Seq2seqChatbots
1.0.0
ニューラル チャットボットのデータを柔軟にトレーニング、対話、生成するための tensor2tensor のラッパー。
Wiki には、ニューラル ダイアログ モデリングに関連する 150 以上の最近の出版物の私のメモと要約が含まれています。
? 独自のトレーニングを実行するか、事前トレーニングされたモデルを試してください
✅ tensor2tensor と統合された 4 つの異なるダイアログ データセット
? tensor2tensor で設定された任意のモデルまたはハイパーパラメータでシームレスに動作します
ダイアログの問題に対して簡単に拡張可能な基本クラス
setup.py を実行すると、必要なパッケージがインストールされ、追加データのダウンロードが完了します。
python setup.py
このペーパーで使用されているすべてのトレーニング済みモデルはここからダウンロードできます。各トレーニングには 2 つのチェックポイントが含まれており、1 つは検証損失の最小値で、もう 1 つは 150 エポック後です。データとトレーニング フォルダー構造は完全に一致します。
python t2t_csaky/main.py --mode=train
mode 引数は、 {generate_data、train、decode、experiment}の 4 つのうちの 1 つです。実験モードでは、実行ファイルの実験関数内で何を行うかを指定できます。各モードの動作については、以下で詳しく説明します。
このファイルで各モードのフラグとパラメータを直接制御できます。実行を開始するたびに、このファイルは適切なディレクトリにコピーされるため、任意の実行のパラメータにすぐにアクセスできます。すべてのモードに設定する必要があるフラグがいくつかあります (構成ファイル内のFLAGSディクショナリ)。
t2t_usr_dir : コードが存在するディレクトリへのパス。ディレクトリの名前を変更しない限り、これを変更する必要はありません。
data_dir : ソースとターゲットのペア、およびその他のデータを生成するディレクトリへのパス。データセットは、このディレクトリから 1 レベル上のraw_dataフォルダーにダウンロードされます。
問題: これは、tensor2tensor が必要とする登録済みの問題の名前です。詳細については、以下の「generate_data」セクションを参照してください。すべてのパスはリポジトリのルートからのものである必要があります。
このモードでは、データをダウンロードして前処理し、ソースとターゲットのペアを生成します。現在、tensor2tensor で与えられる問題以外に使用できる問題が 6 つ登録されています。
persona_chat_chatbot : この問題は、ペルソナチャット データセットを (ペルソナを使用せずに) 実装します。
daily_dialog_chatbot : この問題は、DailyDialog データセットを実装します (トピック、対話行為、または感情は使用しません)。
opensubtitles_chatbot : この問題は、OpenSubtitles データセットを操作するために使用できます。
cornell_chatbot_basic : この問題は Cornell Movie-Dialog Corpus を実装します。
cornell_chatbot_ Separate_names : この問題は同じコーネルコーパスを使用しますが、各発話の話者と宛先の名前が追加されるため、ソース発話は次のようになります。
BIANCA_m0 何か良いものはありますか? キャメロン_m0
Character_chatbot : これは、任意のデータセットで機能する一般的な文字ベースの問題です。これを使用する前に、上記の問題のいずれかによって生成された .txt ファイルをデータ ディレクトリ内に配置する必要があります。その後、この問題を使用して tensor2tensor 文字ベースのデータ ファイルを生成できます。
構成ファイル内のPROBLEM_HPARAMSディクショナリには、データを生成する前に設定できる問題固有のパラメーターが含まれています。
num_train_shards / num_dev_shards : 生成された列車または開発データを複数のファイルにシャーディングする場合。
vocacy_size : 問題に使用する語彙のサイズ。この語彙外の単語はトークンに置き換えられます。
dataset_size : 完全なデータセット (0 で定義) を使用したくない場合の発話ペアの数。
dataset_split : 問題の train-val-test 分割を指定します。
dataset_version : これは opensubtitles データセットにのみ関連します。このデータセットには複数のバージョンがあるため、ダウンロードするデータセットの年を指定できます。
name_vocab_size : これは、別の名前を使用したコーネル問題にのみ関係します。ペルソナのみを含む語彙のサイズを設定できます。
このモードでは、指定された問題とハイパーパラメーターを使用してモデルをトレーニングできます。このコードは tensor2tensor トレーニング スクリプトを呼び出すだけなので、tensor2tensor 内の任意のモデルを使用できます。これらに加えて、小さな変更を加えたサブクラス化されたモデルもあります。
gradient_checkpointed_seq2seq : 独自の hparams を完全に使用できるように、lstm ベースの seq2seq モデルを少し変更しました。ソフトマックスを計算する前に、LSTM 隠れ単位はここのように 2048 線形単位に投影されます。最後に、このモデルに勾配チェックポイントを実装しようとしましたが、良い結果が得られなかったため、現在は削除されています。
構成ファイルのFLAGSディクショナリでトレーニングの実行に指定できる追加のフラグがいくつかあります。そのうちのいくつかは次のとおりです。
train_dir : トレーニング チェックポイント ファイルが保存されるディレクトリの名前。
model : モデルの名前: 上記のいずれか、または tensor2tensor で定義されたモデル。
hparams : 登録済みの hparams_set を指定するか、構成ファイルで hparams を定義する場合は空のままにします。 seq2seqまたはトランスフォーマーモデルの hparams を指定するには、構成ファイルのSEQ2SEQ_HPARAMSおよびTRANSFORMER_HPARAMSディクショナリを使用できます (詳細については、構成ファイルを確認してください)。
このモードを使用すると、トレーニングされたモデルからデコードできます。次のパラメータは、(構成ファイルのFLAGSディクショナリ内の) デコードに影響します。
decode_mode : コマンドラインを使用してモデルとチャットできる対話型にすることができます。ファイルモードでは、応答を生成するソース発話を含むファイルを指定できます。データセットモードでは、提供された検証データがランダムにサンプリングされ、応答が出力されます。
decode_dir : デコードするファイルを指定できるディレクトリ。出力された応答はここに保存されます。
input_file_name :ファイルモードで指定する必要があるファイルの名前 ( decode_dirに配置)。
Output_file_name : 出力応答が保存されるdecode_dir内のファイルの名前。
beam_size : ビーム検索を使用する場合のビームのサイズ。
return_beams : False の場合は上部のビームのみを返し、そうでない場合はbeam_sizeのビーム数を返します。
以下の結果はこれら 2 つの論文から得られたものです。
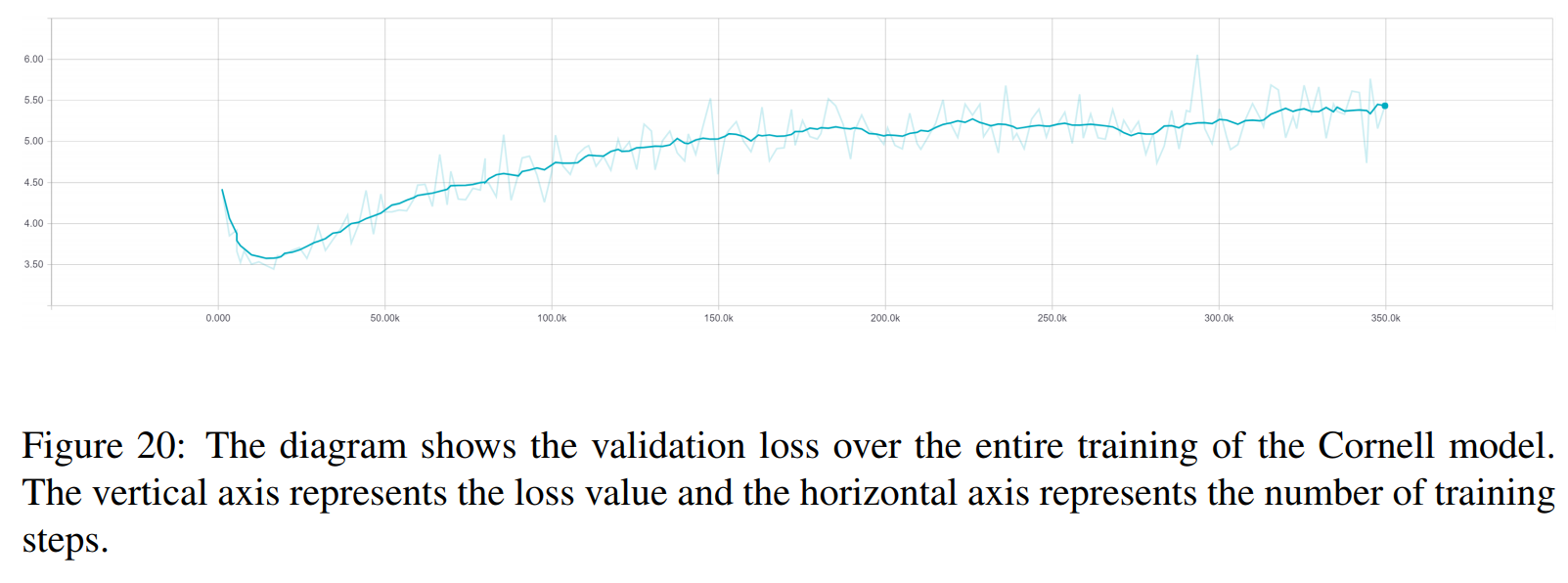

TRF は Transformer モデルであり、RT はトレーニング セットからランダムに選択された応答を意味し、GT はグラウンド トゥルース応答を意味します。メトリクスの説明については、論文を参照してください。
S2S は、Cornell でトレーニングされた LSTM を備えた単純な seq2seq モデルであり、その他は Transformer モデルです。 Opensubtitles F は Opensubtitles で事前トレーニングされ、Cornell で微調整されています。 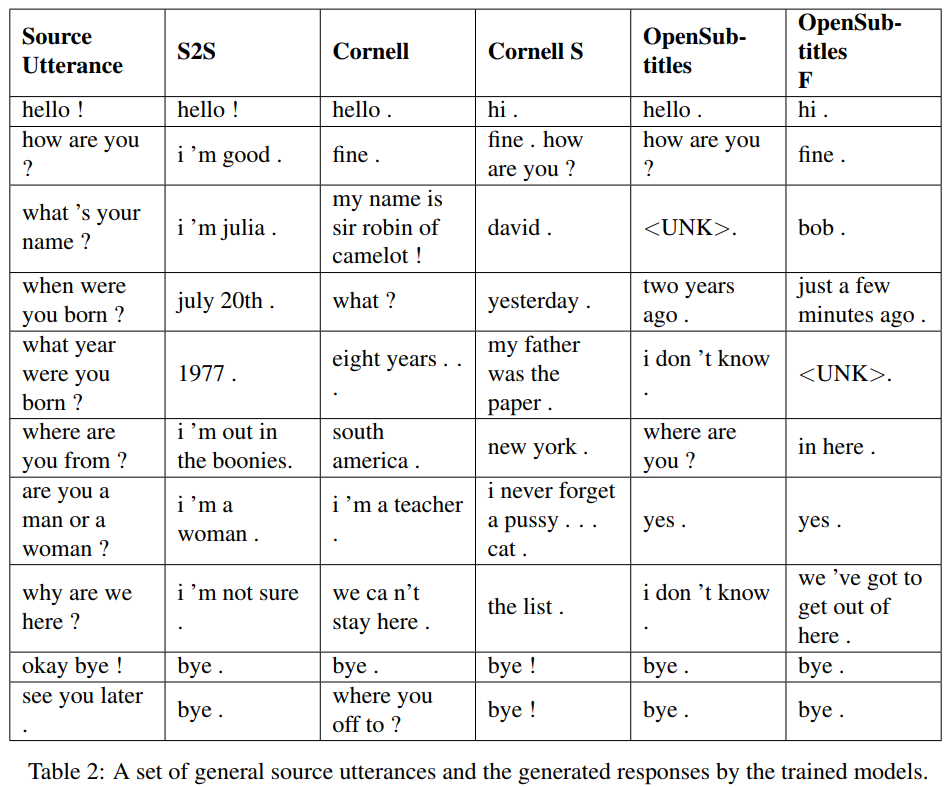
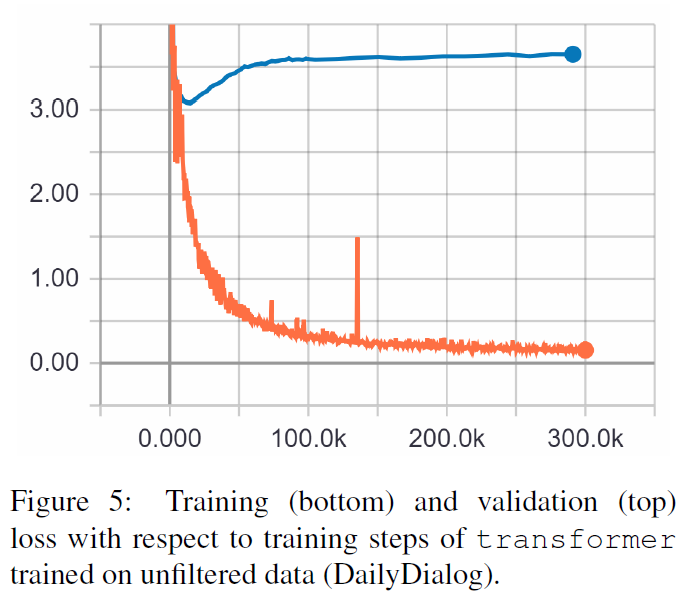

TRF は Transformer モデルであり、RT はトレーニング セットからランダムに選択された応答を意味し、GT はグラウンド トゥルース応答を意味します。メトリクスの説明については、論文を参照してください。
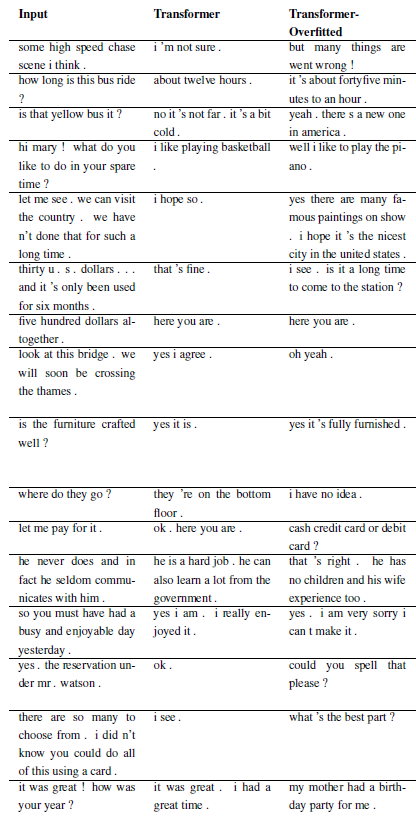
新しい問題は、WordChatbot をサブクラス化することによって登録できます。さらに、いくつかの追加機能が実装されているため、CornellChatbotBasic または OpensubtitleChatbot をサブクラス化することもできます。通常は、 preprocess関数とcreate_data関数をオーバーライドするだけで十分です。詳細についてはドキュメントを確認し、例については daily_dialog_chatbot を参照してください。
新しいモデルとハイパーパラメータは、tensor2tensor チュートリアルに従って追加できます。
Richard Csaky (コードの実行に関してサポートが必要な場合: [email protected])
このプロジェクトは MIT ライセンスに基づいてライセンスされています。詳細については、LICENSE ファイルを参照してください。
仕事で使用し、次の論文の引用を検討する場合は、このリポジトリへのリンクを含めてください。
@InProceedings{Csaky:2017,
title = {Deep Learning Based Chatbot Models},
author = {Csaky, Richard},
year = {2019},
publisher={National Scientific Students' Associations Conference},
url ={https://tdk.bme.hu/VIK/DownloadPaper/asdad},
note={https://tdk.bme.hu/VIK/DownloadPaper/asdad}
} 

