Synonyms
Synonyms
自然言語の処理と理解の中国語の同義語。
より良い中国語の同義語: チャットボット、インテリジェントな質問と回答のツールキット。
synonyms 、テキストの配置、推奨アルゴリズム、類似性の計算、セマンティック オフセット、キーワード抽出、概念抽出、自動要約、検索エンジンなど、自然言語理解における多くのタスクに使用できます。
安定した信頼性が高く、長期的に最適化されたサービスを提供するために、Synonyms は Chunsong ライセンス v1.0 を使用するように変更され、機械学習モデルのダウンロードにかかる料金が異なります。詳細については、証明書ストアを参照してください。以前の貢献者 (顕著な貢献をしたコード貢献者) は、課金の問題について話し合うために私たちに連絡することができます。 -- 株式会社チャトペラ @ 2023 年 10 月
以下の手順に従って、パッケージをインストールしてアクティブ化します。
pip install -U synonyms現在の安定バージョンは v3.x です。
Synonyms の機械学習モデル パッケージには Chatopera ライセンス ストアからのライセンスが必要です。まずライセンスを購入し、Chatopera ライセンス ストアのライセンスページからlicense idを取得します ( license id : 証明書ストアの証明書の詳細ページで [コピー] をクリックします)証明書の ID])。
次に、以下のようにターミナルまたはシェルスクリプトで環境変数を設定します。
例: Linux、Windows、macOS 上のシェル、CMD スクリプト。
# Linux / macOS
export SYNONYMS_DL_LICENSE=YOUR_LICENSE
# # e.g. if your license id is `FOOBAR`, run `export SYNONYMS_DL_LICENSE=FOOBAR`
# Windows
# # 1/2 Command Prompt
set SYNONYMS_DL_LICENSE=YOUR_LICENSE
# # 2/2 PowerShell
$env :SYNONYMS_DL_LICENSE= ' YOUR_LICENSE 'Jupyter Notebookなど
import os
os . environ [ "SYNONYMS_DL_LICENSE" ] = "YOUR_LICENSE"
_licenseid = os . environ . get ( "SYNONYMS_DL_LICENSE" , None )
print ( "SYNONYMS_DL_LICENSE=" , _licenseid )
ヒント: Word ベクター ファイルはインストール後に初めてダウンロードされます。ダウンロード速度はネットワークの状況によって異なります。
最後に、コマンドまたはスクリプトでモデル パッケージをダウンロードします。
python -c " import synonyms; synonyms.display('能量') " # download word vectors file 
環境変数を使用した単語セグメンテーション語彙および word2vec 単語ベクトル ファイルの構成をサポートします。
| 環境変数 | 説明する |
|---|---|
| SYNONYMS_WORD2VEC_BIN_MODEL_ZH_CN | word2vec を使用してトレーニングされた Word ベクター ファイル (バイナリ形式)。 |
| SYNONYMS_WORDSEG_DICT | 中国語単語分割マスター辞書、形式と使用方法のリファレンス |
| SYNONYMS_DEBUG | ["TRUE"|"FALSE"]、デバッグログを出力するかどうか、"TRUE"出力に設定、デフォルトは"FALSE" |
import synonyms
print ( "人脸: " , synonyms . nearby ( "人脸" ))
print ( "识别: " , synonyms . nearby ( "识别" ))
print ( "NOT_EXIST: " , synonyms . nearby ( "NOT_EXIST" )) synonyms.nearby(WORD [,SIZE])はタプルを返します: ([nearby_words], [nearby_words_score]) 。 nearby_wordsはリストの形式で保存されます。距離は近くから遠くまで配置されており、 nearby_words_scoreは、 nearby_words内の対応する位置の単語間の距離のスコアであり、1 に近づくほど、返される単語の数が小さくなりSIZE 。デフォルトは 10 です。例えば:
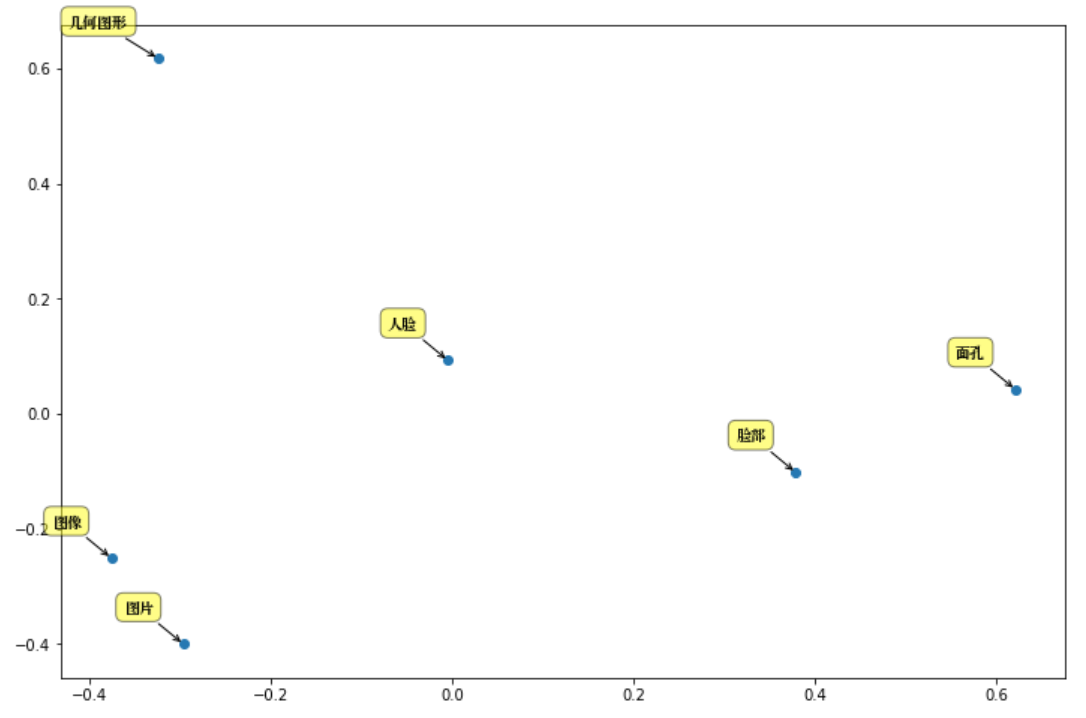
synonyms . nearby (人脸, 10 ) = (
[ "图片" , "图像" , "通过观察" , "数字图像" , "几何图形" , "脸部" , "图象" , "放大镜" , "面孔" , "Mii" ],
[ 0.597284 , 0.580373 , 0.568486 , 0.535674 , 0.531835 , 0.530
095 , 0.525344 , 0.524009 , 0.523101 , 0.516046 ]) OOV の場合、 ([], [])が返され、現在の辞書サイズ: 435,729。
2 つの文の類似性の比較
sen1 = "发生历史性变革"
sen2 = "发生历史性变革"
r = synonyms . compare ( sen1 , sen2 , seg = True )このうちパラメータ seg は、synonyms.compare が sen1 と sen2 に対して単語分割を行うかどうかを示し、デフォルトは True です。戻り値: [0-1] で、1 に近いほど 2 つの文が類似していることを示します。
旗帜引领方向 vs 道路决定命运: 0.429
旗帜引领方向 vs 旗帜指引道路: 0.93
发生历史性变革 vs 发生历史性变革: 1.0デバッグを容易にするために、同義語を分かりやすく表示します。display display(WORD [, SIZE]) synonyms#nearbyメソッドを呼び出します。
>> > synonyms . display ( "飞机" )
'飞机'近义词:
1. 飞机: 1.0
2. 直升机: 0.8423391
3. 客机: 0.8393003
4. 滑翔机: 0.7872388
5. 军用飞机: 0.7832081
6. 水上飞机: 0.77857226
7. 运输机: 0.7724742
8. 航机: 0.7664748
9. 航空器: 0.76592904
10. 民航机: 0.74209654 SIZE印刷される語彙リストの数で、デフォルトは 10 です。
現在のパッケージの説明情報を出力します。
>>> synonyms.describe()
Vocab size in vector model: 435729
model_path: /Users/hain/chatopera/Synonyms/synonyms/data/words.vector.gz
version: 3.18.0
{'vocab_size': 435729, 'version': '3.18.0', 'model_path': '/chatopera/Synonyms/synonyms/data/words.vector.gz'}
numpy 配列である単語ベクトルを取得します。単語が未登録の単語の場合、KeyError 例外がスローされます。
>> > synonyms . v ( "飞机" )
array ([ - 2.412167 , 2.2628384 , - 7.0214124 , 3.9381874 , 0.8219283 ,
- 3.2809453 , 3.8747153 , - 5.217062 , - 2.2786229 , - 1.2572327 ],
dtype = float32 )単語分割後の文のベクトルを取得します。ベクトルは BoW モードで合成されます。
sentence : 句子是分词后通过空格联合起来
ignore : 是否忽略OOV , False时,随机生成一个向量中国語の単語の分割
synonyms . seg ( "中文近义词工具包" )単語分割の結果は、単語と対応する品詞の 2 つのリストで構成されるタプルです。
([ '中文' , '近义词' , '工具包' ], [ 'nz' , 'n' , 'n' ])この分詞はストップワードや句読点を削除しません。
キーワードを抽出します。デフォルトでは、キーワードは重要度に応じて抽出されます。
keywords = synonyms.keywords("9月15日以来,台积电、高通、三星等华为的重要合作伙伴,只要没有美国的相关许可证,都无法供应芯片给华为,而中芯国际等国产芯片企业,也因采用美国技术,而无法供货给华为。目前华为部分型号的手机产品出现货少的现象,若该形势持续下去,华为手机业务将遭受重创。")
デバッグ用にさらにログを取得し、環境変数を設定します。
SYNONYMS_DEBUG=TRUE
「人間の顔」を例として主な構成要素を分析します。
$ pip install -r Requirements.txt
$ python demo.pyステータスステートメントを更新しました。
ユーザーの声:
データはウィキデータ コーパスに基づいて構築されています。
「同義語慈林」は 1983 年に Mei Jiaju らによって編纂されました。現在最も広く使用されているバージョンは、ハルビン工業大学ソーシャル コンピューティングおよび情報検索研究センターが管理する「同義語慈林拡張版」で、中国語の語彙を細かく分割しています。カテゴリとサブカテゴリによって単語間の関係が分類されます。Synonyms Cilin の拡張版には 70,000 語以上の単語が含まれており、そのうち 30,000 語以上がオープン データの形式で共有されています。
HowNet (HowNet とも呼ばれます) は、単なる意味辞書ではなく、単語間の関係がその基本的な使用シナリオの 1 つです。 CNKI には 8 単語以上が含まれています。
単語類似度アルゴリズムの国際評価基準は、一般的にMiller&Charles社が公開している英単語ペアセットの手動判定値を採用しています。単語ペアのセットは、関連性の高い英単語ペア 10 組、関連性が中程度の英単語ペア 10 組、関連性の低い英単語ペア 10 組で構成され、38 人の被験者にこれら 30 組の意味的関連性を判断してもらい、最終的に平均値を取得します。値は手動基準として機能します。次に、さまざまな同義語ツールもこれらの単語の類似性をスコアリングし、ピアソン相関係数を使用するなどの手動の判断基準と比較します。中国語の分野では、この語彙リストの翻訳版を使用して中国語の同義語を比較することも一般的な方法です。
Synonyms の語彙リスト容量は 435,729 です。以下では、Synonyms Cilin、CNKI、および Synonyms に存在するいくつかの単語を選択して、その類似性を比較します。
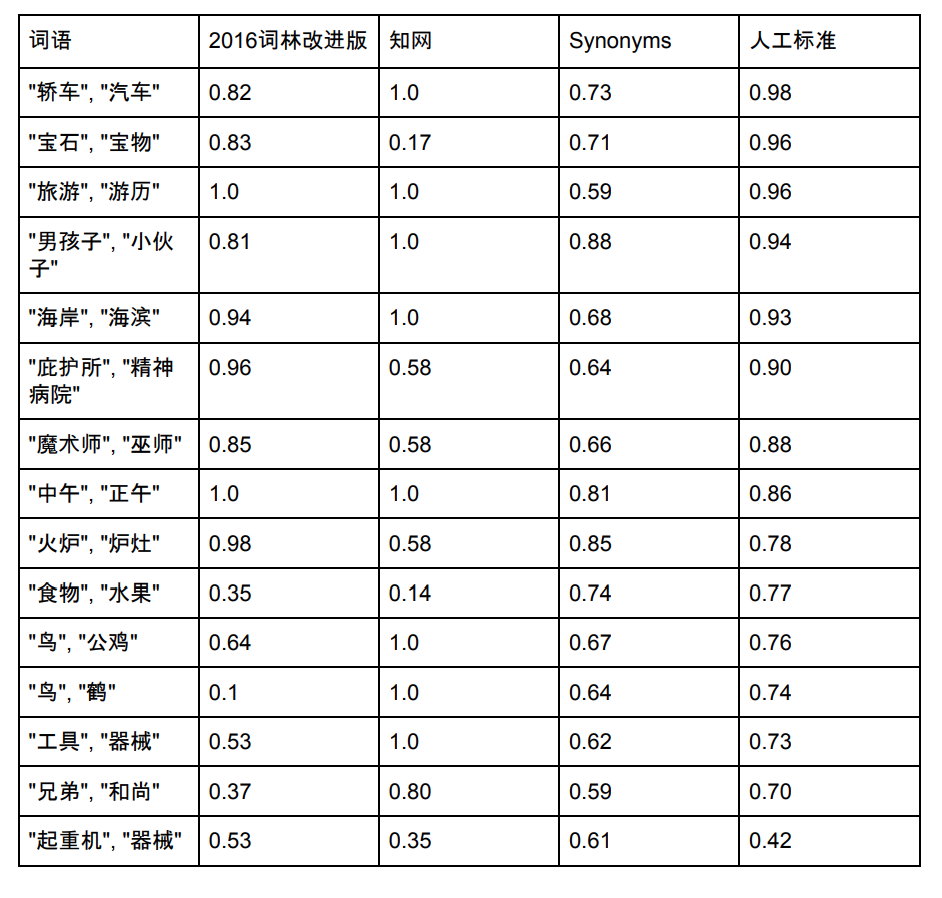
注: シノニム フォレストと CNKI のデータとスコアのソース。同義語も常に最適化されており、新しいスコアは上の図と一致しない可能性があります。
さらなる比較結果。
Github関連ユーザーリスト
py3、MacBook Pro でテストします。
python benchmark.py
++++++++++ OS名とバージョン ++++++++++
プラットフォーム: ダーウィン
カーネル: 16.7.0
アーキテクチャ: ('64 ビット', '')
++++++++++ CPU コア ++++++++++
コア: 4
CPU負荷: 60
++++++++++ システムメモリ ++++++++++
メモリインフォ 8GB
synonyms#nearby: 100000 loops, best of 3 epochs: 0.209 usec per loop
52nlp.cn
機械の心臓部
オンライン共有記録: 同義語中国語同義語ツールキット @ 2018-02-07
Synonyms は証明書 MIT を発行します。データと手順は研究や商業製品で使用される場合があり、出版されたメディア、ジャーナル、雑誌、ブログなどで引用され、言及される必要があります。
@online{Synonyms:hain2017,
author = {Hai Liang Wang, Hu Ying Xi},
title = {中文近义词工具包Synonyms},
year = 2017,
url = {https://github.com/chatopera/Synonyms},
urldate = {2017-09-27}
}
ウィキデータコーパス
word2vec 原理の導出とコード分析
サポートされていません。詳細については #5 を参照してください。
Google がリリースした Word2vec は C 言語で書かれたライブラリで、メモリ使用効率が高く、学習速度が速いです。 gensim は word2vec が出力したモデルファイルを読み込むことができます。
詳細については #64 を参照してください
王海良
胡英熙
この本は、Synonyms の著者によって共著されました。
クイック書籍購入リンク
「インテリジェントな質問応答とディープラーニング」 この本は、機械学習と自然言語処理を始める準備をしている学生とソフトウェア エンジニアを対象としており、理論上の多くの原理とアルゴリズムを紹介し、実用性を高めるためのサンプル プログラムも多数提供しています。これらのプログラムは、主に原理とアルゴリズムを理解するのに役立つようにサンプル プログラム コード ライブラリにまとめられていますので、ダウンロードして実行してください。コードベースのアドレスは次のとおりです。
https://github.com/l11x0m7/book-of-qna-code
Google の Word2vec
ウィキメディア: トレーニング コーパスのソース
gensim: word2vec.py
SentenceSim: 類似性評価コーパス
jieba: 中国語の単語の分割
Chunsong パブリック ライセンス、バージョン 1.0
https://bot.chatopera.com/
Chatoperaクラウドサービスは、チャットロボットをワンストップで導入できるクラウドサービスで、インターフェースの呼び出し回数に応じて課金されます。 Chatopera Cloud Service は、Chatopera ボット プラットフォームの Software-as-a-Service インスタンスです。 Chatopera クラウド サービスは、クラウド コンピューティングに基づいたサービスとしてのチャットボットクラウド サービスです。
Chatopera ロボット プラットフォームには、ナレッジ ベース、マルチラウンド ダイアログ、意図認識と音声認識、標準化されたチャット ロボット開発などのコンポーネントが含まれており、エンタープライズ OA インテリジェント Q&A、HR インテリジェント Q&A、インテリジェント カスタマー サービス、オンライン マーケティングなどのシナリオをサポートします。企業の IT 部門とビジネス部門は Chatopera クラウド サービスを使用して、チャットボットを迅速にオンラインにします。


