stumpy
v1.13.0

STUMPY は強力でスケーラブルな Python ライブラリで、マトリックス プロファイルと呼ばれるものを効率的に計算します。マトリックス プロファイルは、「時系列内のすべての (緑色の) サブシーケンスについて、対応する最近傍 (灰色) を自動的に識別する」ということを学術的に表現したものにすぎません。
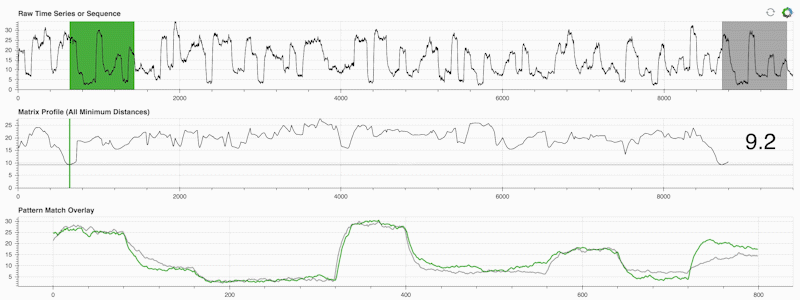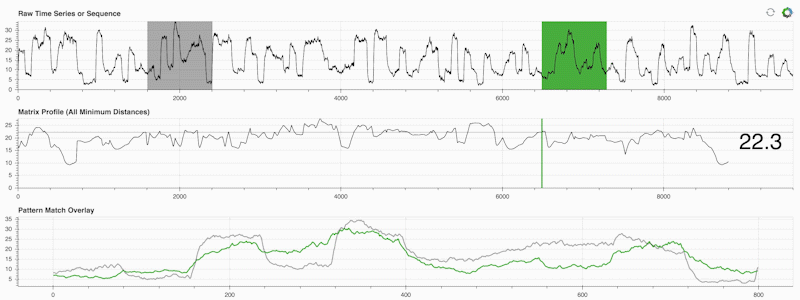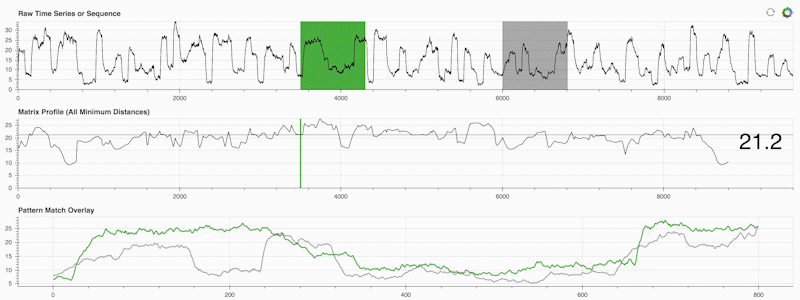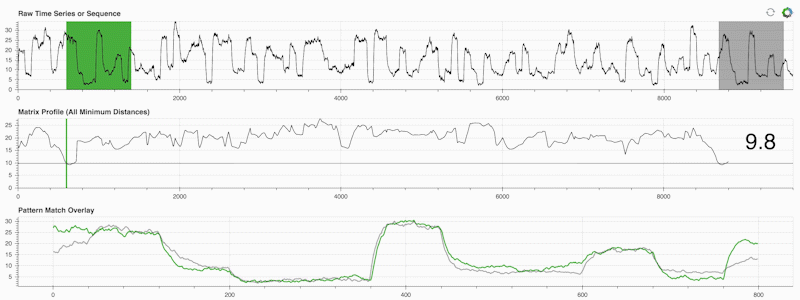
重要なのは、マトリックス プロファイル (上の中央のパネル) を計算したら、次のようなさまざまな時系列データ マイニング タスクに使用できることです。
学者、データ サイエンティスト、ソフトウェア開発者、または時系列愛好家であっても、STUMPY は簡単にインストールできます。私たちの目標は、時系列の洞察をより早く得られるようにすることです。詳細については、ドキュメントを参照してください。
利用可能な関数の完全なリストについては API ドキュメントを参照し、より包括的な使用例については有益なチュートリアルを参照してください。以下に、STUMPY の使用方法を簡単に示すコード スニペットを示します。
STUMP の一般的な使用法 (1 次元の時系列データ):
import stumpy
import numpy as np
if __name__ == "__main__" :
your_time_series = np . random . rand ( 10000 )
window_size = 50 # Approximately, how many data points might be found in a pattern
matrix_profile = stumpy . stump ( your_time_series , m = window_size )Dask Distributed via STUMPED による 1 次元時系列データの分散使用:
import stumpy
import numpy as np
from dask . distributed import Client
if __name__ == "__main__" :
with Client () as dask_client :
your_time_series = np . random . rand ( 10000 )
window_size = 50 # Approximately, how many data points might be found in a pattern
matrix_profile = stumpy . stumped ( dask_client , your_time_series , m = window_size )GPU-STUMP を使用した 1 次元時系列データの GPU 使用率:
import stumpy
import numpy as np
from numba import cuda
if __name__ == "__main__" :
your_time_series = np . random . rand ( 10000 )
window_size = 50 # Approximately, how many data points might be found in a pattern
all_gpu_devices = [ device . id for device in cuda . list_devices ()] # Get a list of all available GPU devices
matrix_profile = stumpy . gpu_stump ( your_time_series , m = window_size , device_id = all_gpu_devices )MSTUMP を使用した多次元時系列データ:
import stumpy
import numpy as np
if __name__ == "__main__" :
your_time_series = np . random . rand ( 3 , 1000 ) # Each row represents data from a different dimension while each column represents data from the same dimension
window_size = 50 # Approximately, how many data points might be found in a pattern
matrix_profile , matrix_profile_indices = stumpy . mstump ( your_time_series , m = window_size )Dask Distributed MSTUMPED を使用した分散多次元時系列データ分析:
import stumpy
import numpy as np
from dask . distributed import Client
if __name__ == "__main__" :
with Client () as dask_client :
your_time_series = np . random . rand ( 3 , 1000 ) # Each row represents data from a different dimension while each column represents data from the same dimension
window_size = 50 # Approximately, how many data points might be found in a pattern
matrix_profile , matrix_profile_indices = stumpy . mstumped ( dask_client , your_time_series , m = window_size )アンカー時系列チェーンを使用した時系列チェーン (ATSC):
import stumpy
import numpy as np
if __name__ == "__main__" :
your_time_series = np . random . rand ( 10000 )
window_size = 50 # Approximately, how many data points might be found in a pattern
matrix_profile = stumpy . stump ( your_time_series , m = window_size )
left_matrix_profile_index = matrix_profile [:, 2 ]
right_matrix_profile_index = matrix_profile [:, 3 ]
idx = 10 # Subsequence index for which to retrieve the anchored time series chain for
anchored_chain = stumpy . atsc ( left_matrix_profile_index , right_matrix_profile_index , idx )
all_chain_set , longest_unanchored_chain = stumpy . allc ( left_matrix_profile_index , right_matrix_profile_index )高速かつ低コストの Unipotent Semantic Semantic Segmentation (FLUSS) によるセマンティック セグメンテーション:
import stumpy
import numpy as np
if __name__ == "__main__" :
your_time_series = np . random . rand ( 10000 )
window_size = 50 # Approximately, how many data points might be found in a pattern
matrix_profile = stumpy . stump ( your_time_series , m = window_size )
subseq_len = 50
correct_arc_curve , regime_locations = stumpy . fluss ( matrix_profile [:, 1 ],
L = subseq_len ,
n_regimes = 2 ,
excl_factor = 1
)サポートされる Python および NumPy のバージョンは、NEP 29 の非推奨ポリシーに従って決定されます。
Conda のインストール (推奨):
conda install -c conda-forge stumpynumpy、scipy、numba がインストールされていることを前提として、PyPI をインストールします。
python -m pip install stumpystumpy をソースからインストールするには、ドキュメントの手順を参照してください。
基礎となるアルゴリズムとアプリケーションを完全に理解して評価するには、元の出版物を読むことが不可欠です。 STUMPY の使用方法の詳細な例については、最新のドキュメントを参照するか、実践的なチュートリアルを参照してください。
さまざまな CPU および GPU ハードウェア リソースとともに、さまざまな長さでランダムに生成された時系列データ (つまり、 np.random.rand(n) ) に対してコードの Numba JIT コンパイル バージョンを使用して、正確な行列プロファイルを計算するパフォーマンスをテストしました。
生の結果は、時間:分:秒.ミリ秒として、一定のウィンドウ サイズ m = 50 で下の表に表示されます。これらの報告された実行時間には、ホストからすべてのホストにデータを移動するのにかかる時間が含まれていることに注意してください。 GPU デバイス。すべてのランタイムを表示するには、表の右側にスクロールする必要がある場合があります。
| 私 | n = 2 i | GPU-ストンプ | スタンプ.2 | スタンプ.16 | 困った.128 | 困惑.256 | GPU-スタンプ.1 | GPU-スタンプ.2 | GPU-スタンプ.DGX1 | GPU-スタンプ.DGX2 |
|---|---|---|---|---|---|---|---|---|---|---|
| 6 | 64 | 00:00:10.00 | 00:00:00.00 | 00:00:00.00 | 00:00:05.77 | 00:00:06.08 | 00:00:00.03 | 00:00:01.63 | NaN | NaN |
| 7 | 128 | 00:00:10.00 | 00:00:00.00 | 00:00:00.00 | 00:00:05.93 | 00:00:07.29 | 00:00:00.04 | 00:00:01.66 | NaN | NaN |
| 8 | 256 | 00:00:10.00 | 00:00:00.00 | 00:00:00.01 | 00:00:05.95 | 00:00:07.59 | 00:00:00.08 | 00:00:01.69 | 00:00:06.68 | 00:00:25.68 |
| 9 | 512 | 00:00:10.00 | 00:00:00.00 | 00:00:00.02 | 00:00:05.97 | 00:00:07.47 | 00:00:00.13 | 00:00:01.66 | 00:00:06.59 | 00:00:27.66 |
| 10 | 1024 | 00:00:10.00 | 00:00:00.02 | 00:00:00.04 | 00:00:05.69 | 00:00:07.64 | 00:00:00.24 | 00:00:01.72 | 00:00:06.70 | 00:00:30.49 |
| 11 | 2048年 | NaN | 00:00:00.05 | 00:00:00.09 | 00:00:05.60 | 00:00:07.83 | 00:00:00.53 | 00:00:01.88 | 00:00:06.87 | 00:00:31.09 |
| 12 | 4096 | NaN | 00:00:00.22 | 00:00:00.19 | 00:00:06.26 | 00:00:07.90 | 00:00:01.04 | 00:00:02.19 | 00:00:06.91 | 00:00:33.93 |
| 13 | 8192 | NaN | 00:00:00.50 | 00:00:00.41 | 00:00:06.29 | 00:00:07.73 | 00:00:01.97 | 00:00:02.49 | 00:00:06.61 | 00:00:33.81 |
| 14 | 16384 | NaN | 00:00:01.79 | 00:00:00.99 | 00:00:06.24 | 00:00:08.18 | 00:00:03.69 | 00:00:03.29 | 00:00:07.36 | 00:00:35.23 |
| 15 | 32768 | NaN | 00:00:06.17 | 00:00:02.39 | 00:00:06.48 | 00:00:08.29 | 00:00:07.45 | 00:00:04.93 | 00:00:07.02 | 00:00:36.09 |
| 16 | 65536 | NaN | 00:00:22.94 | 00:00:06.42 | 00:00:07.33 | 00:00:09.01 | 00:00:14.89 | 00:00:08.12 | 00:00:08.10 | 00:00:36.54 |
| 17 | 131072 | 00:00:10.00 | 00:01:29.27 | 00:00:19.52 | 00:00:09.75 | 00:00:10.53 | 00:00:29.97 | 00:00:15.42 | 00:00:09.45 | 00:00:37.33 |
| 18 | 262144 | 00:00:18.00 | 00:05:56.50 | 00:01:08.44 | 00:00:33.38 | 00:00:24.07 | 00:00:59.62 | 00:00:27.41 | 00:00:13.18 | 00:00:39.30 |
| 19 | 524288 | 00:00:46.00 | 00:25:34.58 | 00:03:56.82 | 00:01:35.27 | 00:03:43.66 | 00:01:56.67 | 00:00:54.05 | 00:00:19.65 | 00:00:41.45 |
| 20 | 1048576 | 00:02:30.00 | 01:51:13.43 | 00:19:54.75 | 00:04:37.15 | 00:03:01.16 | 00:05:06.48 | 00:02:24.73 | 00:00:32.95 | 00:00:46.14 |
| 21 | 2097152 | 00:09:15.00 | 09:25:47.64 | 03:05:07.64 | 00:13:36.51 | 00:08:47.47 | 00:20:27.94 | 00:09:41.43 | 00:01:06.51 | 00:01:02.67 |
| 22 | 4194304 | NaN | 36:12:23.74 | 10:37:51.21 | 00:55:44.43 | 00:32:06.70 | 01:21:12.33 | 00:38:30.86 | 00:04:03.26 | 00:02:23.47 |
| 23 | 8388608 | NaN | 143:16:09.94 | 38:42:51.42 | 03:33:30.53 | 02:00:49.37 | 05:11:44.45 | 02:33:14.60 | 00:15:46.26 | 00:08:03.76 |
| 24 | 16777216 | NaN | NaN | NaN | 14:39:11.99 | 07:13:47.12 | 20:43:03.80 | 09:48:43.42 | 01:00:24.06 | 00:29:07.84 |
| NaN | 17729800 | 09:16:12.00 | NaN | NaN | 15:31:31.75 | 07:18:42.54 | 23:09:22.43 | 10:54:08.64 | 01:07:35.39 | 00:32:51.55 |
| 25 | 33554432 | NaN | NaN | NaN | 56:03:46.81 | 26:27:41.29 | 83:29:21.06 | 39:17:43.82 | 03:59:32.79 | 01:54:56.52 |
| 26 | 67108864 | NaN | NaN | NaN | 211:17:37.60 | 106:40:17.17 | 328:58:04.68 | 157:18:30.50 | 15:42:15.94 | 07:18:52.91 |
| NaN | 100000000 | 291:07:12.00 | NaN | NaN | NaN | 234:51:35.39 | NaN | NaN | 35:03:44.61 | 16:22:40.81 |
| 27 | 134217728 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 64:41:55.09 | 29:13:48.12 |
GPU-STOMP: これらの結果は、元の Matrix Profile II 論文 - NVIDIA Tesla K80 (2 つの GPU を含む) から再現されており、比較するパフォーマンス ベンチマークとして機能します。
STUMP.2: stumpy.stump は合計 2 つの CPU で実行されました - Dask なしの単一サーバー上の Numba と並列化された 2x Intel(R) Xeon(R) CPU E5-2650 v4 @ 2.20GHz プロセッサ。
STUMP.16: stumpy.stump は合計 16 個の CPU で実行されました - Dask なしの単一サーバー上で、Numba と並列化された 16 個の Intel(R) Xeon(R) CPU E5-2650 v4 @ 2.20GHz プロセッサー。
STUMPED.128: stumpy.stumped は合計 128 個の CPU で実行されました - 8x Intel(R) Xeon(R) CPU E5-2650 v4 @ 2.20GHz プロセッサ x 16 サーバー、Numba で並列処理され、Dask Distributed で分散されました。
STUMPED.256: stumpy.stumped は合計 256 個の CPU で実行されました - 8x Intel(R) Xeon(R) CPU E5-2650 v4 @ 2.20GHz プロセッサ x 32 サーバー、Numba で並列処理、Dask Distributed で分散されました。
GPU-STUMP.1: stumpy.gpu_stump は 1x NVIDIA GeForce GTX 1080 Ti GPU、ブロックあたり 512 スレッド、電力制限 200W で実行され、Numba で CUDA にコンパイルされ、Python マルチプロセッシングで並列化されます。
GPU-STUMP.2: stumpy.gpu_stump は 2x NVIDIA GeForce GTX 1080 Ti GPU、ブロックあたり 512 スレッド、電力制限 200W で実行され、Numba で CUDA にコンパイルされ、Python マルチプロセッシングで並列化されます。
GPU-STUMP.DGX1: stumpy.gpu_stump は 8x NVIDIA Tesla V100、ブロックあたり 512 スレッドで実行され、Numba で CUDA にコンパイルされ、Python マルチプロセッシングで並列化されました。
GPU-STUMP.DGX2: stumpy.gpu_stump は 16x NVIDIA Tesla V100、ブロックあたり 512 スレッドで実行され、Numba で CUDA にコンパイルされ、Python マルチプロセッシングで並列化されました。
テストは、 testsディレクトリに記述され、PyTest を使用して処理されます。コード カバレッジ分析には、 coverage.pyが必要です。テストは以下を使用して実行できます。
./test.shSTUMPY は Python 3.9 以降をサポートしていますが、Unicode 変数名/識別子を使用しているため、Python 2.x とは互換性がありません。依存関係が小さいため、STUMPY は古いバージョンの Python でも動作する可能性がありますが、これはサポートの範囲外であるため、最新バージョンの Python にアップグレードすることを強くお勧めします。
まず、Github 上のディスカッションと問題をチェックして、そこで質問がすでに回答されているかどうかを確認してください。解決策が見つからない場合は、自由に新しいディスカッションや問題を作成してください。著者は適切なタイミングで対応するよう努めます。
どのような形でも寄付を歓迎します。ドキュメント、特に拡張チュートリアルに関する支援はいつでも歓迎します。貢献するには、プロジェクトをフォークし、変更を加え、プル リクエストを送信してください。私たちは、お客様との問題を解決し、コードをメイン ブランチにマージできるよう最善を尽くします。
このコードベースを科学出版物で使用しており、引用したい場合は、Journal of Open Source Software の記事を使用してください。
SM 法、(2019)。 STUMPY: 時系列データ マイニング用の強力でスケーラブルな Python ライブラリ。オープンソース ソフトウェアジャーナル、4(39)、1504。
@article { law2019stumpy ,
author = { Law, Sean M. } ,
title = { {STUMPY: A Powerful and Scalable Python Library for Time Series Data Mining} } ,
journal = { {The Journal of Open Source Software} } ,
volume = { 4 } ,
number = { 39 } ,
pages = { 1504 } ,
year = { 2019 }
}イェー、チンチア・マイケル 他(2016) マトリックス プロファイル I: 時系列のすべてのペアの類似性結合: モチーフ、不協和音、シェイプレットを含む統一ビュー。 ICDM:1317-1322。リンク
朱、燕、他(2016) マトリックス プロファイル II: 新しいアルゴリズムと GPU を活用して、時系列モチーフと結合の 1 億の壁を突破します。 ICDM:739-748。リンク
イェー、チンチア・マイケル 他(2017) マトリックス プロファイル VI: 意味のある多次元モチーフの発見。 ICDM:565-574。リンク
朱、燕、他(2017) マトリックス プロファイル VII: 時系列チェーン: 時系列データ マイニングの新しいプリミティブ。 ICDM:695-704。リンク
ガルガビ、シャガイェグ、他。 (2017) マトリックス プロファイル VIII: 超人的なパフォーマンス レベルでのドメインに依存しないオンライン セマンティック セグメンテーション。 ICDM:117-126。リンク
朱、燕、他(2017) 新しいアルゴリズムと GPU を活用して、時系列モチーフと結合に対する 10 京兆のペアごとの比較の障壁を突破します。 KAIS:203-236。リンク
朱、燕、他(2018) マトリックス プロファイル XI: SCRIMP++: インタラクティブな速度での時系列モチーフの発見。 ICDM:837-846。リンク
イェー、チンチア・マイケル 他(2018) 時系列結合、モチーフ、不協和音、シェイプレット: マトリックス プロファイルを活用する統一ビュー。データ最小知識ディスク:83-123。リンク
ガルガビ、シャガイェグ、他。 (2018) 「マトリックス プロファイル XII: MPdist: より困難なシナリオでのデータ マイニングを可能にする新しい時系列距離測定。」 ICDM:965-970。リンク
ジマーマン、ザカリー、他(2019) マトリックス プロファイル XIV: GPU を使用した時系列モチーフ発見のスケーリングにより、1 日に数京のペアごとの比較が可能になり、それ以降も可能になります。 SoCC '19:74-86。リンク
アクバリニア、レザー、ベトランド・クロエズ。 (2019) 異なる距離関数を使用した効率的な行列プロファイル計算。 arXiv:1901.05708。リンク
カムガー、カヴェ、他(2019) マトリックス プロファイル XV: 時系列コンセンサス モチーフを利用して時系列セット内の構造を見つける。 ICDM:1156-1161。リンク


