GenDataAttribution
1.0.0
プロジェクト|紙
Sheng-Yu Wang 1 、 Alexei A. Efros 2 、 Jun-Yan Zhu 1 、 Richard Zhang 3 。
カーネギーメロン大学1 、カリフォルニア大学バークレー校2 、アドビリサーチ2
ICCV では、2023 年。
大規模なテキストから画像へのモデルは「新しい」画像を合成できますが、これらの画像は必然的にトレーニング データを反映したものになります。このようなモデルにおけるデータの帰属の問題、つまり、トレーニング セット内のどの画像が、特定の生成画像の外観に最も関与しているかという問題は、難しいものの重要な問題です。この問題に対する最初のステップとして、既存の大規模モデルを特定の見本オブジェクトまたはスタイルに合わせて調整する「カスタマイズ」メソッドを通じてアトリビューションを評価します。私たちの重要な洞察は、これにより、構築による見本によって計算上の影響を受ける合成画像を効率的に作成できるということです。このような見本に影響された画像の新しいデータセットを使用すると、さまざまなデータ帰属アルゴリズムとさまざまな可能な特徴空間を評価できます。さらに、データセットでトレーニングすることにより、DINO、CLIP、ViT などの標準モデルをアトリビューション問題に合わせて調整できます。この手順は小さな見本セットに合わせて調整されていますが、より大きなセットに対する一般化を示します。最後に、問題に固有の不確実性を考慮することで、一連のトレーニング画像に対してソフト アトリビューション スコアを割り当てることができます。
conda env create -f environment.yaml
conda activate gen-attr # Download precomputed features of 1M LAION images
bash feats/download_laion_feats.sh
# Download jpeg-ed 1M LAION images for visualization
bash dataset/download_dataset.sh laion_jpeg
# Download pretrained models
bash weights/download_weights.sh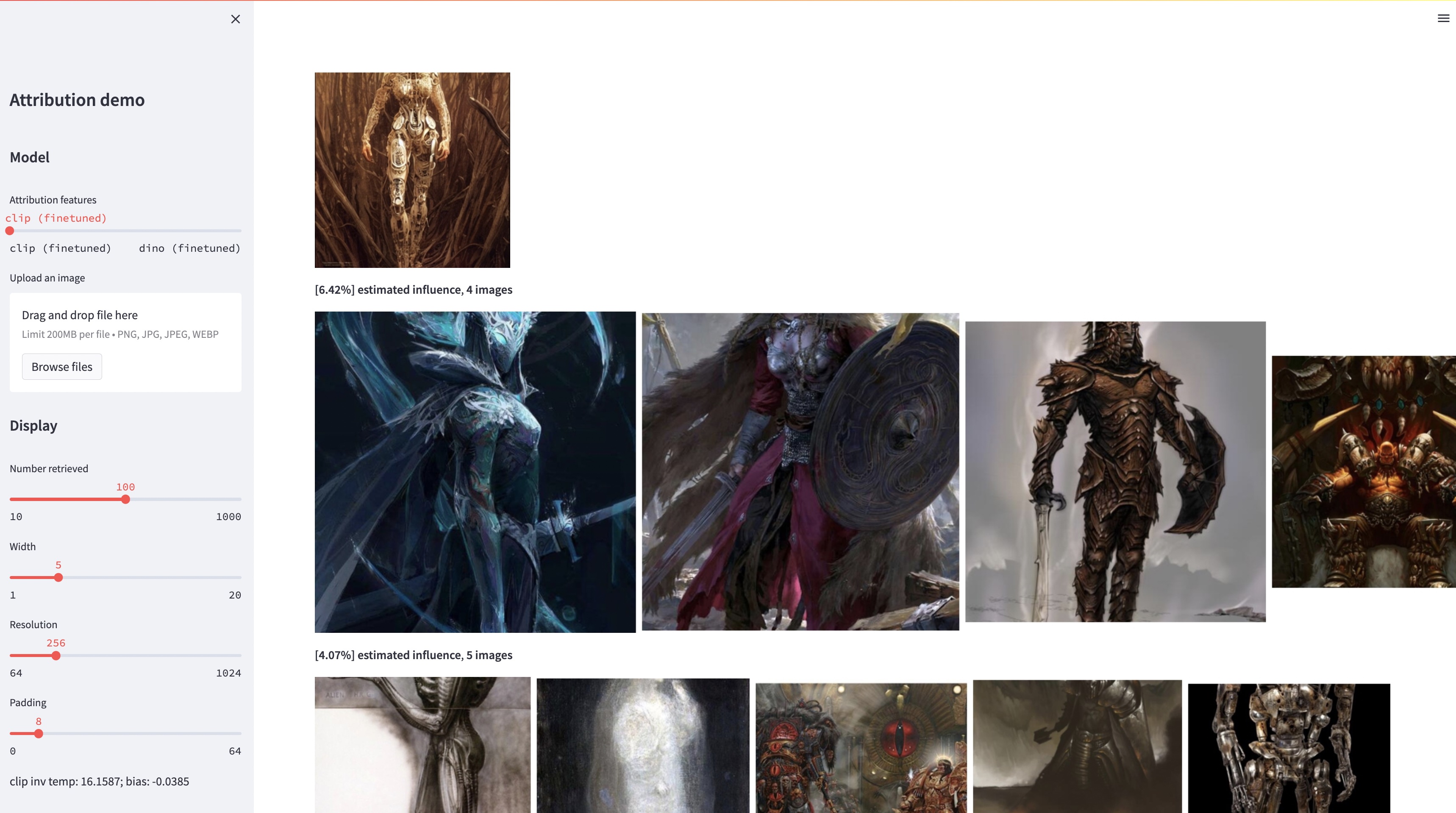
streamlit run streamlit_demo.py評価用にテストセットをリリースします。データセットをダウンロードするには:
# Download the exemplar real images
bash dataset/download_dataset.sh exemplar
# Download the testset portion of images synthesized from Custom Diffusion
bash dataset/download_dataset.sh testset
# (Optional, can download precomputed features instead!)
# Download the uncompressed 1M LAION subset in pngs
bash dataset/download_dataset.sh laionデータセットは次のように構造化されています。
dataset
├── exemplar
│ ├── artchive
│ ├── bamfg
│ └── imagenet
├── synth
│ ├── artchive
│ ├── bamfg
│ └── imagenet
├── laion_subset
└── json
├──test_artchive.json
├──test_bamfg.json
├──...
すべての見本画像はdataset/exemplarに保存され、すべての合成画像はdataset/synthに保存され、png 内の 1M laion 画像はdataset/laion_subsetに保存されます。 dataset/json内の JSON ファイルは、さまざまなテスト ケースを含む train/val/test 分割を指定し、グラウンド トゥルース ラベルとして機能します。 JSON ファイル内の各エントリは、独自に微調整されたモデルです。エントリには、微調整に使用されるサンプル画像とモデルによって生成された合成画像も記録されます。 test_artchive.json 、 test_bamfg.json 、 test_observed_imagenet.json 、およびtest_unobserved_imagenet.jsonの 4 つのテスト ケースがあります。
テストセット、事前計算された LAION 特徴、および事前トレーニングされた重みがダウンロードされたら、 extract_feat.pyを実行してテストセットから特徴を事前計算し、 eval.py実行してパフォーマンスを評価できます。以下は、評価をバッチで実行する bash スクリプトです。
# precompute all features from the testset
bash scripts/preprocess_feats.sh
# run evaluation in batches
bash scripts/run_eval.shメトリックは、 resultsの.pklファイルに保存されます。現在、スクリプトは各コマンドを順番に実行します。コマンドを並行して実行できるように自由に変更してください。次のコマンドは、 .pklファイルを解析して、 .csvファイルとして保存されるテーブルを作成します。
python results_to_csv.py 2023 年 12 月 18 日更新オブジェクト中心モデルまたはスタイル中心モデルでのみトレーニングされたモデルをダウンロードするには、 bash weights/download_style_object_ablation.shを実行します。
@inproceedings{wang2023evaluating,
title={Evaluating Data Attribution for Text-to-Image Models},
author={Wang, Sheng-Yu and Efros, Alexei A. and Zhu, Jun-Yan and Zhang, Richard},
booktitle={ICCV},
year={2023}
}
以前の草稿を読み、洞察力に富んだフィードバックをくださった Aaron Hertzmann に感謝します。 Eli Shechtman 氏、Oliver Wang 氏、Nick Kolkin 氏、Taesung Park 氏、John Collomosse 氏、Sylvain Paris 氏を含む Adobe Research の同僚に、有益な議論をしていただいた Alex Li 氏と Yonglong Tian 氏に感謝します。カスタム拡散トレーニングの指導については Nupur Kumari 氏、ドラフトの校正については Ruihan Gao 氏、安定拡散特徴を抽出するためのポインタについては Alex Li 氏、BAM-FG データセットについては Dan Ruta 氏に感謝します。パンデミックハイキングとブレインストーミングをしてくれたブライアン・ラッセルに感謝します。この取り組みは、SYW が Adobe インターンだったときに始まり、Adobe ギフトと JP モルガン チェース学部研究賞によって部分的に支援されました。


