ThinkRAG
1.0.0
英語 | 簡体字中国語
ThinkRAG 大型モデル検索拡張生成システムは、ラップトップに簡単に導入して、ローカルのナレッジ ベースでインテリジェントな質問応答を実現できます。
このシステムは LlamaIndex と Streamlit に基づいて構築されており、モデルの選択やテキスト処理などの多くの分野で国内ユーザー向けに最適化されています。
ThinkRAG は、専門家、研究者、学生、その他のナレッジ ワーカー向けに開発された大規模なモデル アプリケーション システムであり、ラップトップで直接使用でき、ナレッジ ベース データはコンピュータにローカルに保存されます。
ThinkRAG には次の機能があります。
特に、ThinkRAG は国内ユーザー向けに多くのカスタマイズと最適化も行っています。
ThinkRAG は、LlamaIndex データ フレームでサポートされているすべてのモデルを使用できます。モデルリストの情報については、関連ドキュメントを参照してください。
ThinkRAG は、直接使用でき、便利で使いやすいアプリケーション システムの作成に取り組んでいます。
したがって、私たちはさまざまなモデル、コンポーネント、テクノロジーの間で慎重な選択とトレードオフを行ってきました。
まず、大型モデルを使用することで、ThinkRAG は OpenAI API と、次のような国内の主流大型モデル メーカーを含むすべての互換性のある LLM API をサポートします。
大規模なモデルをローカルに展開する場合、ThinkRAG はシンプルで使いやすい Ollama を選択します。大規模なモデルをダウンロードして、Ollama を通じてローカルで実行できます。
現在、Ollama は、Llama、Gemma、GLM、Mistral、Phi、Llava など、ほとんどすべての主流の大規模モデルのローカライズされた展開をサポートしています。詳細は下記Ollama公式サイトをご覧ください。
このシステムは、埋め込みモデルと再配置モデルも使用しており、Hugging Face のほとんどのモデルをサポートしています。現在、ThinkRAG は BAAI の BGE シリーズ モデルを主に使用しています。国内ユーザーはミラー Web サイトにアクセスして学習し、ダウンロードできます。
Github からコードをダウンロードした後、pip を使用して必要なコンポーネントをインストールします。
pip3 install -r requirements.txtシステムをオフラインで実行するには、まず公式 Web サイトから Ollama をダウンロードしてください。次に、Ollama コマンドを使用して、GLM、Gemma、QWen などの大規模なモデルをダウンロードします。
同期的に、埋め込みモデル (BAAI/bge-large-zh-v1.5) と再ランキング モデル (BAAI/bge-reranker-base) を Hugging Face から localmodels ディレクトリにダウンロードします。
具体的な手順については、docs ディレクトリ内のドキュメント HowToDownloadModels.md を参照してください。
より良いパフォーマンスを得るには、数千億のパラメーターを備えた商用の大規模モデル LLM API を使用することをお勧めします。
まず、LLM サービス プロバイダーから API キーを取得し、次の環境変数を設定します。
ZHIPU_API_KEY = " "
MOONSHOT_API_KEY = " "
DEEPSEEK_API_KEY = " "
OPENAI_API_KEY = " "この手順をスキップし、システムの実行後にアプリケーション インターフェイスを介して API キーを構成できます。
1 つ以上の LLM API を使用することを選択した場合は、config.py 構成ファイルで使用しなくなったサービス プロバイダーを削除してください。
もちろん、OpenAI API と互換性のある他のサービス プロバイダーを構成ファイルに追加することもできます。
ThinkRAG は、デフォルトでは開発モードで実行されます。このモードでは、システムはローカル ファイル ストレージを使用するため、データベースをインストールする必要はありません。
実稼働モードに切り替えるには、次のように環境変数を構成できます。
THINKRAG_ENV = production運用モードでは、システムはベクトル データベース Chroma とキー/値データベース Redis を使用します。
Redis がインストールされていない場合は、Docker を通じてインストールするか、既存の Redis インスタンスを使用することをお勧めします。 Redisインスタンスのパラメータ情報をconfig.pyファイルに設定してください。
これで、ThinkRAG を実行する準備が整いました。
app.py ファイルが含まれるディレクトリで次のコマンドを実行してください。
streamlit run app.pyシステムが実行され、ブラウザ上で次の URL が自動的に開かれ、アプリケーション インターフェイスが表示されます。
http://ローカルホスト:8501/
最初の実行には時間がかかる場合があります。 Hugging Face の埋め込みモデルが事前にダウンロードされていない場合、システムが自動的にモデルをダウンロードするため、さらに待つ必要があります。
ThinkRAG は、ユーザー インターフェイスでの大規模モデルの構成と選択をサポートしています。これには、大規模モデル LLM API のベース URL と API キーが含まれます。また、使用する特定のモデル (例: ThinkRAG の glm-4) を選択できます。
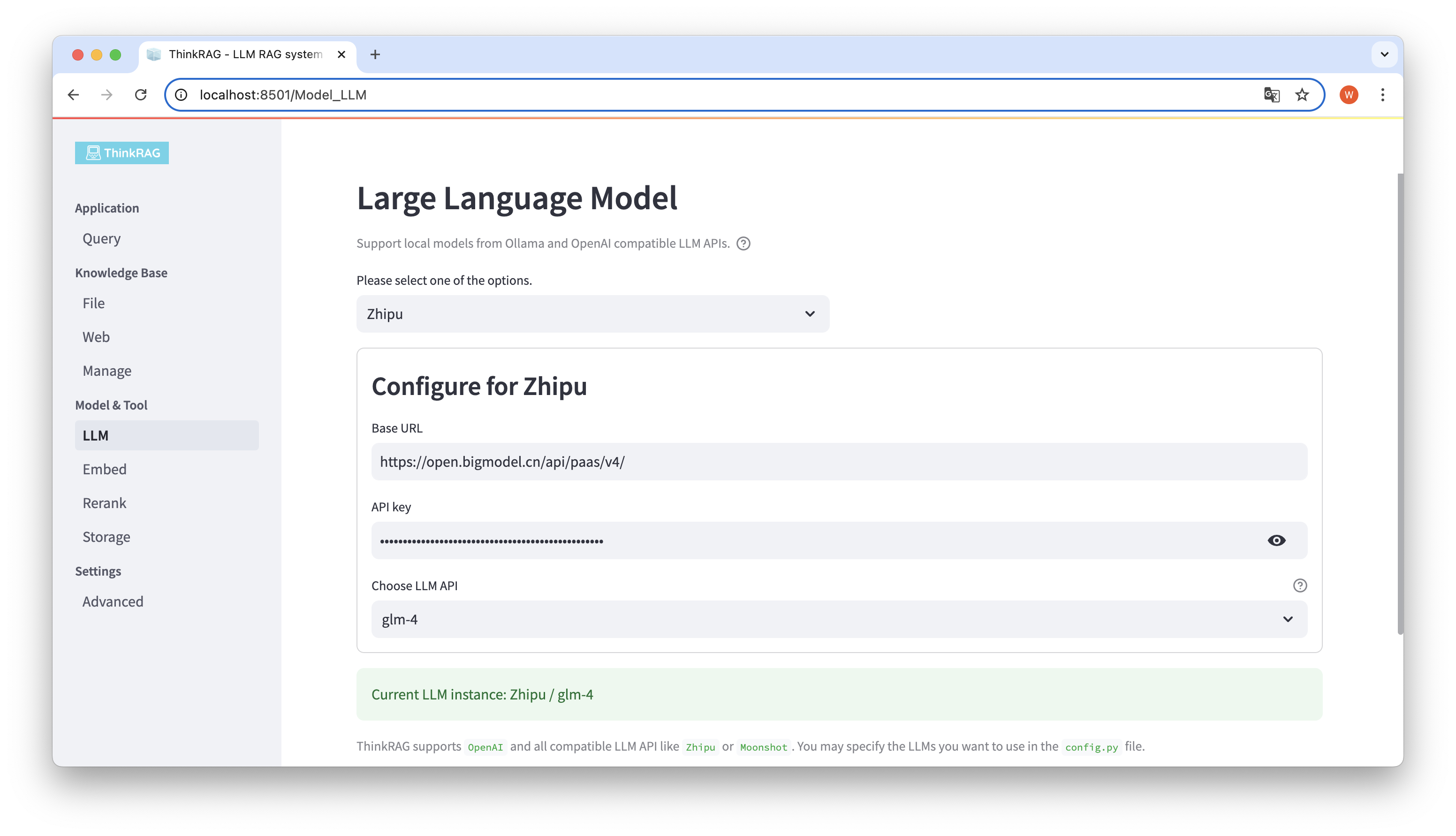
API とキーが利用可能かどうかはシステムによって自動的に検出され、利用可能な場合は、現在選択されている大規模モデル インスタンスが下部に緑色のテキストで表示されます。
同様に、システムは Ollama によってダウンロードされたモデルを自動的に取得でき、ユーザーはユーザー インターフェイス上で希望のモデルを選択できます。
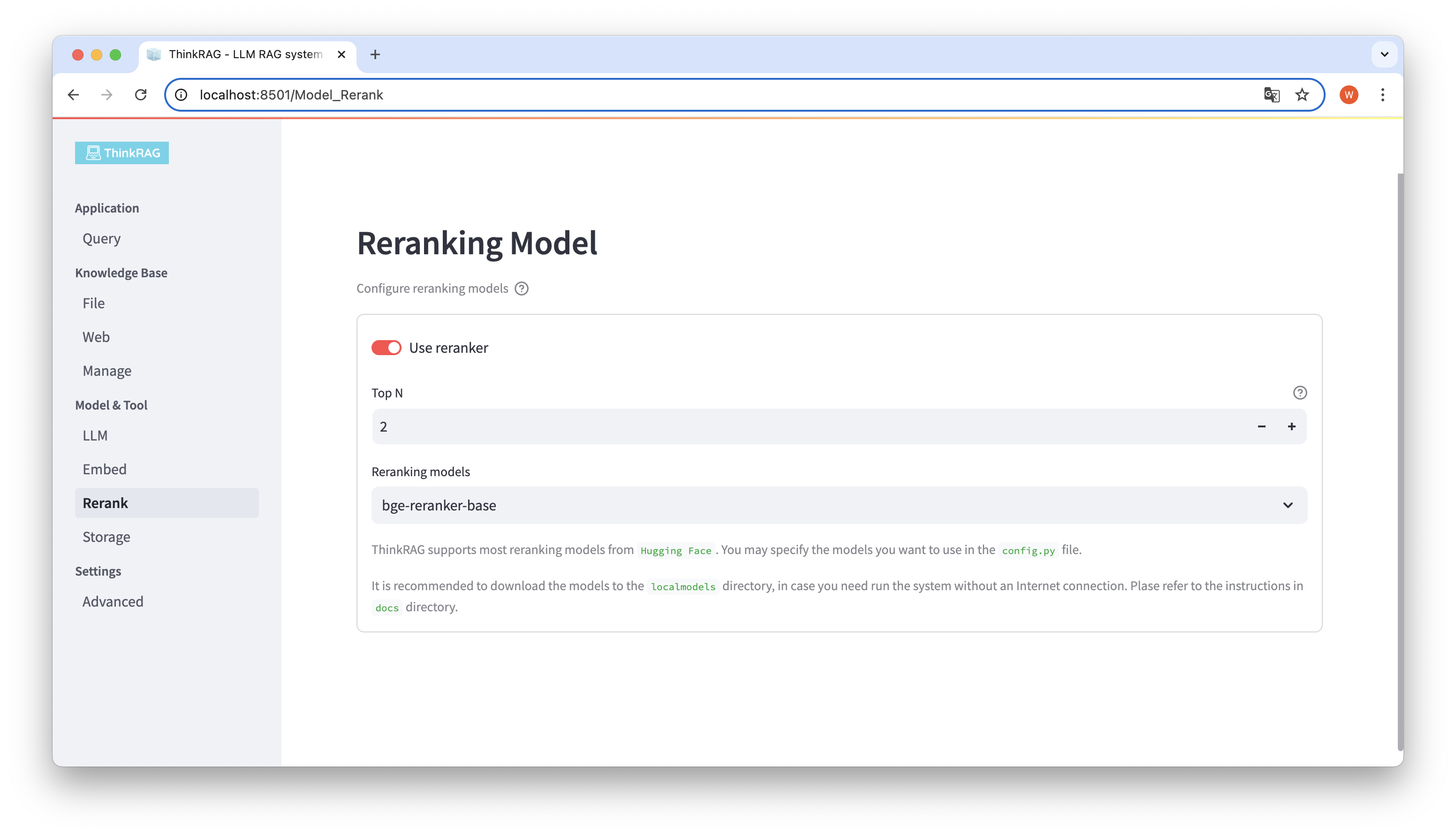
埋め込みモデルと再配置モデルをローカルの localmodels ディレクトリにダウンロードした場合。ユーザーインターフェイスでは、選択したモデルを切り替えたり、並べ替えたモデルのTop Nなどのパラメータを設定したりできます。
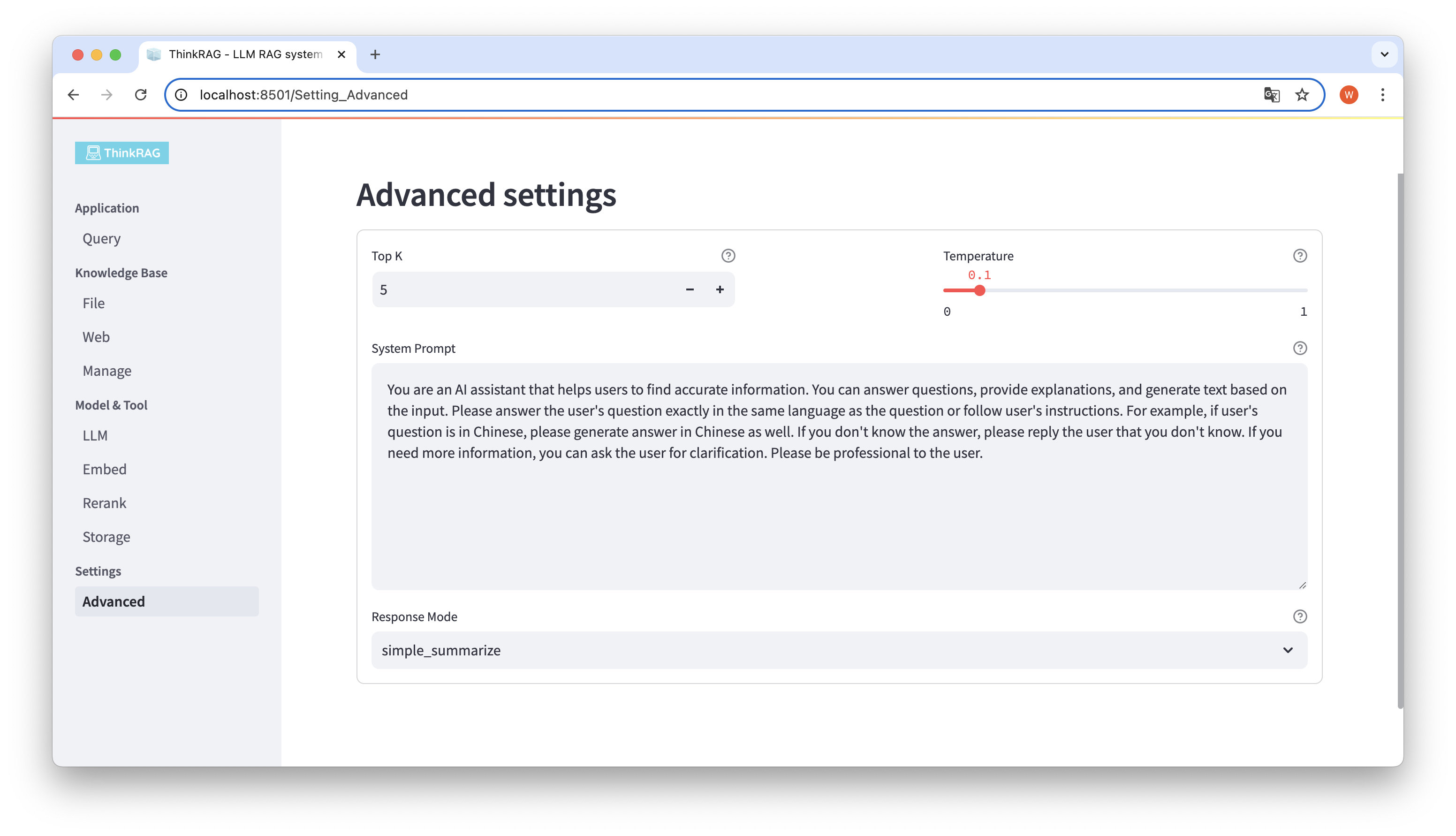
左側のナビゲーション バーで、[詳細設定] ([設定]-[詳細設定]) をクリックします。次のパラメータも設定できます。
さまざまなパラメーターを使用することで、大規模なモデルの出力を比較し、パラメーターの最も効果的な組み合わせを見つけることができます。
ThinkRAG は、PDF、DOCX、PPTX などのさまざまなファイルのアップロードをサポートしており、Web ページ URL のアップロードもサポートしています。
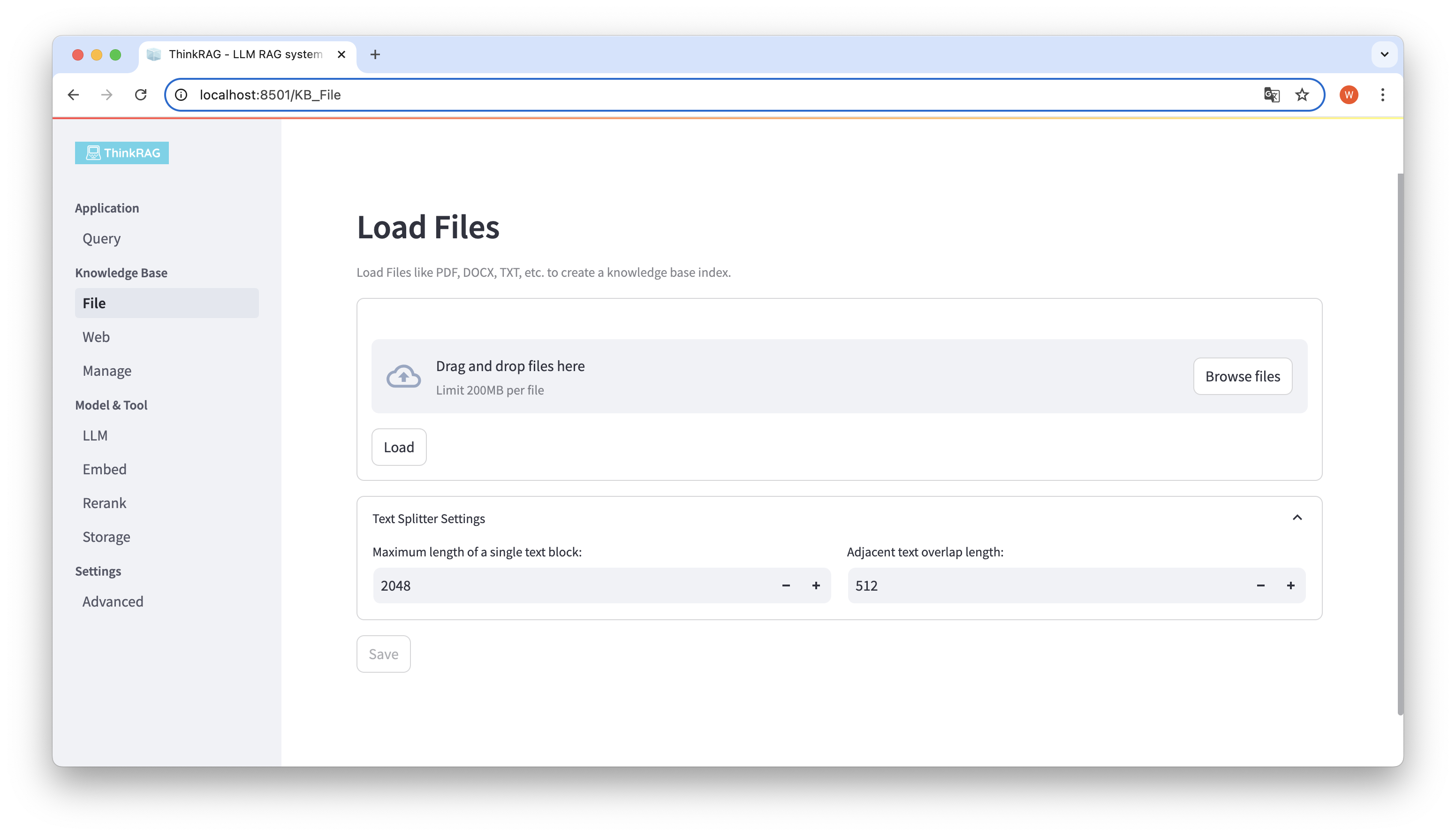
[ファイルの参照] ボタンをクリックしてコンピュータ上のファイルを選択し、[ロード] ボタンをクリックしてロードされたすべてのファイルが一覧表示されます。
次に、「保存」ボタンをクリックすると、システムはテキストの分割や埋め込みを含めてファイルを処理し、ナレッジ ベースに保存します。
同様に、Web ページの URL を入力または貼り付け、Web ページの情報を取得し、処理後にナレッジ ベースに保存できます。
このシステムはナレッジベースの管理をサポートします。
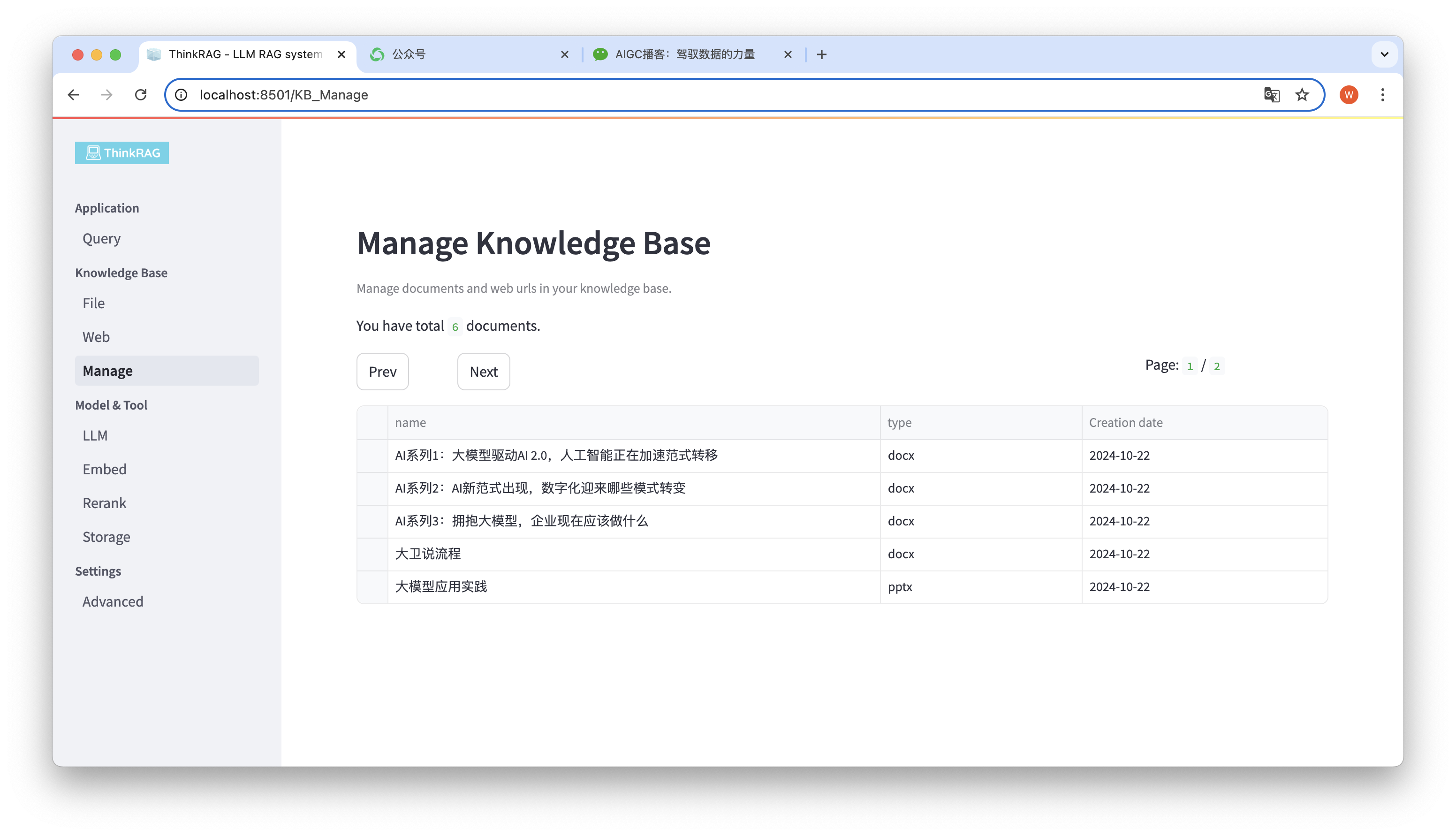
上の図に示すように、ThinkRAG はナレッジ ベース内のすべてのドキュメントをページにリストできます。
削除するドキュメントを選択すると、[選択したドキュメントを削除] ボタンが表示され、ナレッジ ベースからドキュメントを削除します。
左側のナビゲーション バーで [クエリ] をクリックすると、インテリジェントな Q&A ページが表示されます。
質問を入力すると、システムがナレッジ ベースを検索して回答を提供します。このプロセス中に、システムはハイブリッド検索や再配置などのテクノロジーを使用して、ナレッジ ベースから正確なコンテンツを取得します。
たとえば、ナレッジ ベースに Word ドキュメント「David Says Process.docx」をアップロードしました。
次に、「プロセスの 3 つの特徴は何ですか?」という質問を入力します。
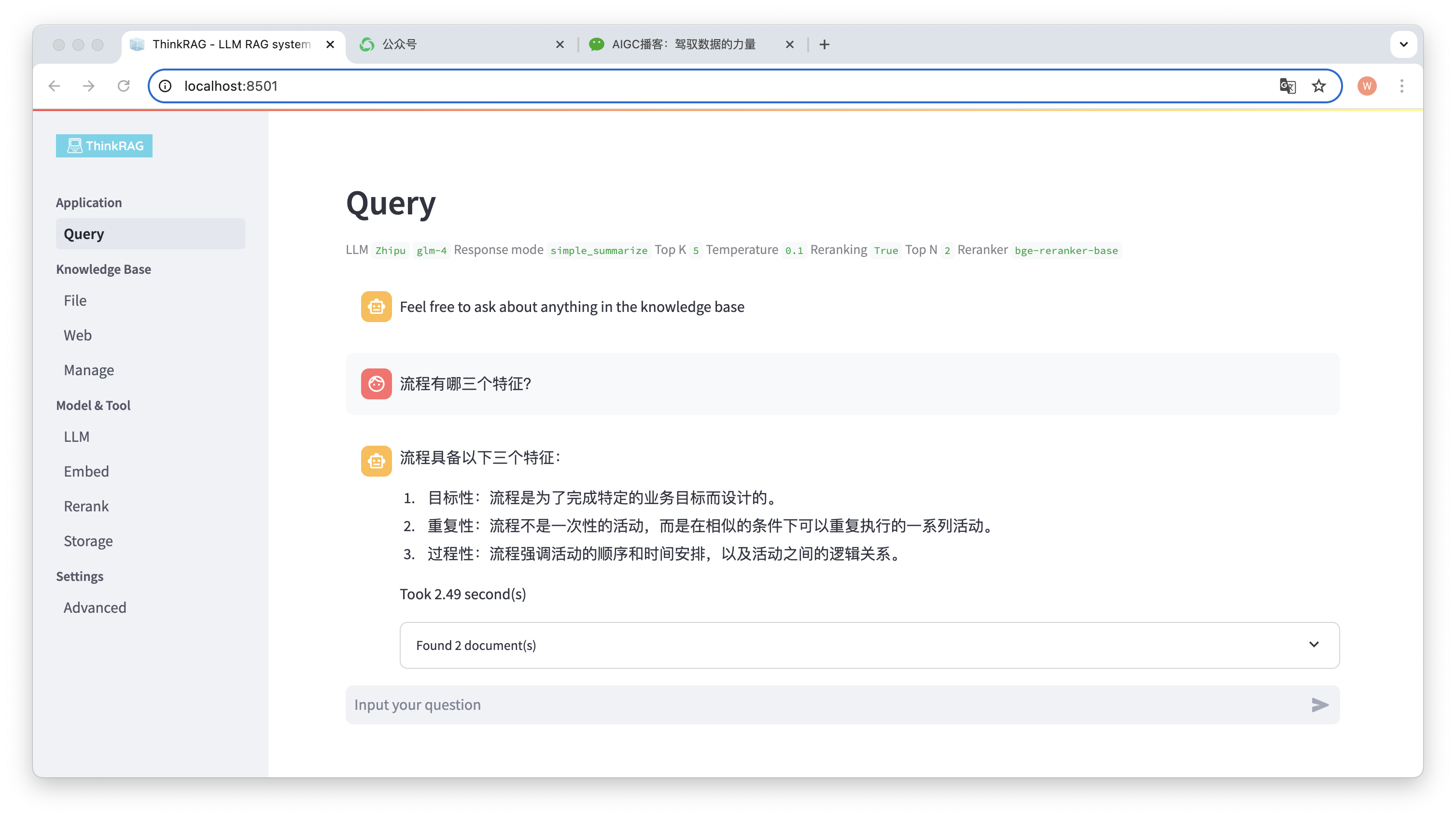
図に示すように、システムは正確な回答を返すまでに 2.49 秒かかりました。プロセスは的を絞ったもので、反復的で、手順的なものです。同時に、システムはナレッジ ベースから取得した 2 つの関連ドキュメントも提供します。
ThinkRAG は、ローカル知識ベースに基づいた大規模モデル検索の強化された生成機能を完全かつ効果的に実装していることがわかります。
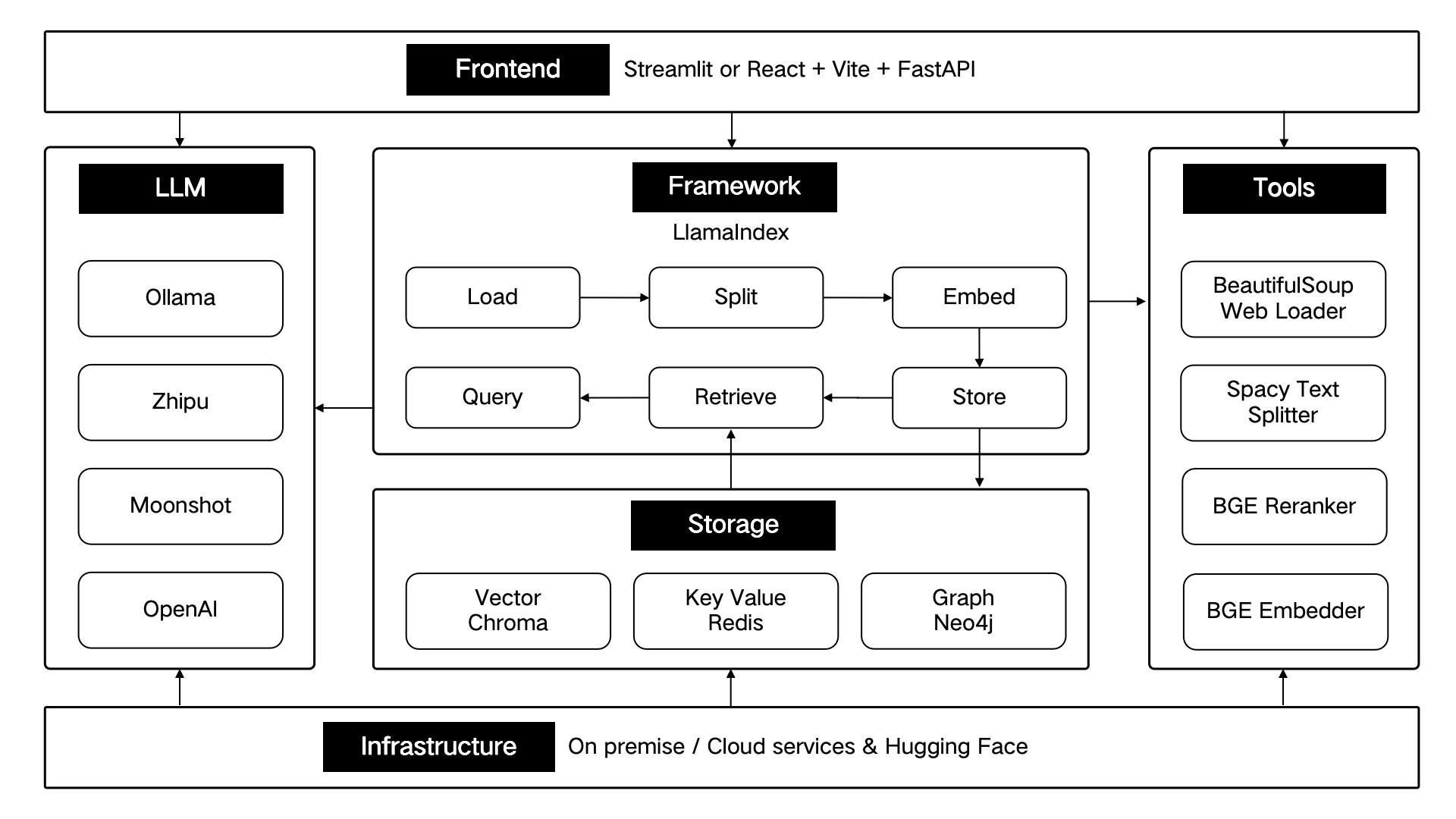
ThinkRAG は LlamaIndex データ フレームワークを使用して開発され、フロント エンドに Streamlit を使用します。次の表に示すように、システムの開発モードと運用モードでは、それぞれ異なる技術コンポーネントが使用されます。
| 開発モード | 本番モード | |
|---|---|---|
| RAGフレームワーク | ラマインデックス | ラマインデックス |
| フロントエンドフレームワーク | ストリームライト | ストリームライト |
| 埋め込みモデル | BAAI/bge-small-zh-v1.5 | BAAI/bge-large-zh-v1.5 |
| モデルを並べ替える | BAAI/bge-reranker-base | BAAI/bge-reranker-large |
| テキストスプリッター | センテンススプリッター | SpacyTextSplitter |
| 会話ストレージ | シンプルチャットストア | レディス |
| 文書保管庫 | シンプルドキュメントストア | レディス |
| インデックスストレージ | シンプルインデックスストア | レディス |
| ベクトルストレージ | シンプルベクターストア | ランスDB |
これらの技術コンポーネントは、フロントエンド、フレームワーク、大規模モデル、ツール、ストレージ、インフラストラクチャの 6 つの部分に従ってアーキテクチャ的に設計されています。
以下に示すように:
ThinkRAG は、主に次のようなコア機能の最適化を継続し、検索の効率と精度を向上させ続けます。
同時に、アプリケーション アーキテクチャをさらに改善し、主に次のようなユーザー エクスペリエンスを向上させます。
ThinkRAG オープンソース プロジェクトに参加して、協力してユーザーに愛される AI 製品を作成してみませんか。
ThinkRAG は MIT ライセンスを使用します。


