reflexion
1.0.0
このリポジトリには、Noah Shinn、Federico Cassano、Edward Berman、Ashwin Gopinath、Karthik Narasimhan、Shunyu Yao によるreflexion : Language Agents with Verbal Reinforcement Learning のコード、デモ、およびログ ファイルが保存されています。
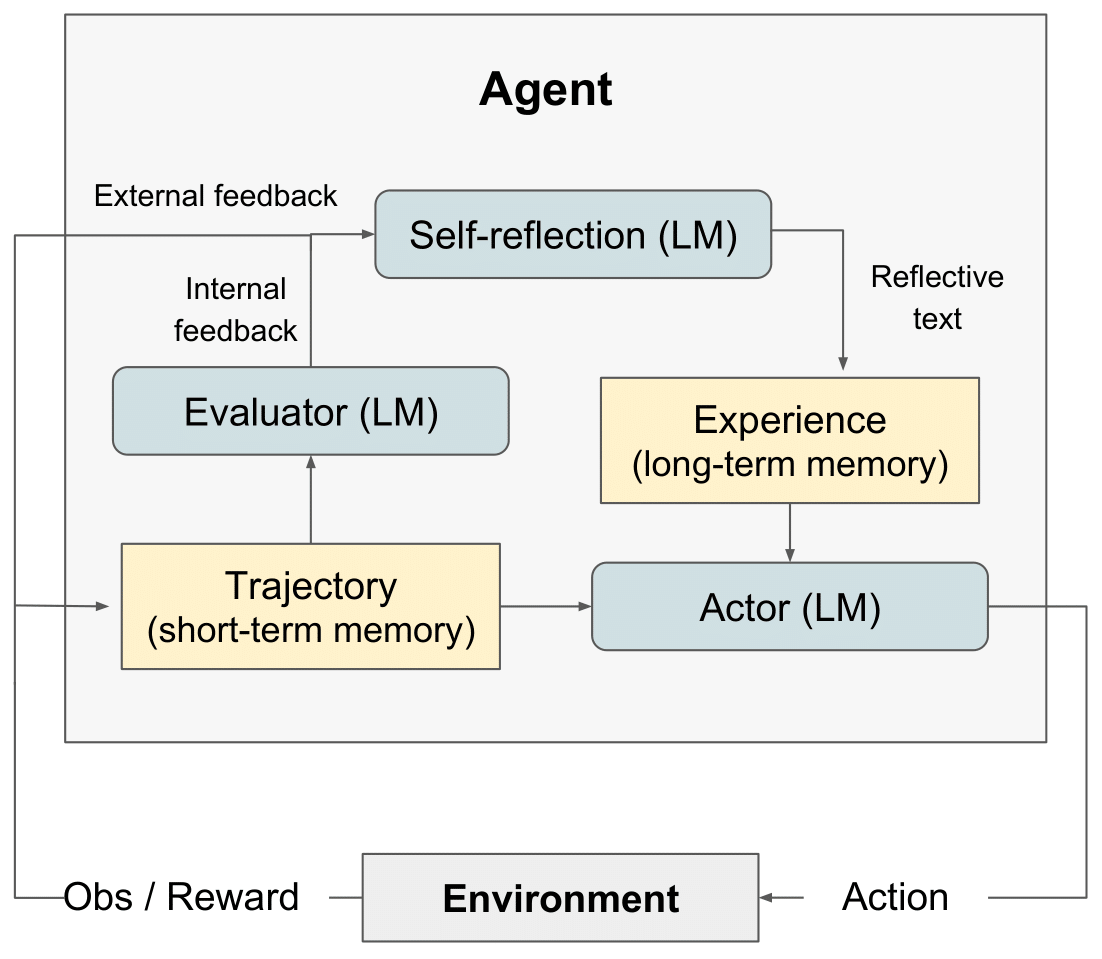 反射 RL 図" style="max-width: 100%;">
反射 RL 図" style="max-width: 100%;">
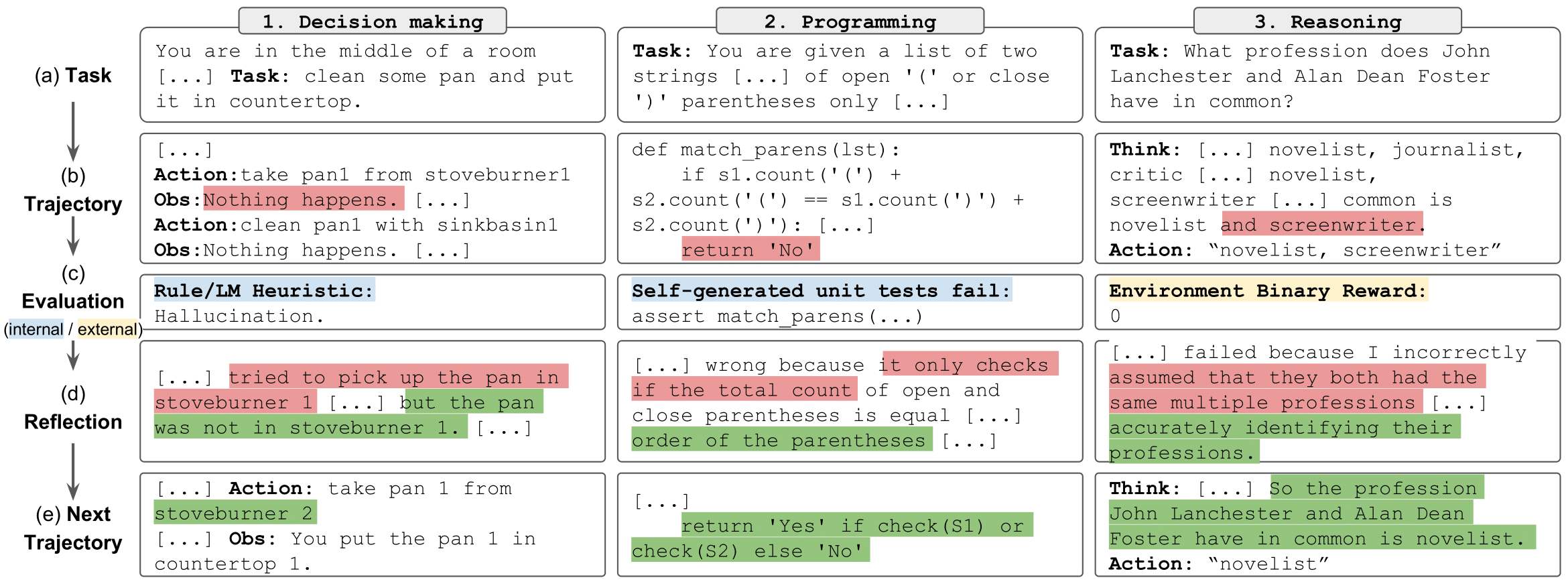 リフレクション タスク" style="max-width: 100%;">
リフレクション タスク" style="max-width: 100%;">
LeetcodeHardGymをここでリリースしました
推論実験の結果を簡単に実行、探索、操作できるように、ノートブックのセットが提供されています。各実験は、HotPotQA ディストラクター データセットからの 100 の質問のランダム サンプルで構成されます。サンプル内の各質問は、特定の種類とreflexion戦略を使用してエージェントによって試行されます。
始めるには:
git clone https://github.com/noahshinn/reflexion && cd ./hotpotqa_runspip install -r requirements.txtOPENAI_API_KEY環境変数を OpenAI API キーに設定します。 export OPENAI_API_KEY= < your key > エージェントのタイプは、実行することを選択したノートブックによって決まります。利用可能なエージェントのタイプは次のとおりです。
ReAct - リアクトエージェント
CoT_context - 質問に関するサポートコンテキストを与えられた CoT エージェント
CoT_no_context - CoT エージェントには質問に関するサポート コンテキストが与えられませんでした
各エージェント タイプのノートブックは./hotpot_runs/notebooksディレクトリにあります。
各ノートブックでは、エージェントが使用するreflexion戦略を指定できます。 Enumで定義されている使用可能なreflexion戦略には次のものがあります。
reflexion Strategy.NONE - エージェントには、最後の試行に関する情報が与えられません。
reflexion Strategy.LAST_ATTEMPT - エージェントには、質問に対する最後の試行からの推論トレースがコンテキストとして与えられます。
reflexion Strategy. reflexion - エージェントには、最後の試行に関する自己反省がコンテキストとして与えられます。
reflexion Strategy.LAST_ATTEMPT_AND_ reflexion - エージェントには、コンテキストとして最後の試行における推論トレースと自己反省の両方が与えられます。
このリポジトリのクローンを作成し、AlfWorld ディレクトリに移動します
git clone https://github.com/noahshinn/reflexion && cd ./alfworld_runs ./run_ reflexion .shで実行パラメータを指定します。 num_trials : 反復学習ステップの数num_envs : 試行ごとのタスクと環境のペアの数run_name : この実行の名前use_memory : 永続メモリを使用して自己反映を保存します (ベースライン実行を実行するにはオフにします) is_resume : 再開するためにログ ディレクトリを使用します前回の実行resume_dir : 前回の実行を再開するログディレクトリstart_trial_num : 実行を再開する場合、開始するトライアル番号
トライアルを実行する
./run_ reflexion .shログは./root/<run_name>に送信されます。
これらの実験の性質上、GPT-4 にはアクセスが制限されており、API 料金が高額であるため、個々の開発者が結果を再実行することは現実的ではない可能性があります。論文のすべての実行と追加の結果は、意思決定の場合は./alfworld_runs/rootに、推論の場合は./hotpotqa_runs/rootに、プログラミングの場合は./programming_runs/rootに記録されます。
元のコードのコードはここで確認してください
ここのブログ投稿を読む
ここで興味深い型予測の実装を確認してください: OpenTau
ご質問がある場合は、[email protected] までお問い合わせください。
@misc { shinn2023 reflexion ,
title = { reflexion : Language Agents with Verbal Reinforcement Learning } ,
author = { Noah Shinn and Federico Cassano and Edward Berman and Ashwin Gopinath and Karthik Narasimhan and Shunyu Yao } ,
year = { 2023 } ,
eprint = { 2303.11366 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.AI }
}

