automata
v0.0.4
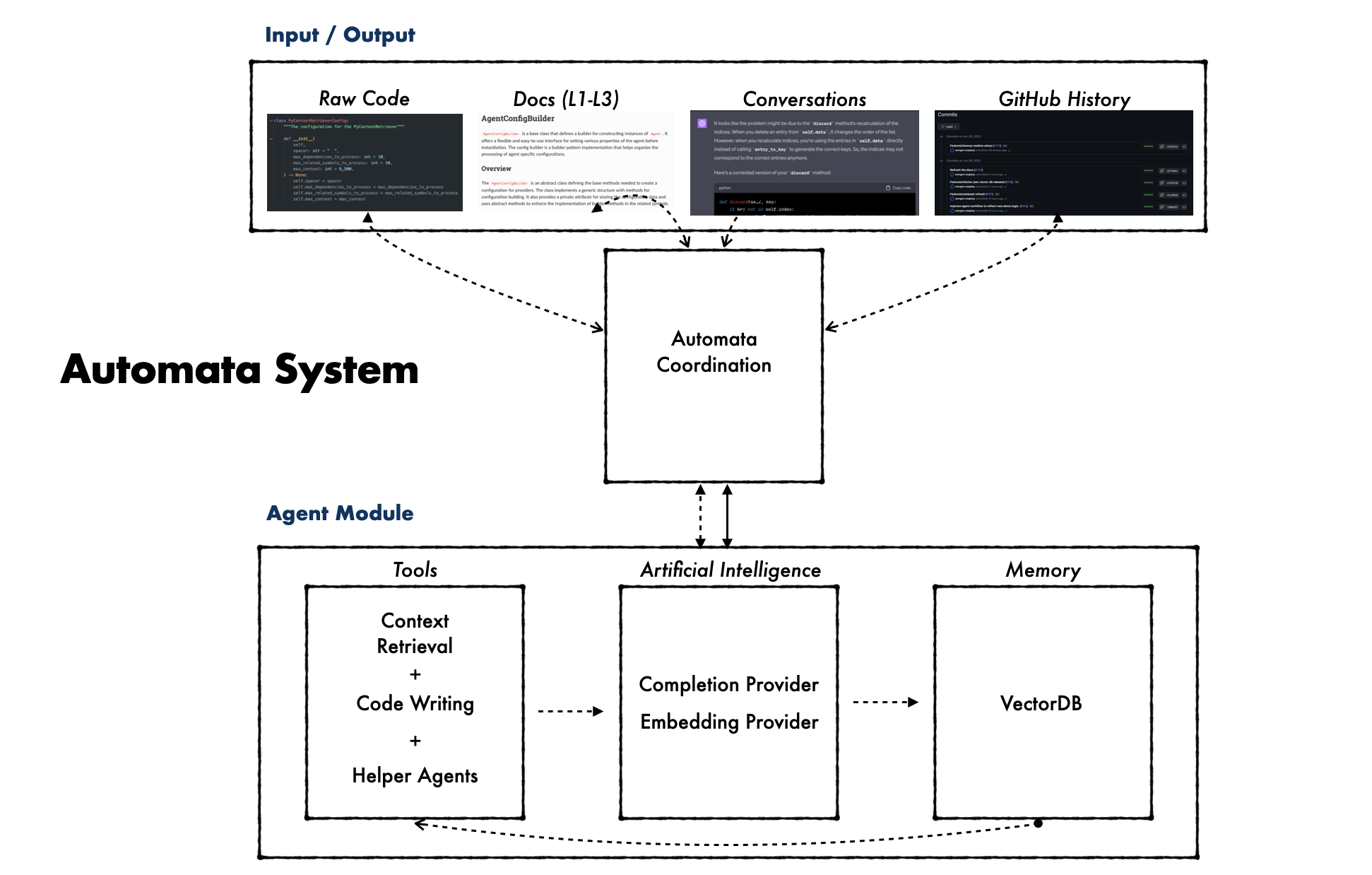
automata 、コードは本質的にメモリの一種であり、適切なツールを備えた場合、AI はリアルタイム機能を進化させ、AGI の作成につながる可能性があるという理論に触発されています。 automata言葉はギリシャ語の αὐτόματος に由来しており、「自発的、自発的、自発的」を意味し、 automata理論は抽象的な機械とautomata 、およびそれらを使用して解決できる計算問題の研究です。 。
詳細については以下に続きます。
automata環境をセットアップするには、次の手順に従ってください。
# Clone the repository
git clone [email protected]:emrgnt-cmplxty/ automata .git && cd automata /
# Initialize git submodules
git submodule update --init
# Install poetry and the project
pip3 install poetry && poetry install
# Configure the environment and setup files
poetry run automata configureDocker イメージをプルします。
$ docker pull ghcr.io/emrgnt-cmplxty/ automata :latestDocker イメージを実行します。
$ docker run --name automata _container -it --rm -e OPENAI_API_KEY= < your_openai_key > -e GITHUB_API_KEY= < your_github_key > ghcr.io/emrgnt-cmplxty/ automata :latestこれにより、 automataがインストールされた Docker コンテナが起動し、使用する対話型シェルが開きます。
Windows ユーザーは、特定の依存関係について、Visual Studio の「C++ を使用したデスクトップ開発」を通じて C++ サポートをインストールする必要がある場合があります。
さらに、gcc-11 および g++-11 への更新が必要になる場合があります。これは、次のコマンドを実行することで実行できます。
# Adds the test toolchain repository, which contains newer versions of software
sudo add-apt-repository ppa:ubuntu-toolchain-r/test
# Updates the list of packages on your system
sudo apt update
# Installs gcc-11 and g++-11 packages
sudo apt install gcc-11 g++-11
# Sets gcc-11 and g++-11 as the default gcc and g++ versions for your system
sudo update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-11 60 --slave /usr/bin/g++ g++ /usr/bin/g++-11automata検索を実行するには SCIP インデックスが必要です。これらのインデックスは、コードベース全体の依存関係によってシンボルを関連付けるコード グラフを作成するために使用されます。 automataコードベース用に新しいインデックスが定期的に生成され、アップロードされますが、プログラマーはローカル開発に必要な場合、インデックスを手動で生成する必要があります。問題が発生した場合は、こちらの手順を参照することをお勧めします。
# Install dependencies and run indexing on the local codebase
poetry run automata install-indexing # Refresh the code embeddings (after making local changes)
poetry run automata run-code-embedding
# Refresh the documentation + embeddings
poetry run automata run-doc-embedding --embedding-level=2
次のコマンドは、簡単な命令でシステムを実行する方法を示しています。システムが期待どおりに動作していることを確認するために、最初の実行はこのようなものにすることをお勧めします。
# Run a single agent w/ trivial instruction
poetry run automata run-agent --instructions= " Return true " --model=gpt-3.5-turbo-0613
# Run a single agent w/ a non-trivial instruction
poetry run automata run-agent --instructions= " Explain what automata Agent is and how it works, include an example to initialize an instance of automata Agent. " automata 、GPT-4 などの大規模言語モデルをベクトル データベースと組み合わせて機能し、コードの文書化、検索、記述が可能な統合システムを形成します。この手順は、包括的なドキュメントとコード インスタンスの生成から始まります。これは、検索機能と組み合わせることで、 automataの自己コーディングの可能性の基礎を形成します。
automata下流のツールを使用して高度なコーディング タスクを実行し、その専門知識と自律性を継続的に構築します。このセルフコーディングのアプローチは自律的な職人の仕事を反映しており、ツールやテクニックはフィードバックと蓄積された経験に基づいて一貫して改良されています。
複雑なシステムを理解するための最良の方法は、基本的な例を理解することから始めることです。次の例は、独自のautomataエージェントを実行する方法を示しています。エージェントは簡単な命令で初期化され、その命令を実行するコードの作成を試みます。エージェントは試行の結果を返します。
from automata . config . base import AgentConfigName , OpenAI automata AgentConfigBuilder
from automata . agent import OpenAI automata Agent
from automata . singletons . dependency_factory import dependency_factory
from automata . singletons . py_module_loader import py_module_loader
from automata . tools . factory import AgentToolFactory
# Initialize the module loader to the local directory
py_module_loader . initialize ()
# Construct the set of all dependencies that will be used to build the tools
toolkit_list = [ "context-oracle" ]
tool_dependencies = dependency_factory . build_dependencies_for_tools ( toolkit_list )
# Build the tools
tools = AgentToolFactory . build_tools ( toolkit_list , ** tool_dependencies )
# Build the agent config
agent_config = (
OpenAI automata AgentConfigBuilder . from_name ( " automata -main" )
. with_tools ( tools )
. with_model ( "gpt-4" )
. build ()
)
# Initialize and run the agent
instructions = "Explain how embeddings are used by the codebase"
agent = OpenAI automata Agent ( instructions , config = agent_config )
result = agent . run ()このコードベースの埋め込みは、 SymbolCodeEmbeddingやSymbolDocEmbeddingなどのクラスによって表されます。これらのクラスは、シンボルと、高次元空間でシンボルを表すベクトルであるそのそれぞれの埋め込みに関する情報を格納します。
これらのクラスの例は次のとおりです。 SymbolCodeEmbeddingシンボルのコードに関連する埋め込みを格納するために使用されるクラス。 SymbolDocEmbeddingシンボルのドキュメントに関連する埋め込みを格納するために使用されるクラスです。
「SymbolCodeEmbedding」のインスタンスを作成するコード例:
import numpy as np
from automata . symbol_embedding . base import SymbolCodeEmbedding
from automata . symbol . parser import parse_symbol
symbol_str = 'scip-python python automata 75482692a6fe30c72db516201a6f47d9fb4af065 ` automata .agent.agent_enums`/ActionIndicator#'
symbol = parse_symbol ( symbol_str )
source_code = 'symbol_source'
vector = np . array ([ 1 , 0 , 0 , 0 ])
embedding = SymbolCodeEmbedding ( symbol = symbol , source_code = source_code , vector = vector )「SymbolDocEmbedding」のインスタンスを作成するコード例:
from automata . symbol_embedding . base import SymbolDocEmbedding
from automata . symbol . parser import parse_symbol
import numpy as np
symbol = parse_symbol ( 'your_symbol_here' )
document = 'A document string containing information about the symbol.'
vector = np . random . rand ( 10 )
symbol_doc_embedding = SymbolDocEmbedding ( symbol , document , vector )automataに貢献したい場合は、必ず貢献ガイドラインを確認してください。このプロジェクトはautomataの行動規範に準拠しています。参加することにより、この規範を遵守することが期待されます。
リクエストやバグの追跡には GitHub の問題を使用します。一般的な質問やディスカッションについてはautomataディスカッションを参照し、特定の質問を直接送ってください。
automataプロジェクトは、オープンソース ソフトウェア開発で一般に受け入れられているベスト プラクティスを遵守するよう努めています。
automataプロジェクトの最終的な目標は、複雑なソフトウェア システムを独立して設計、作成、テスト、改良できるレベルの熟練度に達することです。これには、大規模なコードベースを理解してナビゲートする能力、ソフトウェア アーキテクチャについて推論する能力、パフォーマンスを最適化する能力、さらには必要に応じて新しいアルゴリズムやデータ構造を発明する能力が含まれます。
この目標を完全に実現するのは複雑で長期的な取り組みとなる可能性が高いですが、それに向けた一歩一歩が人間のプログラマーの生産性を劇的に向上させるだけでなく、AI とコンピューターの根本的な問題にも光を当てる可能性を秘めています。科学。
automata Apache License 2.0 に基づいてライセンスされています。
このプロジェクトは、このリポジトリから始まった emrgnt-cmplxty と maks-ivanov の間の初期の取り組みの延長です。


