ChatLearner
1.0.0
新しいシーケンスツーシーケンス (NMT) モデルに基づいて TensorFlow に実装されたチャットボットで、特定のルールがシームレスに統合されています。
中国語のチャットボットに興味のある方はこちらをご覧ください。
ChatLearner (Papaya) のコアは NMT モデル (https://github.com/tensorflow/nmt) に基づいて構築されており、チャットボットのニーズに合わせて調整されています。 TensorFlow 1.4 の tf.data API に加えられた変更と、TensorFlow 1.12 以降のその他の多くの変更により、この ChatLearner バージョンは TF バージョン 1.4 ~ 1.11 のみをサポートします。 TensorFlow 1.12 をサポートする必要がある場合は、tokenizeddata.py ファイルで簡単に更新できます。
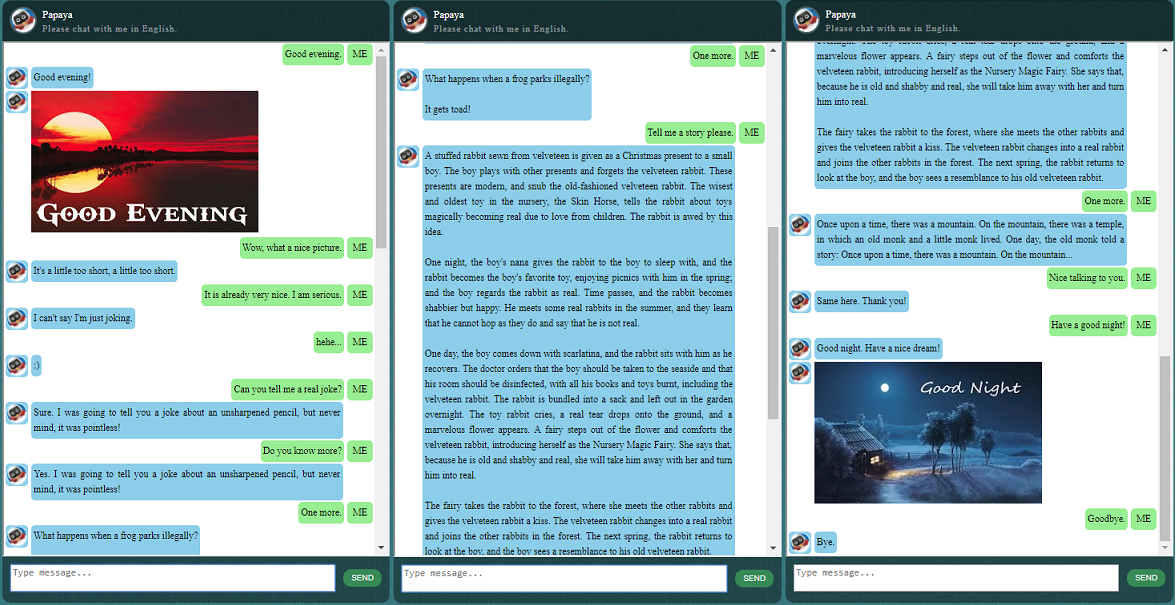
他のことを始める前に、ChatLearner がどのように動作するかを感じてみるとよいでしょう。以下またはここで会話のサンプルをご覧ください。または、私のトレーニング済みモデルを試してみたい場合は、ここからダウンロードしてください。ダウンロードした .rar ファイルを解凍し、Result フォルダーをプロジェクト ルートの下の Data フォルダーにコピーします。将来トレーニング済みモデルを更新せずに更新する場合に備えて、vocab.txt ファイルも含まれています。
このリポジトリのチェックに時間を費やす理由は何ですか?考えられる理由は次のとおりです。
チャットボットをトレーニングするための Papaya データ セット。オンラインで大量のトレーニング データを簡単に見つけることができますが、これほど高品質なものは見つかりません。データセットについては、以下の詳細な説明を参照してください。
簡潔なコード スタイルと、動的 RNN (新しい NMT モデルとも呼ばれる) に基づく新しい seq2seq モデルの明確な実装。チャットボット向けにカスタマイズされており、公式チュートリアルと比べて非常に理解しやすくなっています。
シームレスに統合された ChatSession を使用して基本的な会話コンテキストを処理するというアイデア。
一部のルールは、従来のルールベースのチャットボットと新しい深層学習モデルを組み合わせる方法をデモするために統合されています。深層学習モデルがどれほど強力であっても、単純な算術計算やその他多くの質問に答えることさえできません。ここで説明するアプローチは、ニュースやその他のオンライン情報を取得するために簡単に適用できます。ルールを実装すると、多くの興味深い質問に適切に答えることができます。例えば:
ルールに興味がない場合は、knowledgebase.py および functiondata.py に関連する行を簡単に削除できます。
SOAP ベースの Web サービス (SOAP を使用したくない場合は、REST-API ベースの代替サービス) を使用すると、モデルを Python と TensorFlow でトレーニングして実行しながら、Java で GUI を表示できます。
TensorFlow で文字列テンソルを小文字に変換する簡単なソリューション (グラフ内)。 TensorFlow の新しい DataSet API (tf.data.TextLineDataSet) を利用してテキスト ファイルからトレーニング データをロードする場合に必要です。
リポジトリには、従来の seq2seq モデルに基づいたチャットボット実装も含まれています。ご興味がございましたら、https://github.com/bshao001/ChatLearner/tree/Legacy_Chatbot の Legacy_Chatbot ブランチをご確認ください。
Papaya Data Set は、チャットボットのトレーニングに使用できる、Web 上で見つけられる最高の (最もクリーンでよく整理された) 無料の英会話データです。詳細は次のとおりです。
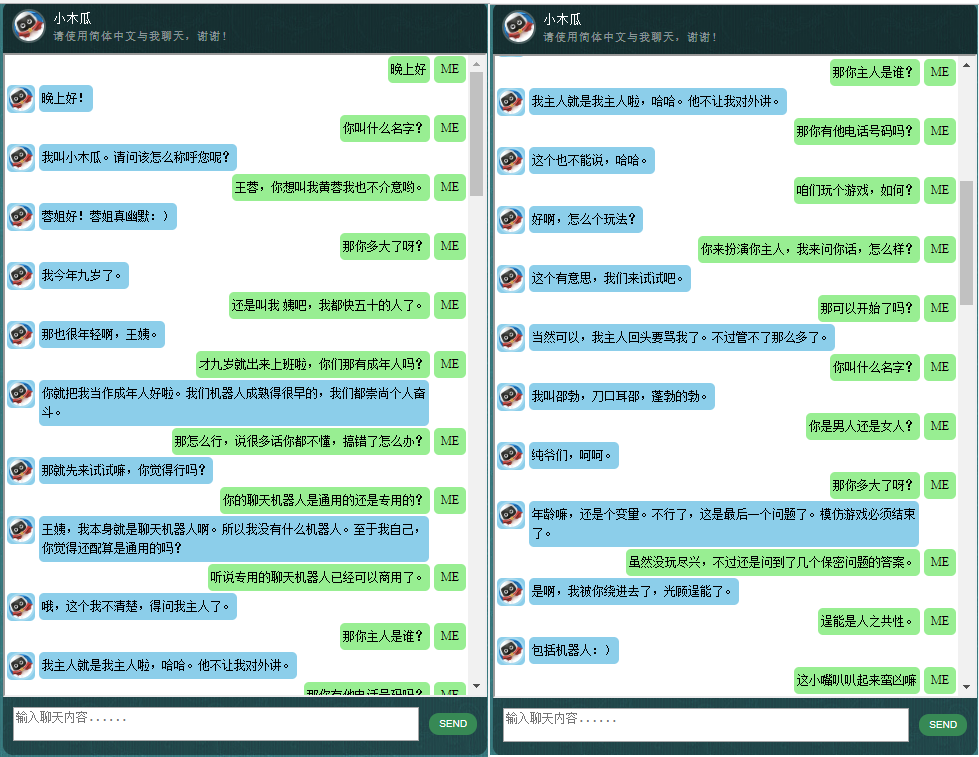
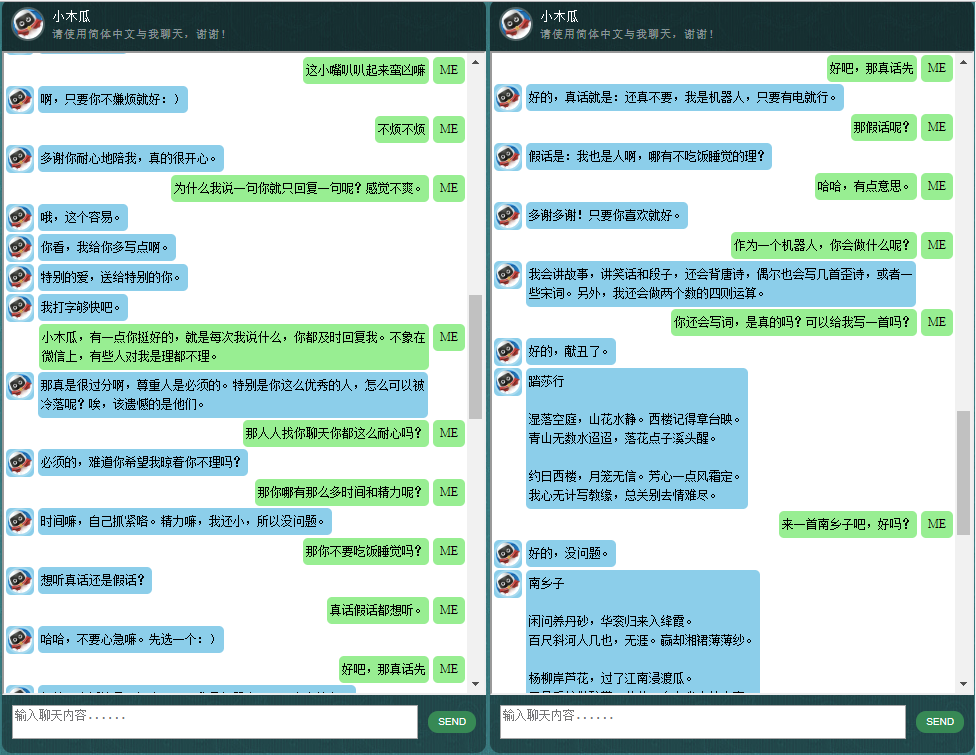
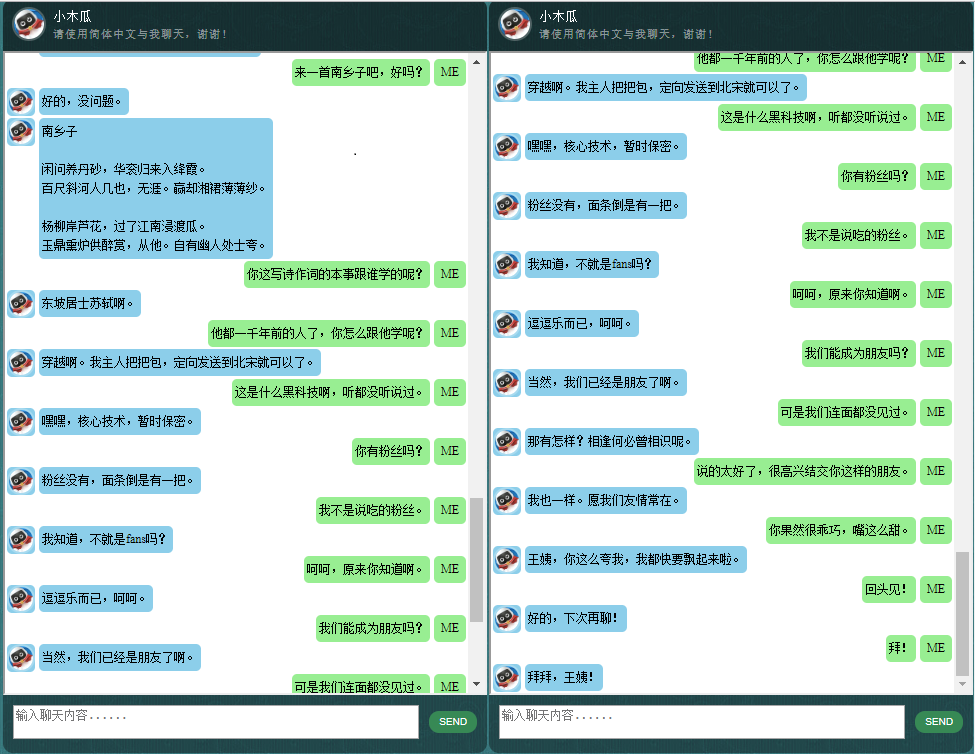
データは 2 つのセットで構成されています。最初のセットは手作りで、チャットボットの一貫した役割を維持するためにサンプルを作成しました。したがって、チャットボットは、礼儀正しく、忍耐強く、ユーモアがあり、哲学的であり、自分がどのような人間であるかを認識するように訓練することができます。ロボットですが、パパイヤという名前の9歳の男の子のふりをします。 2 番目のセットは、ロボットのトレーニング用に設計されたシナリオの会話、コーネル映画のダイアログ、クリーンアップされた Reddit データなど、いくつかのオンライン リソースからクリーンアップされました。
トレーニング データ セットは 3 つのカテゴリに分割されます。2 つのサブセットはトレーニング中に異なるレベルまたは時間で拡張/反復されますが、3 番目のサブセットは拡張されません。拡張されたサブセットは、従うべきルールとある程度の知識と常識を使用してモデルをトレーニングするためのものであり、3 番目のサブセットは言語モデルのトレーニングを支援するためのものです。
シナリオ会話は http://www.eslfast.com/robot/ から抽出して再構成したものです。モデルがコンテキストをサポートできる場合は、これらの会話を利用することでより適切に機能するでしょう。
オリジナルの Cornell データセットはここにあります。 Python スクリプトを使用してクリーンアップしました (スクリプトは Corpus フォルダーにもあります)。次に、特定のパターンをすばやく検索して手動でクリーンアップしました。
Reddit データの場合、クリーンアップされたサブセット (約 110,000 ペア) がこのリポジトリに含まれています。語彙ファイルとモデルパラメータは、含まれるすべてのデータファイルに基づいて作成および調整されます。より大きなセットが必要な場合は、Corpus/RedditData フォルダーで Reddit コメントを解析してクリーンアップするスクリプトを見つけることもできます。これらのスクリプトを使用するには、ここのトレント リンクから Reddit コメントのトレントをダウンロードする必要があります。通常、1 か月分のコメントで十分な量になります (およそ 300 万ペアのトレーニング サンプルを生成できます)。ニーズに基づいてスクリプト内のパラメータを調整できます。
このデータ セット内のデータ ファイルはすでに NLTK トークナイザーで前処理されているため、TensorFlow の新しい tf.data API を使用してモデルにフィードする準備ができています。
TensorFlow のバージョンが正しいことを確認してください。ここで使用されている tf.data API は TF 1.4 で新しく更新されたため、これは TensorFlow 1.4 でのみ動作し、それ以前のリリースでは動作しません。
環境変数 PYTHONPATH が設定されていることを確認してください。これは、チャットボット、データ、webui フォルダーがあるプロジェクトのルート ディレクトリを指す必要があります。 PyCharm などの IDE で実行している場合は、それが自動的に作成されます。ただし、コマンド ラインで Python スクリプトを実行する場合は、その環境変数が必要です。そうでないと、モジュールのインポート エラーが発生します。
トレーニングと推論/予測の両方に同じ vocab.txt ファイルを使用していることを確認してください。私たちのように、モデルは単語を決して認識しないことに注意してください。すべて整数が入力され、整数が出力されますが、vocab.txt 内の単語とその順序は、単語と整数の間のマッピングに役立ちます。
モデルの大きさ、エンコーダー/デコーダーの最大長はどれくらい、語彙セットのサイズ、使用するトレーニング データのペアの数などについて少し時間をかけて考えてください。モデルには容量制限、つまり学習または記憶できるデータの量があることに注意してください。層の数、ユニットの数、RNN セルのタイプ (GRU など) が固定されており、エンコーダー/デコーダーの長さを決定した場合、モデルの学習能力に影響を与えるのは、主にボキャブラリーの数ではなく、ボキャブラリーのサイズです。トレーニングサンプル。より多くのトレーニング データを使用するときに語彙サイズが増加しないように管理できれば、おそらくうまくいきますが、現実には、より多くのトレーニング サンプルがあると、語彙サイズも非常に急速に増加します。あなたのモデルはそのサイズのデータにまったく対応できません。必要に応じて、お気軽に問題を開いて議論してください。
Python 3.6 (3.5 も同様に動作するはず)、Numpy、TensorFlow 1.4 以外。 NLTK (Natural Language Toolkit) バージョン 3.2.4 (または 3.2.5) も必要です。
トレーニング中に、関数 tf.gradients のパラメーター (colocate_gradients_with_ops) を試してみることを強くお勧めします。 modelcreator.py には次のような行があります: gradients = tf.gradients(self.train_loss, params)。 colocate_gradients_with_ops=True を設定 (追加) して、少なくとも 1 エポックのトレーニングを実行し、時間をメモしてから、これを False に設定して (または単に削除し)、少なくとも 1 エポックのトレーニングを実行して、時間が必要かどうかを確認します。ある時代では大きく異なります。少なくとも私にとっては衝撃的です。
それ以外は、トレーニングは簡単です。最初に、Data フォルダーの下に Result という名前のフォルダーを作成することを忘れないでください。次に、次のコマンドを実行するだけです。
cd chatbot
python bottrainer.pyトレーニングには非常に時間がかかるため、優れた GPU を使用することを強くお勧めします。複数の GPU がある場合、すべての GPU のメモリが TensorFlow によって利用され、それに応じて hparams.json ファイルのバッチ サイズ パラメータを調整して、メモリを最大限に活用することができます。 Data/Result/ フォルダーの下にトレーニング結果が表示されます。次の 2 つのファイルが存在することを確認してください。これらはすべてテストと予測に必要です (推論モデルは個別に作成されるため、.meta ファイルはオプションです)。
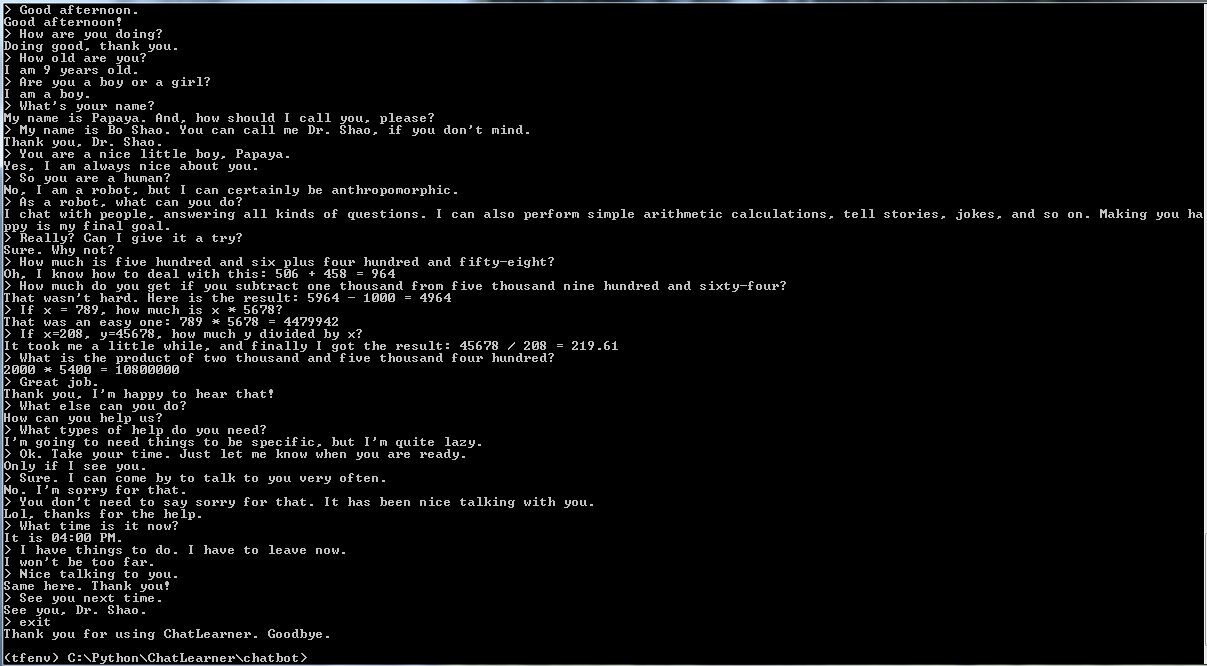
テストと予測のために、シンプルなコマンド インターフェイスと Web ベースのインターフェイスが提供されます。 vocab.txt ファイル (およびこのチャットボットの場合は KnowledgeBase 内のファイル) も推論に必要であることに注意してください。トレーニングされたモデルがどのように実行されるかをすばやく確認するには、次のコマンド インターフェイスを使用します。
cd chatbot
python botui.pyコマンド プロンプト > " が表示されるまで待ちます。
デモテストの結果も提供されます。このチャットボットが現在どのように動作しているかを確認するには、https://github.com/bshao001/ChatLearner/blob/master/Data/Test/responses.txt を確認してください。
SOAP ベースの Web サービス アーキテクチャが、Python サーバーと Java クライアントを使用して実装されています。参考のために、優れた GUI も含まれています。詳細については、https://github.com/bshao001/ChatLearner/tree/master/webui をご確認ください。特定の情報 (画像など) は Web インターフェイスでのみ利用可能です (コマンド ライン インターフェイスでは利用できません) のでご注意ください。
SOAP を選択できない場合は、REST-API ベースの代替手段も提供されます。詳細については、https://github.com/bshao001/ChatLearner/tree/master/webui_alternative をご確認ください。最新のアップデートの一部は、このオプションでは利用できない場合があります。これを使用する必要がある場合は、他のオプションからの変更をマージします。
ここでは、自身が公開した NLP マークアップ フレームワークに基づくいくつかのマークアップ フレームワークを示します。 (自然语言処理标记フレーム)、特定の分野の問題の精緻化を実現し、解決することができます。この方法は、商業上の用途(対面の仕事)に適している。 ) アンテナ機械者の発表、たとえば前、後、または特定の分野 (法律、医療など) の技術評価サービスなど。