cambrian
1.0.0
興味深い事実: 視覚はカンブリア紀の動物に出現しました。これが私たちのプロジェクト名「カンブリアン」のインスピレーションとなりました。
eval/サブフォルダーを参照してください。dataengine/サブフォルダーを参照してください。現在、TorchXLA を使用した TPU のトレーニングをサポートしています
git clone https://github.com/cambrian-mllm/cambrian
cd cambrianconda create -n cambrian python=3.10 -y
conda activate cambrian
pip install --upgrade pip # enable PEP 660 support
pip install -e " .[tpu] " pip install torch~=2.2.0 torch_xla[tpu]~=2.2.0 -f https://storage.googleapis.com/libtpu-releases/index.html
git clone https://github.com/cambrian-mllm/cambrian
cd cambrianconda create -n cambrian python=3.10 -y
conda activate cambrian
pip install --upgrade pip # enable PEP 660 support
pip install " .[gpu] " ここではカンブリア紀のチェックポイントとウェイトの使用方法を説明します。当社のモデルは、8B、13B、および 34B パラメーター レベルで、さまざまな次元で優れています。これらは、いくつかのベンチマークにおいて、GPT-4V、Gemini-Pro、Grok-1.4V などのクローズドソースの独自モデルと比較して競争力のあるパフォーマンスを示しています。
| モデル | #ヴィス。トック。 | MMB | SQA-I | MathVistaM | チャートQA | MMVP |
|---|---|---|---|---|---|---|
| GPT-4V | UNK | 75.8 | - | 49.9 | 78.5 | 50.0 |
| ジェミニ-1.0 プロ | UNK | 73.6 | - | 45.2 | - | - |
| ジェミニ-1.5 プロ | UNK | - | - | 52.1 | 81.3 | - |
| Grok-1.5 | UNK | - | - | 52.8 | 76.1 | - |
| MM-1-8B | 144 | 72.3 | 72.6 | 35.9 | - | - |
| MM-1-30B | 144 | 75.1 | 81.0 | 39.4 | - | - |
| ベース LLM: ファイ-3-3.8B | ||||||
| カンブリア紀-1-8B | 576 | 74.6 | 79.2 | 48.4 | 66.8 | 40.0 |
| ベース LLM: LLaMA3-8B-命令 | ||||||
| ミニジェミニ-HD-8B | 2880 | 72.7 | 75.1 | 37.0 | 59.1 | 18.7 |
| LLaVA-NeXT-8B | 2880 | 72.1 | 72.8 | 36.3 | 69.5 | 38.7 |
| カンブリア紀-1-8B | 576 | 75.9 | 80.4 | 49.0 | 73.3 | 51.3 |
| ベースLLM:ビクーニャ1.5-13B | ||||||
| ミニジェミニ-HD-13B | 2880 | 68.6 | 71.9 | 37.0 | 56.6 | 19.3 |
| LLaVA-NeXT-13B | 2880 | 70.0 | 73.5 | 35.1 | 62.2 | 36.0 |
| カンブリア紀-1-13B | 576 | 75.7 | 79.3 | 48.0 | 73.8 | 41.3 |
| ベースLLM:Hermes2-Yi-34B | ||||||
| ミニジェミニ-HD-34B | 2880 | 80.6 | 77.7 | 43.4 | 67.6 | 37.3 |
| LLaVA-NeXT-34B | 2880 | 79.3 | 81.8 | 46.5 | 68.7 | 47.3 |
| カンブリア紀-1-34B | 576 | 81.4 | 85.6 | 53.2 | 75.6 | 52.7 |
完全な表については、Cambrian-1 論文を参照してください。
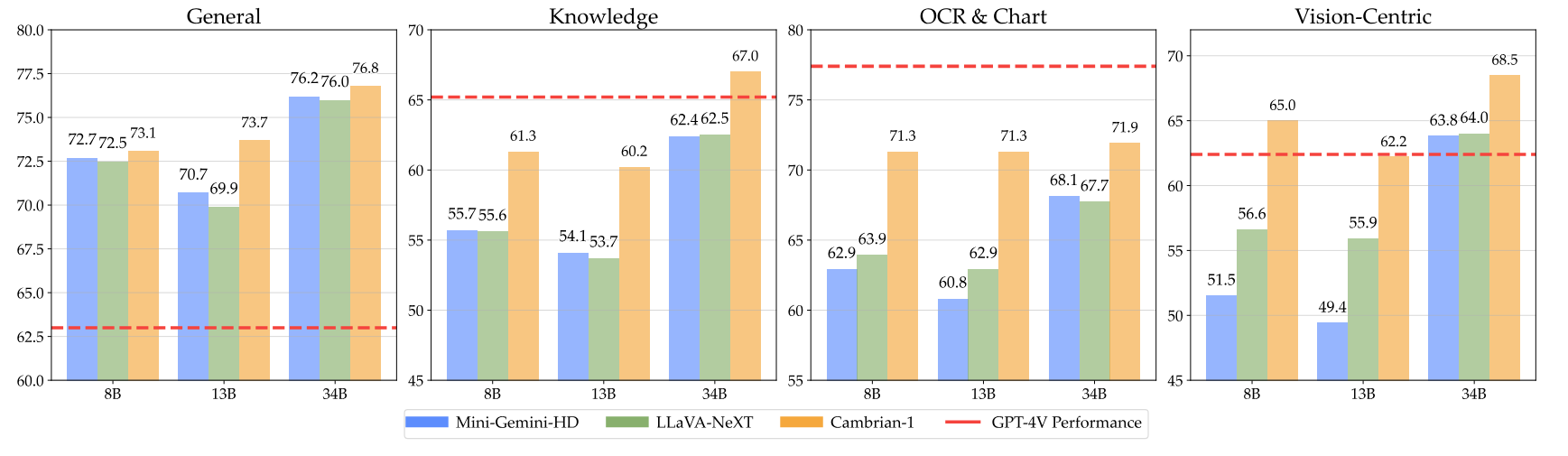
当社のモデルは、より少ない固定数のビジュアル トークンを使用しながら、非常に競争力のあるパフォーマンスを提供します。
モデル ウェイトを使用するには、Hugging Face からダウンロードします。
サンプルモデルの読み込みおよび生成スクリプトをinference.pyで提供します。

この作業では、MLLM のトレーニングにおけるデータを研究するための将来の作業のために、非常に大規模な命令調整データのプールである Cambrian-10M を収集します。予備調査では、データをフィルタリングして、Cambrian-7M と呼ばれる 700 万個の厳選されたデータ ポイントの高品質セットに絞り込みます。これらのデータセットはどちらも、Hugging Face Dataset: Cambrian-10M で利用できます。
VQA、視覚的会話、身体化された視覚的インタラクションなど、さまざまなソースからさまざまな視覚的指示のチューニング データを収集しました。高品質で信頼性の高い大規模なナレッジ データを確保するために、インターネット データ エンジンを設計しました。
さらに、VQA データは非常に短い出力を生成する傾向があり、トレーニング データからの分布のシフトが生じることが観察されました。この問題に対処するために、GPT-4v と GPT-4o を活用して、拡張応答とより創造的なデータを作成しました。
科学関連データの不十分さを解決するために、信頼できる科学関連の VQA データを収集するインターネット データ エンジンを設計しました。このエンジンは、あらゆるトピックに関するデータを収集するために適用できます。このエンジンを使用して、さらに 161,000 個の科学関連の視覚的指導調整データ ポイントを収集し、このドメインの総データが 400% 増加しました。この部分のデータを使用したい場合は、この jsonl を使用してください。
GPT-4v を使用して、追加の 77,000 データ ポイントを作成しました。このデータは、GPT-4v を使用して、元の回答のみの VQA をより詳細な回答を含む長い回答に書き換えるか、指定された画像に基づいて視覚的な指示調整データを生成します。この部分のデータを使用したい場合は、この jsonl を使用してください。
GPT-4o を使用して、追加の 60,000 のクリエイティブ データ ポイントを作成しました。このデータにより、モデルは非常に長い応答を生成するようになり、多くの場合、詩を書く、曲を作曲するなど、非常に創造的な質問が含まれます。この部分のデータを使用したい場合は、この jsonl を使用してください。
私たちは次の方法でデータキュレーションに関する初期調査を実施しました。
経験的にその設定が見つかりました
| カテゴリ | データ比率 |
|---|---|
| 言語 | 21.00% |
| 一般的な | 34.52% |
| OCR | 27.22% |
| 数える | 8.71% |
| 数学 | 7.20% |
| コード | 0.87% |
| 科学 | 0.88% |
以下の表に示すように、以前の LLaVA-665K モデルと比較して、スケールアップとデータ キュレーションの改善により、モデルのパフォーマンスが大幅に向上しました。
| モデル | 平均 | 一般知識 | OCR | チャート | ビジョン中心 |
|---|---|---|---|---|---|
| LLaVA-665K | 40.4 | 64.7 | 45.2 | 20.8 | 31.0 |
| カンブリアン-10M | 53.8 | 68.7 | 51.6 | 47.1 | 47.6 |
| カンブリア紀-7M | 54.8 | 69.6 | 52.6 | 47.3 | 49.5 |
Cambrian-7M を使用したトレーニングでは競争力のあるベンチマーク結果が得られますが、モデルが短い応答を出力し、質問応答機のように動作する傾向があることが観察されました。 「応答マシン」現象と呼ばれるこの動作は、より複雑なインタラクションにおけるモデルの有用性を制限する可能性があります。
「単一の単語または語句を使用して質問に答えてください」などのシステム プロンプトを追加すると問題があることがわかりました。問題を軽減するのに役立ちます。このアプローチにより、モデルは文脈上適切な場合にのみそのような簡潔な回答を提供するようになります。詳細については、論文を参照してください。
また、システム プロンプトを備えたデータセット Cambrian-7Mも厳選しました。これには、モデルの創造性とチャット機能を強化するシステム プロンプトが含まれています。
以下は、Cambrian-1 の最新のトレーニング構成です。
Cambrian-1 の論文では、2 段階のトレーニングの必要性を実証するために広範な研究が行われています。 Cambrian-1 トレーニングは 2 つの段階で構成されます。
Cambrian-1 は TPU-V4-512 でトレーニングされますが、TPU-V4-64 以降の TPU でトレーニングすることもできます。 GPU トレーニング コードは間もなくリリースされる予定です。少ない GPU での GPU トレーニングの場合は、 per_device_train_batch_sizeを減らし、それに応じてgradient_accumulation_stepsを増やし、グローバル バッチ サイズが同じになるようにします: per_device_train_batch_size x gradient_accumulation_steps x num_gpus 。
事前トレーニングと微調整で使用される両方のハイパーパラメーターを以下に示します。
| 基本LLM | グローバルバッチサイズ | 学習率 | SVA 学習率 | エポック | 最大長さ |
|---|---|---|---|---|---|
| LLaMA-3 8B | 512 | 1e-3 | 1e-4 | 1 | 2048年 |
| ビクーニャ-1.5 13B | 512 | 1e-3 | 1e-4 | 1 | 2048年 |
| エルメス Yi-34B | 1024 | 1e-3 | 1e-4 | 1 | 2048年 |
| 基本LLM | グローバルバッチサイズ | 学習率 | エポック | 最大長さ |
|---|---|---|---|---|
| LLaMA-3 8B | 512 | 4e-5 | 1 | 2048年 |
| ビクーニャ-1.5 13B | 512 | 4e-5 | 1 | 2048年 |
| エルメス Yi-34B | 1024 | 2e-5 | 1 | 2048年 |
命令を微調整するために、モデル トレーニングの最適な学習率を決定するために実験を実施しました。調査結果に基づき、次の式を使用して、デバイスの可用性に基づいて学習率を調整することをお勧めします。
optimal lr = base_lr * sqrt(bs / base_bs)
基本 LLM を取得し、8B、13B、および 34B モデルをトレーニングするには:
LLaVA、ShareGPT4V、Mini-Gemini、および ALLaVA アライメント データの組み合わせを使用して、ビジュアル コネクタ (SVA) を事前トレーニングします。カンブリアン 1 では、追加の位置合わせデータを使用する必要性と利点を実証するために広範な研究が行われています。
まずは、ハグ顔アライメント データ ページにアクセスして詳細をご確認ください。次のリンクからアライメント データをダウンロードできます。
サンプル トレーニング スクリプトは次の場所で提供されています。
他のデータ ソースまたはカスタム データを使用してトレーニングする場合は、一般的に使用される LLaVA データ形式がサポートされます。非常に大きなファイルを処理する場合、メモリ使用量を最適化するために遅延データ読み込み用の JSON 形式ではなく JSONL 形式を使用します。
トレーニング SVA と同様に、命令チューニング データの詳細については、Cambrian-10M データを参照してください。
サンプル トレーニング スクリプトは次の場所で提供されています。
--mm_projector_type : SVA モジュールを使用するには、この値をsvaに設定します。 LLaVA スタイルの 2 層 MLP プロジェクターを使用するには、この値をmlp2x_geluに設定します。--vision_tower_aux_list : 使用するビジョン モデルのリスト (例: '["siglip/CLIP-ViT-SO400M-14-384", "openai/clip-vit-large-patch14-336", "facebook/dinov2-giant-res378", "clip-convnext-XXL-multi-stage"]' )。--vision_tower_aux_token_len_list : 各ビジョン タワーのビジョン トークンの数のリスト。各数値は平方数である必要があります (例: '[576, 576, 576, 9216]' )。各ビジョン タワーのフィーチャ マップは、この要件を満たすように補間されます。--image_token_len : LLM に提供されるビジョン トークンの最終数。数値は平方数である必要があります (例: 576 )。 mm_projector_typeが mlp の場合、 vision_tower_aux_token_len_listの各数値はimage_token_lenと同じである必要があることに注意してください。以下の引数は、SVA プロジェクターに対してのみ意味があります。--num_query_group : SVA モジュールのG値。--query_num_list : SVA のクエリの各グループのクエリ番号のリスト (例: '[576]' )。リストの長さはnum_query_groupと等しくなければなりません。--connector_depth : SVA モジュールのD値。--vision_hidden_size : SVA モジュールの非表示サイズ。--connector_only : true の場合、SVA モジュールは LLM の前にのみ表示されます。そうでない場合は、LLM 内に複数回挿入されます。次の 3 つの引数は、これがFalseに設定されている場合にのみ意味を持ちます。--num_of_vision_sampler_layers : LLM 内に挿入された SVA モジュールの総数。--start_of_vision_sampler_layers : SVA の挿入が開始される LLM レイヤー インデックス。--stride_of_vision_sampler_layers : LLM 内への SVA モジュール挿入のストライド。 評価コードをeval/サブフォルダーに公開しました。詳細については、そこにある README を参照してください。
次の手順では、Cambrian を使用してローカル Gradio デモを起動する方法を説明します。モデルを操作するためのシンプルな Web インターフェイスが提供されています。 CLI を推論に使用することもできます。このセットアップは LLaVA から大きなインスピレーションを受けています。
ローカルの Gradio デモを起動するには、以下の手順に従ってください。ローカル サービング コードの図は以下の1にあります。
%%{init: {"テーマ": "ベース"}}%%
フローチャートBT
%% ノードを宣言する
スタイル gws 塗りつぶし:#f9f、ストローク:#333、ストローク幅:2px
スタイル c 塗りつぶし:#bbf、ストローク:#333、ストローク幅:2px
スタイル mw8b 塗りつぶし:#aff、ストローク:#333、ストローク幅:2px
スタイル mw13b 塗りつぶし:#aff、ストローク:#333、ストローク幅:2px
%% スタイル sglw13b 塗りつぶし:#ffa、ストローク:#333、ストローク幅:2px
%% スタイル lsglw13b 塗りつぶし:#ffa、ストローク:#333、ストローク幅:2px
gws["Gradio (UI サーバー)"]
c["コントローラー (API サーバー):<br/>ポート: 10000"]
mw8b["モデル ワーカー:<br/><b>カンブリアン-1-8B</b><br/>ポート: 40000"]
mw13b["モデル ワーカー:<br/><b>カンブリアン-1-13B</b><br/>ポート: 40001"]
%% sglw13b["SGLang バックエンド:<br/><b>カンブリアン-1-34B</b><br/>http://localhost:30000"]
%% lsglw13b["SGLang ワーカー:<br/><b>カンブリアン-1-34B<b><br/>ポート: 40002"]
サブグラフ「デモアーキテクチャ」
BT方向
c <--> GWS
mw8b <--> c
mw13b <--> c
%% lsglw13b <--> c
%% sglw13b <--> lsglw13b
終わり
python -m cambrian.serve.controller --host 0.0.0.0 --port 10000python -m cambrian.serve.gradio_web_server --controller http://localhost:10000 --model-list-mode reloadGradio Web インターフェイスを起動しました。これで、画面に印刷された URL で Web インターフェイスを開くことができます。モデル リストにモデルが存在しないことに気付くかもしれません。まだモデルワーカーを立ち上げていないので、心配しないでください。モデル ワーカーを起動すると自動的に更新されます。
近日公開。
これは、GPU で推論を実行する実際のワーカーです。各ワーカーは、 --model-pathで指定された単一のモデルを担当します。
python -m cambrian.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path nyu-visionx/cambrian-8bプロセスがモデルのロードを完了し、「Uvicorn running on ...」が表示されるまで待ちます。ここで、Gradio Web UI を更新すると、モデル リストに起動したモデルが表示されます。
必要な数のワーカーを起動し、同じ Gradio インターフェイス内の異なるモデル チェックポイント間を比較できます。 --controller同じままにして、 --port port と--workerワーカーごとに異なるポート番号に変更してください。
python -m cambrian.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port < different from 40000, say 40001> --worker http://localhost: < change accordingly, i.e. 40001> --model-path < ckpt 2> M1 または M2 チップを搭載した Apple デバイスを使用している場合は、 --deviceフラグ--device mps使用して mps デバイスを指定できます。
GPU の VRAM が 24GB 未満の場合 (RTX 3090、RTX 4090 など)、複数の GPU で実行してみてください。複数の GPU がある場合、最新のコード ベースは自動的に複数の GPU の使用を試みます。 CUDA_VISIBLE_DEVICESで使用する GPU を指定できます。以下は、最初の 2 つの GPU で実行する例です。
CUDA_VISIBLE_DEVICES=0,1 python -m cambrian.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path nyu-visionx/cambrian-8bTODO
カンブリア紀があなたの研究や応用に役立つと思われる場合は、この BibTeX を使用して引用してください。
@misc { tong2024cambrian1 ,
title = { Cambrian-1: A Fully Open, Vision-Centric Exploration of Multimodal LLMs } ,
author = { Shengbang Tong and Ellis Brown and Penghao Wu and Sanghyun Woo and Manoj Middepogu and Sai Charitha Akula and Jihan Yang and Shusheng Yang and Adithya Iyer and Xichen Pan and Austin Wang and Rob Fergus and Yann LeCun and Saining Xie } ,
year = { 2024 } ,
eprint = { 2406.16860 } ,
}
使用法とライセンスに関する通知: このプロジェクトでは、それぞれの元のライセンスの対象となる特定のデータセットとチェックポイントを利用します。ユーザーは、データセットの OpenAI 利用規約や、データセットを使用してトレーニングされたチェックポイントの基本言語モデルの特定のライセンス (例: LLaMA-3 の Llama コミュニティ ライセンス、およびビクーニャ-1.5)。このプロジェクトには、元のライセンスに規定されているものを超える追加の制約は課されません。さらに、ユーザーは、データセットとチェックポイントの使用が、適用されるすべての法律および規制に準拠していることを確認するよう注意されます。
LLaVA の図からコピーしました。 ↩


