DialogStudio
1.0.0

紙、ハグフェイス、モデル、Twitter
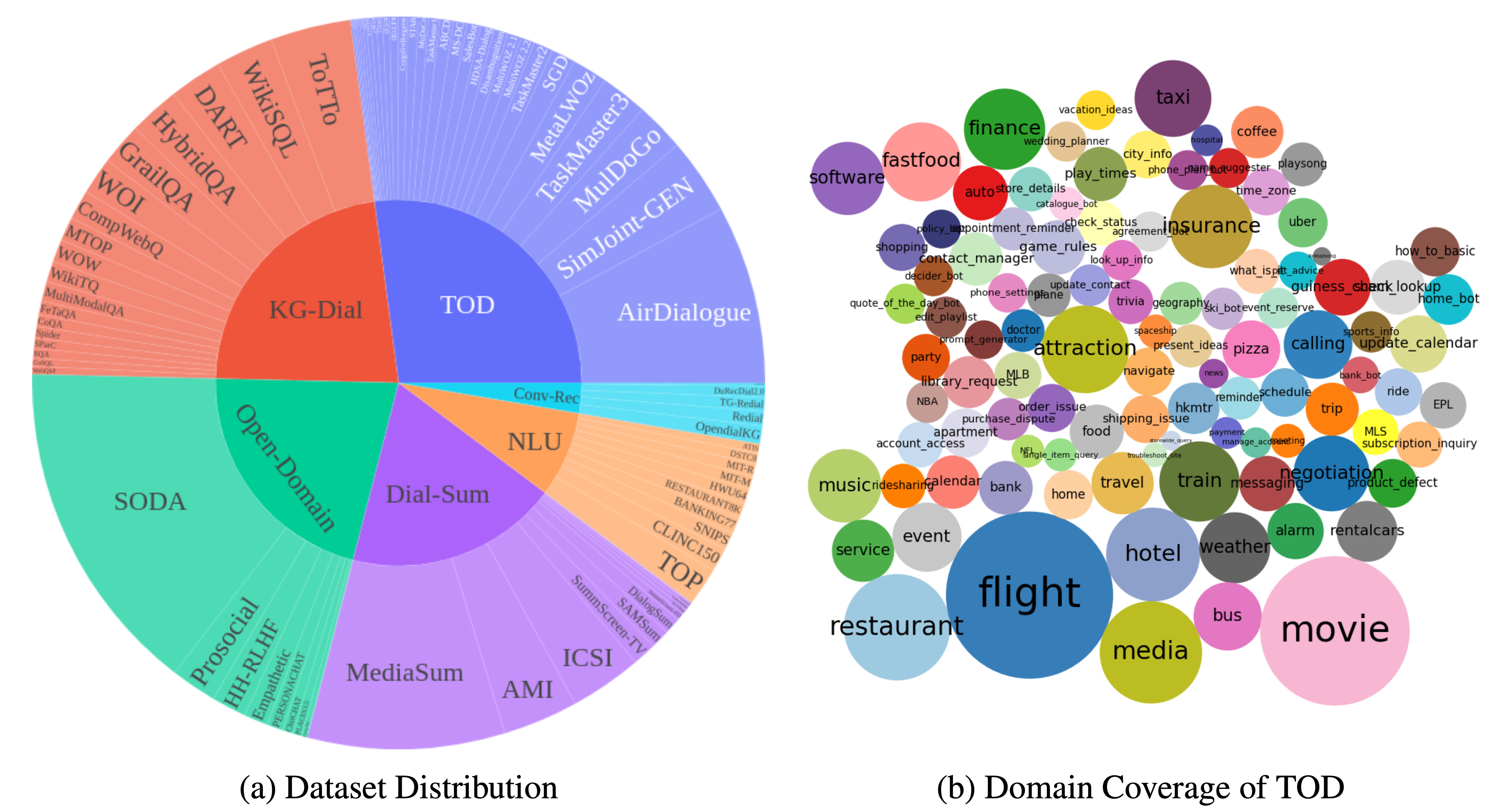
DialogStudio 、大規模なコレクションと統合されたダイアログ データセットです。以下の図は、 DialogStudioに関連する一般的な統計の概要を示しています。 DialogStudio 、元の情報を維持しながら各データセットを統合したため、個々のデータセットと大規模言語モデル (LLM) トレーニングの両方の研究をサポートするのに役立ちます。利用可能なすべてのデータセットの完全なリストはここにあります。
データは、「データのロード」で紹介されているように、Huggingface を通じてダウンロードできます。このリポジトリでは、各データセットの例も提供しています。より詳細なカテゴリ固有の詳細については、 DialogStudioコレクション内の各カテゴリに対応する個別のフォルダー (たとえば、タスク指向ダイアログ カテゴリにある MULTIWOZ2_2 データセット) を参照してください。
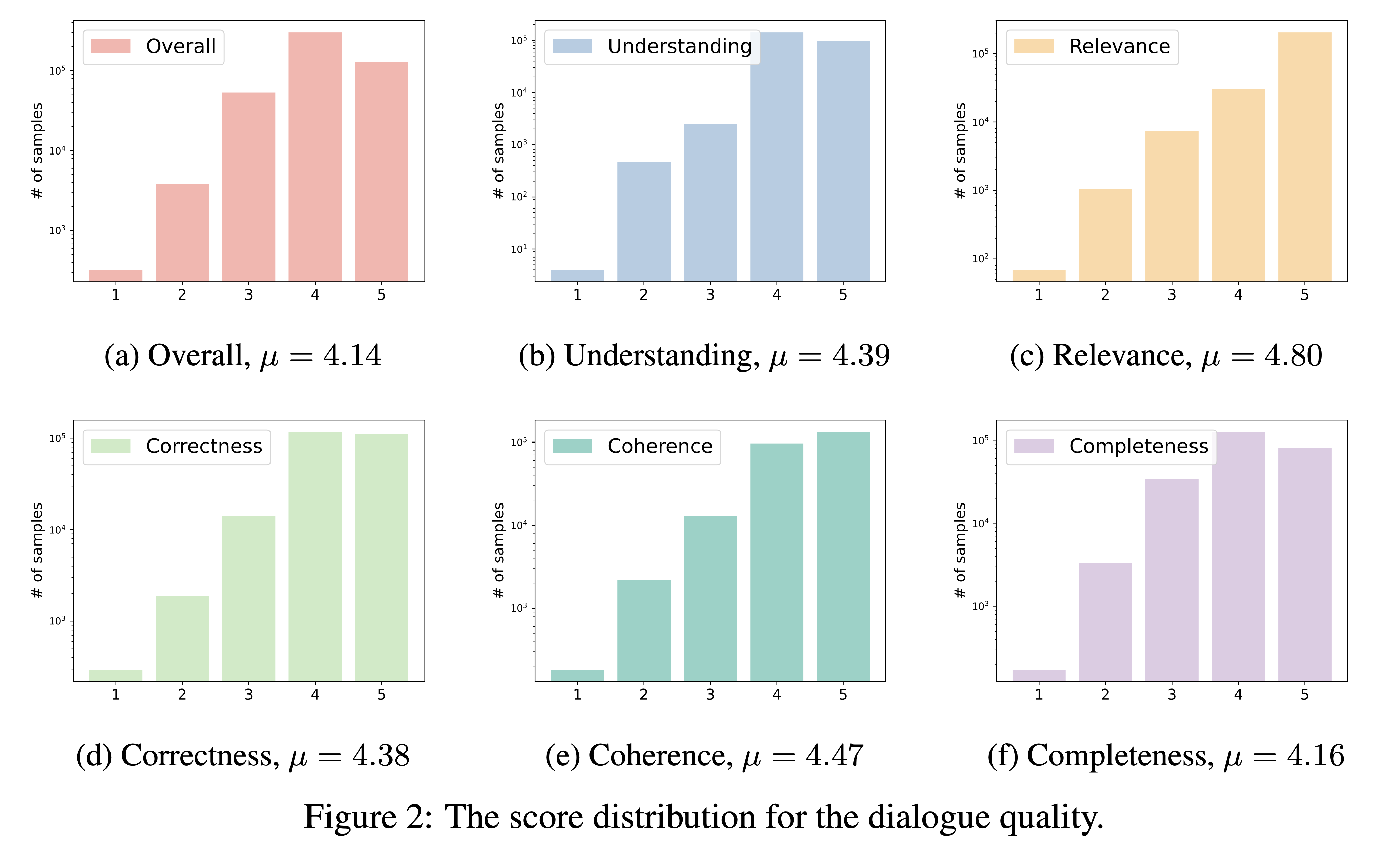
DialogStudio 、理解、関連性、正確性、一貫性、完全性、全体的な品質という 6 つの重要な基準に基づいて対話の品質を評価します。各基準は 1 ~ 5 のスケールで採点され、最高のスコアは例外的な対話のために確保されます。
DialogStudioに組み込まれている膨大な数のデータセットを考慮して、「gpt-3.5-turbo」を利用して 33 の異なるデータセットを評価しました。この評価に使用される対応するスクリプトには、リンクからアクセスできます。
対話品質評価の結果は以下に示されています。今後、個別に選定したセリフの評価点を公開する予定です。
{dataset_name} (正確にデータセット フォルダー名) を要求することで、HuggingFace ハブからDialogStudioに任意のデータセットを読み込むことができます。利用可能なすべてのデータセットは、データセットのコンテンツで説明されています。
以下は、タスク指向ダイアログ カテゴリの下で MULTIWOZ2_2 データセットをロードする一例です。
データセットをロードする
from datasets import load_dataset
dataset = load_dataset ( 'Salesforce/ DialogStudio ' , 'MULTIWOZ2_2' )MultiWOZ 2.2の出力構造は次のとおりです。
DatasetDict ({
train : Dataset ({
features : [ 'original dialog id' , 'new dialog id' , 'dialog index' , 'original dialog info' , 'log' , 'prompt' , 'external knowledge non-flat' , 'external knowledge' , 'dst knowledge' , 'intent knowledge' ],
num_rows : 8437
})
validation : Dataset ({
features : [ 'original dialog id' , 'new dialog id' , 'dialog index' , 'original dialog info' , 'log' , 'prompt' , 'external knowledge non-flat' , 'external knowledge' , 'dst knowledge' , 'intent knowledge' ],
num_rows : 1000
})
test : Dataset ({
features : [ 'original dialog id' , 'new dialog id' , 'dialog index' , 'original dialog info' , 'log' , 'prompt' , 'external knowledge non-flat' , 'external knowledge' , 'dst knowledge' , 'intent knowledge' ],
num_rows : 1000
})
})データセットは、この GitHub リポジトリと HuggingFace ハブでいくつかのカテゴリに分割されています。詳細については、データセットの表を確認してください。各フォルダーをクリックすると、いくつかの例を確認できます。
いくつかの選択されたDialogStudioデータセットでトレーニングされたモデルのバージョン 1.0 ( DialogStudio -t5-base-v1.0、 DialogStudio -t5-large-v1.0、 DialogStudio -t5-3b-v1.0) をロールアウトしました。詳細については、各モデル カードを確認してください。
以下は CPU 上でモデルを実行する一例です。
from transformers import AutoTokenizer , AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer . from_pretrained ( "Salesforce/ DialogStudio -t5-base-v1.0" )
model = AutoModelForSeq2SeqLM . from_pretrained ( "Salesforce/ DialogStudio -t5-base-v1.0" )
input_text = "Answer the following yes/no question by reasoning step-by-step. Can you write 200 words in a single tweet?"
input_ids = tokenizer ( input_text , return_tensors = "pt" ). input_ids
outputs = model . generate ( input_ids , max_new_tokens = 256 )
print ( tokenizer . decode ( outputs [ 0 ], skip_special_tokens = True ))私たちのプロジェクトは、ライセンスに関して次の構造に従っています。
ライセンス情報の詳細については、元のデータセットに付属する特定のライセンスを参照してください。当社はライセンスの問題について責任を負わないため、これらの規約を理解しておくことが重要です。
会話型 AI 分野に貢献してくださったすべてのデータセット作成者に心から感謝します。慎重な努力にも関わらず、引用または参照に不正確さが生じる可能性があります。エラーや欠落を見つけた場合は、改善のために問題を提起するか、プル リクエストを送信してください。ありがとう!
このリポジトリのデータとコードのほとんどは、以下の論文用に開発されたか、そこから派生したものです。 DialogStudioのデータセットを利用する場合は、元の著作物と私たち自身の著作物の両方を引用していただくようお願いいたします (長い論文として EACL 2024 Findings に受け入れられました)。
@article{zhang2023 DialogStudio ,
title={ DialogStudio : Towards Richest and Most Diverse Unified Dataset Collection for Conversational AI},
author={Zhang, Jianguo and Qian, Kun and Liu, Zhiwei and Heinecke, Shelby and Meng, Rui and Liu, Ye and Yu, Zhou and Savarese, Silvio and Xiong, Caiming},
journal={arXiv preprint arXiv:2307.10172},
year={2023}
}
私たちはコミュニティからの貢献を熱心に募集しています。会話型 AI の分野を前進させるという私たちの共通の使命に参加してください。


