Okapi
1.0.0
オカピ
人間のフィードバックからの強化学習を使用した、複数言語での命令調整された大規模言語モデル
これは、複数の言語でのヒューマン フィードバックからの強化学習 (RLHF) による大規模言語モデル (LLM) の命令チューニングのためのリソースとモデルを紹介する、Okapi フレームワークのリポジトリです。私たちのフレームワークは、8 つの高リソース言語、11 の中程度のリソース言語、7 つの低リソース言語を含む 26 の言語をサポートしています。
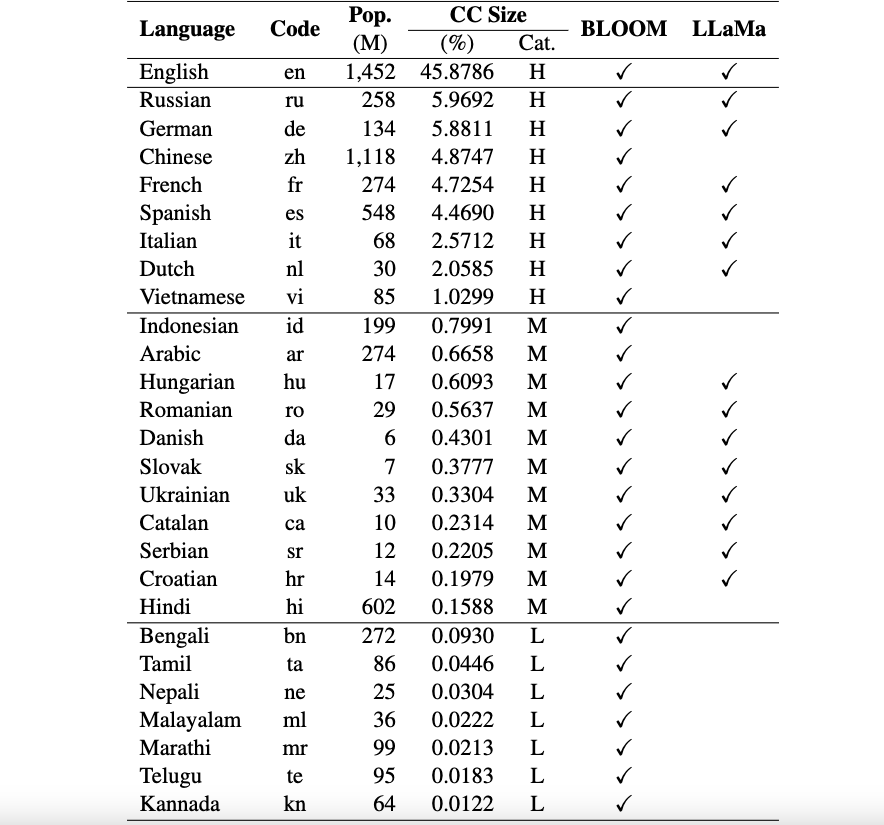
okapi リソース: ChatGPT プロンプト、多言語命令データセット、多言語応答ランキング データなど、26 言語の RLHF を使用した命令チューニングを実行するためのリソースを提供します。
okapi モデル:Okapi データセット上の 26 言語向けに、RLHF ベースの命令調整された LLM を提供します。当社のモデルには、BLOOM ベースのバージョンと LLaMa ベースのバージョンの両方が含まれています。また、モデルと対話し、リソースを使用して LLM を微調整するためのスクリプトも提供します。
多言語評価ベンチマーク データセット: 26 言語の多言語大規模言語モデル (LLM) を評価するための 3 つのベンチマーク データセットを提供します。ここから完全なデータセットと評価スクリプトにアクセスできます。
使用法とライセンスに関する通知:Okapi は研究用途のみを目的としており、ライセンスが付与されています。データセットは CC BY NC 4.0 (非営利使用のみ許可) であり、データセットを使用してトレーニングされたモデルは研究目的以外に使用しないでください。
評価結果を記載したテクニカルペーパーはこちらからご覧いただけます。
当社は、多言語フレームワークのokapiに必要なデータを準備するために、次の4つの主要なステップで包括的なデータ収集プロセスを実行します。
データセット全体をダウンロードするには、次のスクリプトを使用できます。
bash scripts/download.sh特定の言語のデータのみが必要な場合は、スクリプトへの引数として言語コードを指定できます。
bash scripts/download.sh [LANG]
# For example, to download the dataset for Vietnamese: bash scripts/download.sh viダウンロード後、リリースされたデータはデータセットディレクトリにあります。これには次のものが含まれます。
multilingual-alpaca-52k : Alpaca の 52K の英語命令を 26 言語に翻訳したデータ。
multilingual-ranking-data-42k : 26 言語の多言語応答ランキング データ。言語ごとに 42K の命令が提供されています。それぞれに 4 つのランク付けされた回答があります。このデータは、26 言語の報酬モデルをトレーニングするために使用できます。
multilingual-rl-tuning-64k : RLHF の多言語命令データ。 26 言語ごとに 62K の命令が提供されています。
okapi データセットと RLHF ベースの命令チューニング技術を使用して、LLaMA と BLOOM の 7B バージョンに基づいて構築された 26 言語向けの多言語微調整 LLM を導入します。モデルは、HuggingFace から入手できます。
okapi は、26 言語の多言語命令調整済み LLM との対話型チャットをサポートしています。チャットについては次の手順に従います。
git clone https://github.com/nlp-uoregon/Okapi.git
cd Okapi
pip install -r requirements.txt
from chat import pipeline
model_path = 'uonlp/okapi-vi-bloom'
p = pipeline ( model_path , gpu = True )
instruction = 'Dịch câu sau sang Tiếng Việt' # Translate the following sentence into Vietnamese
prompt_input = 'The City of Eugene - a great city for the arts and outdoors. '
response = p . generate ( instruction = instruction , prompt_input = prompt_input )
print ( response )また、RLHF を使用して指示データで LLM を微調整するためのスクリプトも提供しており、教師あり微調整、報酬モデリング、RLHF による微調整という 3 つの主要なステップをカバーしています。 LLM を微調整するには、次の手順を使用します。
conda create -n okapi python=3.9
conda activate okapi
pip install -r requirements.txtbash scripts/supervised_finetuning.sh [LANG]bash scripts/reward_modeling.sh [LANG]bash scripts/rl_training.sh [LANG]このリポジトリ内のデータ、モデル、またはコードを使用する場合は、以下を引用してください。
@article { dac2023okapi ,
title = { Okapi: Instruction-tuned Large Language Models in Multiple Languages with Reinforcement Learning from Human Feedback } ,
author = { Dac Lai, Viet and Van Nguyen, Chien and Ngo, Nghia Trung and Nguyen, Thuat and Dernoncourt, Franck and Rossi, Ryan A and Nguyen, Thien Huu } ,
journal = { arXiv e-prints } ,
pages = { arXiv--2307 } ,
year = { 2023 }
}

