MELD
1.0.0
IQ テスト LLM に興味がある場合は、新しい作品 AlgoPuzzleVQA をチェックしてください。
Resnetを使用して抽出された視覚的特徴をリリースしました - https://github.com/declare-lab/MM-Align
更新されたベースラインについては、このリンクにアクセスしてください: conv-emotion
データをダウンロードするには、wget を使用します: wget http://web.eecs.umich.edu/~mihalcea/downloads/MELD.Raw.tar.gz
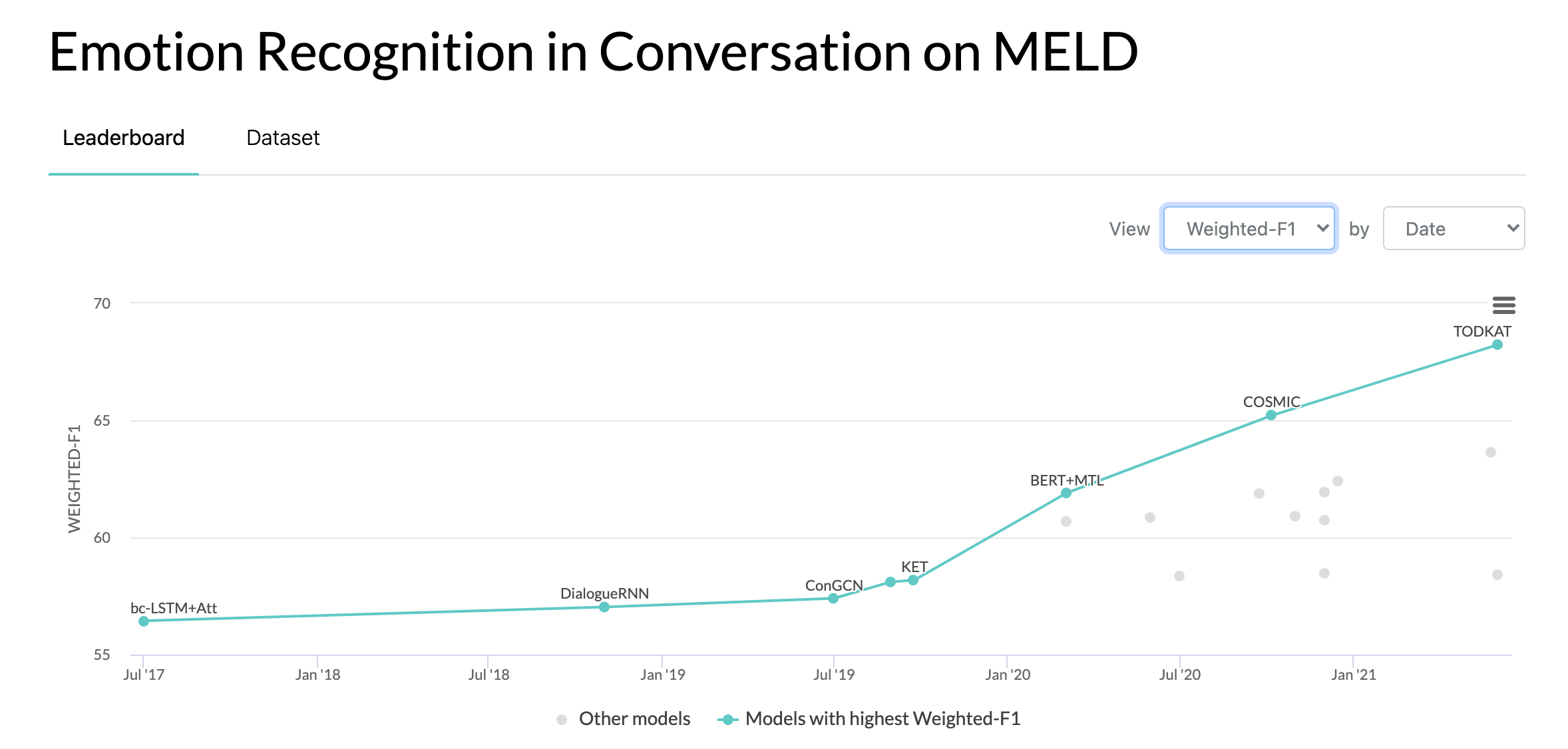
2020/10/10: MELD データセットの会話における感情認識に関する新しい論文と SOTA。コードについては、COSMIC ディレクトリを参照してください。論文を読んでください -- COSMIC: 会話における eMotion Identification に関する COmmonSense の知識。
2019/05/22: MELD: A Multimodal Multi-Party Dataset for Emotion Recognition in Conversation が ACL 2019 で完全な論文として受理されました。更新された論文はここでご覧いただけます - https://arxiv.org/pdf/1810.02508。 pdf
2019/05/22: Dyadic MELD がリリースされました。二項会話モデルをテストするために使用できます。
2018/11/15: train.tar.gz の問題が修正されました。
チャン、ヤジョウ、Qiuchi Li、Dawei Song、Peng Zhang、Panpan Wang。 「会話感情分析のための量子にインスピレーションを得たインタラクティブ ネットワーク」。 IJCAI 2019。
張、東、呉良青、孫長龍、李寿山、朱喬明、周国東。 「複数話者による会話における感情検出のための文脈依存性と話者依存性の両方をモデル化する。」 IJCAI 2019。
ゴサル、ディーパンウェイ、ナボニル・マジュムデル、ソウジャンヤ・ポリア、ニヤティ・チャヤ、アレクサンダー・ゲルブク。 「DialogueGCN: 会話における感情認識のためのグラフ畳み込みニューラル ネットワーク」 EMNLP 2019。
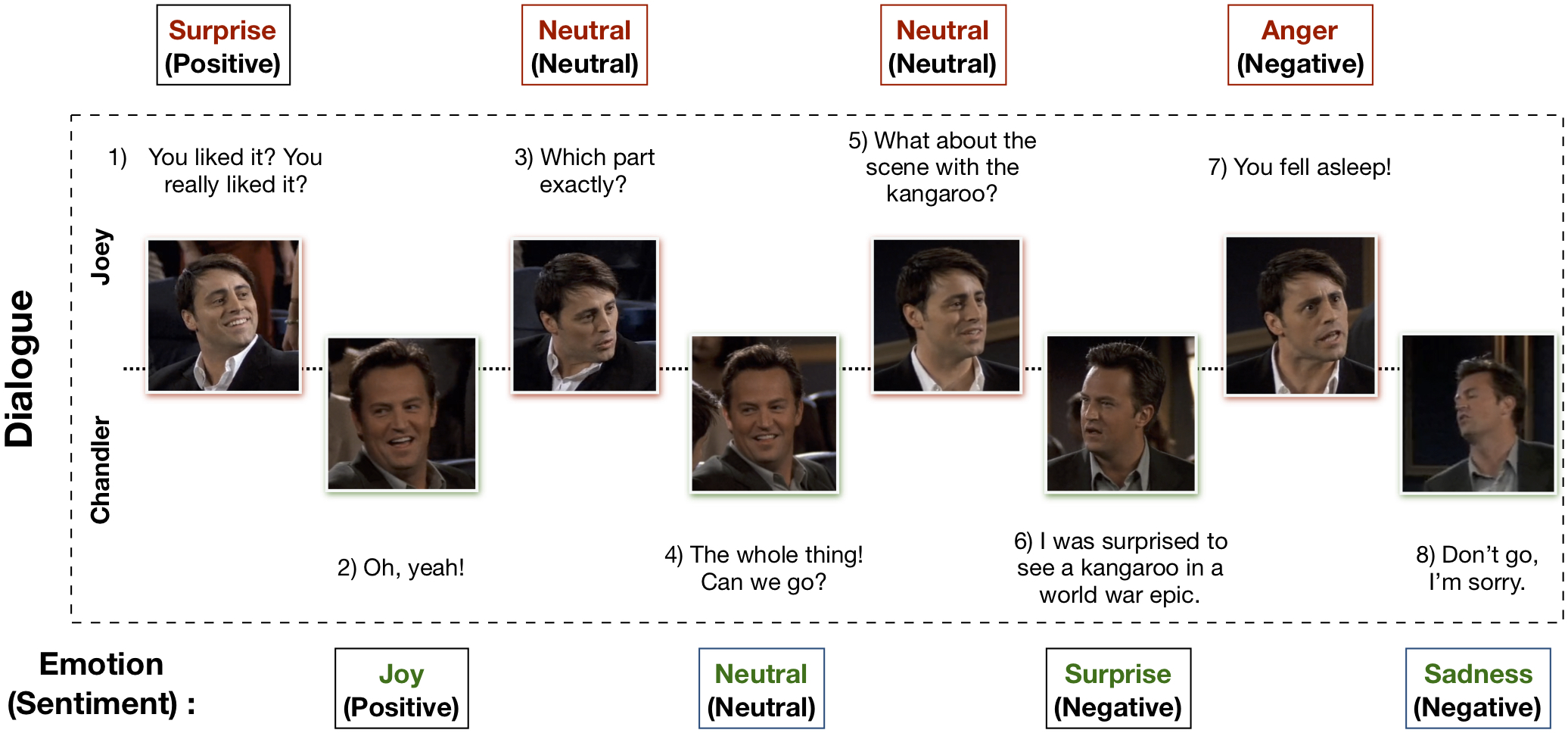
マルチモーダル EmotionLines データセット (MELD) は、EmotionLines データセットを強化および拡張することによって作成されました。 MELD には、EmotionLines で使用できるのと同じダイアログ インスタンスが含まれていますが、テキストとともにオーディオおよびビジュアル モダリティも含まれています。 MELD には、フレンズ TV シリーズからの 1400 を超えるダイアログと 13000 の発話が収録されています。対話には複数の講演者が参加した。対話内の各発話には、怒り、嫌悪、悲しみ、喜び、中立、驚き、恐怖の 7 つの感情のいずれかがラベル付けされています。 MELD には、各発話に対する感情 (肯定的、否定的、中立的) アノテーションもあります。
| 統計 | 電車 | 開発者 | テスト |
|---|---|---|---|
| モダリティの数 | {a、v、t} | {a、v、t} | {a、v、t} |
| 固有の単語の数 | 10,643 | 2,384 | 4,361 |
| 平均発話の長さ | 8.03 | 7.99 | 8.28 |
| 最大。発話の長さ | 69 | 37 | 45 |
| 平均対話ごとの感情の数 | 3.30 | 3.35 | 3.24 |
| 対話の数 | 1039 | 114 | 280 |
| 発言数 | 9989 | 1109 | 2610 |
| スピーカーの数 | 260 | 47 | 100 |
| 感情の変化の数 | 4003 | 427 | 1003 |
| 平均発話の長さ | 3.59秒 | 3.59秒 | 3.58秒 |
詳細については、https://affective-meld.github.io をご覧ください。
| 電車 | 開発者 | テスト | |
|---|---|---|---|
| 怒り | 1109 | 153 | 345 |
| 嫌悪 | 271 | 22 | 68 |
| 恐れ | 268 | 40 | 50 |
| 喜び | 1743年 | 163 | 402 |
| 中性 | 4710 | 470 | 1256 |
| 悲しみ | 683 | 111 | 208 |
| 驚き | 1205 | 150 | 281 |
マルチモーダル データ分析は、複数の並列データ チャネルからの情報を意思決定に利用します。 AI の急速な成長に伴い、マルチモーダル感情認識は、主に対話生成やマルチモーダル インタラクションなど、多くの困難なタスクに応用できる可能性があるため、大きな研究関心を集めています。会話型感情認識システムを使用すると、次のような適切な応答を生成できます。ユーザーの感情を分析します。マルチモーダル感情認識については数多くの研究が行われていますが、実際に会話中の感情の理解に焦点を当てている研究はごくわずかです。ただし、彼らの仕事は二項会話の理解にのみ限定されているため、参加者が 3 人以上の多者間会話における感情認識には拡張できません。 EmotionLines は、視覚や音声などの他のモダリティからのデータが含まれていないため、テキストのみの感情認識のリソースとして使用できます。同時に、感情認識研究に利用できるマルチモーダルな複数当事者の会話データセットがないことに注意する必要があります。この作業では、マルチモーダル シナリオ向けに EmotionLines データセットを拡張、改善し、さらに開発しました。連続したターンでの感情認識にはいくつかの課題があり、コンテキストの理解もその 1 つです。対話の一連のターンにおける感情の変化と感情の流れにより、正確なコンテキストのモデリングが困難な作業になります。このデータセットでは、各対話のマルチモーダル データ ソースにアクセスできるため、コンテキスト モデリングが改善され、全体的な感情認識パフォーマンスに利益がもたらされると仮説を立てます。このデータセットは、マルチモーダルな感情対話システムの開発にも使用できます。 IEMOCAP、SEMAINE は、各発話の感情ラベルを含むマルチモーダルな会話データセットです。ただし、これらのデータセットは本質的に二項関係にあるため、Multimodal-EmotionLines データセットの重要性が正当化されます。その他に公開されているマルチモーダル感情およびセンチメント認識データセットには、MOSEI、MOSI、MOUD があります。ただし、これらのデータセットはいずれも会話型ではありません。
最初のステップでは、EmotionLines データセットに存在する各ダイアログ内のすべての発話のタイムスタンプを見つけます。これを達成するために、発話の開始と終了のタイムスタンプを含むすべてのエピソードの字幕ファイルをクロールしました。このプロセスにより、エピソード内の各発話のシーズン ID、エピソード ID、およびタイムスタンプを取得できるようになりました。タイムスタンプを取得する際に 2 つの制約を設けます。(a) 対話内の発話のタイムスタンプは昇順でなければなりません。(b) 対話内のすべての発話は同じエピソードおよびシーンに属していなければなりません。これら 2 つの条件で制約すると、EmotionLines では、いくつかの対話が複数の自然な対話で構成されていることがわかりました。これらのケースをデータセットから除外しました。このエラー修正ステップにより、私たちの場合、EmotionLines と比較してダイアログの数が異なります。各発話のタイムスタンプを取得した後、ソース エピソードから対応するオーディオビジュアル クリップを抽出しました。これとは別に、これらのビデオ クリップから音声コンテンツも取り出しました。最後に、データセットには、各ダイアログのビジュアル、オーディオ、およびテキストのモダリティが含まれています。
このデータセットを説明する論文は、https://arxiv.org/pdf/1810.02508.pdf にあります。
生データをダウンロードするには、http://web.eecs.umich.edu/~mihalcea/downloads/MELD.Raw.tar.gz にアクセスしてください。データは .mp4 形式で保存され、XXX.tar.gz ファイルにあります。注釈は https://github.com/declare-lab/MELD/tree/master/data/MELD にあります。
| 列名 | 説明 |
|---|---|
| シニアNo. | 発話のシリアル番号。主に、異なるバージョンまたは異なるサブセットを持つ複数のコピーがある場合に発話を参照するために使用されます。 |
| 発話 | EmotionLines からの個々の発話を文字列として表現します。 |
| スピーカー | 発話に関連付けられた話者の名前。 |
| 感情 | 話者が発話の中で表現した感情 (中立、喜び、悲しみ、怒り、驚き、恐怖、嫌悪)。 |
| 感情 | 話者が発話の中で表現した感情 (肯定的、中立的、否定的)。 |
| ダイアログ_ID | 0から始まる対話のインデックス。 |
| 発話_ID | 対話内の特定の発話の 0 から始まるインデックス。 |
| 季節 | シーズンNo.特定の発言が属するフレンズ TV 番組の。 |
| エピソード | エピソードNo.発言が属する特定のシーズンのフレンズテレビ番組の。 |
| 開始時間 | 指定されたエピソードの発話の開始時刻 (「hh:mm:ss,ms」形式)。 |
| 終了時間 | 指定されたエピソードの発話の終了時刻 (「hh:mm:ss,ms」形式)。 |
ベースライン モデルのトレーニングに使用されるデータと特徴で構成される 13 個の pickle ファイルがあります。以下に、各 pickle ファイルについて簡単に説明します。
import pickle
data , W , vocab , word_idx_map , max_sentence_length , label_index = pickle . load ( open ( filepath , 'rb' )) import pickle
train_text_avg_emb , val_text_avg_emb , test_text_avg_emb = pickle . load ( open ( filepath , 'rb' )) import pickle
train_audio_emb , val_audio_emb , test_audio_emb = pickle . load ( open ( filepath , 'rb' )) import pickle
train_text_CNN_emb , val_text_CNN_emb , test_text_CNN_emb = pickle . load ( open ( filepath , 'rb' )) import pickle
train_text_emb , val_text_emb , test_text_emb = pickle . load ( open ( filepath , 'rb' )) import pickle
train_audio_emb , val_audio_emb , test_audio_emb = pickle . load ( open ( filepath , 'rb' )) import pickle
train_bimodal_emb , val_bimodal_emb , test_bimodal_emb = pickle . load ( open ( filepath , 'rb' ))「./utils/」には 2 つの Python スクリプトが提供されています。
実験のために、すべてのラベルはワンホット エンコーディングとして表され、そのインデックスは次のとおりです。
感情分類のベースラインには、次のクラス重みが使用されました。インデックス付けは上記と同じです。クラスの重み: [4.0、15.0、15.0、3.0、1.0、6.0、3.0]。
ベースラインを実行するには、次の手順に従ってください。
./data/pickles/にコピーします。baseline/baseline.pyを実行します。python baseline.py -classify [Sentiment|Emotion] -modality [text|audio|bimodal] [-train|-test]python baseline.py -classify Sentiment -modality text -trainpython baseline.py -h使用して、パラメータのヘルプ テキストを取得します。./data/models/内に配置します。 このデータセットが研究に役立つと思われる場合は、次の論文を引用してください。
S. ポリア、D. ハザリカ、N. マジュムデル、G. ナイク、E. カンブリア、R. ミハルセア。 MELD: 会話中の感情認識のためのマルチモーダルなマルチパーティ データセット。 ACL2019。
Chen、SY、Hsu、CC、Kuo、CC、および Ku、LW EmotionLines: 多者間の会話の感情コーパス。 arXiv プレプリント arXiv:1802.08379 (2018)。
マルチモーダル EmoryNLP 感情検出データセットは、EmoryNLP 感情検出データセットを強化および拡張することによって作成されました。これには、EmoryNLP 感情検出データセットで利用できるものと同じダイアログ インスタンスが含まれていますが、テキストとともに音声と視覚のモダリティも含まれています。マルチモーダル EmoryNLP データセットには、フレンズ TV シリーズの 800 を超えるダイアログと 9000 の発話が存在します。対話には複数の講演者が参加した。対話内の各発話には、中立、喜び、平和、力強い、怖い、狂気、悲しみの 7 つの感情のいずれかがラベル付けされています。注釈は元のデータセットから借用されます。
| 統計 | 電車 | 開発者 | テスト |
|---|---|---|---|
| モダリティの数 | {a、v、t} | {a、v、t} | {a、v、t} |
| 固有の単語の数 | 9,744 | 2,123 | 2,345 |
| 平均発話の長さ | 7.86 | 6.97 | 7.79 |
| 最大。発話の長さ | 78 | 60 | 61 |
| 平均シーンごとの感情の数 | 4.10 | 4.00 | 4.40 |
| 対話の数 | 659 | 89 | 79 |
| 発言数 | 7551 | 954 | 984 |
| スピーカーの数 | 250 | 46 | 48 |
| 感情の変化の数 | 4596 | 575 | 653 |
| 平均発話の長さ | 5.55秒 | 5.46秒 | 5.27秒 |
| 電車 | 開発者 | テスト | |
|---|---|---|---|
| 楽しい | 1677年 | 205 | 217 |
| 狂った | 785 | 97 | 86 |
| 中性 | 2485 | 322 | 288 |
| 平和な | 638 | 82 | 111 |
| 強力な | 551 | 70 | 96 |
| 悲しい | 474 | 51 | 70 |
| 怖がった | 941 | 127 | 116 |
このデータセットのビデオ クリップは、このリンクからダウンロードできます。注釈ファイルは https://github.com/SenticNet/MELD/tree/master/data/emorynlp にあります。 3 つの .csv ファイルがあります。これらの CSV ファイルの最初の列の各エントリには発話が含まれており、その対応するビデオ クリップはここで見つけることができます。各発話とそのビデオ クリップには、シーズン番号、エピソード番号、シーン ID、発話 ID によってインデックスが付けられます。たとえば、 sea1_ep2_sc6_utt3.mp4 は、クリップがシーズン番号の発話に対応していることを意味します。 1、エピソードNo. 2、scene_id 6、および speech_id 3。シーンは単なる対話です。このインデックス付けは元のデータセットと一致しています。 .csv ファイルとビデオ ファイルは、元のデータセットに従って、トレーニング セット、検証セット、およびテスト セットに分割されます。注釈は、元の EmoryNLP データセットから直接借用しました (Zahiri et al. (2018))。
| 列名 | 説明 |
|---|---|
| 発話 | EmoryNLP からの文字列としての個々の発話。 |
| スピーカー | 発話に関連付けられた話者の名前。 |
| 感情 | 話者が発話内で表現した感情 (中立、楽しい、平和、力強い、怖い、狂った、悲しい)。 |
| シーンID | 0から始まる対話のインデックス。 |
| 発話_ID | 対話内の特定の発話の 0 から始まるインデックス。 |
| 季節 | シーズンNo.特定の発言が属するフレンズ TV 番組の。 |
| エピソード | エピソードNo.発言が属する特定のシーズンのフレンズテレビ番組の。 |
| 開始時間 | 指定されたエピソードの発話の開始時刻 (「hh:mm:ss,ms」形式)。 |
| 終了時間 | 指定されたエピソードの発話の終了時刻 (「hh:mm:ss,ms」形式)。 |
注:字幕に不一致があり、開始時刻と終了時刻が特定できなかった発話がいくつかあります。このような発話はデータセットから除外されています。ただし、ユーザーには、元のデータセットから対応する発話を見つけて、その発話のビデオ クリップを生成することをお勧めします。
このデータセットが研究に役立つと思われる場合は、次の論文を引用してください。
S・ザヒリとJD・チョイ。シーケンスベースの畳み込みニューラル ネットワークを使用したテレビ番組トランスクリプトの感情検出。感情内容分析に関する AAAI ワークショップ、AFFCON'18、2018 年。
S. ポリア、D. ハザリカ、N. マジュムデル、G. ナイク、E. カンブリア、R. ミハルセア。 MELD: 会話中の感情認識のためのマルチモーダルなマルチパーティ データセット。 ACL2019。


