SmartFilteringRAG
1.0.0
「古い白黒コメディ」を検索した結果、現代のアクション映画を組み合わせた作品が大量に表示されたことはありませんか?イライラしますよね?これが従来の検索エンジンの課題です。クエリのニュアンスを理解するのに苦労することが多く、無関係な結果をさまよってしまうことになります。
ここでスマート フィルタリングが登場します。スマート フィルタリングは、メタデータとベクトル検索を使用して、意図に真に一致する検索結果を提供する革新的なツールです。手間をかけずに、あなたが求めている古典的なコメディを正確に見つけることを想像してみてください。
スマート フィルタリングとは何か、その仕組み、そしてより良い検索エクスペリエンスを構築するためにスマート フィルタリングが不可欠である理由について詳しく説明します。このテクノロジーの背後にある魔法を明らかにし、このテクノロジーが検索方法にどのような革命をもたらすかを探ってみましょう。
ベクトル検索は、コンピューターが単語そのものだけでなく、データの背後にある意味を理解するのに役立つ強力なツールです。キーワードを一致させるのではなく、基礎となる概念と関係に焦点を当てます。 「犬」を検索すると、「子犬」、「犬」、さらには犬の画像も含まれる結果が表示されることを想像してください。それがベクトル検索の魔法です。
どのように機能するのでしょうか?データをベクトルと呼ばれる数学的表現に変換します。これらのベクトルは地図上の座標のようなもので、このベクトル空間では同様のデータ ポイントが互いに接近しています。何かを検索すると、システムはクエリに最も近いベクトルを検索し、意味的に類似した結果を返します。
ベクトル検索はコンテキストを理解する点では優れていますが、単純なフィルタリング タスクに関しては不十分な場合があります。たとえば、2000 年より前に公開されたすべての映画を検索するには、意味を理解するだけでなく、正確なフィルタリングが必要です。ここで、ベクトル検索を補完するスマート フィルタリングが登場します。
Vector はクエリの本当の意味の理解に近づけますが、ユーザーが望むものと検索エンジンが提供するものの間にはまだギャップがあります。 「2000 年以前の最も初期のコメディ映画」のような複雑な検索クエリは、依然として課題となる可能性があります。セマンティック検索は、「コメディ」や「映画」の概念は理解できるかもしれませんが、「最も初期」や「2000 年以前」という詳細には対応できない可能性があります。
ここから結果が混乱し始めます。新旧のコメディが混在したり、誤ってドラマが含まれたりする可能性があります。ユーザーを真に満足させるには、これらの検索結果を絞り込み、より正確にする方法が必要です。そこでプレフィルターが活躍します。
スマート フィルタリングは、この課題に対する解決策です。これは、データセットのメタデータを使用して特定のフィルターを作成し、検索結果を絞り込み、より正確かつ効率的にする手法です。スマート フィルタリングは、構造、内容、属性などのデータに関する情報を分析することにより、検索をフィルタリングするための関連基準を特定できます。
「2000 年より前に公開されたコメディ映画」を検索することを想像してみてください。スマート フィルタリングは、ジャンル、リリース日、場合によってはプロット キーワードなどのメタデータを使用して、それらの基準に一致する映画のみを含むフィルタを作成します。こうすることで、無関係なノイズを発生させることなく、正確に必要なもののリストを取得できます。
次のセクションでは、スマート フィルタリングがどのように機能するかをさらに詳しく見てみましょう。
スマート フィルタリングは、データから情報を抽出し、分析し、ニーズに基づいて特定のフィルターを作成する複数のステップからなるプロセスです。分析してみましょう:
メタデータの抽出:最初のステップは、データに関する関連情報を収集することです。これには次のような詳細が含まれます。
プレフィルターの生成:メタデータを取得したら、プレフィルターの作成を開始できます。これらは、データが検索結果に含まれるために満たさなければならない特定の条件です。たとえば、2000 年より前に公開されたコメディ映画を検索する場合は、次のプレフィルターを作成するとよいでしょう。
ベクトル検索との統合:最後のステップは、これらのプレフィルターをベクトル検索と組み合わせることです。これにより、ベクトル検索では、事前定義された基準に一致するデータ ポイントのみが考慮されるようになります。
これらの手順に従うことで、スマート フィルタリングにより検索結果の精度と効率が大幅に向上します。
メタデータの抽出:作業を簡素化するために、サンプル データを使用し、メタデータを手動で定義します。参照: prepare_test_data.pyの get_docs_metadata 。
プレフィルターの生成:プレフィルターは 2 つのステップで生成します。
ステップ 1: メタデータ ベースのフィルター
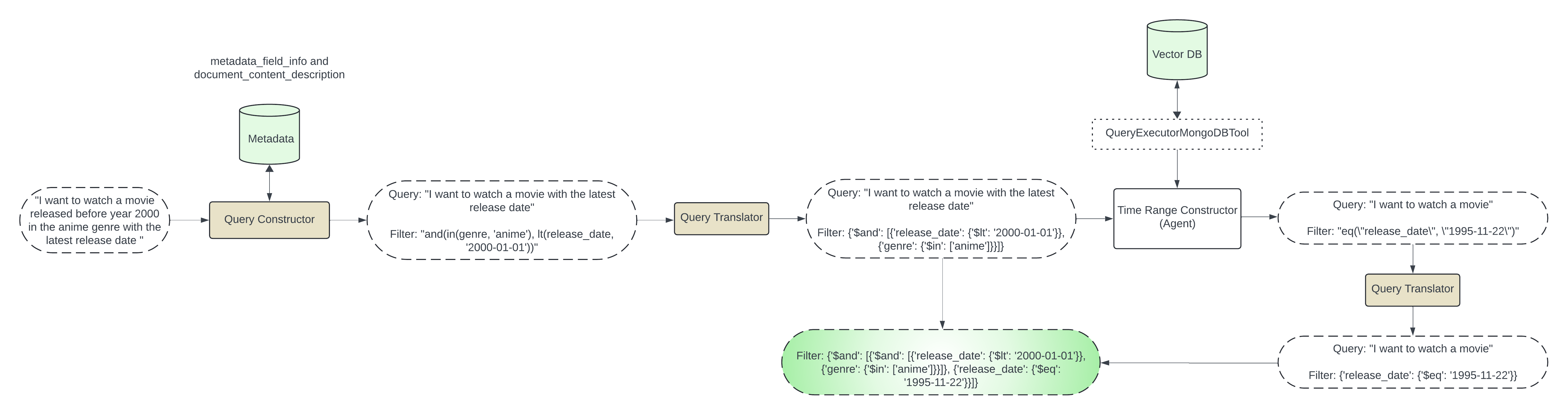
このステップには、メタデータに基づいてフィルターを生成することが含まれます。ユーザー クエリとメタデータを LLM に渡し、メタデータ フィルターを生成します。
この DEFAULT_SCHEMA_PROMPT で初期化される query_constructor を使用します。
注: ユースケースに応じて、プロンプトといくつかのショットの例を更新します。
例: メタデータにgenreとrelease_dateがあり、ユーザーが 2020 年より前にリリースされたactionジャンルの映画を要求した場合、LLM を使用して以下のようなフィルターを生成できます。
{"$and": [{"genre": {"$in": ["anime"]}}, {"release_date": {"$lt": "2024-01-01"}}]}
ステップ 2: 時間ベースのフィルタリング
このステップでは、ユーザーがlatest 、 most recent earliest種類の情報を要求するケースを処理します。この情報を取得するには、実際のデータをクエリする必要があります。このステップでは LLM エージェントを使用し、executor ツールを使用して mongodb コレクションをクエリします。 QueryExecutorMongoDBTool Generate_time_based_filter で時間ベースのフィルターを生成します。また、集計ステージの$matchの最初のステップで生成された pre_filter も使用します。例: ユーザーが最新の映画を必要としている場合、LLM エージェントは実行ツールを使用して以下の集計クエリを実行します。
Invoking: `mongo_db_executor` with `{'pipeline': '[{"$match": {"$and": [{"genre": {"$in": ["anime"]}}, {"release_date": {"$lt": "2024-01-01"}}]}}, { "$sort": { "release_date": -1 } }, { "$limit": 1 }, { "$project": { "release_date": 1 } }]'}`
Vector Search との統合:生成されたプレフィルターは MongoDBAtlasVectorSearch リトリーバーで使用されます。
retriever = vectorstore.as_retriever(
search_kwargs={ ' pre_filter ' : pre_filter}
)新しいPython環境を作成する
python3 -m venv env
source env/bin/activate要件をインストールする
pip3 install -r requirements.txtconfig.yaml で構成を設定します。
database_name: < your database name >
collection_name: < your collection name >
vector_index_name: default
embedding_model_dimensions: 1536
similarity: cosine
model: gpt-4o
embedding_model: text-embedding-ada-002環境変数を設定する
export OPEN_AI_API_KEY = " "
export OPEN_API_BASE = " "
# headers are optional
export OPEN_API_DEFAULT_HEADERS= " "
export MONGO_URI= " "サンプル データを使用して mongodb コレクションを初期化します。このコマンドは、いくつかのサンプル データにインデックスを付け、コレクションにベクトル検索インデックスを作成します。
python3 rag/initialize_mongo_collection.pypython3 rag/main.py --queries < list of queries in json format > python3 rag/main.py --queries ' ["I want to watch an anime genre movie", "Recommend a thriller or action movie release after Feb, 2010", "Recommend an anime movie released before 2023 with the latest release date"] '生成された Pre_filters:
入力クエリ: "I want to watch an anime genre movie", "Recommend a thriller or action movie release after Feb, 2010"
出力: 
入力クエリ: "Recommend a thriller or action movie release after Feb, 2010"
出力: 
入力クエリ: "Recommend an anime movie released before 2023 with the latest release date"
出力: 
スマート フィルタリングはテーブルに多くの利点をもたらし、検索エクスペリエンスを向上させる貴重なツールになります。
検索精度の向上:スマート フィルタリングは、クエリに一致するデータを正確にターゲットにすることで、関連する結果が見つかる可能性を大幅に高めます。無関係な情報をうろうろする必要はもうありません。
検索結果の高速化:スマート フィルタリングにより検索範囲が絞り込まれるため、システムは情報をより効率的に処理でき、結果が迅速に得られます。
ユーザー エクスペリエンスの強化:ユーザーが探しているものを迅速かつ簡単に見つけられると、満足度が高まり、全体的なエクスペリエンスが向上します。
汎用性:スマート フィルタリングは、電子商取引の商品検索からコンテンツの推奨に至るまで、さまざまなドメインに適用できるため、多用途のツールになります。
スマート フィルタリングは、メタデータを活用し、ターゲットを絞ったプレフィルターを作成することにより、ユーザーの期待に真に応える検索結果を提供できるようにします。
スマート フィルタリングは、ユーザーの意図と結果の間のギャップを埋めることでエクスペリエンスを変革する強力なツールです。メタデータとベクトル検索の力を利用することで、より正確で関連性の高い、効率的な検索結果が得られます。
電子商取引プラットフォーム、コンテンツ推奨システム、または効果的な検索に依存するアプリケーションを構築している場合でも、スマート フィルタリングを組み込むことで、ユーザーの満足度が大幅に向上し、より良い結果が得られます。
スマート フィルタリングの基礎を理解することで、その可能性を探求し、プロジェクトに実装する準備が整います。では、なぜ待つのでしょうか?今すぐスマート フィルタリングの機能を活用して、検索ゲームに革命を起こしましょう。
LangChain の Self Query Retriever からインスピレーションを受けています。


