korpatbert
1.0.0
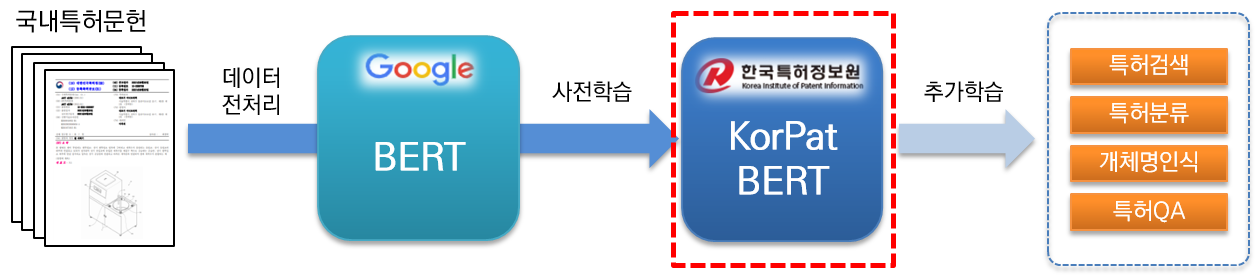
KorPatBERT(Korean Patent BERT)は韓国特許情報院が研究開発したAI言語モデルです。
特許分野 韓国語 自然言語処理問題解決及び特許産業分野の知能情報化インフラづくりのために既存のGoogle BERT baseモデルのアーキテクチャを基盤に大容量国内特許文献(base:約406万文献、large:約506万文献)を事前学習(pre-training)しており、無料で提供しています。
特許分野 特化された高性能事前学習(pre-trained)言語モデルで多様な自然言語処理タスクで活用できます。
[KorPatBERT-base]
[KorPatBERT-large]
[KorPatBERT-base]
[KorPatBERT-large]
言語モデル学習に使用された特許文献を対象に約1,000万個の主要名詞および複合名詞を抽出し、これを韓国語型小分析器Mecab-koのユーザー辞書に追加した後、Google SentencePieceを通じてSubwordに分割する方式の特許テキストに特化したMSPトークナイザー(Mecab-ko Sentencepiece Patent Tokenizer)です。
| モデル | Top@1(ACC) |
|---|---|
| Google BERT | 72.33 |
| KorBERT | 73.29 |
| KoBERT | 33.75 |
| KrBERT | 72.39 |
| KorPatBERT-base | 76.32 |
| KorPatBERT-ラージ | 77.06 |
| モデル | Top@1(ACC) | Top@3(ACC) | Top@5(ACC) |
|---|---|---|---|
| KorPatBERT-base | 61.91 | 82.18 | 86.97 |
| KorPatBERT-ラージ | 62.89 | 82.18 | 87.26 |
| プログラム名 | バージョン | 設置案内経路 | 必須かどうか |
|---|---|---|---|
| python | 3.6以上 | https://www.python.org/ | Y |
| anaconda | 4.6.8以上 | https://www.anaconda.com/ | N |
| tensorflow | 2.2.0以上 | https://www.tensorflow.org/install/pip?hl=ja | Y |
| sentencepiece | 0.1.96以上 | https://github.com/google/sentencepiece | N |
| mecab-ko | 0.996-ja-0.0.2 | https://bitbucket.org/eunjeon/mecab-ja-dic/src/master/ | Y |
| mecab-ko-dic | 2.1.1 | https://bitbucket.org/eunjeon/mecab-ja-dic/src/master/ | Y |
| mecab-python | 0.996-ja-0.9.2 | https://bitbucket.org/eunjeon/mecab-ja-dic/src/master/ | Y |
| python-mecab-ko | 1.0.11以上 | https://pypi.org/project/python-mecab-ja/ | Y |
| keras | 2.4.3以上 | https://github.com/keras-team/keras | N |
| bert_for_tf2 | 0.14.4以上 | https://github.com/kpe/bert-for-tf2 | N |
| tqdm | 4.59.0以上 | https://github.com/tqdm/tqdm | N |
| soynlp | 0.0.493以上 | https://github.com/lovit/soynlp | N |
Installation URL: https://bitbucket.org/eunjeon/mecab-ko-dic/src/master/
mecab-ko > 0.996-ko-0.9.2
mecab-ko-dic > 2.1.1
mecab-python > 0.996-ko-0.9.2
from korpat_tokenizer import Tokenizer
# (vocab_path=Vocabulary 파일 경로, cased=한글->True, 영문-> False)
tokenizer = Tokenizer(vocab_path="./korpat_vocab.txt", cased=True)
# 테스트 샘플 문장
example = "본 고안은 주로 일회용 합성세제액을 집어넣어 밀봉하는 세제액포의 내부를 원호상으로 열중착하되 세제액이 배출되는 절단부 쪽으로 내벽을 협소하게 형성하여서 내부에 들어있는 세제액을 잘짜질 수 있도록 하는 합성세제 액포에 관한 것이다."
# 샘플 토크나이즈
tokens = tokenizer.tokenize(example)
# 샘플 인코딩 (max_len=토큰 최대 길이)
ids, _ = tokenizer.encode(example, max_len=256)
# 샘플 디코딩
decoded_tokens = tokenizer.decode(ids)
# 결과 출력
print("Length of Token dictionary ===>", len(tokenizer._token_dict.keys()))
print("Input example ===>", example)
print("Tokenized example ===>", tokens)
print("Converted example to IDs ===>", ids)
print("Converted IDs to example ===>", decoded_tokens)
Length of Token dictionary ===> 21400
Input example ===> 본 고안은 주로 일회용 합성세제액을 집어넣어 밀봉하는 세제액포의 내부를 원호상으로 열중착하되 세제액이 배출되는 절단부 쪽으로 내벽을 협소하게 형성하여서 내부에 들어있는 세제액을 잘짜질 수 있도록 하는 합성세제 액포에 관한 것이다.
Tokenized example ===> ['[CLS]', '본', '고안', '은', '주로', '일회용', '합성', '##세', '##제', '##액', '을', '집', '##어넣', '어', '밀봉', '하', '는', '세제', '##액', '##포', '의', '내부', '를', '원호', '상', '으로', '열', '##중', '착하', '되', '세제', '##액', '이', '배출', '되', '는', '절단부', '쪽', '으로', '내벽', '을', '협소', '하', '게', '형성', '하', '여서', '내부', '에', '들', '어', '있', '는', '세제', '##액', '을', '잘', '짜', '질', '수', '있', '도록', '하', '는', '합성', '##세', '##제', '액', '##포', '에', '관한', '것', '이', '다', '.', '[SEP]']
Converted example to IDs ===> [5, 58, 554, 32, 2716, 6554, 817, 20418, 20308, 20514, 15, 732, 15572, 39, 1634, 12, 11, 5934, 20514, 20367, 9, 315, 16, 5922, 17, 33, 279, 20399, 16971, 26, 5934, 20514, 13, 674, 26, 11, 10132, 1686, 33, 3781, 15, 11950, 12, 64, 87, 12, 3958, 315, 10, 51, 39, 25, 11, 5934, 20514, 15, 1803, 12889, 399, 24, 25, 118, 12, 11, 817, 20418, 20308, 299, 20367, 10, 439, 56, 13, 18, 14, 6, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
Converted IDs to example ===> ['본', '고안', '은', '주로', '일회용', '합성', '##세', '##제', '##액', '을', '집', '##어넣', '어', '밀봉', '하', '는', '세제', '##액', '##포', '의', '내부', '를', '원호', '상', '으로', '열', '##중', '착하', '되', '세제', '##액', '이', '배출', '되', '는', '절단부', '쪽', '으로', '내벽', '을', '협소', '하', '게', '형성', '하', '여서', '내부', '에', '들', '어', '있', '는', '세제', '##액', '을', '잘', '짜', '질', '수', '있', '도록', '하', '는', '합성', '##세', '##제', '액', '##포', '에', '관한', '것', '이', '다', '.']
※ Google BERT base 学習方式と同じであり、使用例は특허분야 사전학습 언어모델(KorPatBERT) 사용자 매뉴얼 2.3節をご覧ください。
韓国特許情報院言語モデルに関心のある機関・企業、研究者を対象に一定の手続きを通じて普及を遂行中です。 。
| ファイル名 | 説明 |
|---|---|
| pat_all_mecab_dic.csv | Mecab特許ユーザー辞書 |
| lm_test_data.tsv | 分類サンプルデータセット |
| korpat_tokenizer.py | KorPat Tokenizerプログラム |
| test_tokenize.py | Tokenizer使用サンプル |
| test_tokenize.ipynb | Tokenizer使用サンプル(ジュピター) |
| test_lm.py | 言語モデルの使用例 |
| test_lm.ipynb | 言語モデル使用サンプル(ジュピター) |
| korpat_bert_config.json | KorPatBERT Configファイル |
| korpat_vocab.txt | KorPatBERT Vocabularyファイル |
| model.ckpt-381250.meta | KorPatBERT Modelファイル |
| model.ckpt-381250.index | KorPatBERT Modelファイル |
| model.ckpt-381250.data-00000-of-00001 | KorPatBERT Modelファイル |


