JustJoking.ai
1.0.0
このプロジェクトでは、短いジョークを生成するために変圧器モデルをトレーニングしました。次に、推論方法を少し変更することで、同じモデルを使用することができました。入力として初期文字列が与えられると、モデルはそれをユーモラスな方法で完成させようとします。
2 つのノートブックがあり、どちらも同じタスクを実行しています。
ジョーク生成の結果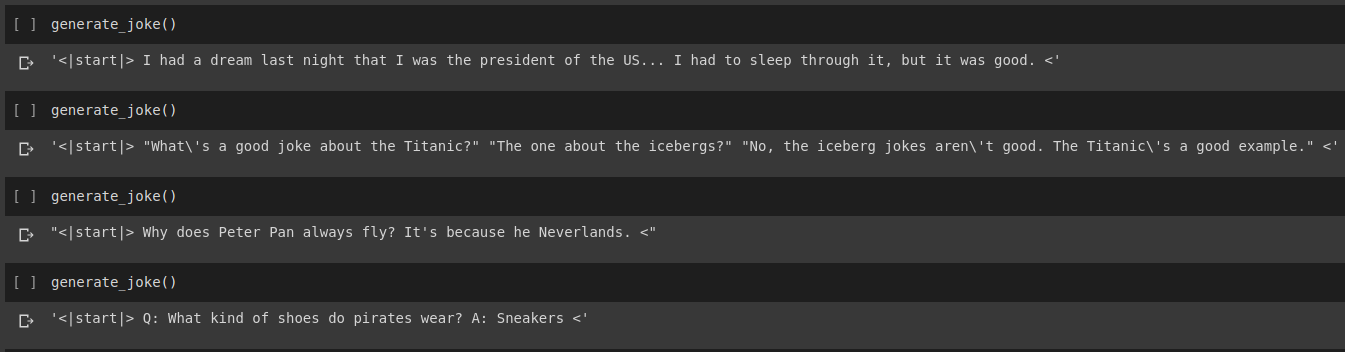
文章完成の結果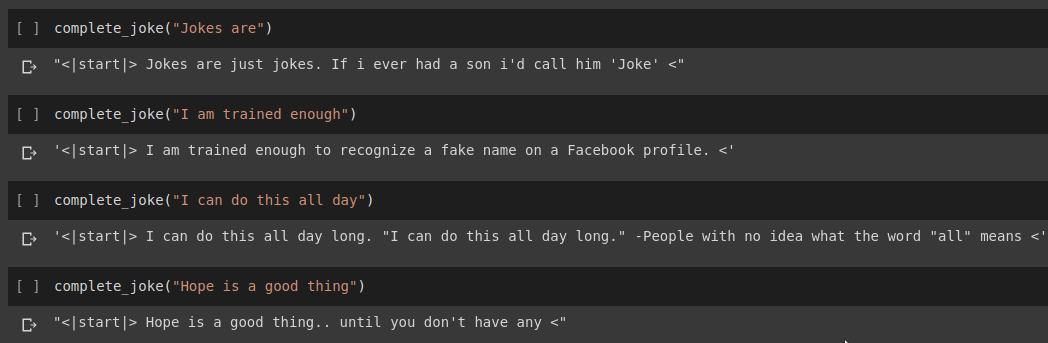
結果
このタスクでは、Kaggle で提供されているデータセットを使用します。これは、Reddit からスクラップされた 200,000 を超えるショート ジョークを含む CSV です。
注 :データセットはさまざまなサブレディットから単純にスクラップされたものであるため、データセット内のジョークの多くは非常に人種差別的で性差別的です。 AI はトレーニング データを単一の知識源として想定しているため、モデルが同様のジョークを生成することがあることが予想されます。
ジョーク文字列をトークン化したら、トークン化されたリストの末尾にstart_tokenとend_tokenを追加します。また、ジョーク文字列は異なる長さになる可能性があるため、すべてのテンソルがバッチ内で同様の形状になるように、指定されたmax_lengthまですべての文字列にパディングを適用します。
このコードは、ノートブックJoke Generation.ipynbにあります。ここでは、HuggingFace ライブラリから GPT2Tokenizer と TFGPT2LMHead モデルをインポートします。コードは Tensorflow2 で書かれています。ノートブックには、適切な場所にコードの説明を提供するコメントが含まれています。また、HuggingFace Docs は、モデルの入力パラメータと戻り値についての優れたドキュメントを提供します。 PyTorch ベースの実装については、Tanul Singh の Humour.ai リポジトリを参照してください。
このコードは、ノートブックJoke_Completion_Pure_TF2_Implementation.ipynbにあります。物事がどのように機能するかをより深く理解するためにプロジェクトをさらに一歩進めて、外部ライブラリを使用せずにトランスフォーマーを構築しようとしました。 Tensorflow が提供する Transformers のチュートリアルを参照し、何が起こっているのかを理解しやすいように、そのチュートリアルで言及されている説明の一部を追加の説明とともにノートブックに貼り付けました。
まず、データセット用のトークナイザーを構築し、それを使用して文字列をトークン化しました。次に、 Positional EncodingsとMultiHeadAttentionのレイヤーを構築しました。また、データに適したマスクを作成するためにLambda layer使用しました。
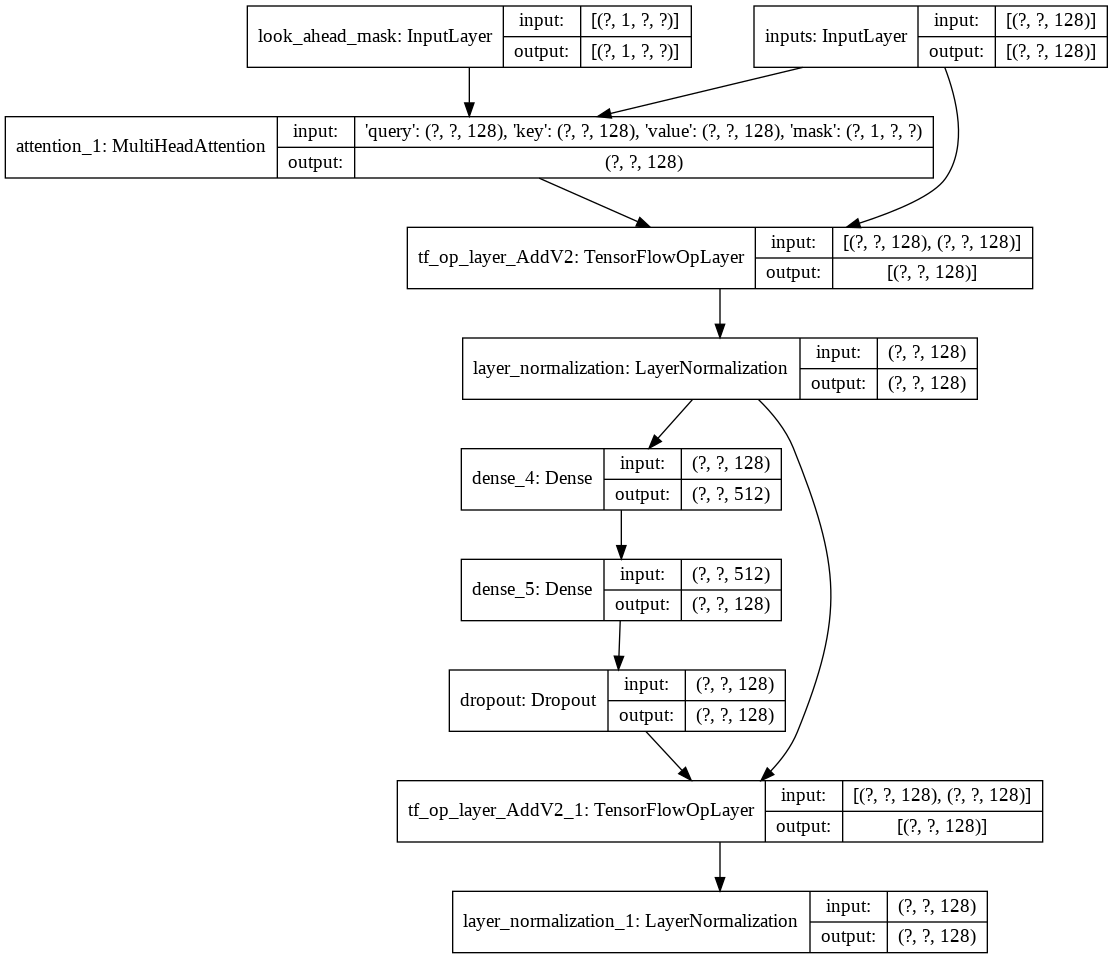
次に、デコーダ用に単一のdecoder layerを構築しました。以下は単一デコーダ層のアーキテクチャです。
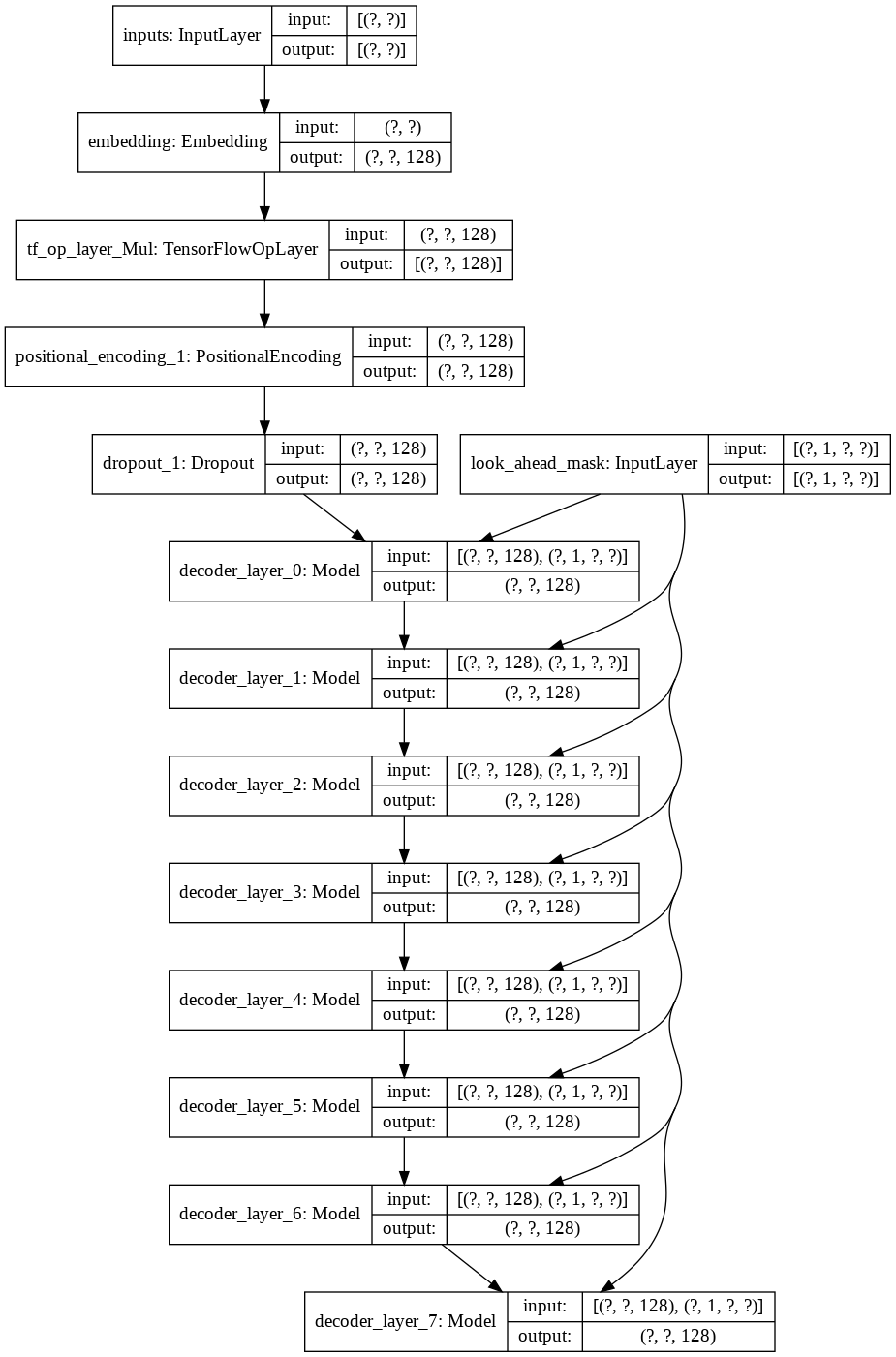
最終的なtransformerモデルでは、入力トークンを受け取り、それをラムダ層に渡してマスクを取得し、マスクとトークンの両方を言語デコーダーに渡し、言語デコーダーの出力は密層を介して渡されます。以下は最終モデルのアーキテクチャです。