turing
v0.3.8
Viglet Turing ES (https://openviglet.github.io/turing/) は、セマンティック ナビゲーションとチャット ボットを主な機能とするオープン ソース ソリューション (https://github.com/openturing) です。いくつかの NLP から選択してデータを強化できます。すべてのコンテンツは検索エンジンとして Solr にインデックス付けされます。
Turing ES の技術ドキュメントは、https://openviglet.github.io/docs/turing/ で入手できます。
Turing ES を実行するには、次の行を実行するだけです。
# Turing Appmvn -Dmaven.repo.local=D:repo spring-boot:run -pl turing-app -Dskip.npm# Angular 18 と Primer CSS を使用した新しい Turing ES UI.cd turing-ui## ログインは歓迎です## Consoleng サービスコンソール## Searchng サービスSN## チャットボットサービスconverse
MariaDB、Solr、Nginx を使用して Turing ES を起動できます。
ドッカー構成アップ
管理コンソール: http://localhost:2700。 (管理者/管理者)
セマンティック ナビゲーション サンプル: http://localhost:2700/sn/Sample。
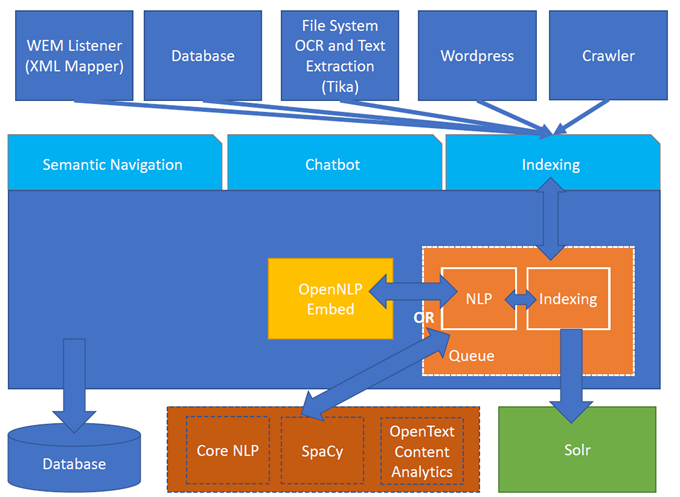
図 1. Turing ES アーキテクチャ
Turing は次のプロバイダーをサポートしています。
Apache OpenNLP は、自然言語テキストを処理するための機械学習ベースのツールキットです。
ウェブサイト: https://opennlp.apache.org/
データを洞察に変換して、リソースと時間を解放しながら、意思決定と情報管理を改善します。
ウェブサイト:https://www.opentext.com/
CoreNLP は、Java での自然言語処理のワンストップ ショップです。 CoreNLP を使用すると、ユーザーは、トークンと文の境界、品詞、名前付きエンティティ、数値と時間の値、依存関係と構成要素の解析、共参照、センチメント、引用の帰属、関係など、テキストの言語注釈を取得できます。 CoreNLP は現在、アラビア語、中国語、英語、フランス語、ドイツ語、スペイン語の 6 つの言語をサポートしています。
ウェブサイト: https://stanfordnlp.github.io/CoreNLP/、
これは、Python での自然言語処理のための無料のオープンソース ライブラリです。 NER、POS タグ付け、依存関係解析、ワード ベクトルなどの機能を備えています。
ウェブサイト:https://spacy.io
Polyglot は、大規模な多言語アプリケーションをサポートする自然言語パイプラインです。
ウェブサイト: https://polyglot.readthedocs.io
PDF とドキュメントを読み取ってプレーン テキストに変換でき、また、OCR を使用して画像内のテキストや画像をドキュメントに検出します。
セマンティック ナビゲーションはコネクタを使用して、多くのソースからのコンテンツにインデックスを付けます。
クローラーを使用してコンテンツにインデックスを付けるための Apache Nutch のプラグイン。
詳細については、https://docs.viglet.com/turing/connectors/#nutch をご覧ください。
sqoop (https://sqoop.apache.org/) と同じ概念を使用して、複雑なクエリを作成し、結果に基づいて属性をインデックスにマップするコマンド ライン。
詳細については、https://docs.viglet.com/turing/connectors/#database をご覧ください。
ファイルのインデックスを作成し、OCR を通じて Word、Excel、PDF などのファイルから画像を含むテキストを抽出するコマンド ライン。
詳細については、https://docs.viglet.com/turing/connectors/#file-system をご覧ください。
Viglet Turing にコンテンツを公開する OpenText WEM リスナー。
詳細については、https://docs.viglet.com/turing/connectors/#wem をご覧ください。
投稿のインデックスを作成できるWordPressプラグイン。
詳細については、https://docs.viglet.com/turing/connectors/#wordpress をご覧ください。
NLP を使用すると、次のようなエンティティを検出できます。
人々
場所
組織
お金
時間
パーセンテージ
ナビゲーションのフィルターとして使用される属性を定義し、表示内のコンテンツ全体を統合します
コンテンツに定義された属性により、ユーザーのプロフィールに基づいて表示を制限することができます。
Java API (https://github.com/openturing/turing-java-sdk) を使用すると、消費者が複雑なクエリでコンテンツを検索する必要がなく、Viglet Turing ES の使用とアクセスが容易になります。
クライアントとコミュニケーションをとり、複雑な意図を詳しく説明し、レポートを取得して、対話を徐々に進化させます。
そのコンポーネント:
エンドユーザーとの会話を処理します。人間の言語のニュアンスを理解する自然言語処理モジュールです
インテントは、会話を変更するエンドユーザーの意図を分類します。エージェントごとに複数のインテントを定義し、インテントを組み合わせて完全な会話を処理できます。
アクションのフィールドは、サービス内でロジックを実行するのに役立つ単純な利便性のフィールドです。
各インテント パラメータにはエンティティ タイプと呼ばれるタイプがあり、エンド ユーザー式のデータがどのように抽出されるかを正確に指定します。
インテントを定義および修正します。
会話履歴やレポートを表示します。
Turing ES は、OCR と NLP を使用して OpenText Blazon ドキュメントのエンティティを検出し、エンティティをドキュメントに表示する Blazon XML を生成します。
Turing ES には、検索エンジン、NLP、Converse (チャット ボット)、セマンティック ナビゲーションなどの多くのコンポーネントがあります。
Turing ES にアクセスすると、ログイン ページが表示されます。デフォルトのログイン/パスワードはadmin / adminです。
図 2. ログイン ページ
検索エンジンは、Converse (チャット ボット) およびセマンティック ナビゲーション サイトのデータを保存および取得するために Turing によって使用されます。
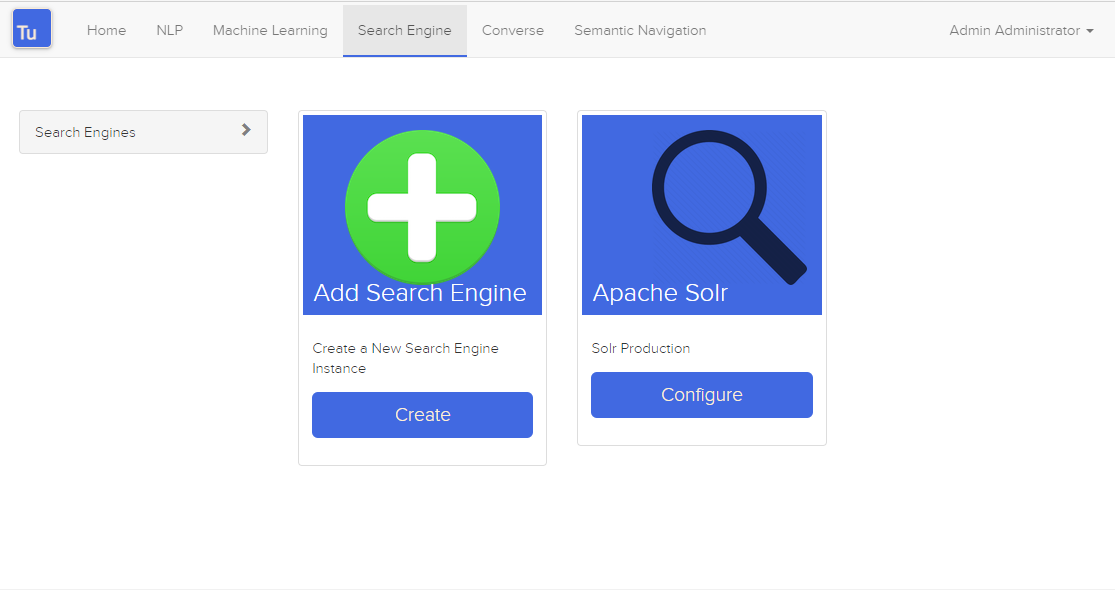
図 3. 検索エンジン ページ
次の属性を使用して検索エンジンを作成または編集できます。
| 属性 | 説明 |
|---|---|
名前 | 検索エンジンの名前 |
説明 | 検索エンジンの説明 |
ベンダー | 検索エンジンのベンダーを選択します。現時点では、Solr のみをサポートしています。 |
ホスト | 検索エンジンサービスがインストールされているホスト名 |
ポート | 検索エンジン サービスのポート |
言語 | 検索エンジン サービスの言語。 |
有効 | 検索エンジンが有効になっている場合。 |
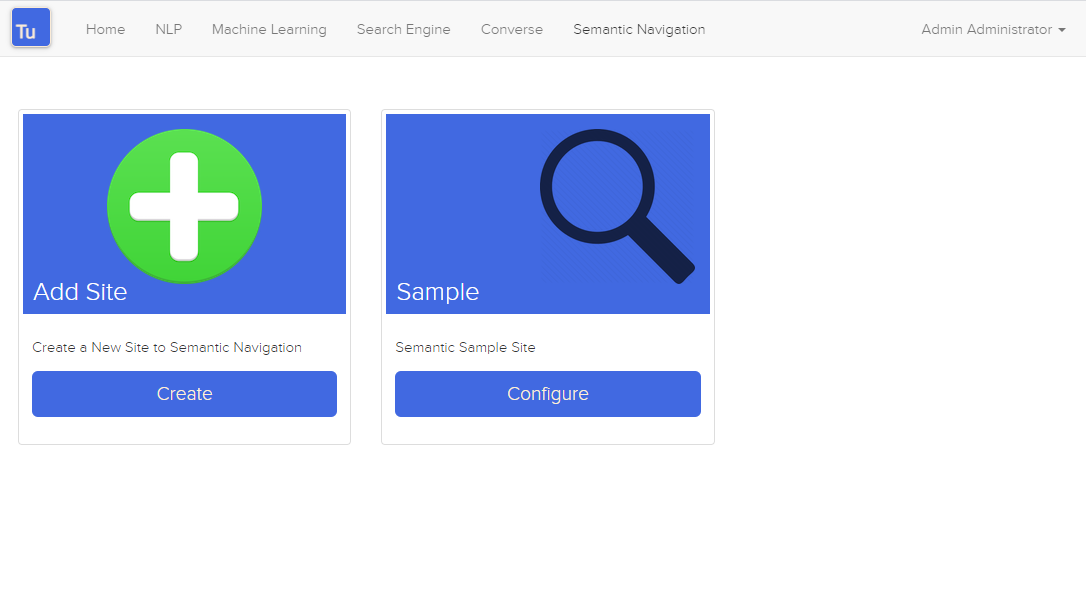
図 4. セマンティック ナビゲーション ページ
セマンティック ナビゲーション サイトの詳細には、次の属性が含まれます。
| 属性 | 説明 |
|---|---|
名前 | セマンティック ナビゲーション サイトの名前。 |
説明 | セマンティック ナビゲーション サイトの説明。 |
検索エンジン | 検索エンジンセクションで作成した検索エンジンを選択します。セマンティック ナビゲーション サイトは、この検索エンジンを使用してデータを保存および取得します。 |
NLP | NLP セクションで作成した NLP を選択します。セマンティック ナビゲーション サイトは、この NLP を使用してインデックス作成中にエンティティを検出します。 |
シソーラス | シソーラスを使用する場合。 |
言語 | セマンティック ナビゲーション サイトの言語。 |
コア | データを保存および取得する検索エンジンのコアの名前。 |
[フィールド] タブには、次の列を含むテーブルが含まれています。 .セマンティック ナビゲーション サイトのフィールドの列
| 列名 | 説明 |
|---|---|
タイプ | フィールドのタイプ。それは次のとおりです。 - NLP で使用される NER (Named Entity Recognition)。 - Solr で使用される検索エンジン。 |
分野 | フィールドの名前。 |
有効 | フィールドが有効かどうか。 |
MLT | このフィールドが MLT で使用される場合。 |
ファセット | このフィールドをファセット (フィルター) のように使用するには |
ハイライト表示 | このフィールドに強調表示された行が表示される場合。 |
NLP | このフィールドが NLP によって処理されて、人、組織、場所などのエンティティ (NER) が検出されるかどうか。 |
「フィールド」をクリックすると、次の属性を含むフィールドの詳細を含む新しいページが表示されます。
| 属性 | 説明 |
|---|---|
名前 | フィールドの名前 |
説明 | フィールドの説明 |
タイプ | フィールドのタイプ。可能性があるのは: |
複数の値 | が配列の場合 |
ファセット名 | 検索ページのファセット(フィルター)のラベル名。 |
ファセット | このフィールドをファセット (フィルター) のように使用するには |
ハイライト表示 | このフィールドに強調表示された行が表示される場合。 |
MLT | このフィールドが MLT で使用される場合。 |
有効 | フィールドが有効な場合。 |
必須 | フィールドが必須の場合。 |
デフォルト値 | これらのフィールドなしでコンテンツのインデックスが作成される場合、これがデフォルト値です。 |
NLP | このフィールドが NLP によって処理されて、人、組織、場所などのエンティティ (NER) が検出されるかどうか。 |
次の属性が含まれます。
| セクション | 属性 | 説明 |
|---|---|---|
外観 | ページあたりのアイテム数 | 検索で表示されるアイテムの数。 |
ファセット | ファセットは有効ですか? | 検索時にファセット (フィルター) が表示される場合。 |
ファセットごとのアイテム数 | 各ファセット (フィルター) に表示される項目の数。 | |
ハイライト表示 | ハイライトは有効ですか? | ハイライトされた行を表示するかどうかを定義します。 |
プレタグ | 学期の初めに使用される HTML タグ。例: <マーク> | |
投稿タグ | 学期末に使用するHTMLタグ。例: </マーク> | |
MLT | もっと似たものを有効にしますか? | MLTを表示するかどうかを定義します |
デフォルトのフィールド | タイトル | Solr schema.xml で定義されるタイトルとして使用されるフィールド |
文章 | Solr schema.xml で定義されるタイトルとして使用されるフィールド | |
説明 | Solr schema.xml で定義される説明として使用されるフィールド | |
日付 | Solr schema.xml で定義された日付として使用されるフィールド | |
画像 | Solr schema.xml で定義される画像 URL として使用されるフィールド | |
URL | Solr schema.xml で定義される URL として使用されるフィールド |
Turing ES Console > Semantic Navigation > <SITE_NAME>で、 Configureボタンをクリックし、 Search Pageボタンをクリックします。
次のパターンを使用する検索ページが開きます。
http://localhost:2700/sn/<SITE_NAME> を取得します
このページは、AJAX 経由で Turing Rest API をリクエストします。たとえば、セマンティック ナビゲーション サイトのすべての結果を JSON 形式で返すには、次のようにします。
GET http://localhost:2700/api/sn/<SITE_NAME>/search?p=1&q=*&sort=relevance
| 属性 | 必須/オプション | 説明 | 例 |
|---|---|---|---|
q | 必須 | 検索クエリ。 | q=フー |
p | 必須 | ページ番号、最初のページは 1 です。 | p=1 |
選別 | 必須 | 値の並べ替え: | 並べ替え=関連性 |
fq[] | オプション | クエリフィールド。次のパターンを使用してフィールドでフィルターします: FIELD : VALUE 。 | fq[]=タイトル:バー |
tr[] | オプション | ターゲティング ルール。 FIELD : VALUEに基づいて検索を制限します。 | tr[]=部門:foobar |
行 | オプション | クエリが返す行数。 | 行=10 |
保険会社のイントラネットでは、OpenText WEM と、Dynamic Portal Module と統合された OpenText Portal を使用し、コネクタ: WEM、ファイル システムを備えたデータベースを使用して、統合検索が Viglet Turing ES で作成されました。このようにして、ユーザーが許可したコンテンツのみを表示できるターゲティング ルールを使用して、検索イントラネットのすべてのコンテンツとファイルを表示することができました。 OpenText ポータルは Viglet Turing ES Java API にアクセスするため、結果を返すために複雑なクエリを作成する必要はありませんでした。
API Rest のセットは、政府機関のすべてのコンテンツをパートナーが利用できるようにするために作成されました。これらのコンテンツはすべて OpenText WEM にあり、Viglet Turing ES 上のコンテンツのインデックス付けには WEM コネクタが使用されました。 Spring Boot アプリケーションは、Viglet Turing ES Java API を通じて Turing ES コンテンツを消費する Rest API セットを使用して作成されました。
ブラジル大学の Web サイトは Viglet Shima CMS (https://viglet.com/しお) を使用して開発されており、すべてのコンテンツは Viglet Turing ES で自動的にインデックス付けされます。この構成はコンテンツ モデリングで行われ、検索テンプレートの開発は Viglet Shima CMS で行われました。


