local LLM with RAG
1.0.0

このプロジェクトは、Ollama を使用してローカルの大規模言語モデル (LLM) を実行し、サンプル PDF に基づいて質問に答えるための検索拡張生成 (RAG) を実行することに関連するアイデアをテストするための実験的なサンドボックスです。このプロジェクトでは、Ollama を使用して、Chroma で使用する nomic-embed-text による埋め込みを作成します。埋め込みはアプリケーションが実行されるたびに再ロードされますが、これは効率的ではなく、ここではテスト目的でのみ行われることに注意してください。
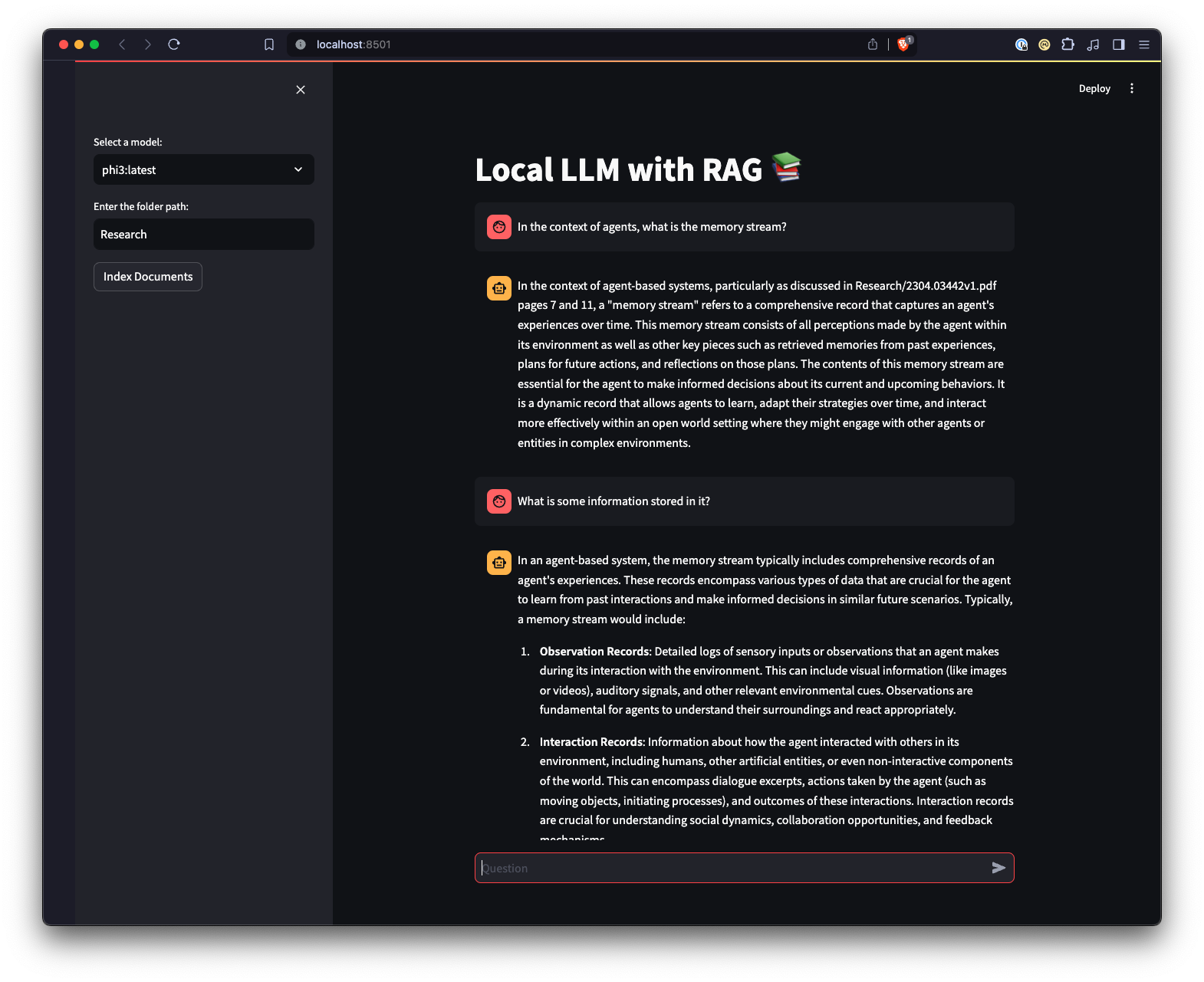
Ollama と対話する別の方法を提供するために、Streamlit を使用して作成された Web UI もあります。
python3 -m venv .venvを実行して、Python 仮想環境を作成します。source .venv/bin/activate実行するか、Windows では..venvScriptsactivateして、仮想環境をアクティブにします。pip install -r requirements.txtを実行して、必要な Python パッケージをインストールします。 注:プロジェクトを初めて実行すると、LLM と埋め込みに必要なモデルが Ollama からダウンロードされます。これは 1 回限りのセットアップ プロセスであり、インターネット接続によっては時間がかかる場合があります。
python app.py -m <model_name> -p <path_to_documents>を使用してメイン スクリプトを実行し、モデルとドキュメントへのパスを指定します。モデルが指定されていない場合は、デフォルトで mistral が使用されます。パスが指定されていない場合は、例として、デフォルトでリポジトリにあるResearchが使用されます。-e <embedding_model_name>で使用する埋め込みモデルを指定できます。指定しない場合、デフォルトの nomic-embed-text が使用されます。これにより、PDF と Markdown ファイルがロードされ、埋め込みが生成され、コレクションがクエリされ、 app.pyで定義された質問に答えます。
ui.pyスクリプトが含まれるディレクトリに移動します。streamlit run ui.pyを実行して、Streamlit アプリケーションを実行します。これにより、ローカル Web サーバーが起動し、アプリケーションを操作できる新しいタブがデフォルトの Web ブラウザーに開きます。 Streamlit UI を使用すると、モデルの選択、フォルダーの選択が可能になり、コマンドライン インターフェイスと比較して、RAG チャットボット システムと対話するためのより簡単かつ直感的な方法が提供されます。アプリケーションは、ドキュメントのロード、埋め込みの生成、コレクションのクエリ、および結果の対話形式の表示を処理します。


