rag with human support
1.0.0
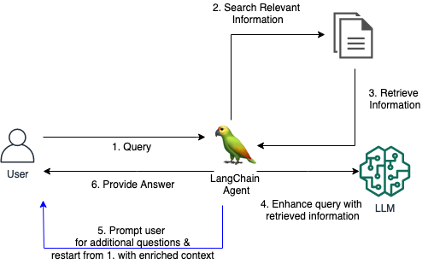
従来の RAG システムは、ユーザーが十分なコンテキストを提供せずに漠然とした質問をした場合、満足のいく回答を提供するのに苦労することがよくありました。これにより、「わかりません」などの役に立たない応答や、LLM が提供する間違ったでっちあげの応答が生成されます。このリポジトリには、従来の RAG エージェントを改善するコードが含まれています。
RAG エージェント用のカスタム LangChain ツールを導入しました。これにより、最初の質問が不明瞭または曖昧すぎる場合に、エージェントがユーザーと会話型の対話を行うことができます。明確な質問をし、ユーザーに詳細を促し、コンテキスト情報を組み込むことにより、エージェントは必要なコンテキストを収集して、たとえ曖昧な最初のクエリであっても、正確で役立つ回答を提供できます。
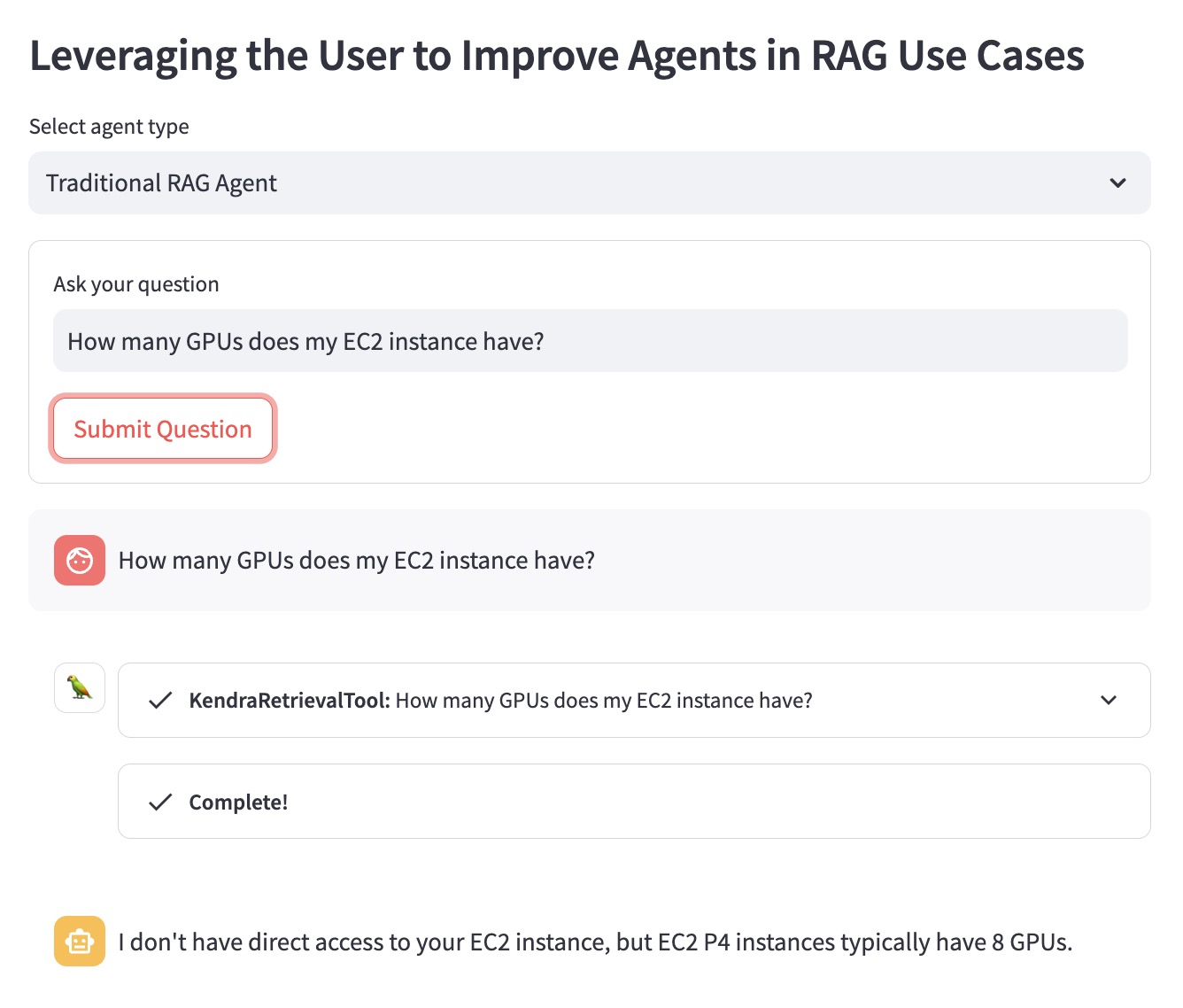
「EC2 インスタンスには GPU がいくつありますか?」という質問の例を使用して利点を説明してみましょう。
従来の RAG エージェントは、ユーザーがどの EC2 インスタンスを念頭に置いているかを知りません。したがって、あまり役に立たない答えが提供されます。
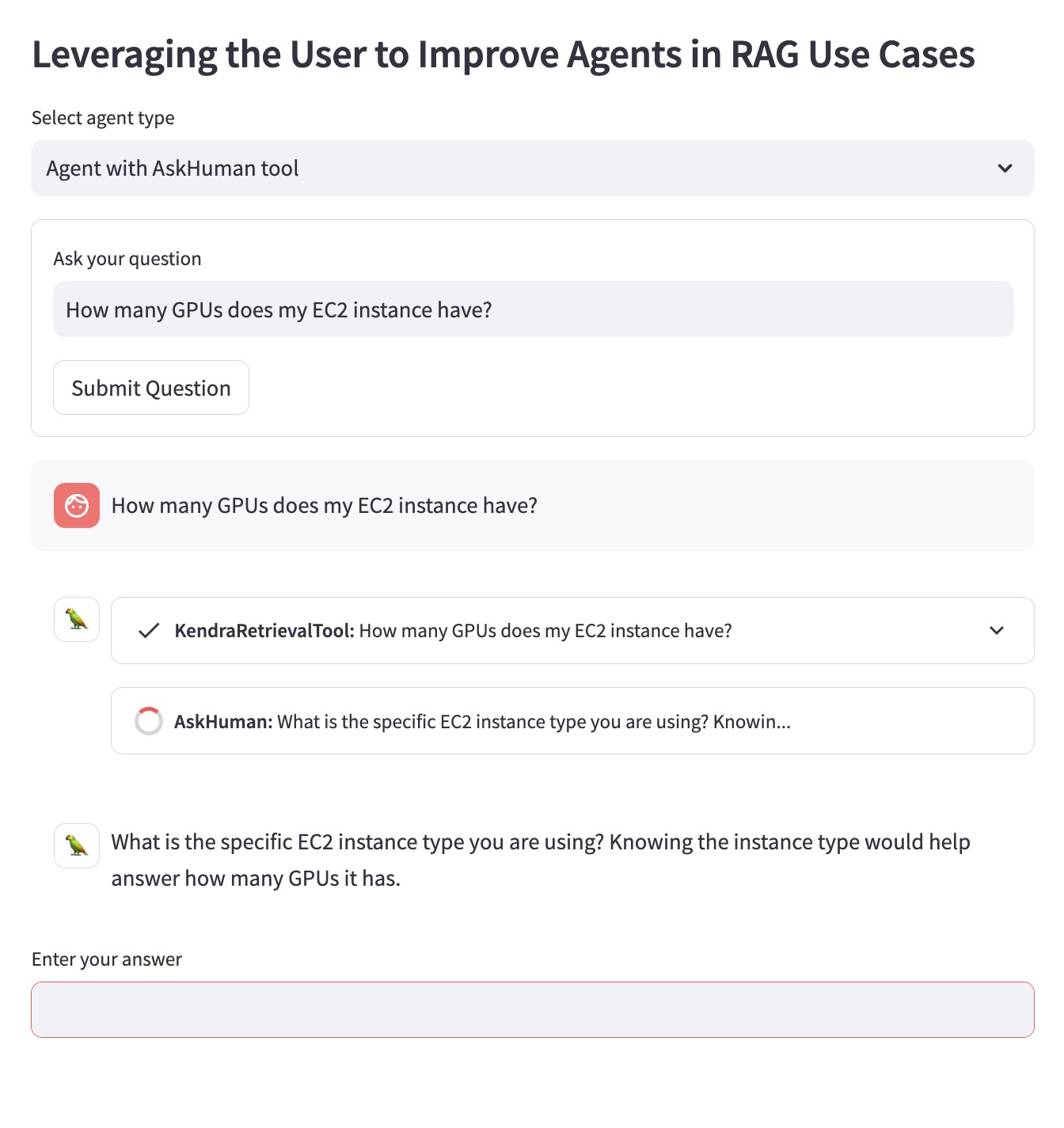
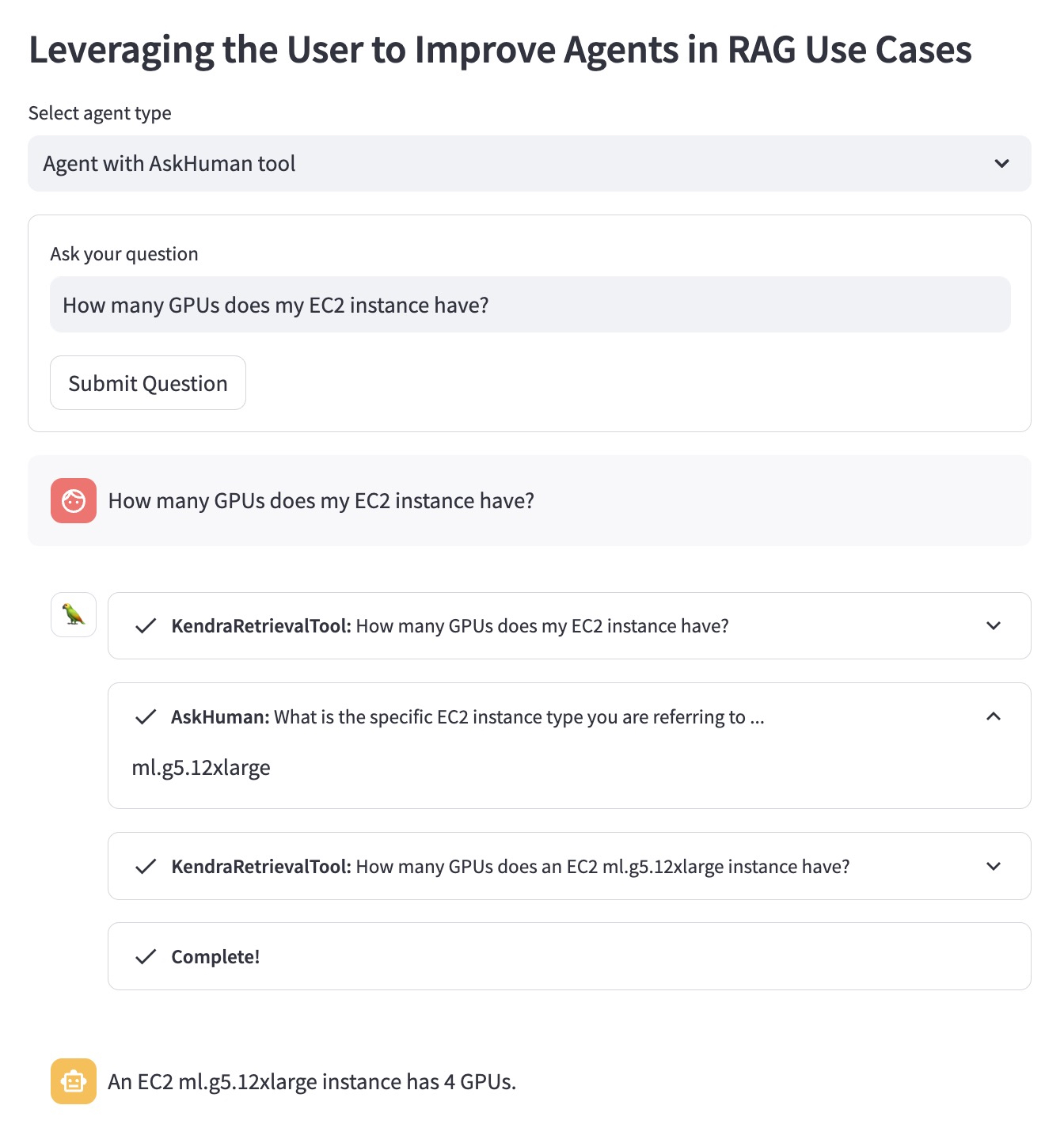
`AskHuman` ツールを使用して改良された RAG エージェントは、次の 2 つの追加手順を実行します。
これは、改善されたエージェントが具体的で役立つ回答を提供するのに役立ちます。
AWS アカウントでこのデモを実行するには、次の手順に従う必要があります。
demo.pyの LangChain エージェントで使用されているllm 、LangChain でサポートされている LLM に置き換えます。sh dependencies.sh実行して、依存関係をインストールします。KENDRA_INDEX_IDレトリーバー パラメーターdemo.pyに指定します。streamlit run demo.pyを実行して、Streamlit アプリを起動します。 新しい Kendra インデックスをデプロイしてデモを実行すると、請求書に追加料金が追加される可能性があることに注意してください。不必要なコストの発生を避けるため、Amazon Kendra Index を使用しない場合は削除し、デモの実行に使用した場合は SageMaker Studio インスタンスをシャットダウンしてください。


