Scraping Dynamic JavaScript Ajax Websites With BeautifulSoup
1.0.0

JavaScriptをレンダリングできますか?Browserほとんどの Web サイトの Web スクレイピングは比較的簡単かもしれません。このトピックについては、このチュートリアルですでに詳しく説明されています。ただし、同じ方法ではスクレイピングできないサイトも数多くあります。その理由は、これらのサイトは JavaScript を使用してコンテンツを動的に読み込むためです。
この技術は、AJAX (Asynchronous JavaScript and XML) とも呼ばれます。歴史的に、この標準には、ページ全体をリロードせずに Web サーバーから XML を取得するXMLHttpRequestオブジェクトの作成が含まれていました。最近では、このオブジェクトが直接使用されることはほとんどありません。通常、jQuery などのラッパーは、JSON、部分的な HTML、さらには画像などのコンテンツを取得するために使用されます。
通常の Web ページをスクレイピングするには、少なくとも 2 つのライブラリが必要です。 requestsライブラリがページをダウンロードします。このページが HTML 文字列として利用可能になったら、次のステップはこれを BeautifulSoup オブジェクトとして解析します。この BeautifulSoup オブジェクトを使用して、特定のデータを検索できます。
これは、 idがfirstHeadingに設定されたh1要素内のテキストを出力する簡単なスクリプトの例です。
import requests
from bs4 import BeautifulSoup
response = requests . get ( "https://quotes.toscrape.com/" )
bs = BeautifulSoup ( response . text , "lxml" )
author = bs . find ( "small" , class_ = "author" )
if author :
print ( author . text )
## OUTPUT
# Albert EinsteinBeautiful Soup ライブラリのバージョン 4 を使用していることに注意してください。以前のバージョンは廃止されました。 Beautiful Soup 4 が単に Beautiful Soup、BeautifulSoup、または bs4 と表記される場合もあります。これらはすべて、同じ美しいSoup 4ライブラリを参照しています。
サイトが動的である場合、同じコードは機能しません。たとえば、同じサイトにはhttps://quotes.toscrape.com/js/に動的バージョンがあります (この URL の末尾にjs があることに注意してください)。
response = requests . get ( "https://quotes.toscrape.com/js" ) # dynamic web page
bs = BeautifulSoup ( response . text , "lxml" )
author = bs . find ( "small" , class_ = "author" )
if author :
print ( author . text )
## No outputその理由は、2 番目のサイトは動的であり、 JavaScript使用してデータが生成されるためです。
このようなサイトを処理するには 2 つの方法があります。
この 2 つのアプローチについては、このチュートリアルで詳しく説明します。
ただし、まず、サイトが動的かどうかを判断する方法を理解する必要があります。
Chrome または Edge を使用して Web サイトが動的であるかどうかを判断する最も簡単な方法は次のとおりです。 (これらのブラウザはどちらも内部で Chromium を使用しています)。
F12キーを押して開発者ツールを開きます。フォーカスが開発者ツールにあることを確認し、 CTRL+SHIFT+Pキーの組み合わせを押してコマンド メニューを開きます。
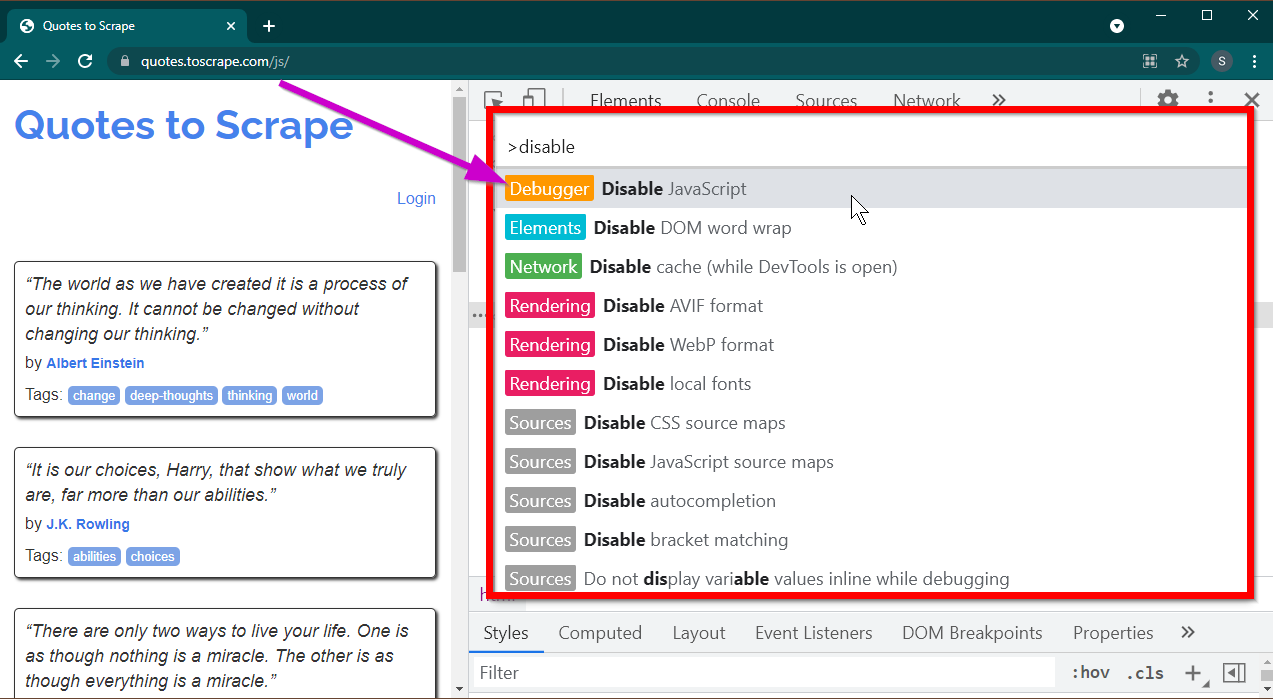
たくさんのコマンドが表示されます。 disable入力し始めると、コマンドがフィルターされてDisable JavaScript表示されます。 JavaScript無効にするには、このオプションを選択します。
Ctrl+RまたはF5を押してこのページをリロードします。ページがリロードされます。
これが動的サイトの場合、多くのコンテンツが表示されなくなります。
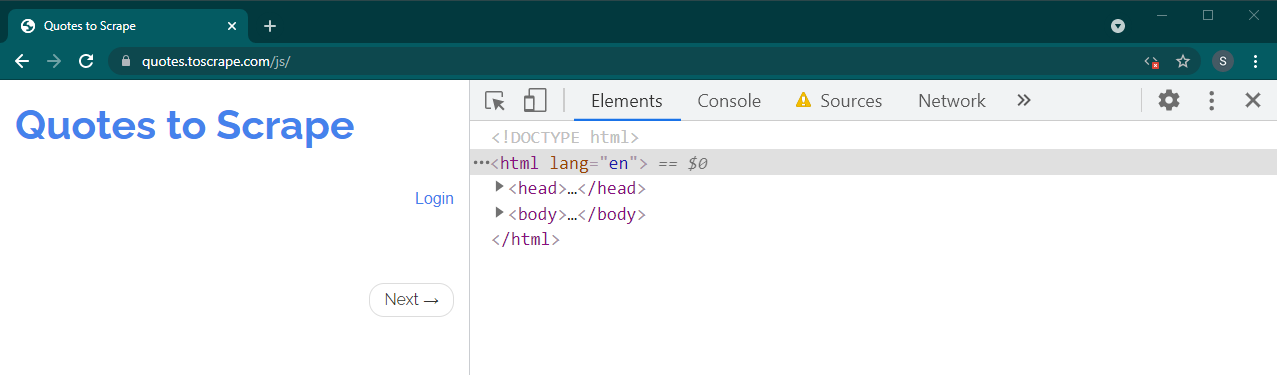
場合によっては、サイトにデータは表示されますが、基本機能に戻ります。たとえば、このサイトには無限スクロールがあります。 JavaScript が無効になっている場合は、通常のページネーションが表示されます。
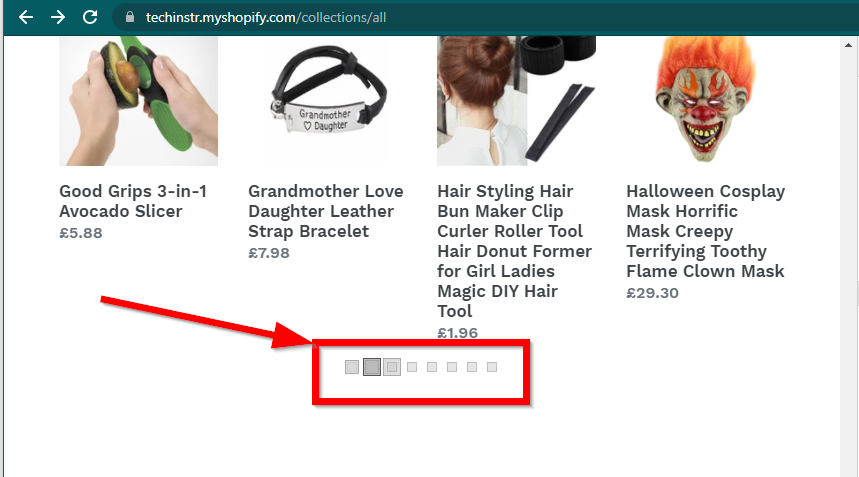 | 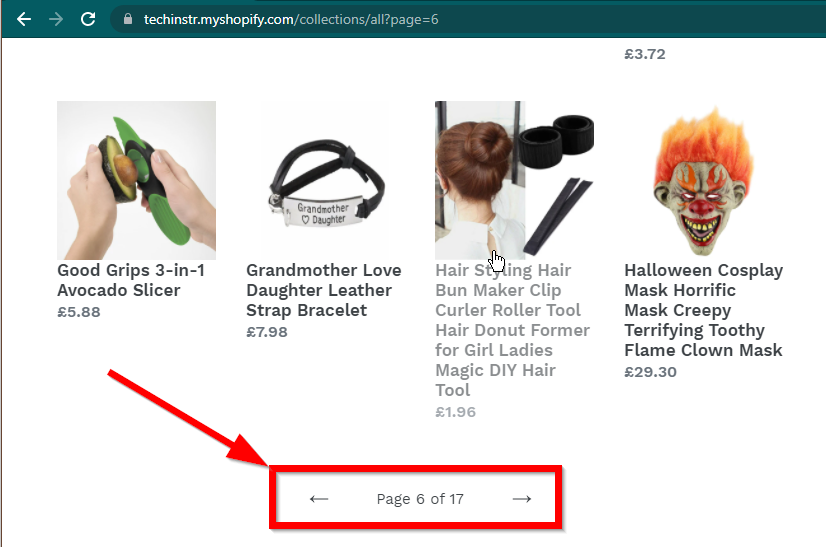 |
|---|---|
| JavaScriptが有効です | JavaScriptが無効です |
次に答える必要がある質問は、BeautifulSoup の機能です。
JavaScriptをレンダリングできますか?簡単に言うと「ノー」です。
解析やレンダリングなどの言葉を理解することが重要です。解析とは、単に Python オブジェクトの文字列表現を実際のオブジェクトに変換することです。
では、レンダリングとは何でしょうか?レンダリングは基本的に、HTML、JavaScript、CSS、および画像をブラウザーに表示されるものに解釈することです。
Beautiful Soup は、HTML ファイルからデータを抽出するための Python ライブラリです。これには、HTML 文字列を BeautifulSoup オブジェクトに解析することが含まれます。解析するには、まず文字列としての HTML が必要です。動的 Web サイトには、HTML 内にデータが直接含まれていません。これは、BeautifulSoup が動的 Web サイトでは動作できないことを意味します。
Selenium ライブラリは、Chrome や Firefox などのブラウザでの Web サイトの読み込みとレンダリングを自動化できます。 Selenium は HTML からのデータの抽出をサポートしていますが、完全な HTML を抽出し、代わりに Beautiful Soup を使用してデータを抽出することもできます。
まずは Selenium を使用して Python で動的 Web スクレイピングを始めてみましょう。
Selenium をインストールするには、次の 3 つのものをインストールする必要があります。
選択したブラウザ (すでにお持ちのブラウザ):
ブラウザのドライバー:
Python Selenium パッケージ:
pip install seleniumconda-forgeチャネルからインストールできます。 conda install -c conda-forge selenium ブラウザを起動し、ページをロードし、ブラウザを閉じるための Python スクリプトの基本的なスケルトンは次のとおりです。
from selenium . webdriver import Chrome
from webdriver_manager . chrome import ChromeDriverManager
driver = Chrome ( ChromeDriverManager (). install ())
driver . get ( 'https://quotes.toscrape.com/js/' )
#
# Code to read data from HTML here
#
driver . quit ()ブラウザにページをロードできるようになったので、特定の要素の抽出を見てみましょう。要素を抽出するには、Selenium と Beautiful Soup の 2 つの方法があります。
この例の目的は、author 要素を見つけることです。
Chrome でサイトhttps://quotes.toscrape.com/js/をロードし、作成者名を右クリックして、「検査」をクリックします。これにより、次のように author 要素が強調表示された開発者ツールがロードされます。
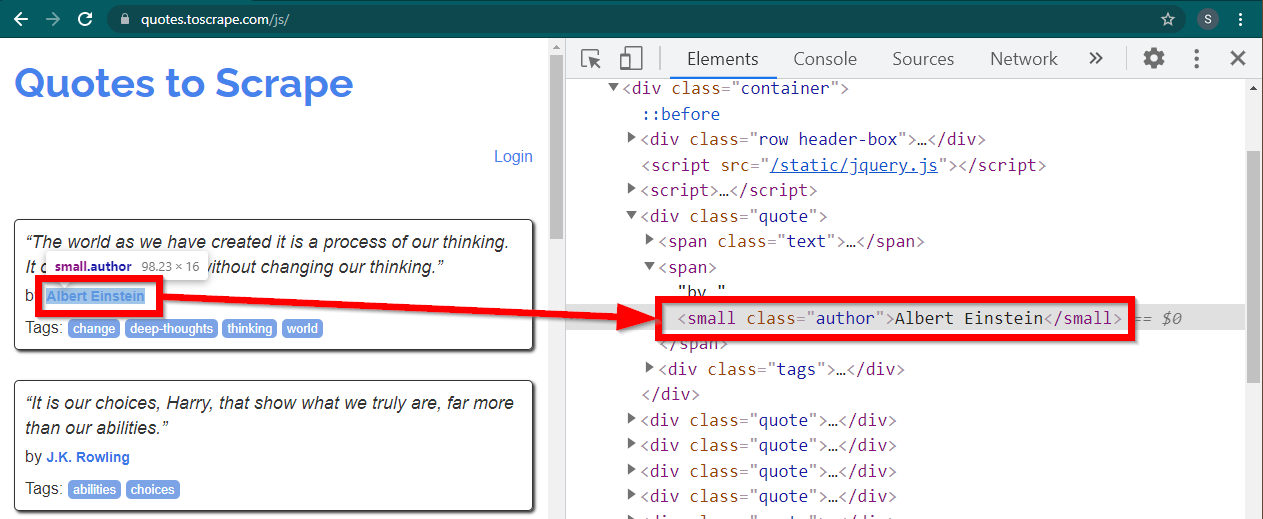
これは、 class属性がauthorに設定されたsmall要素です。
< small class =" author " > Albert Einstein </ small >Selenium では、さまざまなメソッドで HTML 要素を見つけることができます。これらのメソッドはドライバー オブジェクトの一部です。ここで役立つ方法のいくつかは次のとおりです。
element = driver . find_element ( By . CLASS_NAME , "author" )
element = driver . find_element ( By . TAG_NAME , "small" )他にもいくつかの方法があり、他のシナリオに役立つ可能性があります。これらの方法は次のとおりです。
element = driver . find_element ( By . ID , "abc" )
element = driver . find_element ( By . LINK_TEXT , "abc" )
element = driver . find_element ( By . XPATH , "//abc" )
element = driver . find_element ( By . CSS_SELECTOR , ".abc" )おそらく最も便利なメソッドはfind_element(By.CSS_SELECTOR)とfind_element(By.XPATH)です。これら 2 つの方法のいずれでも、ほとんどのシナリオを選択できるはずです。
最初の作成者を印刷できるようにコードを変更しましょう。
from selenium . webdriver import Chrome
from selenium . webdriver . common . by import By
from webdriver_manager . chrome import ChromeDriverManager
driver = Chrome ( ChromeDriverManager (). install ())
driver . get ( 'https://quotes.toscrape.com/js/' )
element = driver . find_element ( By . CLASS_NAME , "author" )
print ( element . text )
driver . quit ()すべての著者を印刷したい場合はどうすればよいでしょうか?
すべてのfind_elementメソッドには、対応するfind_elementsがあります。複数化に注意してください。すべての作成者を検索するには、次の 1 行を変更するだけです。
elements = driver . find_elements ( By . CLASS_NAME , "author" )これにより、要素のリストが返されます。ループを実行するだけで、すべての著者を出力できます。
for element in elements :
print ( element . text )注: 完全なコードは selenium_example.py コード ファイルにあります。
ただし、すでに BeautifulSoup に慣れている場合は、Beautiful Soup オブジェクトを作成できます。
最初の例で見たように、Beautiful Soup オブジェクトには HTML が必要です。 Web スクレイピング静的サイトの場合、 requestsライブラリを使用して HTML を取得できます。次のステップでは、この HTML 文字列を解析して BeautifulSoup オブジェクトを作成します。
response = requests . get ( "https://quotes.toscrape.com/" )
bs = BeautifulSoup ( response . text , "lxml" )BeautifulSoup を使って動的な Web サイトをスクレイピングする方法を見てみましょう。
次の部分は前の例から変更されていません。
from selenium . webdriver import Chrome
from webdriver_manager . chrome import ChromeDriverManager
from bs4 import BeautifulSoup
driver = Chrome ( ChromeDriverManager (). install ())
driver . get ( 'https://quotes.toscrape.com/js/' )ページのレンダリングされた HTML は、属性page_sourceで入手できます。
soup = BeautifulSoup ( driver . page_source , "lxml" )スープ オブジェクトが利用可能になると、すべての Beautiful Soup メソッドを通常どおり使用できるようになります。
author_element = soup . find ( "small" , class_ = "author" )
print ( author_element . text )注: 完全なソース コードは selenium_bs4.py にあります。
Browserスクリプトの準備が完了すると、スクリプトの実行中にブラウザを表示する必要はありません。ブラウザを非表示にしても、スクリプトは正常に実行されます。ブラウザのこの動作は、ヘッドレス ブラウザとも呼ばれます。
ブラウザをヘッドレスにするには、 ChromeOptionsをインポートします。他のブラウザの場合は、独自の Options クラスが利用可能です。
from selenium . webdriver import ChromeOptionsここで、このクラスのオブジェクトを作成し、 headless属性を True に設定します。
options = ChromeOptions ()
options . headless = True最後に、Chrome インスタンスの作成中にこのオブジェクトを送信します。
driver = Chrome ( ChromeDriverManager (). install (), options = options )これで、スクリプトを実行すると、ブラウザは表示されなくなります。完全な実装については、selenium_bs4_headless.py ファイルを参照してください。
ブラウザのロードには負荷がかかり、実際には必要のない CPU、RAM、帯域幅が占有されます。 Web サイトがスクレイピングされる場合、重要なのはデータです。これらすべての CSS、画像、レンダリングは実際には必要ありません。
Python を使用して動的 Web ページをスクレイピングする最も速くて効率的な方法は、データが存在する実際の場所を特定することです。
このデータは次の 2 つの場所にあります。
<script>タグに埋め込まれた JSON 形式のメイン ページ自体いくつかの例を見てみましょう。
Chrome で https://quotes.toscrape.com/js を開きます。ページがロードされたら、Ctrl+U を押してソースを表示します。 Ctrl+F を押して検索ボックスを表示し、Albert を検索します。
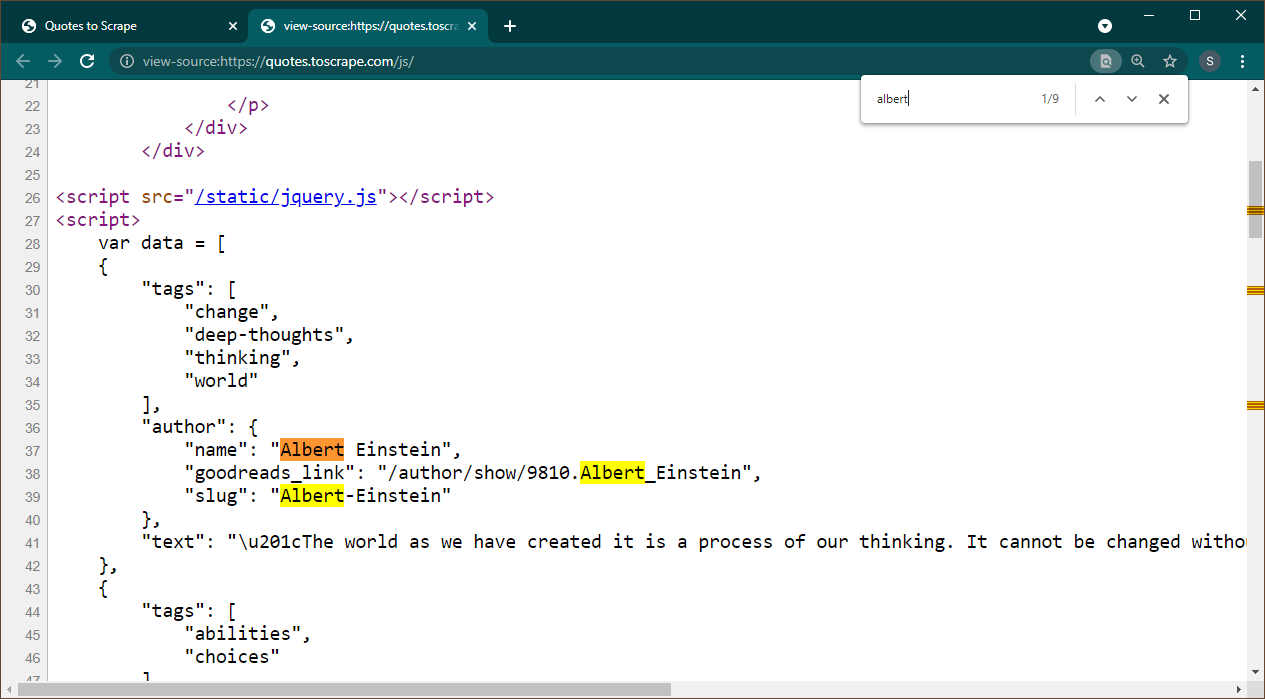
データがページ上に JSON オブジェクトとして埋め込まれていることがすぐにわかります。また、これは、このデータが変数dataに割り当てられるスクリプトの一部であることに注意してください。
この場合、Requests ライブラリを使用してページを取得し、Beautiful Soup を使用してページを解析してスクリプト要素を取得できます。
response = requests . get ( 'https://quotes.toscrape.com/js/' )
soup = BeautifulSoup ( response . text , "lxml" )複数の<script>要素があることに注意してください。必要なデータが含まれているものにはsrc属性がありません。これを使って script 要素を抽出してみましょう。
script_tag = soup . find ( "script" , src = None )このスクリプトには、対象のデータとは別に他の JavaScript コードが含まれていることに注意してください。このため、正規表現を使用してこのデータを抽出します。
import re
pattern = "var data =(.+?); n "
raw_data = re . findall ( pattern , script_tag . string , re . S )データ変数は 1 つの項目を含むリストです。これで、JSON ライブラリを使用して、この文字列データを Python オブジェクトに変換できるようになりました。
if raw_data :
data = json . loads ( raw_data [ 0 ])
print ( data )出力は Python オブジェクトになります。
[{ 'tags' : [ 'change' , 'deep-thoughts' , 'thinking' , 'world' ], 'author' : { 'name' : 'Albert Einstein' , 'goodreads_link' : '/author/show/9810.Albert_Einstein' , 'slug' : 'Albert-Einstein' }, 'text' : '“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”' }, { 'tags' : [ 'abilities' , 'choices' ], 'author' : { 'name' : 'J.K. Rowling' , .....................このリストは、必要に応じていかなる形式にも変換できません。また、各項目には著者ページへのリンクが含まれていることに注意してください。これは、これらのリンクを読み取り、スパイダーを作成してこれらすべてのページからデータを取得できることを意味します。
この完全なコードは data_in_same_page.py に含まれています。
Web スクレイピング動的サイトは、まったく異なるパスをたどることができます。場合によっては、データが完全に別のページに読み込まれることがあります。その一例がLibrivoxです。
開発者ツールを開き、[ネットワーク] タブに移動して、XHR でフィルターします。このリンクを開くか、任意の書籍を検索してください。データが JSON に埋め込まれた HTML であることがわかります。
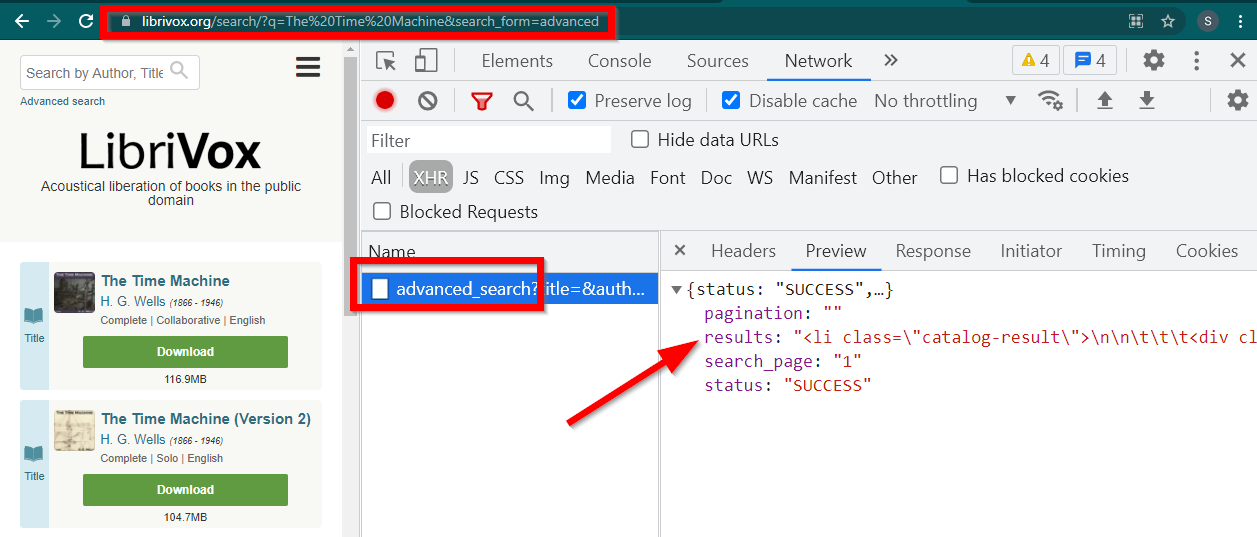
いくつか注意してください:
ブラウザで表示されるURLはhttps://librivox.org/search/?q=...です。
データはhttps://librivox.org/advanced_search?....にあります。
ヘッダーを見ると、advanced_search ページに特別なヘッダーX-Requested-With: XMLHttpRequestが送信されていることがわかります。
このデータを抽出するスニペットは次のとおりです。
headers = {
'X-Requested-With' : 'XMLHttpRequest'
}
url = 'https://librivox.org/advanced_search?title=&author=&reader=&keywords=&genre_id=0&status=all&project_type=either&recorded_language=&sort_order=alpha&search_page=1&search_form=advanced&q=The%20Time%20Machine'
response = requests . get ( url , headers = headers )
data = response . json ()
soup = BeautifulSoup ( data [ 'results' ], 'lxml' )
book_titles = soup . select ( 'h3 > a' )
for item in book_titles :
print ( item . text )完全なコードは、librivox.py ファイルに含まれています。


