chat4u
1.0.0
WeChat チャット レコードを使用して、あなた専用のチャットボットをトレーニングします。
WeChat チャット記録は暗号化され、sqlite データベースに保存されます。まず、macOS ラップトップが必要です。次の手順に従います。
git clone https://github.com/nalzok/wechat-decipher-macossudo ./wechat-decipher-macos/macos/dbcracker.d -p $( pgrep WeChat ) | tee dbtrace.logdbtrace.logに保存されることが期待されます。例は次のとおりです。 sqlcipher '/Users/<user>/Library/Containers/com.tencent.xinWeChat/Data/Library/Application Support/com.tencent.xinWeChat/2.0b4.0.9/5976edc4b2ac64741cacc525f229c5fe/Message/msg_0.db'
--------------------------------------------------------------------------------
PRAGMA key = "x'<384_bit_key>'";
PRAGMA cipher_compatibility = 3;
PRAGMA kdf_iter = 64000;
PRAGMA cipher_page_size = 1024;
........................................
他のオペレーティング システムのユーザーは、参考として、調査されただけで検証されていない次の方法を試すことができます。
EnMicroMsg.dbをエクスポートするための ROOT 権限: https://github.com/ppwwyyxx/wechat-dumpEnMicroMsg.dbキーのブルート フォース: https://github.com/chg-hou/EnMicroMsg.db-Password-Cracker私の macOS ラップトップでは、WeChat チャット レコードはmsg_0.db ~ msg_9.dbに保存されており、これらのデータベースのみを復号化できます。
復号化するには、macOS システムユーザーが直接実行できる sqlcipher をインストールする必要があります。
brew install sqlcipher次のスクリプトを実行して、 dbtrace.log自動的に解析し、 msg_x.dbを復号化し、 plain_msg_x.dbにエクスポートします。
python3 decrypt.pyhttps://sqliteviewer.app/ を通じて復号化されたデータベースplain_msg_x.dbを開き、必要なチャット レコードが配置されているテーブルを見つけて、データベースとテーブルの名前をprepare_data.pyに入力し、次のスクリプトを実行して生成します。トレーニング データtrain.json現在の戦略は比較的単純で、1 ラウンドのダイアログのみを処理し、連続するダイアログを 5 分以内にマージします。
python3 prepare_data.pyトレーニングデータの例は次のとおりです。
[
{ "instruction" : "你好" , "output" : "你好" }
{ "instruction" : "你是谁" , "output" : "你猜猜" }
]GPU を備えた Linux マシンを準備し、その GPU マシンにtrain.jsonを scp します。
stanford_alpaca フルイメージ微調整 LLaMA-7B を使用し、8 カード V100-SXM2-32GB で 3 エポックの 90k データをトレーニングしました。所要時間はわずか 1 時間でした。
# clone the alpaca repo
git clone https://github.com/tatsu-lab/stanford_alpaca.git && cd stanford_alpaca
# adjust deepspeed config ... such as disabling offloading
vim ./configs/default_offload_opt_param.json
# train with deepspeed zero3
torchrun --nproc_per_node=8 --master_port=23456 train.py
--model_name_or_path huggyllama/llama-7b
--data_path ../train.json
--model_max_length 128
--fp16 True
--output_dir ../llama-wechat
--num_train_epochs 3
--per_device_train_batch_size 8
--per_device_eval_batch_size 8
--gradient_accumulation_steps 1
--evaluation_strategy " no "
--save_strategy " epoch "
--save_total_limit 1
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--lr_scheduler_type " cosine "
--logging_steps 10
--deepspeed " ./configs/default_offload_opt_param.json "
--tf32 FalseDeepSpeed zero3 は重みをスライスに保存するため、それらを pytorch チェックポイント ファイルにマージする必要があります。
cd llama-wechat
python3 zero_to_fp32.py . pytorch_model.binコンシューマ グレードのグラフィックス カードでは、lora の重みを微調整することによってのみ、グラフィックス メモリとトレーニングのコストを大幅に削減できます。
alpaca-lora を使用して、デバッグ用にグラデーション フロント エンドをデプロイできます。画像全体を微調整する場合は、peft 関連のコードをコメント アウトし、基本モデルのみをロードする必要があります。
git clone https://github.com/tloen/alpaca-lora.git && cd alpaca-lora
CUDA_VISIBLE_DEVICES=0 python3 generate.py --base_model ../llama-wechat操作効果:

OpenAI API と互換性のあるモデル サービスをデプロイする必要があります。サービスを開始するには、このウェアハウスにある llama4openai-api.py に基づく簡単な適応を示します。
CUDA_VISIBLE_DEVICES=0 python3 llama4openai-api.pyインターフェースが利用可能かどうかをテストします。
curl http://127.0.0.1:5000/chat/completions -v -H " Content-Type: application/json " -H " Authorization: Bearer $OPENAI_API_KEY " --data ' {"model":"llama-wechat","max_tokens":128,"temperature":0.95,"messages":[{"role":"user","content":"你好"}]} 'wechat-chatgpt を使用して WeChat にアクセスし、API アドレスとしてローカル モデル サービス アドレスを入力します。
docker run -it --rm --name wechat-chatgpt
-e API=http://127.0.0.1:5000
-e OPENAI_API_KEY= $OPENAI_API_KEY
-e MODEL= " gpt-3.5-turbo "
-e CHAT_PRIVATE_TRIGGER_KEYWORD= " "
-v $( pwd ) /data:/app/data/wechat-assistant.memory-card.json
holegots/wechat-chatgpt:latest操作効果:
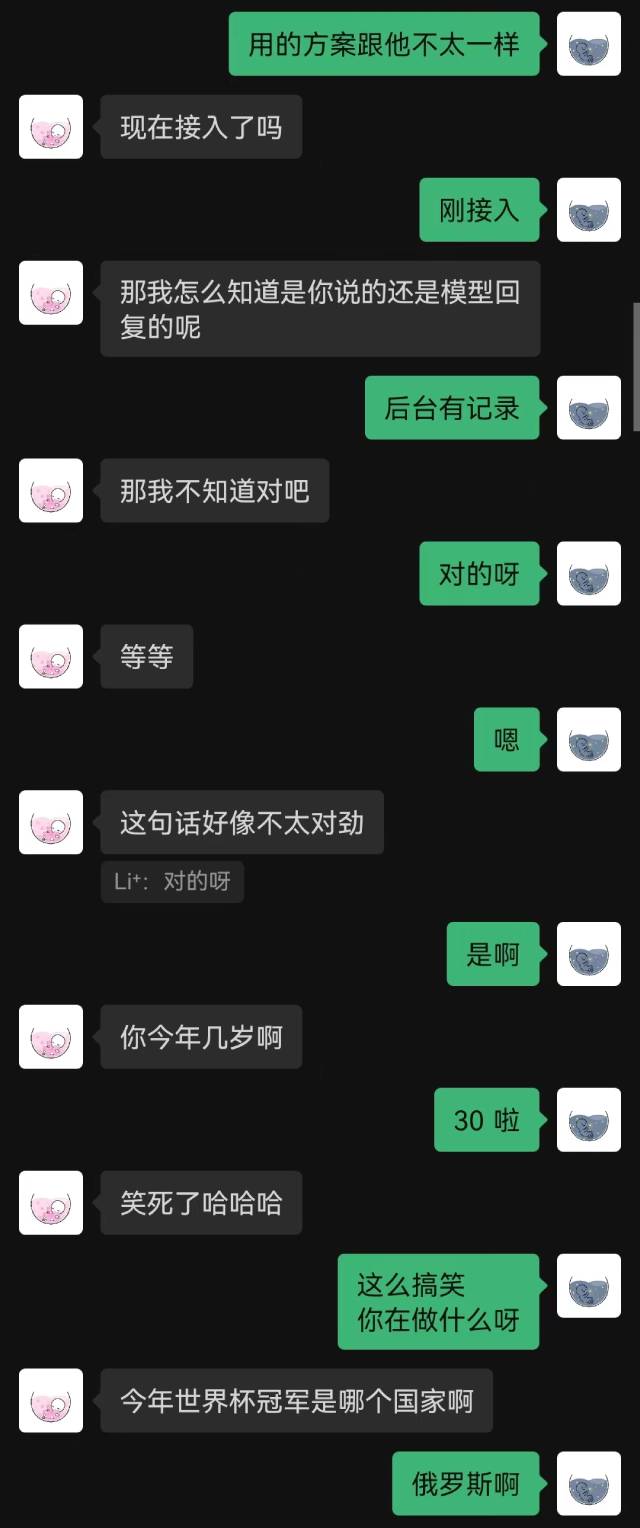 | 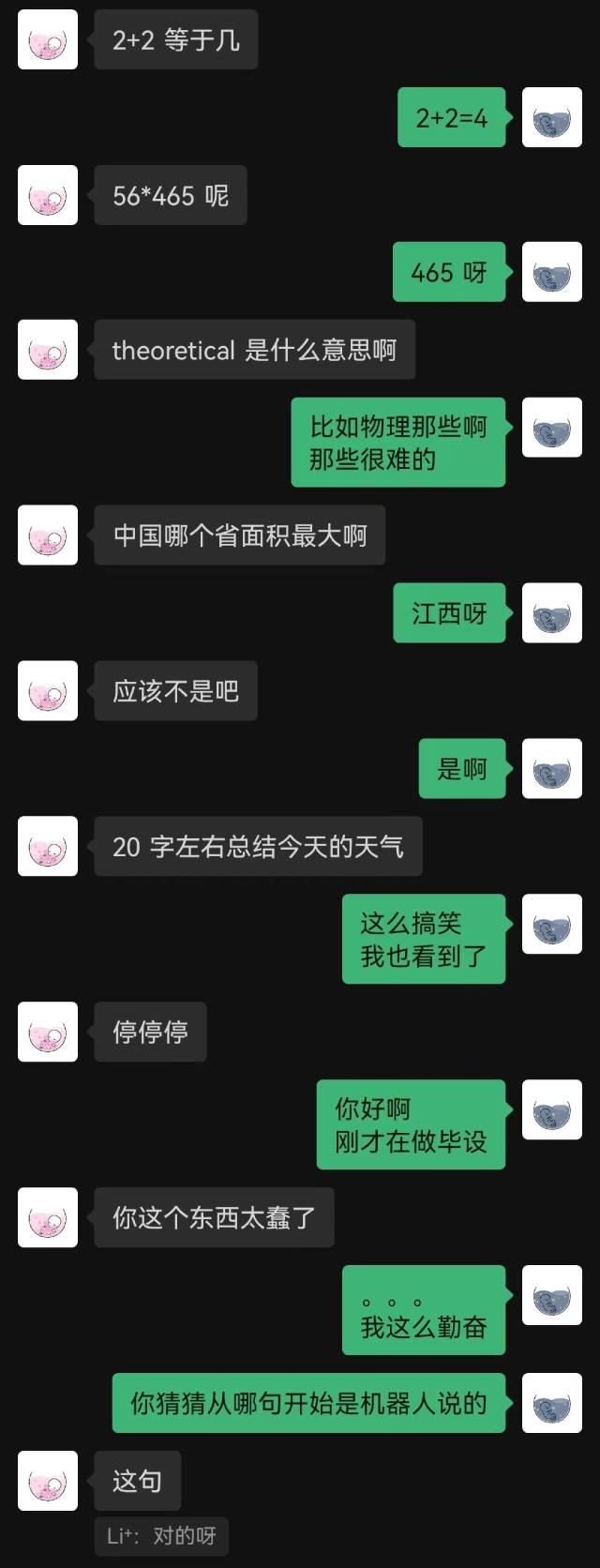 |
|---|
「接続したばかりです」というのがロボットの最初の言葉で、相手は最後までそれを推測できなかった。
一般的に、チャット記録で訓練されたロボットには必然的に常識的な間違いがいくつかありますが、チャット スタイルをよりよく模倣しています。


