必ず選択してください。
Desktop development with C++
# Then from the "Optional" category on the right, make sure to select the following:
MSVC C++ x64/x86 build tools
C++ CMake tools for Windows
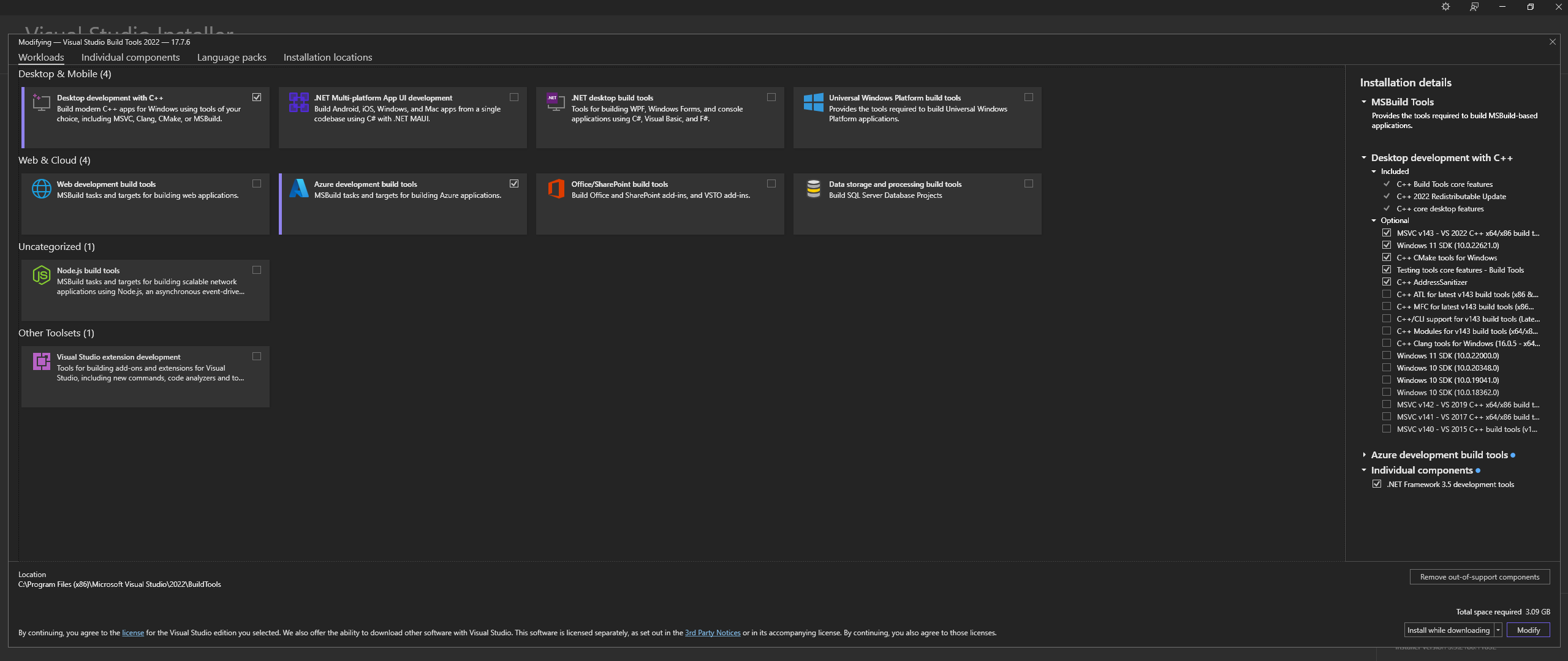
Desktop development with C++ 、 MSVC and C++ CMakeオプションが上記のとおり選択されていることを確認します。Linux (Ubuntu および Debian ベース) では、次のパッケージをインストールします。
sudo apt-get update
sudo apt-get install -y software-properties-common build-essential libffi-dev libssl-dev cmake
公式リポジトリからダウンロードします。
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
公式サイトから Windows に CMAKE をインストールする
C:Program FilesCMakebinCMAKE を使用して llama.cpp をビルドします。
注: コンパイルを高速化するには、-j 引数を追加して複数のジョブを並行して実行します。たとえば、 cmake --build build --config Release -j 8 8 つのジョブを並行して実行します。
CUDA を使用してビルドする:
cmake -B build -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES="52;61;70;75;80;86"
cmake --build build --config Release
cmake -B build
cmake --build build --config Release
CMake -B buildを実行しようとしたときに問題が発生した場合は、以下の広範な CMake インストールのトラブルシューティング手順を確認してください。
PATH に追加:
path_to_cloned_repollama.cppbuildbinRelease
端末経由でインストールを確認します。
llama-server
Nvidia GPU ドライバーをインストールする
Nvidia CUDA Toolkit のインストール - LARS は v12.2 および v12.4 で構築およびテストされています
端末経由でインストールを確認します。
nvcc -V
nvidia-smi
CMAKE-CUDA 修正 (非常に重要!):
次のディレクトリから 4 つのファイルすべてをコピーします。
C:Program FilesNVIDIA GPU Computing ToolkitCUDAv12.2extrasvisual_studio_integrationMSBuildExtensions
それらを次のディレクトリに貼り付けます。
C:Program Files (x86)Microsoft Visual Studio2022BuildToolsMSBuildMicrosoftVCv170BuildCustomizations
これはオプションですが、強く推奨される依存関係です。このセットアップが完了していない場合、PDF のみがサポートされます。
Windows:
公式サイトからダウンロード
次のいずれかの方法で PATH に追加します。
詳細システム設定 -> 環境変数 -> システム変数 -> パス変数の編集 -> 以下を追加します (インストール場所に応じて変更します)。
C:Program FilesLibreOfficeprogram
または PowerShell 経由:
Set PATH=%PATH%;C:Program FilesLibreOfficeprogram
Ubuntu および Debian ベースの Linux - 公式サイトからダウンロードするか、ターミナル経由でインストールします。
sudo apt-get update
sudo apt-get install -y libreoffice
Fedora およびその他の RPM ベースのディストリビューション - 公式サイトからダウンロードするか、ターミナル経由でインストールします。
sudo dnf update
sudo dnf install libreoffice
MacOS - 公式サイトからダウンロードするか、Homebrew 経由でインストールします。
brew install --cask libreoffice
インストールの確認:
Windows および MacOS の場合: LibreOffice アプリケーションを実行します。
Linux ではターミナル経由で次のようにします。
libreoffice --version
LARS は、pdf2image Python ライブラリを利用して、OCR に必要なドキュメントの各ページを画像に変換します。このライブラリは本質的に、変換プロセスを処理する Poppler ユーティリティのラッパーです。
Windows:
公式リポジトリからダウンロード
次のいずれかの方法で PATH に追加します。
詳細システム設定 -> 環境変数 -> システム変数 -> パス変数の編集 -> 以下を追加します (インストール場所に応じて変更します)。
path_to_installationpoppler_versionLibrarybin
または PowerShell 経由:
Set PATH=%PATH%;path_to_installationpoppler_versionLibrarybin
Linux:
sudo apt-get update
sudo apt-get install -y poppler-utils wget
これはオプションの依存関係です - Tesseract-OCR は LARS では積極的に使用されていませんが、それを使用するメソッドがソース コードに存在します。
Windows:
UB-Mannheim 経由で Windows 用 Tesseract-OCR をダウンロード
次のいずれかの方法で PATH に追加します。
詳細システム設定 -> 環境変数 -> システム変数 -> パス変数の編集 -> 以下を追加します (インストール場所に応じて変更します)。
C:Program FilesTesseract-OCR
または PowerShell 経由:
Set PATH=%PATH%;C:Program FilesTesseract-OCR
目次に戻る
LARS は Python v3.11.x で構築およびテストされています
Windows に Python v3.11.x をインストールします。
公式サイトからv3.11.9をダウンロード
インストール中に、「Python 3.11 を PATH に追加」にチェックを入れるか、後で次のいずれかの方法で手動で追加してください。
詳細システム設定 -> 環境変数 -> システム変数 -> パス変数の編集 -> 以下を追加します (インストール場所に応じて変更します)。
C:Usersuser_nameAppDataLocalProgramsPythonPython311
または PowerShell 経由:
Set PATH=%PATH%;C:Usersuser_nameAppDataLocalProgramsPythonPython311
Linux (Ubuntu および Debian ベース) に Python v3.11.x をインストールします。
sudo add-apt-repository ppa:deadsnakes/ppa -y
sudo apt-get update
sudo apt-get install -y python3.11 python3.11-venv python3.11-dev
sudo python3.11 -m ensurepip
端末経由でインストールを確認します。
python3 --version
pip installでエラーが発生した場合は、次のことを試してください。
バージョン番号を削除します。
==version.numberセグメントを削除します。次に例を示します。urllib3==2.0.4urllib3Python 仮想環境を作成して使用します。
他の Python プロジェクトとの競合を避けるために、仮想環境を使用することをお勧めします。
Windows:
Python 仮想環境 (venv) を作成します。
python -m venv larsenv
venv をアクティブ化し、その後使用します。
.larsenvScriptsactivate
完了したら、venv を非アクティブ化します。
deactivate
Linux および MacOS:
Python 仮想環境 (venv) を作成します。
python3 -m venv larsenv
venv をアクティブ化し、その後使用します。
source larsenv/bin/activate
完了したら、venv を非アクティブ化します。
deactivate
問題が解決しない場合は、LARS GitHub リポジトリで問題を開いてサポートを受けることを検討してください。
CMake nmake failedエラーが発生した場合: 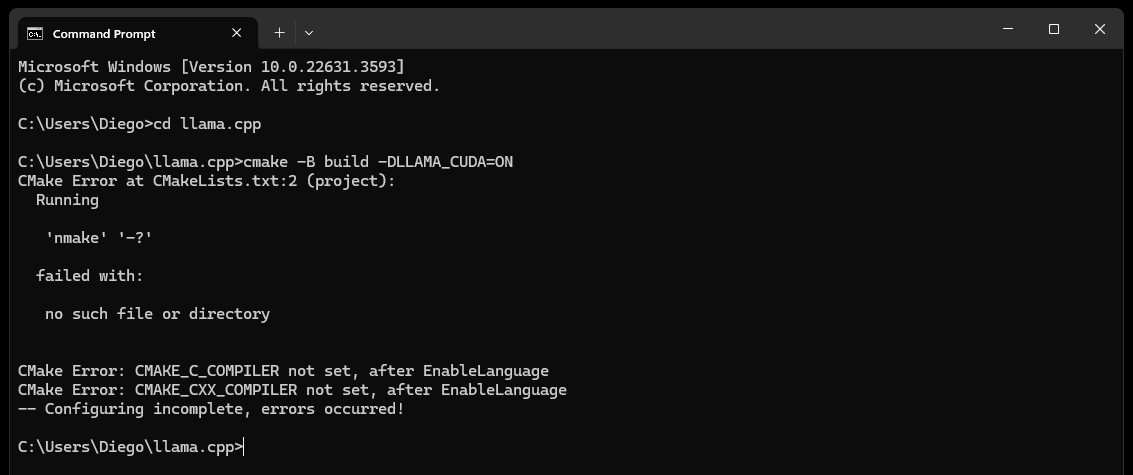
CMake が Microsoft Visual Studio ビルド ツールの一部である nmake ツールを見つけることができないため、これは通常、Microsoft Visual Studio ビルド ツールに問題があることを示しています。問題を解決するには、次の手順を試してください。
Visual Studio ビルド ツールがインストールされていることを確認します。
nmake などの Visual Studio ビルド ツールがインストールされていることを確認してください。これらのツールは、 Desktop development with C++ワークロード、およびMSVC and C++ CMakeオプションを選択することで、Visual Studio インストーラーを通じてインストールできます。
「依存関係」セクションのステップ 0、特にその中のスクリーンショットを確認してください。
環境変数を確認します。
C:Program Files (x86)Microsoft Visual Studio2019CommunityVCAuxiliaryBuild
C:Program Files (x86)Microsoft Visual Studio2019CommunityCommon7IDE
C:Program Files (x86)Microsoft Visual Studio2019CommunityCommon7Tools
開発者コマンド プロンプトを使用します。
「Visual Studio の開発者コマンド プロンプト」を開き、必要な環境変数を設定します。
このプロンプトは、Visual Studio の [スタート] メニューから見つけることができます。
CMake ジェネレーターを設定します。
cmake -G "NMake Makefiles" -B build -DLLAMA_CUDA=ON
問題が解決しない場合は、LARS GitHub リポジトリで問題を開いてサポートを受けることを検討してください。
最終的に (約 60 秒後)、エラーを示すアラートがページに表示されます。
Failed to start llama.cpp local-server
これは、初回実行が完了し、すべてのアプリ ディレクトリが作成されたが、 modelsディレクトリに LLM が存在しないため、モデル ディレクトリに移動できることを示します。
LLM (llama.cpp でサポートされている任意のファイル形式、できれば GGUF) を、デフォルトで次の場所にある新しく作成されたmodelsディレクトリに移動します。
C:/web_app_storage/models/app/storage/models/app/models LLM を上記の適切なmodelsディレクトリに配置したら、 http://localhost:5000/を更新します。
約 60 秒後に、 Failed to start llama.cpp local-serverというエラー アラートが再度表示されます。
これは、LLM を LARS Settingsメニューで選択する必要があるためです。
アラートを受け入れ、右上のSettings歯車アイコンをクリックします。
LLM Selectionタブで、適切なドロップダウンから LLM と適切なプロンプト テンプレート形式を選択します。
詳細設定を変更して、選択した LLM のGPUオプション、 Context-Length 、およびオプションでトークン生成制限 ( Maximum tokens to predict ) を正しく設定します。
Saveをクリックし、自動更新がトリガーされない場合は、ページを手動で更新します。
すべての手順が正しく実行された場合、初回セットアップは完了し、LARS を使用できるようになります。
LARS は、後で使用できるように LLM 設定も記憶します。
目次に戻る
サポートされているドキュメント形式:
「依存関係」セクションのステップ 4 で説明されているように、LibreOffice がインストールされ、PATH に追加されている場合、次の形式がサポートされます。
LibreOffice がセットアップされていない場合は、PDF のみがサポートされます
テキスト抽出のための OCR オプション:
LARS は、さまざまなドキュメントの種類と品質に対応して、ドキュメントからテキストを抽出するための 3 つの方法を提供します。
ローカル テキスト抽出: PyPDF2 を使用して、スキャンされていない PDF から効率的にテキストを抽出します。高精度が重要ではない場合、または完全にローカルな処理が必要な場合の迅速な処理に最適です。
Azure ComputerVision OCR - テキスト抽出の精度を向上させ、スキャンされたドキュメントをサポートします。標準的なドキュメント レイアウトを処理する場合に便利です。初回試用および少量使用に適した無料枠を提供し、1 分あたり 20 トランザクションで月あたり 5,000 トランザクションに制限されます。
Azure AI Document Intelligence OCR - 表などの複雑な構造を持つドキュメントに最適です。 LARS のカスタム パーサーは抽出プロセスを最適化します。
注:
Azure OCR オプションでは、ほとんどの場合 API コストが発生し、LARS にはバンドルされていません。
ComputerVision OCR の制限付き無料利用枠は、上記のリンクから利用できます。このサービスは全体的に安価ですが、速度が遅く、非標準のドキュメント レイアウト (A4 など) では機能しない可能性があります。
OCR オプションを選択するときは、ドキュメントの種類と精度のニーズを考慮してください。
LLM:
現在ローカル LLM のみがサポートされています
Settingsメニューには、パワーユーザーがLLM Selectionタブから LLM を構成および変更するための多くのオプションが用意されています。
llama.cpp を使用する場合の注意事項: 非常に重要: 実行している LLM に適切なプロンプト テンプレート形式を選択してください
次のプロンプト テンプレート形式用にトレーニングされた LLM は、現在、llama.cpp によってサポートされています。
Advanced Settingsでコア構成設定を調整します (LLM の再ロードとページの更新をトリガーします)。
設定を調整すると、いつでも応答動作を変更できます。
埋め込みモデルとベクトル データベース:
LARS では 4 つの埋め込みモデルが提供されています。
Azure-OpenAI 埋め込みを除いて、他のすべてのモデルは完全にローカルで無料で実行されます。初回実行時に、これらのモデルは HuggingFace Hub からダウンロードされます。これは 1 回限りのダウンロードであり、その後はローカルに存在します。
ユーザーは、 Settings ] メニューのVectorDB & Embedding Modelsタブから、いつでもこれらの埋め込みモデルを切り替えることができます。
ドキュメントが読み込まれたテーブル: Settingsメニューでは、選択した埋め込みモデルのテーブルが表示され、関連するベクトル データベースに埋め込まれたドキュメントのリストが表示されます。ドキュメントが複数回ロードされると、このテーブルに複数のエントリが含まれることになり、問題のデバッグに役立つ可能性があります。
VectorDB のクリア: Resetボタンを使用して、選択したベクトル データベースをクリアすることを確認します。これにより、選択した埋め込みモデル用の新しい VectorDB がディスク上に作成されます。古い VectorDB はまだ保存されており、config.json ファイルを手動で変更することで元に戻すことができます。
システムプロンプトを編集します。
システム プロンプトは、会話全体に対する LLM への指示として機能します。
LARS では、 System PromptタブのドロップダウンからCustomオプションを選択し、 Settingsメニューからシステム プロンプトを編集する機能がユーザーに提供されます。
システムプロンプトを変更すると、新しいチャットが開始されます
RAG を強制的に有効/無効にする:
ユーザーは、 Settingsメニューを使用して、必要に応じていつでも RAG (検索拡張生成 – LLM で生成された応答を改善するためのドキュメントのコンテンツの使用) を強制的に有効または無効にすることができます。
これは、両方のシナリオで LLM 応答を評価する目的で役立つことがよくあります。
強制的に無効にするとアトリビューション機能も無効になります
NLP を使用して RAG を実行する必要があるかどうかを決定するデフォルト設定が推奨オプションです。
この設定はいつでも変更できます
チャット履歴:
左上のチャット履歴メニューを使用して、以前の会話を参照して再開します
非常に重要: 以前の会話を再開するときは、プロンプト テンプレートの不一致に注意してください。右上のInformationアイコンを使用して、以前の会話で使用された LLM と現在使用されている LLM が両方とも同じプロンプト テンプレート形式に基づいていることを確認します。
ユーザー評価:
ユーザーはいつでも各回答を 5 段階評価で評価できます。
評価データは、アプリ ディレクトリにあるchat-history.db SQLite3 データベースに保存されます。
C:/web_app_storage/app/storage/app評価データは、ワークフローのツールの評価と改良に非常に価値があります。
すべきこととしてはいけないこと:
目次に戻る
チャットがうまくいかない場合、または奇妙な応答が生成された場合は、左上のメニューからNew Chat開始してみてください。
または、ページを更新するだけで新しいチャットを開始できます
引用または RAG パフォーマンスで問題が発生した場合は、上記の一般ユーザー ガイドのステップ 4 の説明に従って、vectorDB をリセットしてみてください。
アプリケーションの問題が発生し、新しいチャットを開始するか LARS を再起動するだけでは解決できない場合は、以下の手順に従って config.json ファイルを削除してみてください。
CTRL+Cで Python プログラムを終了して、LARS アプリ サーバーをシャットダウンします。LARS/web_app ( app.pyと同じディレクトリ) にあるconfig.jsonファイルをバックアップして削除します。上記の一般ユーザー ガイドのステップ 4 で説明されているように VectorDB をリセットしても解決されない重大なデータおよび引用の問題については、次の手順を実行します。
CTRL+Cで Python プログラムを終了して、LARS アプリ サーバーをシャットダウンします。C:/web_app_storage/app/storage/app問題が解決しない場合は、LARS GitHub リポジトリで問題を開いてサポートを受けることを検討してください。
目次に戻る
LARS は、以下の 2 つの個別のイメージを介して Docker コンテナ デプロイ環境に適応されています。
どちらも要件が異なり、前者は展開がシンプルですが、CPU と DDR メモリがボトルネックとなるため、推論パフォーマンスが大幅に低下します。
明示的に必須ではありませんが、Docker コンテナーに関するある程度の経験と、コンテナー化と仮想化の概念に精通していると、このセクションでは非常に役に立ちます。
両方に共通のセットアップ手順から始めます。
Docker のインストール
CPU は仮想化をサポートしており、システムの BIOS/UEFI で有効になっている必要があります。
Docker デスクトップをダウンロードしてインストールします
Windows の場合、Linux 用 Windows サブシステムがまだ存在していない場合は、インストールする必要がある場合があります。これを行うには、管理者として PowerShell を開き、次のコマンドを実行します。
wsl --install
Docker デスクトップが起動して実行中であることを確認してから、コマンド プロンプト/ターミナルを開いて次のコマンドを実行して、Docker が正しくインストールされ、起動して実行中であることを確認します。
docker ps
実行時に LARS コンテナーに接続される Docker ストレージ ボリュームを作成します。
LARS コンテナで使用するストレージ ボリュームを作成すると、すべての設定、チャット履歴、ベクター データベースをシームレスに保持しながら、LARS コンテナを新しいバージョンにアップグレードしたり、CPU と GPU コンテナのバリアントを切り替えたりできるため、非常に有利です。 。
コマンド プロンプト/ターミナルで次のコマンドを実行します。
docker volume create lars_storage_volue
このボリュームは、後の実行時に LARS コンテナに接続されます。ここでは、以下の手順で LARS イメージの構築に進みます。
コマンド プロンプト/ターミナルで、次のコマンドを実行します。
git clone https://github.com/abgulati/LARS # skip if already done
cd LARS # skip if already done
cd dockerized
docker build -t lars-no-gpu .
# Once the build is complete, run the container:
docker run -p 5000:5000 -p 8080:8080 -v lars_storage:/app/storage lars-no-gpu
完了したら、ブラウザでhttp://localhost:5000/に移動し、最初の実行手順とユーザー ガイドの残りの部分に従います。
トラブルシューティングのセクションは Container-LARS にも適用されます
要件 (Docker に加えて):
Compatible Nvidia GPU(s)
Nvidia GPU drivers
Nvidia CUDA Toolkit v12.2
Linux の場合、上記の設定はすべて完了しているため、次のステップをスキップして、さらに下のビルドと実行のステップに直接進みます。
Windows を使用していて、Docker 上で Nvidia GPU コンテナーを実行するのが初めての場合は、これがかなり大変になるため、しっかりと準備をしてください (好きな飲み物 1 つまたは 3 つを強くお勧めします)。
極端な冗長性が生じる危険があるため、続行する前に、次の依存関係が存在することを確認してください。
Compatible Nvidia GPU(s)
Nvidia GPU drivers
Nvidia CUDA Toolkit v12.2
Docker Desktop
Windows Subsystem for Linux (WSL)
不明な場合は、上記の「Nvidia CUDA 依存関係」セクションと「Docker セットアップ」セクションを参照してください。
上記が存在し、セットアップされている場合は、そのまま続行できます。
PC で Microsoft Store アプリを開き、Ubuntu 22.04.3 LTS をダウンロードしてインストールします (dockerfile の 2 行目のバージョンと一致する必要があります)
はい、上記を正しく読みました: Microsoft ストア アプリから Ubuntu をダウンロードしてインストールします。以下のスクリーンショットを参照してください。
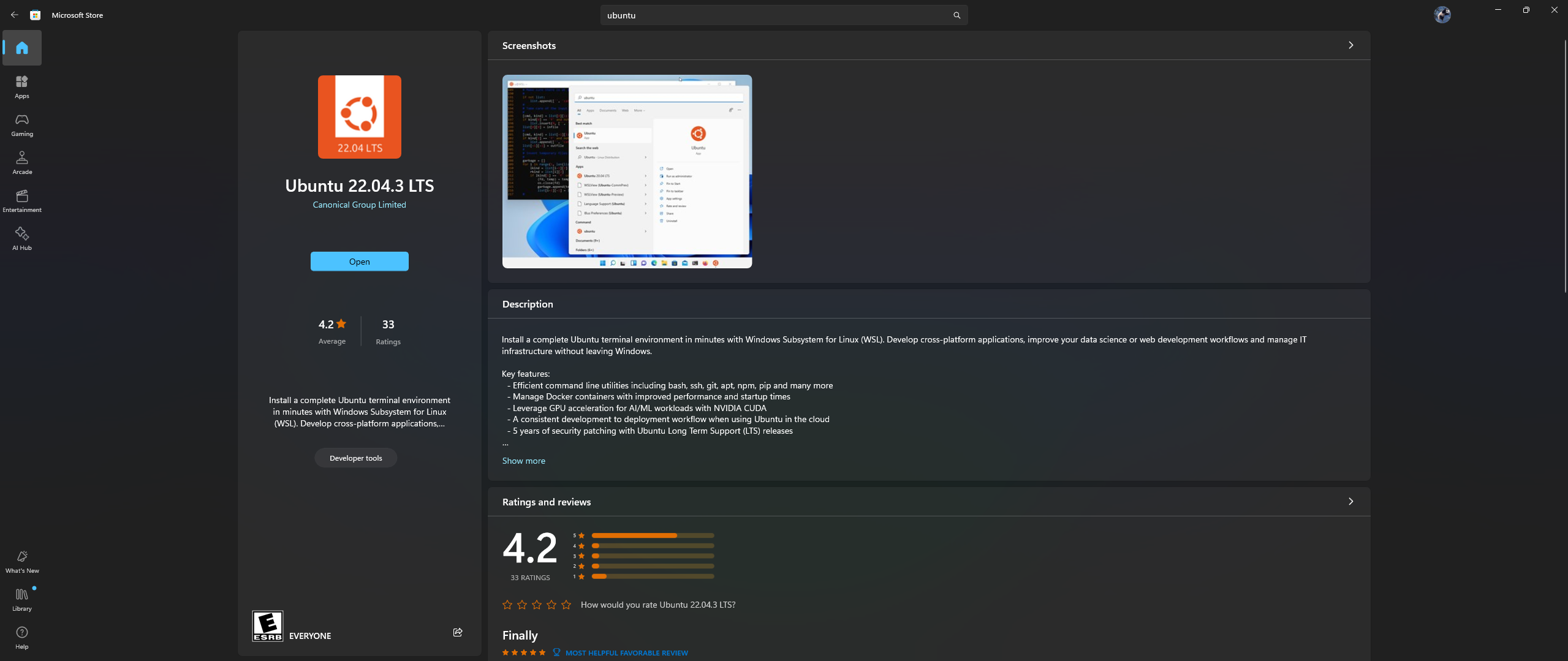
ここで、Ubuntu 内に Nvidia Container Toolkit をインストールします。これを行うには、次の手順に従います。
上記のインストールが完了したら、「スタート」メニューでUbuntuを検索して、Windows で Ubuntu シェルを起動します。
開いたこの Ubuntu コマンドラインで、次の手順を実行します。
実稼働リポジトリを構成します。
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list |
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' |
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
リポジトリからパッケージ リストを更新し、Nvidia Container Toolkit パッケージをインストールします。
sudo apt-get update && apt-get install -y nvidia-container-toolkit
nvidia-ctk コマンドを使用してコンテナー ランタイムを構成します。これにより、Docker が Nvidia コンテナー ランタイムを使用できるように /etc/docker/daemon.json ファイルが変更されます。
sudo nvidia-ctk runtime configure --runtime=docker
Docker デーモンを再起動します。
sudo systemctl restart docker
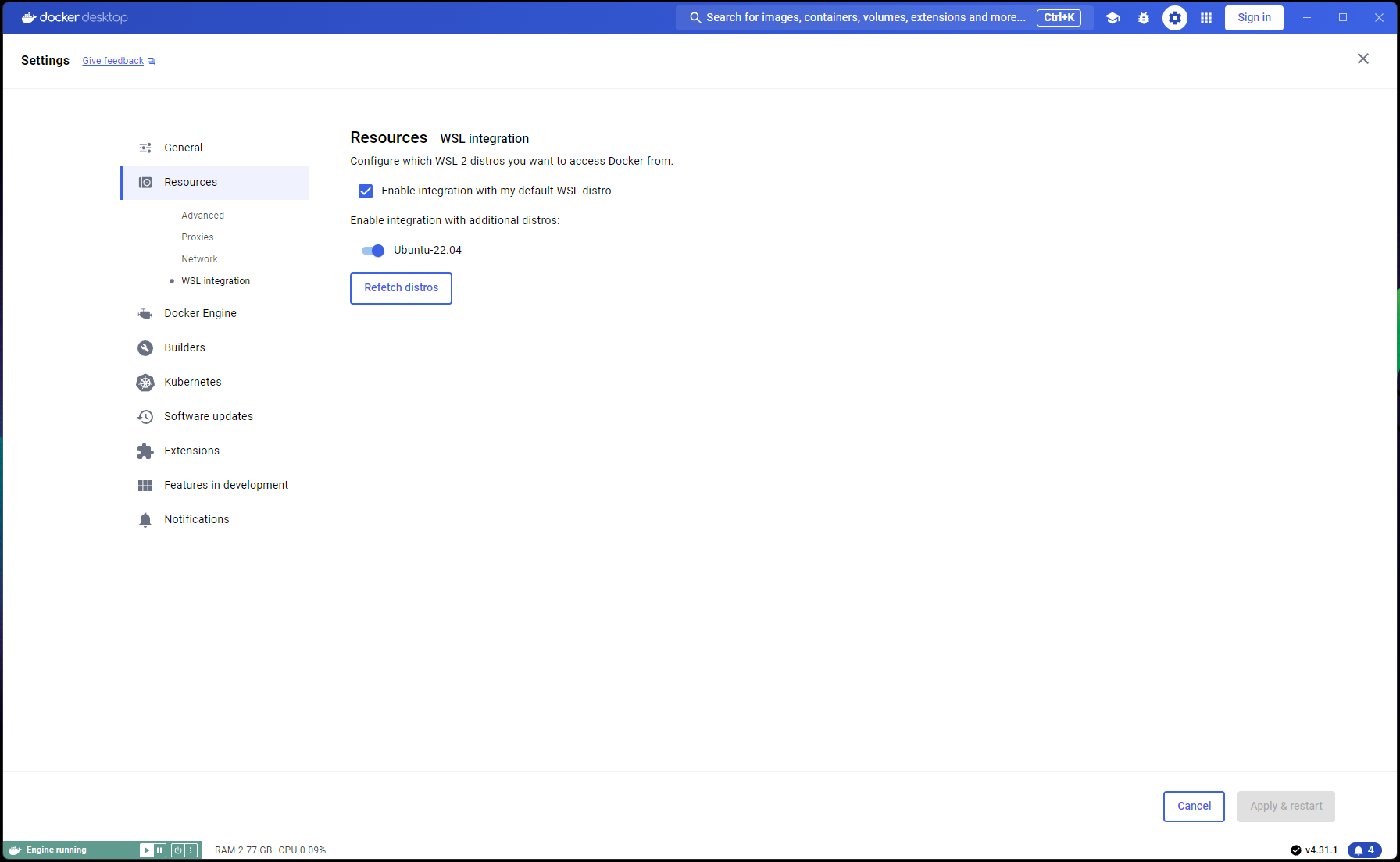
これで Ubuntu のセットアップが完了しました。WSL と Docker の統合を完了します。
新しい PowerShell ウィンドウを開き、この Ubuntu インストールを WSL のデフォルトとして設定します。
wsl --list
wsl --set-default Ubuntu-22.04 # if not already marked as Default
Docker Desktop -> Settings -> Resources -> WSL Integration -> [デフォルトと Ubuntu 22.04 の統合を確認] に移動します。以下のスクリーンショットを参照してください。
すべてが正しく行われていれば、コンテナを構築して実行する準備が整いました。
コマンド プロンプト/ターミナルで、次のコマンドを実行します。
git clone https://github.com/abgulati/LARS # skip if already done
cd LARS # skip if already done
cd dockerized_nvidia_cuda_gpu
docker build -t lars-nvcuda .
# Once the build is complete, run the container:
docker run --gpus all -p 5000:5000 -p 8080:8080 -v lars_storage:/app/storage lars-nvcuda
完了したら、ブラウザでhttp://localhost:5000/に移動し、最初の実行手順とユーザー ガイドの残りの部分に従います。
トラブルシューティングのセクションは Container-LARS にも適用されます
ネットワーク関連のエラー、特にコンテナの構築時に使用できないパッケージ リポジトリに関連するエラーが発生した場合、これはファイアウォールの問題に関連することが多い、エンド側のネットワークの問題です。
Windows では、 Control PanelSystem and SecurityWindows Defender FirewallAllowed appsに移動するか、スタート メニューでFirewall検索し、 Allow an app through the firewallに進み、```Docker Desktop Backend`` が許可されていることを確認します。
初めて LARS を実行すると、文変換埋め込みモデルがダウンロードされます。
コンテナ化された環境では、このダウンロードに問題が発生し、クエリを実行するとエラーが発生する場合があります。
この問題が発生した場合は、LARS 設定メニューに進み、 Settings->VectorDB & Embedding Models移動し、埋め込みモデルを BGE-Base または BGE-Large に変更します。これにより、リロードと再ダウンロードが強制的に行われます。
完了したら、再度質問に進み、通常どおり応答が生成されるはずです。
文変換埋め込みモデルに戻すと、問題は解決されるはずです。
上記のトラブルシューティング セクションで述べたように、埋め込みモデルは LARS の初回実行時にダウンロードされます。
コンテナをシャットダウンする前にコンテナの状態を保存することをお勧めします。これにより、コンテナが起動されるたびにこのダウンロード手順を繰り返す必要がなくなります。
これを行うには、実行中の LARS コンテナを閉じる前に、別のコマンド プロンプト/ターミナルを開いて変更をコミットします。
docker ps # note the container_id here
docker commit <container_ID> <new_image_name> # for new_image_name, I simply add 'pfr', for 'post-first-run' to the current image name, example: lars-nvcuda-pfr
これにより、以降の実行で使用できる更新されたイメージが作成されます。
docker run --gpus all -p 5000:5000 -p 8080:8080 -v lars_storage:/app/storage lars-nvcuda-pfr
注: 上記の作業を行った後、 docker images使用してイメージによって使用されているスペースを確認すると、大量のスペースが使用されていることがわかります。ただし、ここでのサイズを文字通りに受け取らないでください。各イメージに表示されるサイズには、そのすべてのレイヤーの合計サイズが含まれますが、特にそれらのイメージが同じベース イメージに基づいている場合、またはあるイメージが別のイメージのコミットされたバージョンである場合、これらのレイヤーの多くはイメージ間で共有されます。 Docker イメージが実際に使用しているディスク容量を確認するには、次を使用します。
docker system df
目次に戻る
| カテゴリ | タスク | 状態 |
|---|---|---|
| バグ修正: | ゼロバイトのテキスト ファイル作成の危険性 - 入力ドキュメントの OCR/テキスト抽出が失敗した場合、0B .txt ファイルが残る場合があり、そのファイルがすでにロードされていると信じてさらに再試行が行われる可能性があります。 | ?今後の課題 |
| 実用的な機能: | 使いやすさを重視: | |
| Azure CV-OCR の無料枠 UI 切り替え | ✅ 2024 年 6 月 8 日に完了 | |
| チャットの削除 | ?今後の課題 | |
| チャットの名前を変更する | ?今後の課題 | |
| PowerShell インストール スクリプト | ?今後の課題 | |
| Linux インストール スクリプト | ?今後の課題 | |
| llama.cpp の代替としての Ollama LLM 推論バックエンド | ?今後の課題 | |
| 他のクラウドプロバイダー(GCP、AWS、OCIなど)のOCRサービスの統合 | ?今後の課題 | |
| ドキュメントのアップロード時に以前のテキスト抽出を無視するように UI を切り替えます | ?今後の課題 | |
| ファイルアップロード用のモーダルポップアップ: 設定からのテキスト抽出オプションのミラーリング、送信時のグローバル上書き、設定の永続化への切り替え | ?今後の課題 | |
| パフォーマンス中心: | ||
| Nvidia TensorRT-LLM AWQ のサポート | ?今後の課題 | |
| 研究課題: | Nvidia TensorRT-LLM を調査する: ターゲット GPU に固有の AWQ-LLM TRT エンジンを構築する必要があります。NvTensorRT-LLM は独自のエコシステムであり、Python v3.10 でのみ動作します。 | ✅ 2024 年 6 月 13 日に完了 |
| Vision LLM を使用したローカル OCR: MS-TrOCR (完了)、Kosmos-2.5 (高優先度)、Llava、Florence-2 | ? 2024 年 7 月 5 日のアップデートが進行中 | |
| RAG の改善: リランカー、RAPTOR、T-RAG | ?今後の課題 | |
| GraphDB の統合を調査する: LLM を使用してドキュメントからエンティティ関係データを抽出し、GraphDB にデータを入力、更新、維持する | ?今後の課題 |
目次に戻る
LARS があなたの仕事に価値をもたらしてくれることを願っています。また、LARS の進行中の開発をサポートしていただければ幸いです。このツールに感謝し、将来の機能強化に貢献したい場合は、寄付を検討してください。皆様のご支援により、LARS の改善と新機能の追加を続けることができます。
寄付方法 寄付するには、次の PayPal へのリンクを使用してください。
PayPal経由で寄付する
あなたの貢献は大いに感謝され、さらなる開発努力の資金として使用されます。
目次に戻る


