Patron
1.0.0
このリポジトリには、ACL 2023 論文「コールドスタート データ選択による少数ショット言語モデルの微調整: プロンプトベースの不確実性伝播アプローチ」のコードが含まれています。
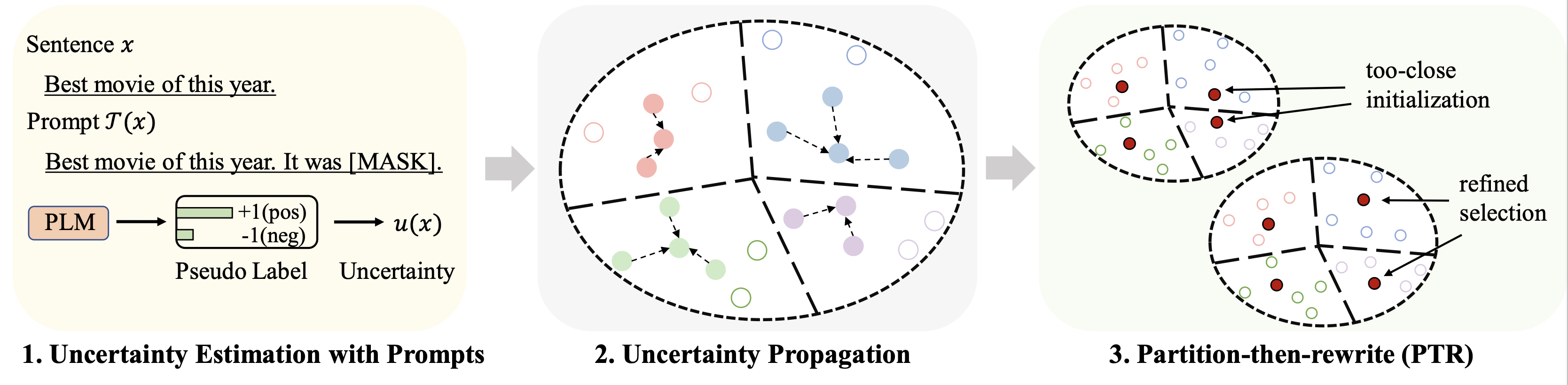
微調整のためのさまざまなデータセット (予算として 128 ラベルを使用) の結果は次のように要約されます。
| 方法 | IMDB | Yelp がいっぱい | AGニュース | ヤフー! | DBペディア | TREC | 平均 |
|---|---|---|---|---|---|---|---|
| 全面監修(RoBERTaベース) | 94.1 | 66.4 | 94.0 | 77.6 | 99.3 | 97.2 | 88.1 |
| ランダムサンプリング | 86.6 | 47.7 | 84.5 | 60.2 | 95.0 | 85.6 | 76.7 |
| 最良のベースライン (Chang et al. 2021) | 88.5 | 46.4 | 85.6 | 61.3 | 96.5 | 87.7 | 77.6 |
| Patron (私たちのもの) | 89.6 | 51.2 | 87.0 | 65.1 | 97.0 | 91.1 | 80.2 |
プロンプトベースの学習には、LM-BFF と同じパイプラインを使用します。 128 ラベルの結果は次のように表示されます。
| 方法 | IMDB | Yelp がいっぱい | AGニュース | ヤフー! | DBペディア | TREC | 平均 |
|---|---|---|---|---|---|---|---|
| 全面監修(RoBERTaベース) | 94.1 | 66.4 | 94.0 | 77.6 | 99.3 | 97.2 | 88.1 |
| ランダムサンプリング | 87.7 | 51.3 | 84.9 | 64.7 | 96.0 | 85.0 | 78.2 |
| 最良のベースライン (Yuan et al.、2020) | 88.9 | 51.7 | 87.5 | 65.9 | 96.8 | 86.5 | 79.5 |
| Patron (私たちのもの) | 89.3 | 55.6 | 87.8 | 67.6 | 97.4 | 88.9 | 81.1 |
python 3.8
transformers==4.2.0
pytorch==1.8.0
scikit-learn
faiss-cpu==1.6.4
sentencepiece==0.1.96
tqdm>=4.62.2
tensorboardX
nltk
openprompt
主な実験には次の 4 つのデータセットを使用します。
| データセット | タスク | クラス数 | ラベルなしデータ/テストデータの数 |
|---|---|---|---|
| IMDB | 感情 | 2 | 25k/25k |
| Yelp がいっぱい | 感情 | 5 | 39k/10k |
| AGニュース | ニューストピック | 4 | 119k/7.6k |
| ヤフー!答え | QAトピック | 5 | 180k/30.1k |
| DBペディア | オントロジーのトピック | 14 | 280k/70k |
| TREC | 質問のトピック | 6 | 5k/0.5k |
加工したデータはこちらのリンクからご覧いただけます。これらのデータセットを配置するフォルダーについては、次のパートで説明します。
次のコマンドを実行します
python gen_embedding_simcse.py --dataset [the dataset you use] --gpuid [the id of gpu you use] --batchsize [the number of data processed in one time]
データセットについては、上記のリンクのプロンプトを介して取得された疑似予測を提供します。詳細については原著論文を参照してください。
次のコマンドを実行します (AG News データセットの例)
python Patron _sample.py --dataset agnews --k 50 --rho 0.01 --gamma 0.5 --beta 0.5
いくつかの重要なハイパーパラメータ:
rho : 式(1)の不確実性の伝播に使用されるパラメータ。紙の6beta : 式の距離の正則化。紙の8gamma : 式の正則化項の重み。紙の10枚詳細な手順については、 finetuneフォルダーを参照してください。
詳細な手順については、 prompt_learningフォルダーを参照してください。
プロンプトベースの予測を生成するためのパイプラインとしてこのリンクを参照してください。プロンプト言語化ツールとテンプレートをカスタマイズする必要があることに注意してください。
ドキュメントの埋め込みを生成するには、SimCSE を使用して上記のコマンドに従います。
選択したデータのインデックスを生成したら、 Running Fine-tuning ExperimentsとRunning Prompt-based Learning Experiments 。
このリポジトリがあなたの研究に役立つと思われる場合は、次の論文を引用してください。前もって感謝します!
@article{yu2022 Patron ,
title={Cold-Start Data Selection for Few-shot Language Model Fine-tuning: A Prompt-Based Uncertainty Propagation Approach
},
author={Yue Yu and Rongzhi Zhang and Ran Xu and Jieyu Zhang and Jiaming Shen and Chao Zhang},
journal={arXiv preprint arXiv:2209.06995},
year={2022}
}
よく整理されたコードを提供してくれたリポジトリ SimCSE と OpenPrompt の作成者に感謝します。


