3DDFA
1.0.0
郭建柱著。

【更新情報】
2022.5.14 : 顔プロファイリングの Python 実装を推奨: face_pose_augmentation。2020.8.30 : ECCV-20 の事前学習済みモデルとコードが 3DDFA_V2 で公開され、著作権については Jianzhu Guo と CBSR グループが説明しています。2020.8.2 : このプロジェクトのシンプルな C++ ポートを更新しました。2020.7.3 : Towards Fast, Accurate and Stable 3D Dense Face Alignment の拡張作業が ECCV 2020 に受理されました。 詳細については、私のページをご覧ください。2019.9.15 : いくつかの更新。詳細についてはコミットを参照してください。2019.6.17 : zjjMaiMai さんによるデモ動画を追加しました。2019.5.2 : PyTorch v1.1.0 を使用した CPU での推論速度の評価。こことspeed_cpu.pyを参照してください。2019.4.27 : ~25ms/フレーム (720p) で実行される単純なレンダリング パイプライン。詳細については、rendering.py を参照してください。2019.4.24 : obama のデモ構築を提供します。詳細については、demo@ovama/readme.md を参照してください。2019.3.28 : 一部更新。2018.12.23 :深度画像推定、PNCC、PAF 機能、obj シリアル化などの機能を追加しました。詳細については、 dump_depth 、 dump_pncc 、 dump_paf 、 dump_objオプションを参照してください。2018.12.2 : ランドマークフリーの顔トリミングをサポートしますdlib_landmarkオプションを参照してください。2018.12.1 : コードを改良し、ポーズ推定機能を追加しました。詳細については、utils/estimate_pose.py を参照してください。2018.11.17 : コードを修正し、3D 頂点を元の画像空間にマッピングします。2018.11.11 :エンドツーエンドの推論パイプラインを更新: 1 つの任意の画像を指定して 3D 顔の形状と 68 個のランドマークを推論/シリアル化します。詳細については、以下の readme.md を参照してください。2018.10.4 : Matlab フェイス メッシュ レンダリング デモをビジュアライズに追加しました。2018.9.9 : ベンチマークに顔トリミングの前処理を追加。【藤堂】
このリポジトリには、論文「Face Alignment in Full Pose Range: A 3D Total Solution」の pytorch 改良版が含まれています。リアルタイム トレーニングやトレーニング戦略など、元の論文を超えるいくつかの作業が追加されています。したがって、このリポジトリは元の作品の改良版です。これまでのところ、このリポジトリは、MobileNet-V1 構造の事前トレーニングされた第 1 段階の pytorch モデル、事前処理されたトレーニングおよびテスト データセット、およびコードベースをリリースしています。 GeForce GTX TITAN X では、推論時間は画像あたり約 0.27 ミリ秒(入力バッチとして 128 個の画像を含む入力バッチ) であることに注意してください。
このリポジトリは暇なときに更新し続けます。有意義な問題や PR は大歓迎です。
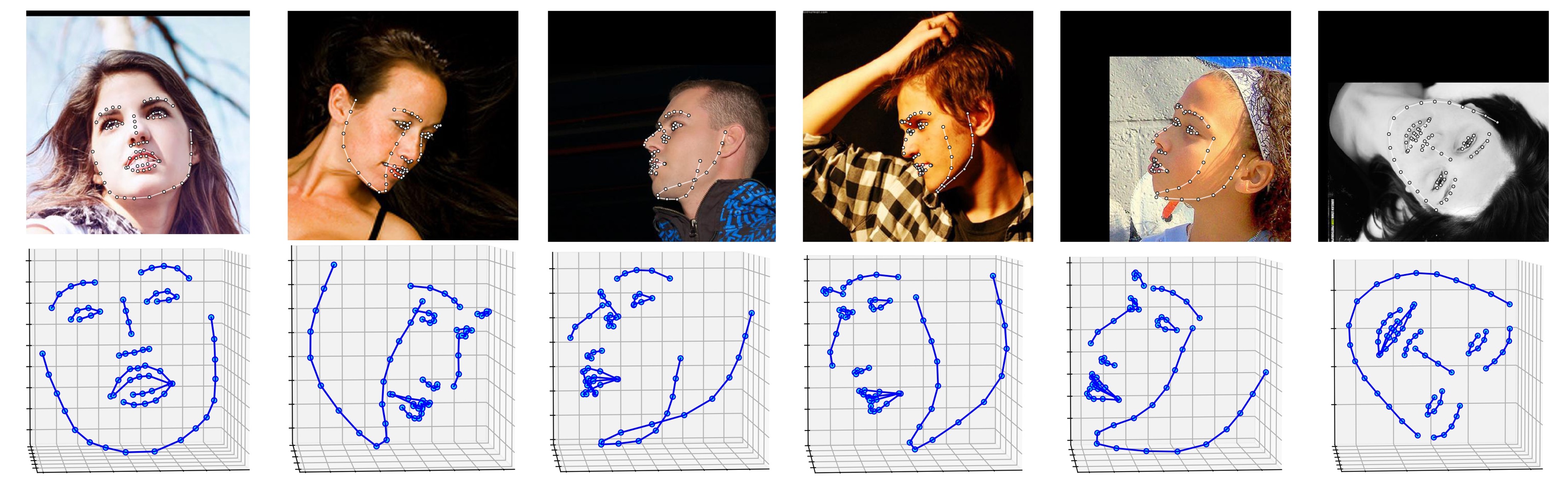
ALFW-2000 データセット (モデルphase1_wpdc_vdc.pth.tarから推論) に関するいくつかの結果を以下に示します。





# installation structions
sudo pip3 install torch torchvision # for cpu version. more option to see https://pytorch.org
sudo pip3 install numpy scipy matplotlib
sudo pip3 install dlib==19.5.0 # 19.15+ version may cause conflict with pytorch in Linux, this may take several minutes. If 19.5 version raises errors, you may try 19.15+ version.
sudo pip3 install opencv-python
sudo pip3 install cython
さらに、より優れた設計のため、古いバージョンではなく Python3.6 以降を使用することを強くお勧めします。
このリポジトリのクローンを作成します (少し大きいため、時間がかかる場合があります)
git clone https://github.com/cleardusk/3DDFA.git # or [email protected]:cleardusk/3DDFA.git
cd 3DDFA
次に、dlib ランドマークの事前トレーニング済みモデルを Google ドライブまたは Baidu Yun にダウンロードし、 modelsディレクトリに置きます。 (このリポジトリのサイズを減らすために、このモデルを含むいくつかの大きなサイズのバイナリ ファイルを削除するので、ダウンロードする必要があります:))
cython モジュールをビルドします (ビルドは 1 行のみ)
cd utils/cython
python3 setup.py build_ext -i
これは、Python の for ループが遅すぎるため、深度推定と PNCC レンダリングを高速化するためです。
任意の画像を入力としてmain.py実行します
python3 main.py -f samples/test1.jpg
ターミナルにこれらの出力ログが表示されれば、正常に実行されています。
Dump tp samples/test1_0.ply
Save 68 3d landmarks to samples/test1_0.txt
Dump obj with sampled texture to samples/test1_0.obj
Dump tp samples/test1_1.ply
Save 68 3d landmarks to samples/test1_1.txt
Dump obj with sampled texture to samples/test1_1.obj
Dump to samples/test1_pose.jpg
Dump to samples/test1_depth.png
Dump to samples/test1_pncc.png
Save visualization result to samples/test1_3DDFA.jpg
test1.jpgには 2 つの面があるため、2 つの.plyファイルと.objファイル (Meshlab または Microsoft 3D Builder でレンダリング可能) が予測されます。深度、PNCC、PAF、姿勢推定はすべてデフォルトで true に設定されます。詳細については、 python3 main.py -hを実行するか、コードを確認してください。
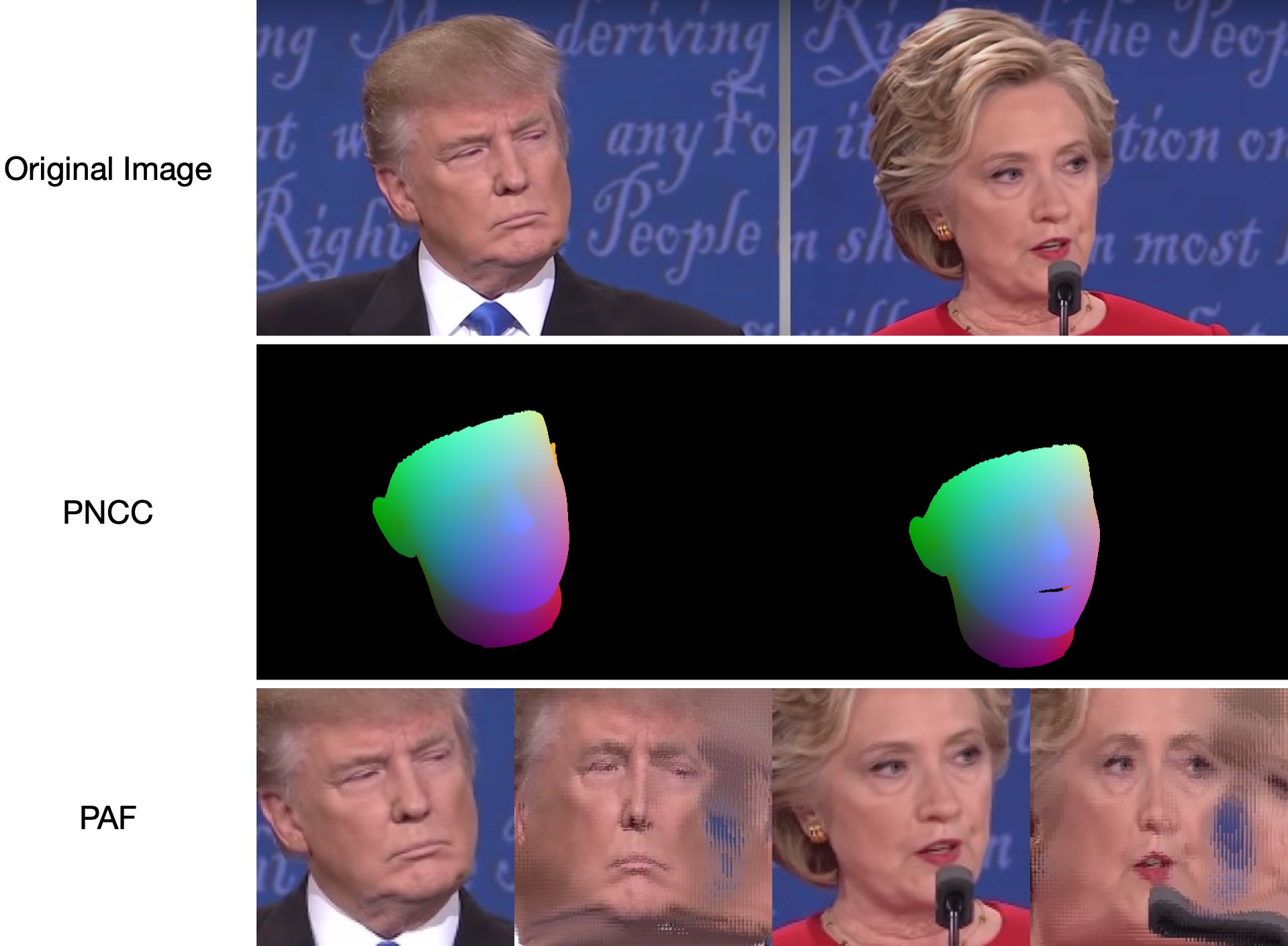
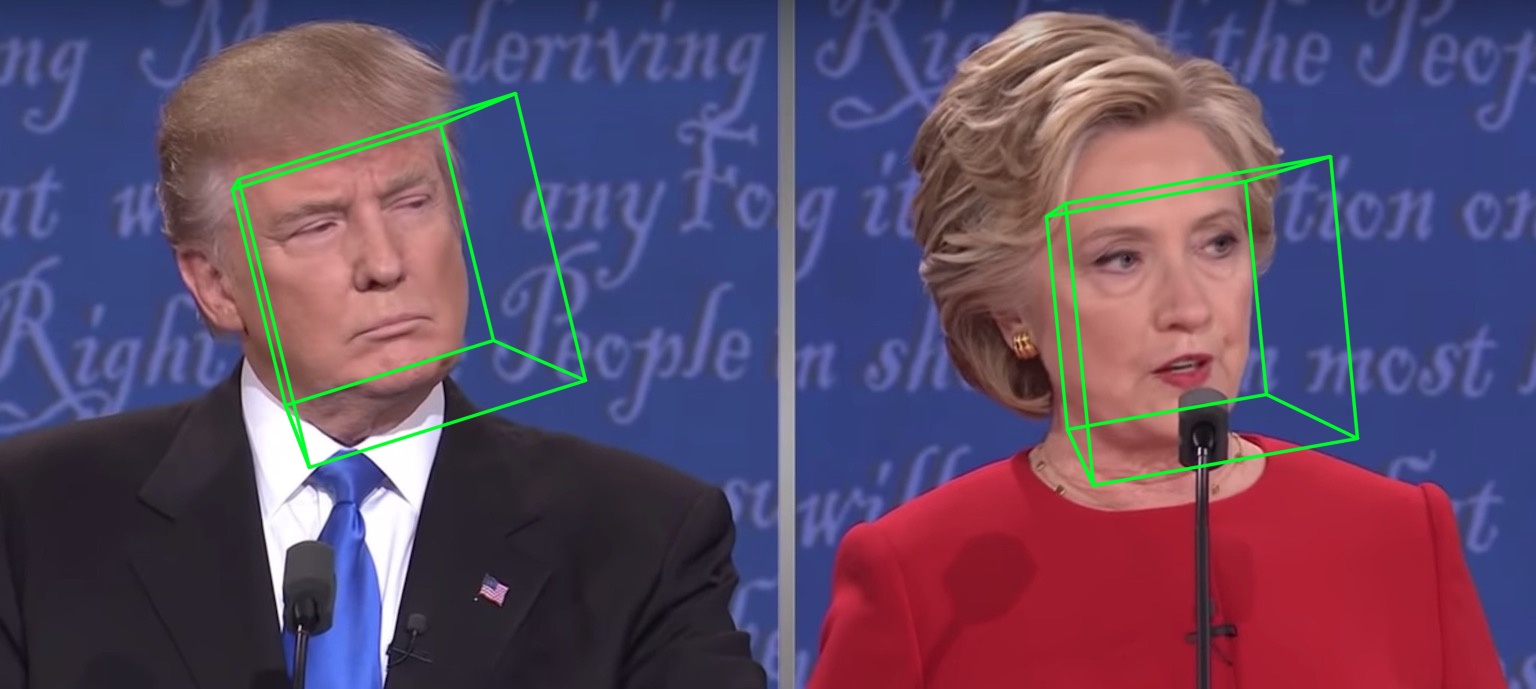
68 個のランドマークの可視化結果samples/test1_3DDFA.jpgと姿勢推定結果samples/test1_pose.jpgを以下に示します。

追加の例
python3 ./main.py -f samples/emma_input.jpg --bbox_init=two --dlib_bbox=false
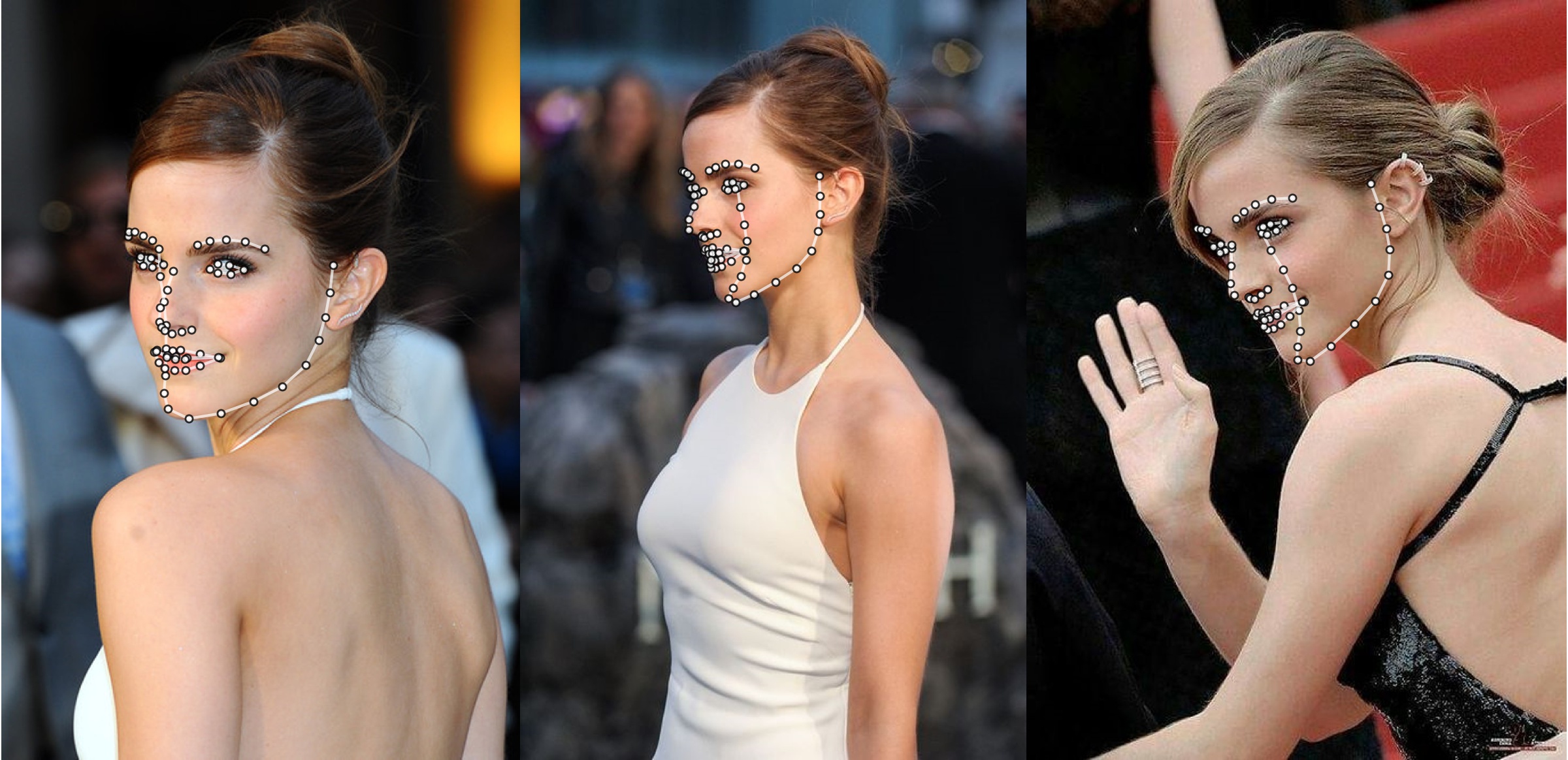
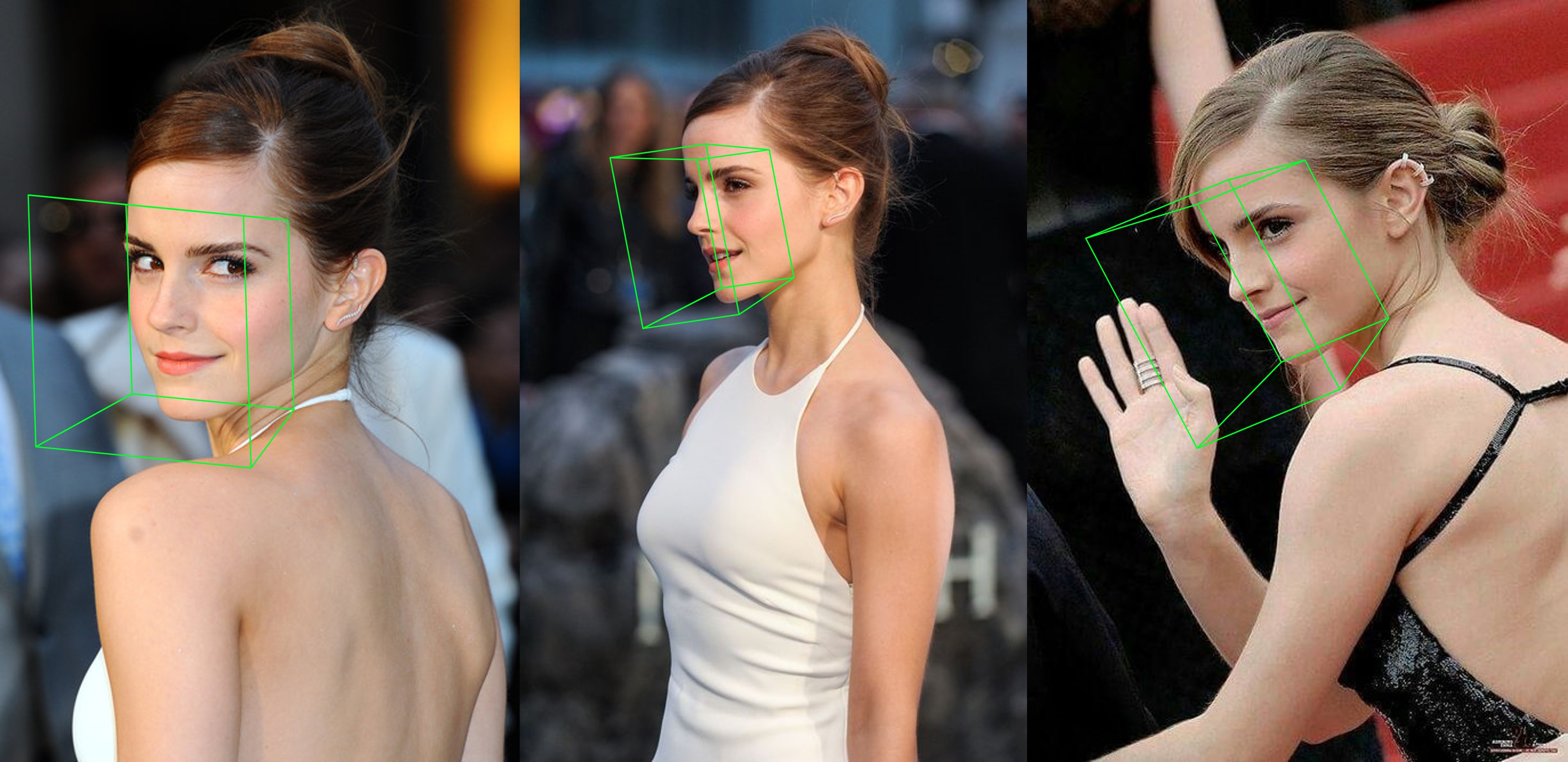
ただ走ってください
python3 speed_cpu.py
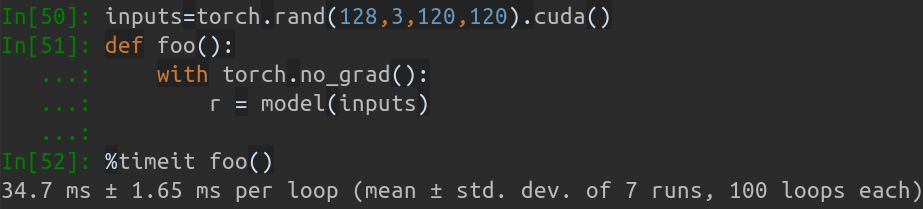
私の MBP (13 インチ MacBook Pro 上の i5-8259U CPU @ 2.30GHz) では、 PyTorch v1.1.0に基づいており、入力が 1 つで、実行中の出力は次のようになります。
Inference speed: 14.50±0.11 ms
入力バッチサイズが 128 の場合、MobileNet-V1 の合計推論時間は約 34.7ms かかります。平均速度は約0.27ms/picです。
トレーニング スクリプトはtrainingディレクトリにあります。関連リソースは以下の表にあります。
| データ | ダウンロードリンク | 説明 |
|---|---|---|
| train.configs | BaiduYun または Google ドライブ、217M | 3DMM パラメータとトレーニング データセットのファイルリストを含むディレクトリ |
| train_aug_120x120.zip | BaiduYun または Google ドライブ、2.15G | 拡張トレーニング データセットのトリミングされた画像 |
| テスト.データ.zip | BaiduYun または Google ドライブ、151M | AFLW および ALFW-2000-3D テストセットのトリミングされた画像 |
トレーニング データセットと構成ファイルを準備した後、 trainingディレクトリに移動し、bash スクリプトを実行してトレーニングします。 train_wpdc.sh 、 train_vdc.sh 、 train_pdc.shはトレーニング スクリプトの例です。トレーニング セットとテスト セットを構成したら、それらをトレーニングのために実行するだけです。以下にtrain_wpdc.sh例に挙げます。
#!/usr/bin/env bash
LOG_ALIAS=$1
LOG_DIR="logs"
mkdir -p ${LOG_DIR}
LOG_FILE="${LOG_DIR}/${LOG_ALIAS}_`date +'%Y-%m-%d_%H:%M.%S'`.log"
#echo $LOG_FILE
./train.py --arch="mobilenet_1"
--start-epoch=1
--loss=wpdc
--snapshot="snapshot/phase1_wpdc"
--param-fp-train='../train.configs/param_all_norm.pkl'
--param-fp-val='../train.configs/param_all_norm_val.pkl'
--warmup=5
--opt-style=resample
--resample-num=132
--batch-size=512
--base-lr=0.02
--epochs=50
--milestones=30,40
--print-freq=50
--devices-id=0,1
--workers=8
--filelists-train="../train.configs/train_aug_120x120.list.train"
--filelists-val="../train.configs/train_aug_120x120.list.val"
--root="/path/to//train_aug_120x120"
--log-file="${LOG_FILE}"
学習率、ミニバッチ サイズ、エポックなど、特定のトレーニング パラメーターはすべて bash スクリプトで表示されます。
まず、トリミングされたテストセット ALFW および ALFW-2000-3D を test.data.zip にダウンロードし、解凍してルート ディレクトリに置きます。次に、トレーニングされたモデルのパスを指定してベンチマーク コードを実行します。すでに 5 つの事前トレーニング済みモデルをmodelsディレクトリに提供しています (以下の表を参照)。これらのモデルは、最初の段階でさまざまな損失を使用してトレーニングされます。 MobileNet-V1構造の高効率化によりモデルサイズは約13Mです。
python3 ./benchmark.py -c models/phase1_wpdc_vdc.pth.tar
事前学習済みモデルのパフォーマンスを以下に示します。第 1 段階では、さまざまな損失の有効性は、WPDC > VDC > PDC の順になります。一方、VDC を使用して WPDC を微調整する戦略では、最良の結果が得られます。
| モデル | AFLW (21 点) | AFLW 2000-3D (68 点) | ダウンロードリンク |
|---|---|---|---|
| フェーズ1_pdc.pth.tar | 6.956±0.981 | 5.644±1.323 | Baidu Yu または Google ドライブ |
| フェーズ1_vdc.pth.tar | 6.717±0.924 | 5.030±1.044 | Baidu Yu または Google ドライブ |
| フェーズ1_wpdc.pth.tar | 6.348±0.929 | 4.759±0.996 | Baidu Yu または Google ドライブ |
| フェーズ1_wpdc_vdc.pth.tar | 5.401±0.754 | 4.252±0.976 | このレポでは。 |
このリポジトリのフレームワークは、計算量を増やすことなく PRNet よりも優れたパフォーマンスを達成できると信じてください。関連作業は審査中であり、承認され次第コードが公開されます。
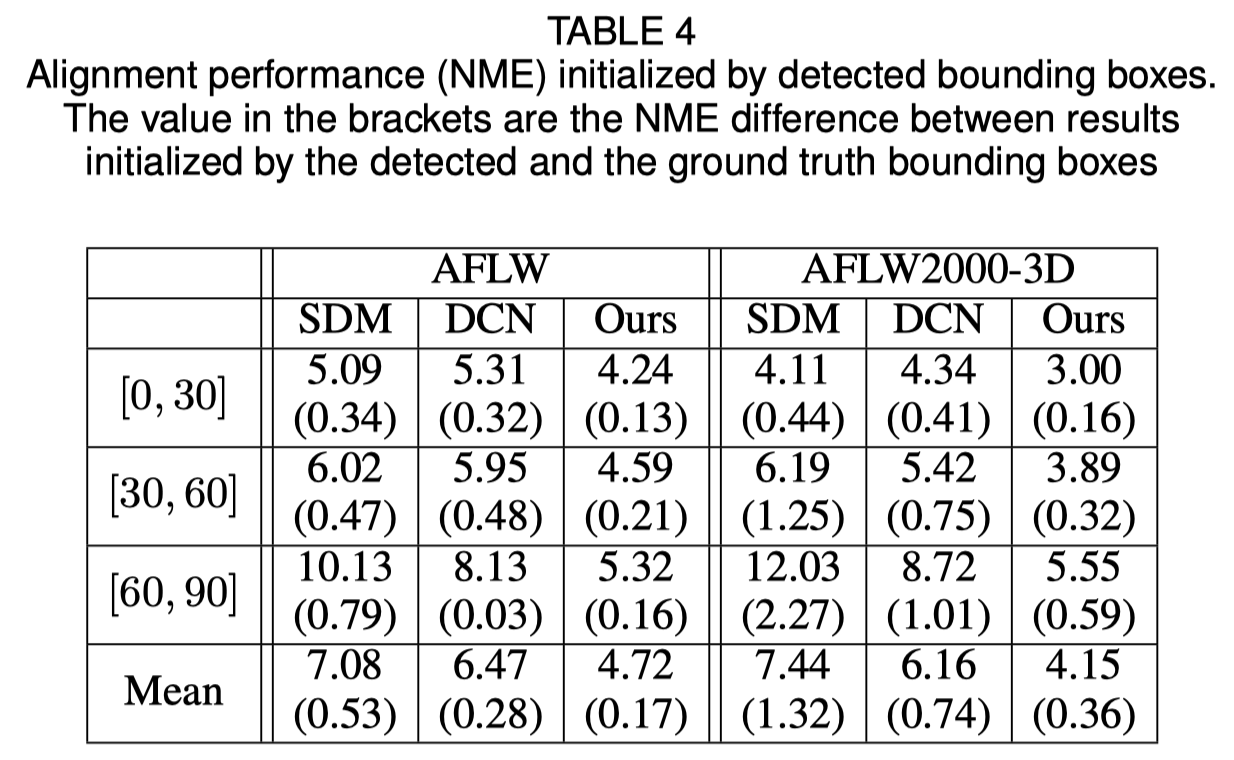
顔の境界ボックスの初期化
元の論文では、グラウンド トゥルース ボックスの代わりに検出されたバウンディング ボックスを使用すると、パフォーマンスが若干低下することが示されています。したがって、現在の顔トリミング方法が最も堅牢です。定量的結果を以下の表に示します。
顔の再構成
セルフオクルージョンにより非表示領域のテクスチャが歪んでいるため、顔の非表示領域が奇妙に(少しひどいように)見える場合があります。
シェイプおよびエクスプレッションパラメータのクリッピングについて
パラメータのクリッピングによりトレーニングと再構築は高速化されますが、特に目を閉じるなどの詳細の精度が低下します。以下は、パラメータの寸法が 40+10、60+29、および 199+29 (元の画像) の画像です。形状と比較して、感情が含まれる場合、表情クリッピングは再構成の精度に大きな影響を与えます。したがって、速度/パラメータサイズと精度の間のトレードオフを選択できます。クリッピングのトレードオフの推奨値は 60+29 です。

このリポジトリにご興味をお持ちいただきありがとうございます。あなたの仕事や研究がこのリポジトリから恩恵を受ける場合は、スターを付けてください。
私の 3D 顔関連の仕事、つまり MeGlass と Face Anti-Spoofing に集中することを歓迎します。
あなたの作品がこのリポジトリから恩恵を受ける場合は、以下に 3 つのゼッケンを引用してください。
@misc{3ddfa_cleardusk,
author = {Guo, Jianzhu and Zhu, Xiangyu and Lei, Zhen},
title = {3DDFA},
howpublished = {url{https://github.com/cleardusk/3DDFA}},
year = {2018}
}
@inproceedings{guo2020towards,
title= {Towards Fast, Accurate and Stable 3D Dense Face Alignment},
author= {Guo, Jianzhu and Zhu, Xiangyu and Yang, Yang and Yang, Fan and Lei, Zhen and Li, Stan Z},
booktitle= {Proceedings of the European Conference on Computer Vision (ECCV)},
year= {2020}
}
@article{zhu2017face,
title= {Face alignment in full pose range: A 3d total solution},
author= {Zhu, Xiangyu and Liu, Xiaoming and Lei, Zhen and Li, Stan Z},
journal= {IEEE transactions on pattern analysis and machine intelligence},
year= {2017},
publisher= {IEEE}
}
Jianzhu Guo (郭建珠) [ホームページ、Google Scholar]: [email protected]または[email protected] 。


