mind x
1.0.0

このプロジェクトは、これらのモデルの急速な成長に合わせて、パーソナル アシスタントとしてのパーソナライズされた LLM (または LMM) の実現可能性を実証します。
私たちは、コンテキスト境界がある従来のプロンプト チューニングと、リアルタイムのデータ更新や幻覚の問題に悩まされるファイン チューニングの制限を克服するために、検索拡張生成 (RAG) 手法を導入しました。
従来、RAG はストアとして LangChain を介して Chroma などのデータベースを検索するために使用されてきましたが、この方法は固定コンテキスト内で動作するため制限がありました。
そこで、独自の RAG システムを構築する予定です。このプロセスには、LangChain が提供する推論と回帰の問題への対処が含まれる場合があります。
私たちは迅速な開発に取り組んでおり、間もなく多言語互換性を実現する予定です。現在、このシステムは英語を完全にサポートしていますが、近いうちに韓国語、日本語、その他の言語もサポートする予定です。さらに、回帰システムと推論システムも間もなく組み込まれる予定です。
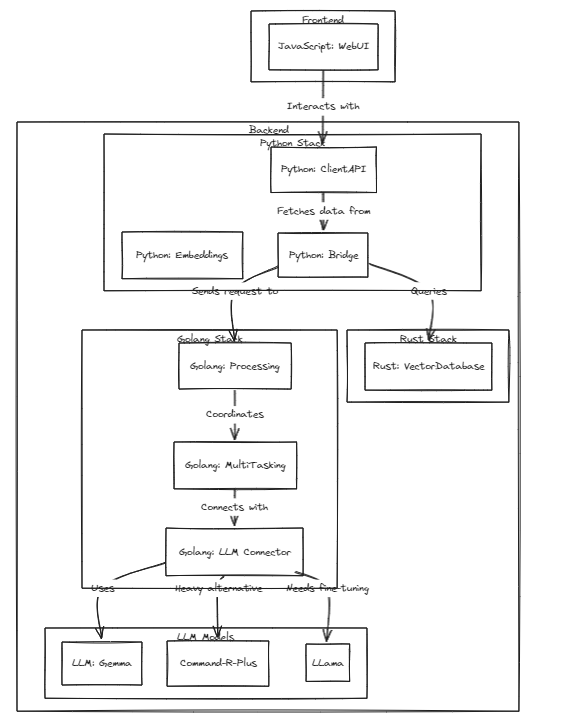
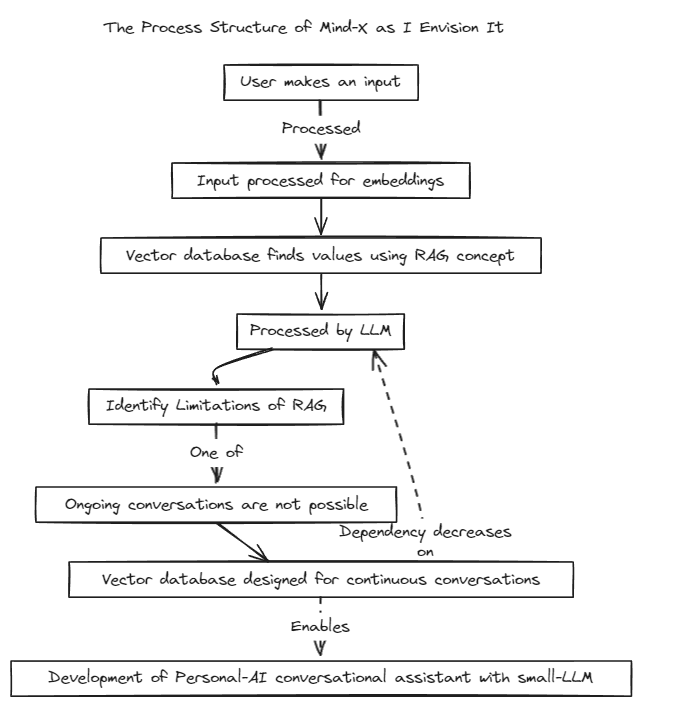
テストを実行するには、次のコマンドを実行します
# start embeddings server
cd embd & pip install -r requirements.txt
python app.py
# start mindx-v server (vector-database)
# not using cgo, only assembly
cd mindx-v & go run cmd/mxvd/main.go
# start processor server
cd processor & go run cmd/main.go
# start demo client
cd sample_client & npm start
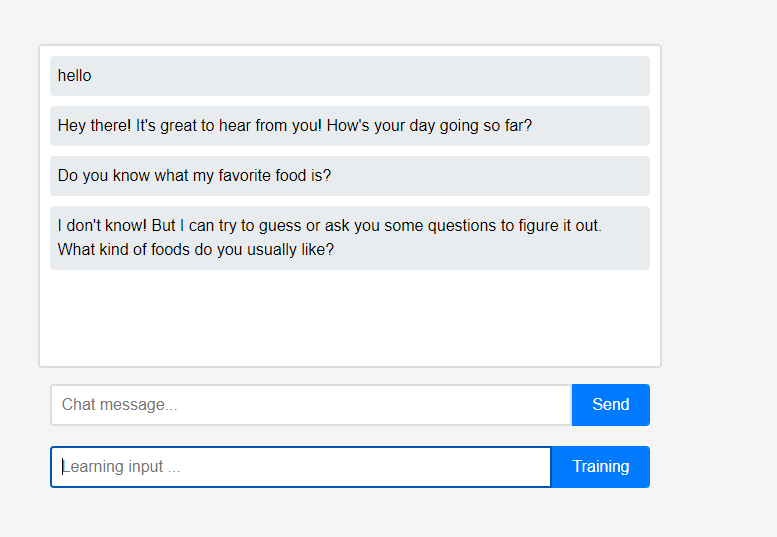 最初、アシスタントはユーザーについて何も知りません。
最初、アシスタントはユーザーについて何も知りません。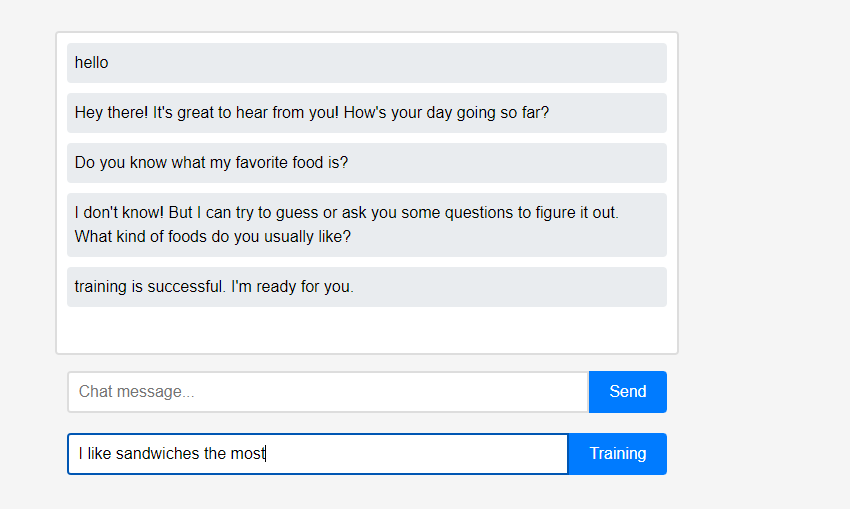 ただし、ユーザーはアシスタントに自分自身についてリアルタイムで教えることができます。
ただし、ユーザーはアシスタントに自分自身についてリアルタイムで教えることができます。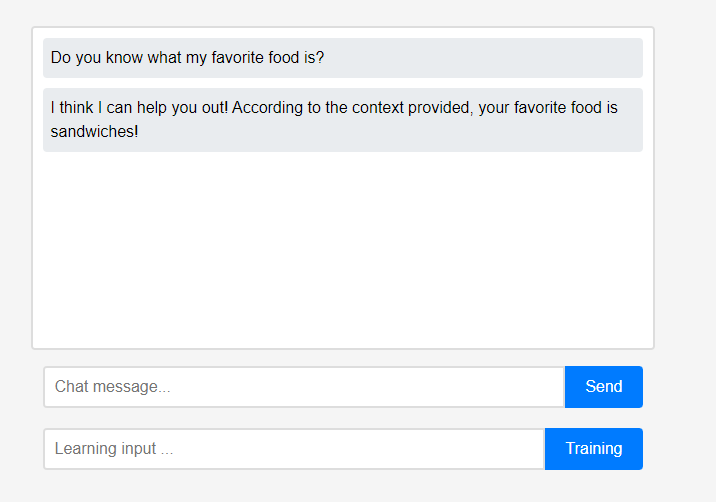 (LLMの特性上、学習ではなく会話連鎖として記憶されていると誤解される可能性があるため、リフレッシュしてから行っています。) 学習したデータはすぐに反映されており、これはアシスタントの最初のパーソナライゼーションと言えます。
(LLMの特性上、学習ではなく会話連鎖として記憶されていると誤解される可能性があるため、リフレッシュしてから行っています。) 学習したデータはすぐに反映されており、これはアシスタントの最初のパーソナライゼーションと言えます。
プロジェクトのこれらすべての機能は、外部のクラウド統合やインターネット接続を必要とせずに、ローカルでサポートできます。



query = protobuf . search_pb2 . SearchRequest (
dataset_id = dataset_id ,
query = get_image_embedding ( "./test_data/bad.png" ),
k = 1
)
results = search . Search ( query )
try :
for result in results :
print ( "Search result:" , result . id , result . metadata , result . score )
except grpc . RpcError as e :
print ( "Search failed:" , e )
query = protobuf . search_pb2 . SearchRequest (
dataset_id = dataset_id ,
query = get_image_embedding ( "./test_data/good.png" ),
k = 1
)
results = search . Search ( query )
try :
for result in results :
print ( "Search result:" , result . id , result . metadata , result . score )
except grpc . RpcError as e :
print ( "Search failed:" , e )


