MoEL
1.0.0


これは論文の PyTorch 実装です。
MoEL: 共感的な聞き手の混合。 Zhaojiang Lin 、Andrea Madotto、Jamin Shin、Peng Xu、Pascale Fung EMNLP 2019 [PDF]
このコードは PyTorch >= 0.4.1 を使用して書かれています。このツールキットに含まれるソース コードまたはデータセットを仕事で使用する場合は、次の論文を引用してください。ビブテックスは以下のとおりです。
@article{lin2019moel,
title={MoEL: 共感的な聞き手の混合},
author={リン、チャオジャンとマドット、アンドレアとシン、ジャミンとシュー、ペンとフォン、パスカル}、
ジャーナル={arXiv プレプリント arXiv:1908.07687},
年={2019}
}
共感対話システムに関するこれまでの研究は、主に、特定の感情が与えられた場合に応答を生成することに焦点を当てていました。ただし、共感するためには、感情的な反応を生成する能力が必要であるだけでなく、さらに重要なことに、ユーザーの感情を理解し、適切に応答する必要があります。この論文では、対話システムにおける共感をモデル化するための新しいエンドツーエンドのアプローチ、Mixture of Empathetic Listeners (MoEL) を提案します。私たちのモデルはまずユーザーの感情を捕捉し、感情分布を出力します。これに基づいて、MoEL は、特定の感情に反応するようにそれぞれ最適化された適切なリスナーの出力状態をソフトに組み合わせ、共感的な応答を生成します。共感対話データセットに対する人による評価では、MoEL が共感、関連性、流暢さの点でマルチタスク トレーニングのベースラインを上回っていることが確認されています。さらに、さまざまなリスナーの生成された応答に関するケーススタディは、私たちのモデルの高い解釈可能性を示しています。
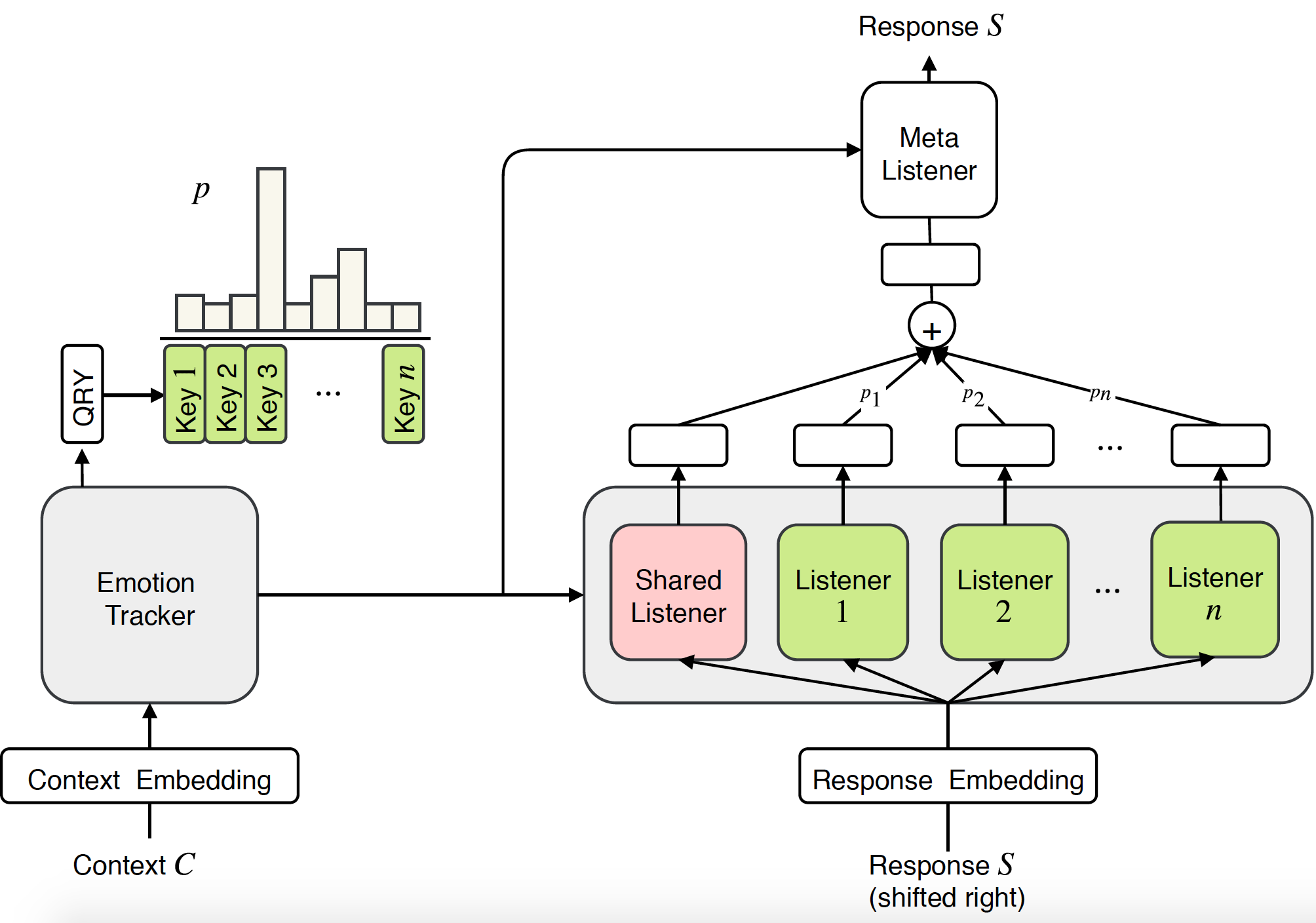
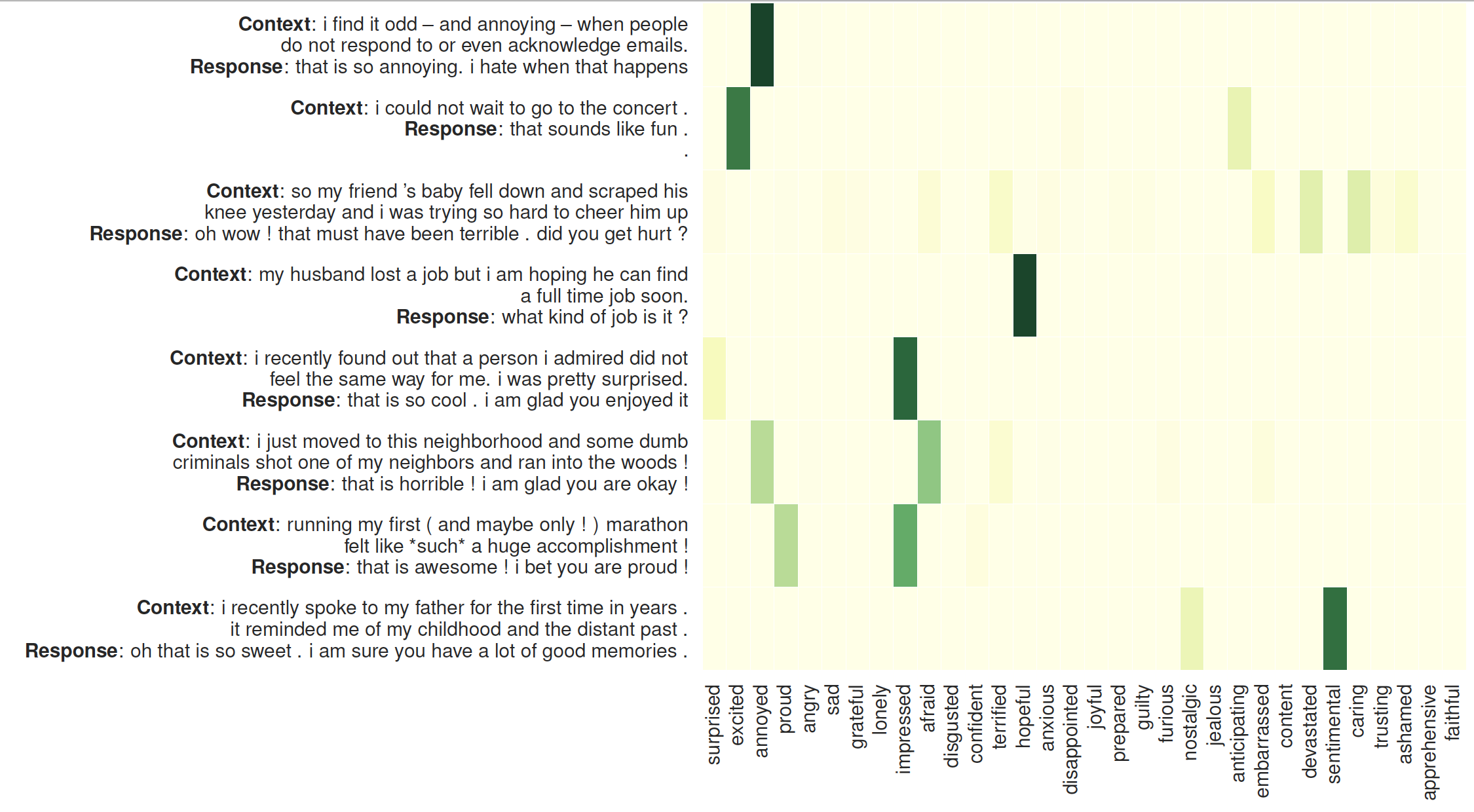
リスナーの注意の視覚化: 左側は、MoEL によって生成された応答が続くコンテキストです。ヒート マップは 32 人のリスナーの注意の重みを示しています
必要なパッケージを確認するか、単にコマンドを実行します
❱❱❱ pip install -r requirements.txt事前トレーニングされたグローブの埋め込み: フォルダー /vectors/ 内のglove.6B.300d.txt 。
クイック結果
トレーニングをスキップするには、 generation_result.txtを確認してください。
データセット
データセット (共感対話) は前処理され、npy 形式で保存されます: sys_dialog_texts.train.npy、sys_target_texts.train.npy、sys_emotion_texts.train.npy。これらはコンテキスト (ソース)、応答 (ターゲット)、および感情ラベルの並列リストで構成されます。 (追加ラベル)。
トレーニングとテスト
MoEL
❱❱❱ python3 main.py --model experts --label_smoothing --noam --emb_dim 300 --hidden_dim 300 --hop 1 --heads 2 --topk 5 --cuda --pretrain_emb --softmax --basic_learner --schedule 10000 --save_path save/moel/
変圧器のベースライン
❱❱❱ python3 main.py --model trs --label_smoothing --noam --emb_dim 300 --hidden_dim 300 --hop 2 --heads 2 --cuda --pretrain_emb --save_path save/trs/
マルチタスク Transformer ベースライン
❱❱❱ python3 main.py --model trs --label_smoothing --noam --emb_dim 300 --hidden_dim 300 --hop 2 --heads 2 --cuda --pretrain_emb --multitask --save_path save/multi-trs/


