nnl
gpt2-xl assets
nnl 、低メモリ GPU プラットフォーム上の大規模モデル用の推論エンジンです。
大きなモデルは大きすぎて GPU メモリに収まりません。 nnl PCIE 帯域幅とメモリの間のトレードオフによってこの問題に対処します。
一般的な推論パイプラインは次のとおりです。
NNIL では、GPU メモリ プールとメモリのデフラグを使用して、ローエンド GPU プラットフォームで大規模なモデルを推論できるようになります。
これは数週間で書き上げた単なる趣味のプロジェクトであり、現在は CUDA バックエンドのみがサポートされています。
make lib nnl _cuda.a && make lib nnl _cuda_kernels.aこのコマンドは、2 つの静的ライブラリ ( lib/lib nnl _cuda.aおよびlib/lib nnl _cuda_kernels.a )をビルドします。 1 つ目は C++ の CUDA バックエンドを備えたコア ライブラリで、2 つ目は CUDA カーネル用です。
GPT2-XL (1.6B) のデモプログラムをここに提供します。このプログラムは次のコマンドでコンパイルできます。
make gpt2_1558mリリースからすべてのウェイトをダウンロードした後、GTX 1050 (2 GB メモリ) などのローエンド GPU プラットフォームで次のコマンドを実行できます。
./bin/gpt2_1558m --max_len 20 " Hi. My name is Feng and I am a machine learning engineer "そして出力は次のようになります: 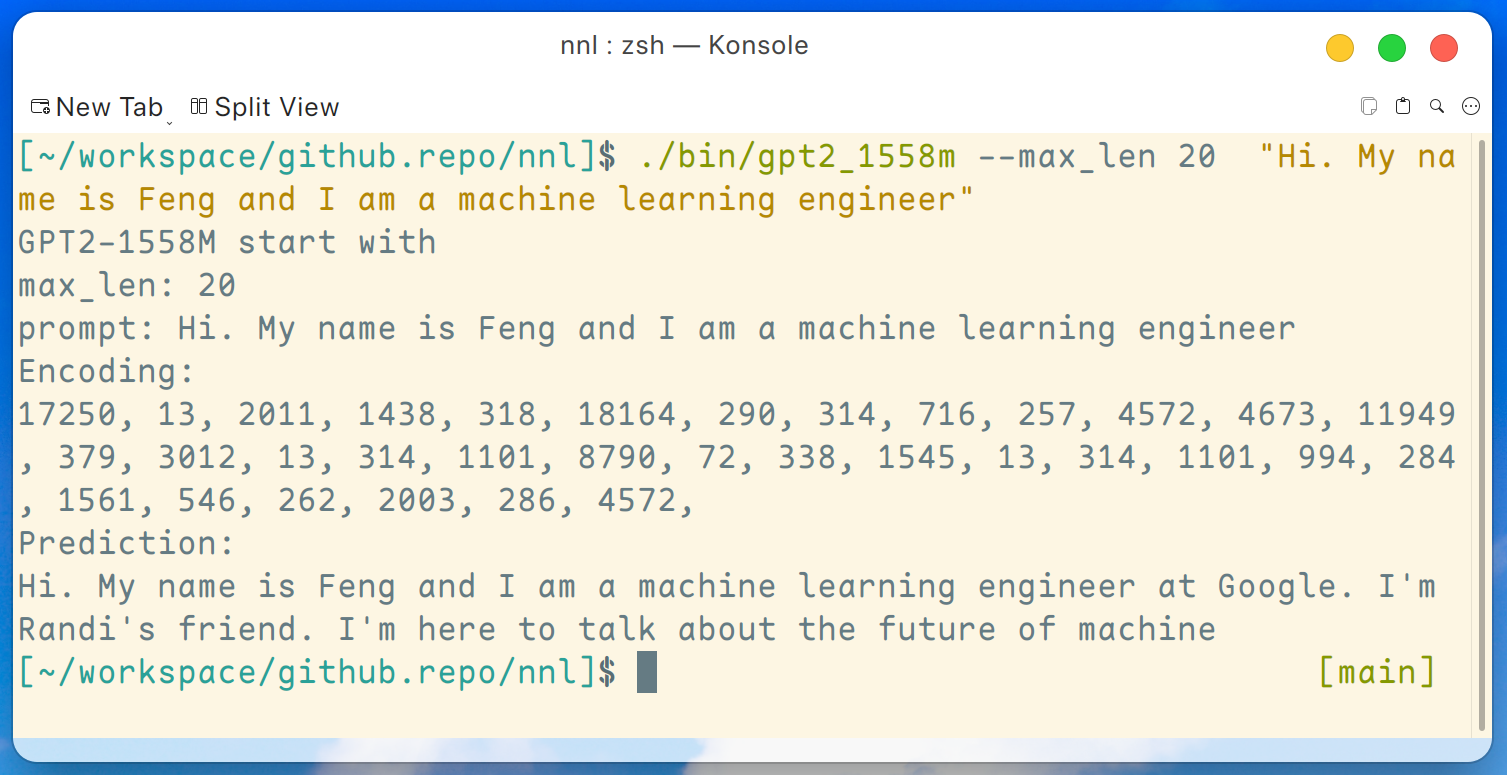
免責事項: これは gpt2-xl によって生成された単なる例であり、私は Google で働いているわけではないので、Randi のことは知りません。
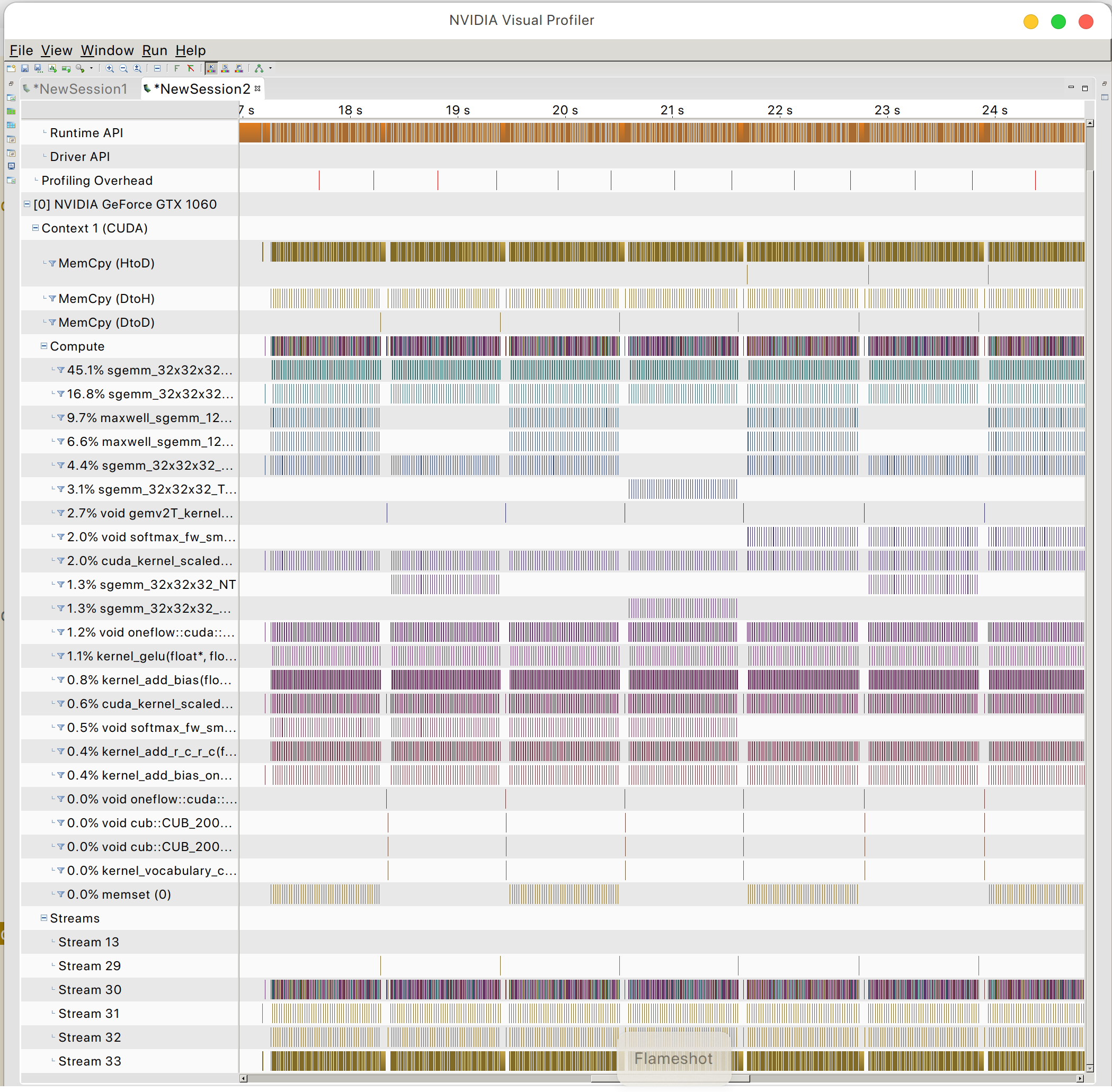
GPU メモリ アクセス パターンを見つけることができます
PeaceOSL