vaex
Version linked to the paper
Vaex は、大きな表形式のデータセットを視覚化して探索するための、遅延アウトオブコア データフレーム(Pandas と同様) 用の高性能 Python ライブラリです。 N 次元グリッド上で1 秒あたり10 億( 10^9 ) サンプル/行を超える平均、合計、カウント、標準偏差などの統計を計算します。ヒストグラム、密度プロット、 3D ボリューム レンダリングを使用して視覚化が行われ、ビッグ データのインタラクティブな探索が可能になります。 Vaex は、最高のパフォーマンス (メモリの無駄なし) を実現するために、メモリ マッピング、ゼロ メモリ コピー ポリシー、遅延計算を使用します。
ピップの場合:
$ pip install vaex
またはコンダ:
$ conda install -c conda-forge vaex
詳細については、ドキュメントを参照してください
HDF5 と Apache Arrow がサポートされています。

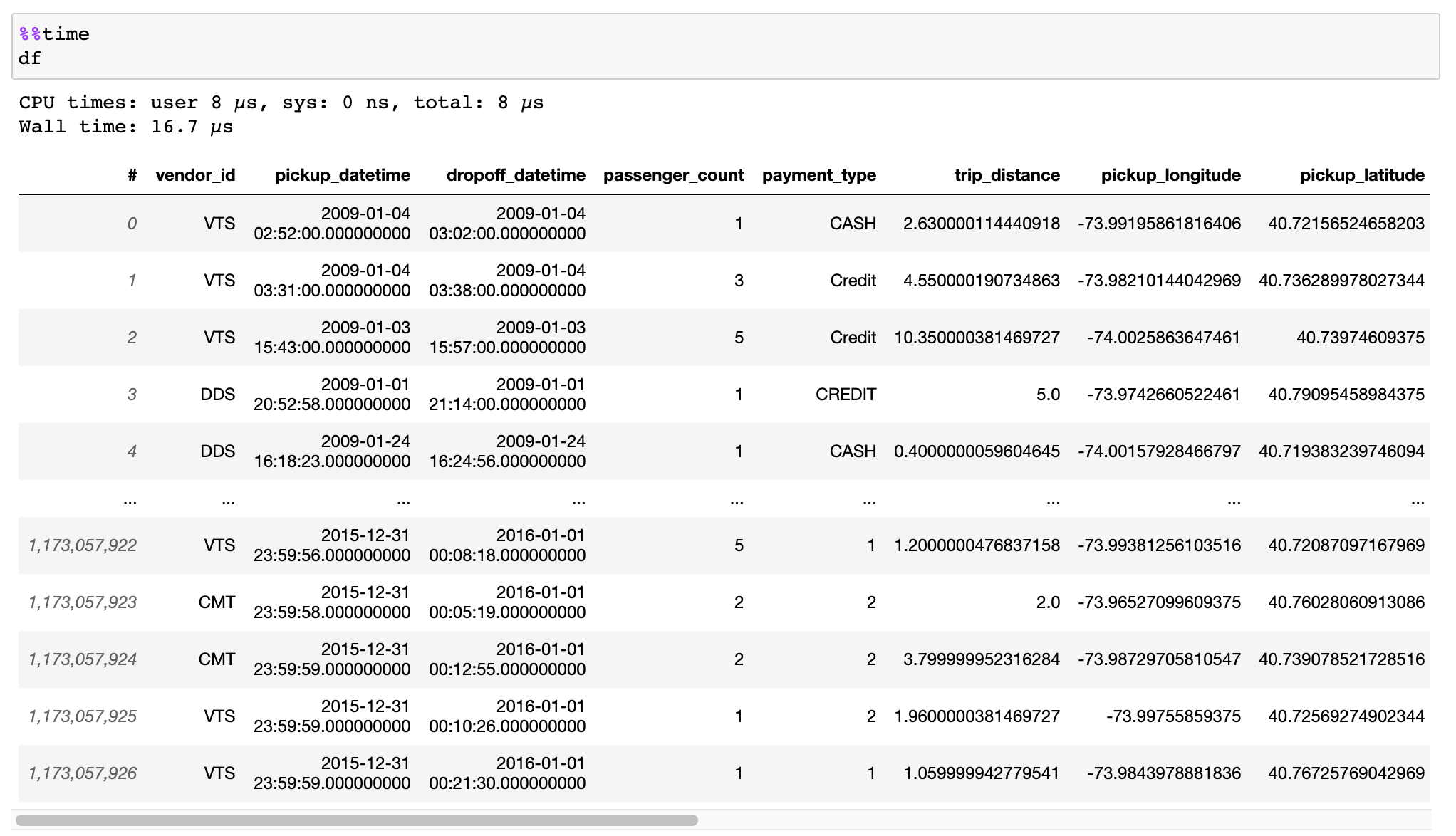
CSV ファイル、Pandas DataFrames、またはその他のソースからデータを効率的に変換する方法に関するドキュメントをお読みください。
S3 からの遅延ストリーミングは、メモリ マッピングと組み合わせてサポートされます。

特徴量エンジニアリングでメモリや時間を無駄にする必要はありません。必要に応じてデータを (遅延的に) 変換します。
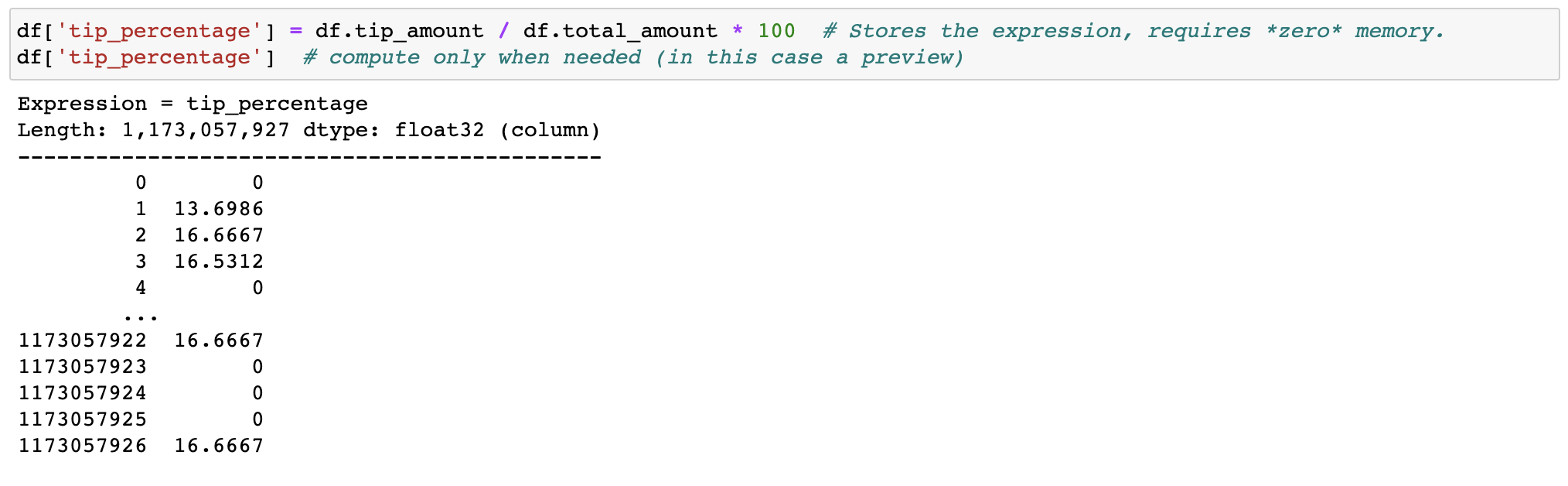
式のフィルタリングと評価では、コピーを作成してメモリを浪費することはありません。データはディスク上にそのまま保持され、必要な場合にのみストリーミングされます。クラスターが必要になるまでの時間を遅らせます。
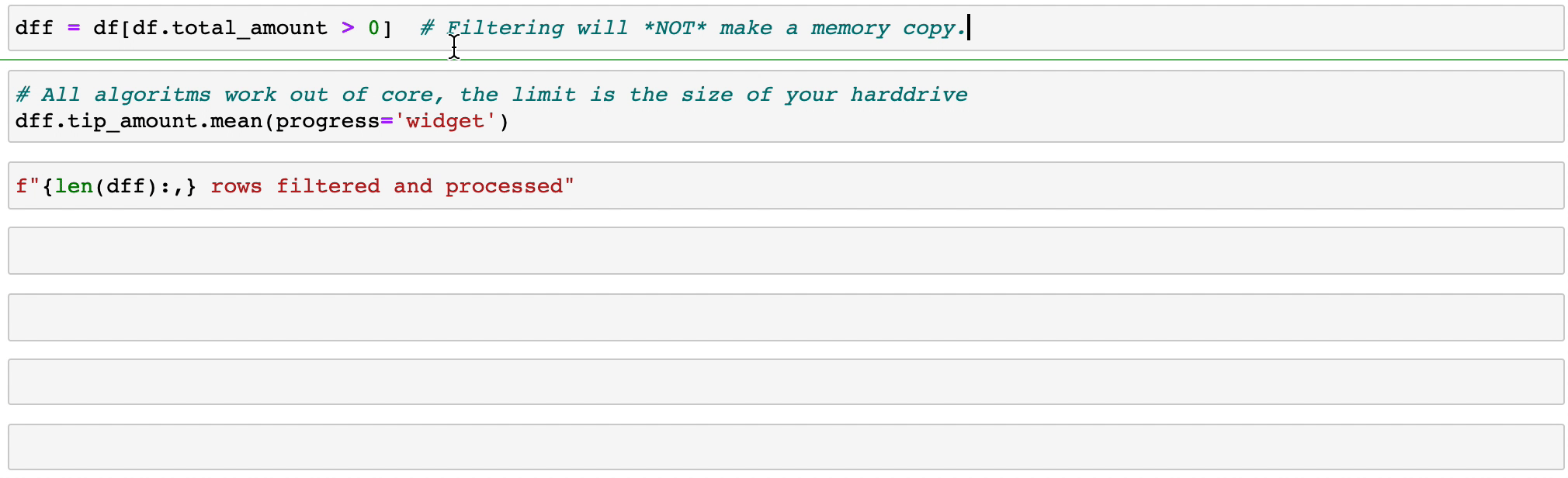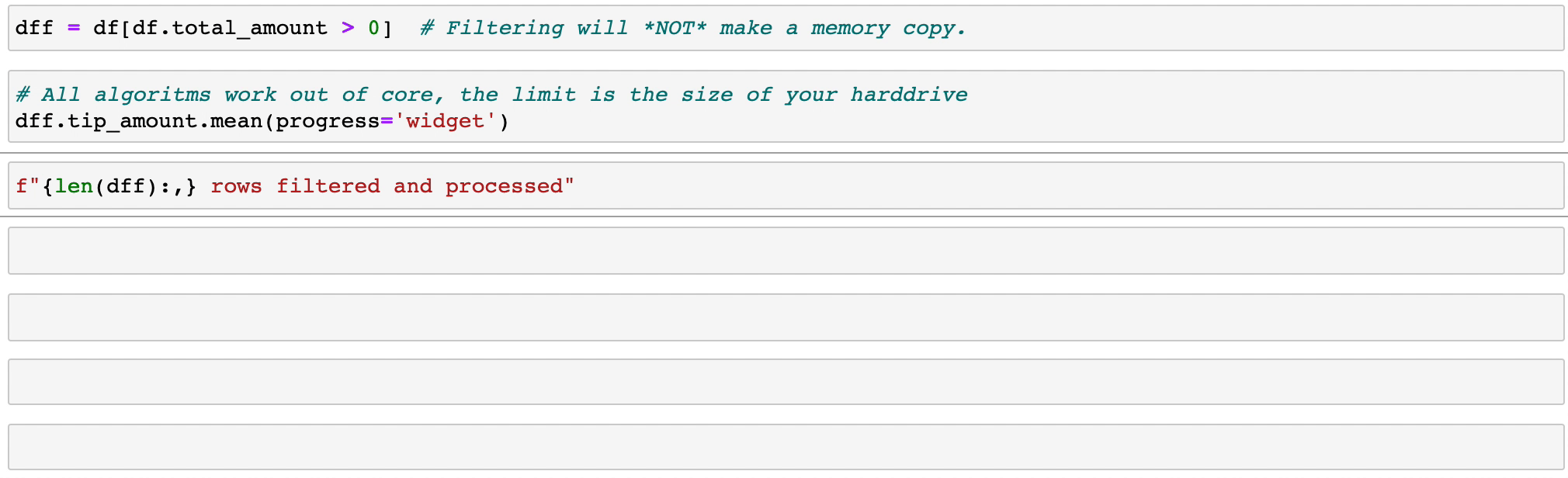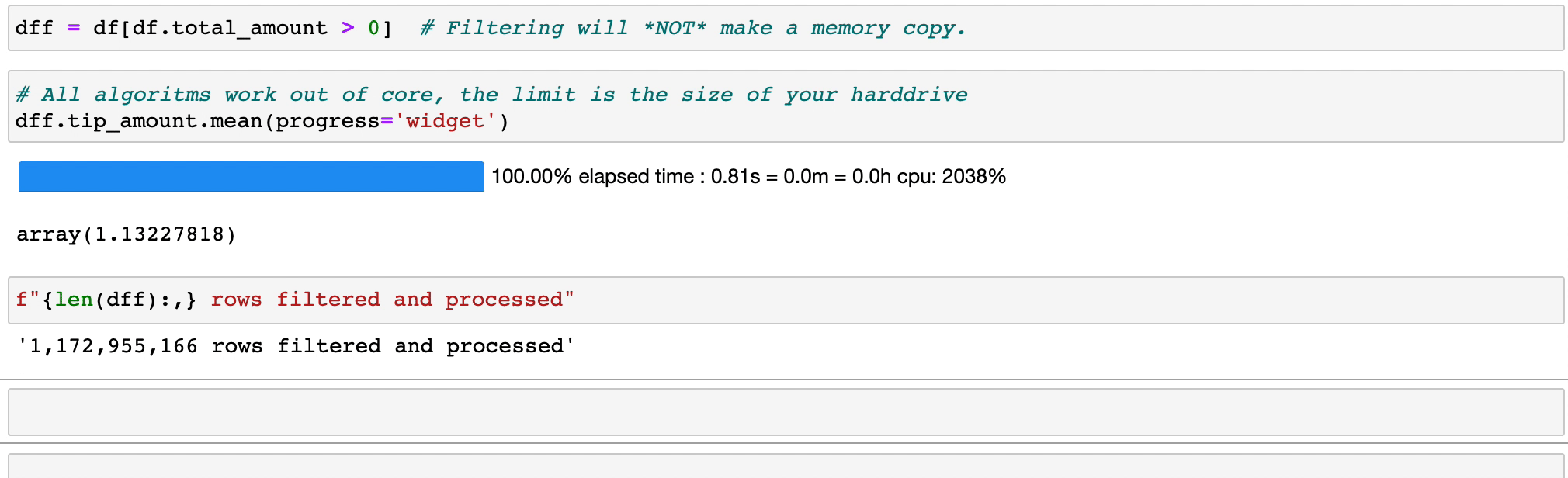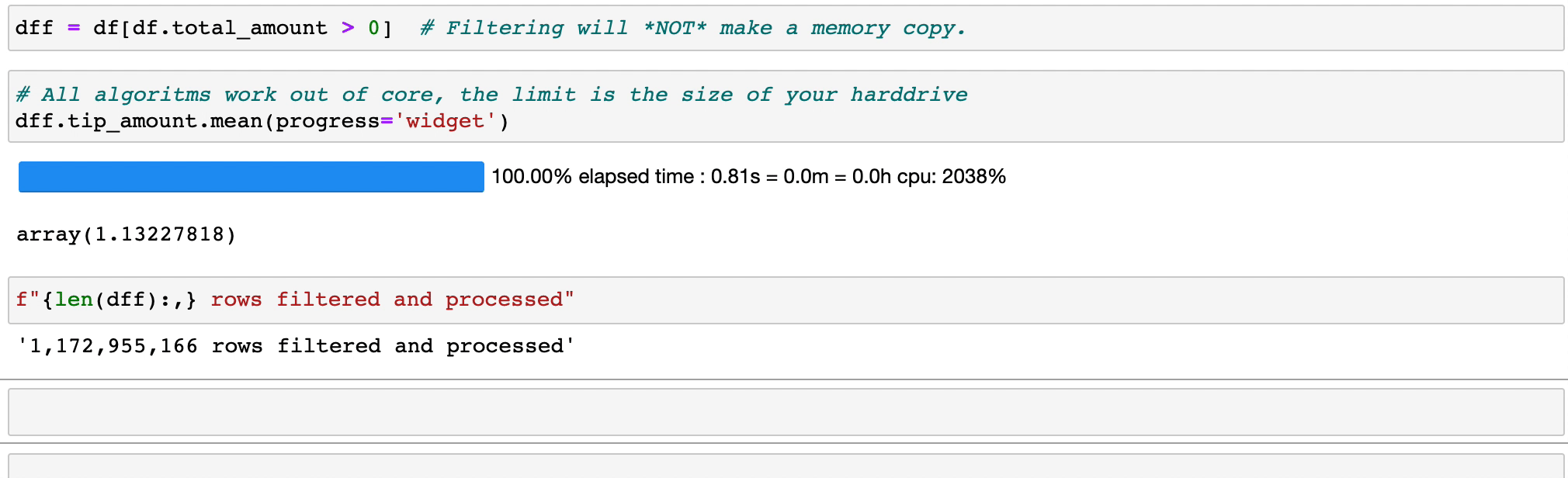
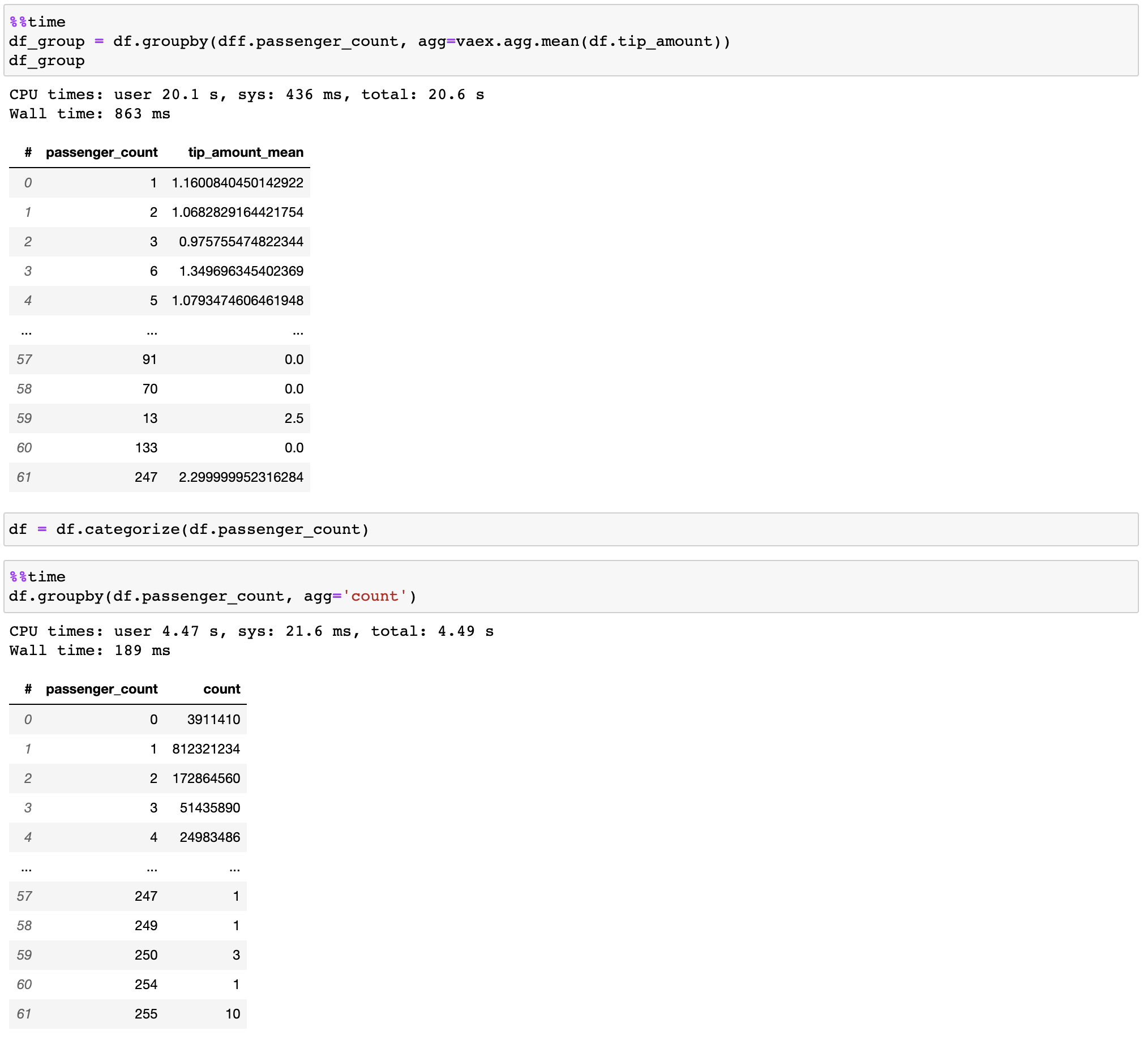
Vaex は、特にカテゴリを使用する場合 (10 億/秒以上)、並列化された高パフォーマンスのgroupby操作を実装します。
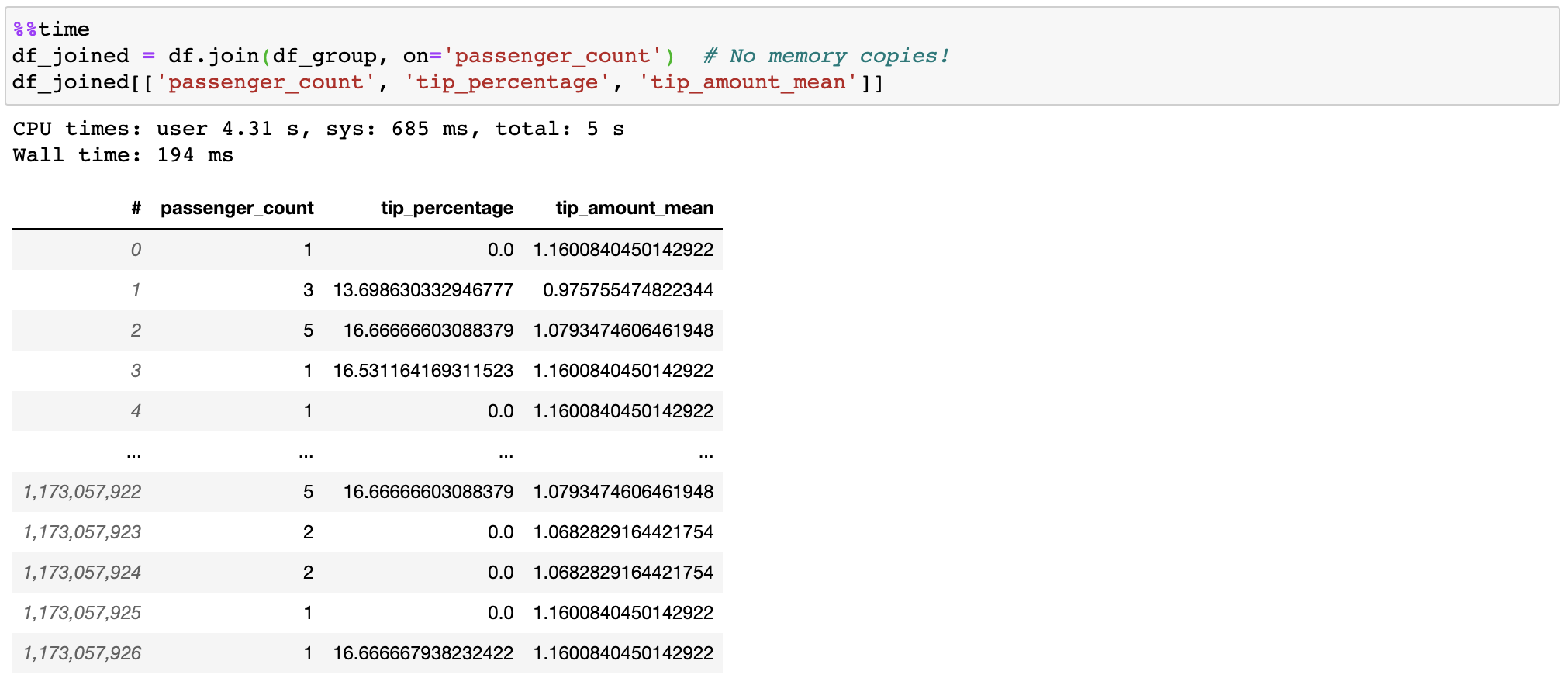
Vaex は結合時に「正しい」テーブルをコピー/実体化しないため、ギガバイトのメモリを節約できます。 10 億行を 1 秒未満で結合できるため、非常に高速です。
寄稿ページを参照してください。
Slack チャンネルでディスカッションに参加してください。
記事
チュートリアルに従ってください
最近の講演をご覧ください:
データ サイエンス ソリューション、トレーニング、エンタープライズ サポートについては、https://vaex.io/ からお問い合わせください。


