feathr
v1.0.0

Feathr は、LinkedIn の本番環境で長年にわたって広く使用されているデータおよび AI エンジニアリング プラットフォームで、2022 年にオープンソース化されました。現在、LF AI & Data Foundation のプロジェクトです。
オープン ソーシング Feathr と Feathr on Azure に関する発表、および LF AI & Data Foundation からの発表をお読みください。
Feather を使用すると、次のことが可能になります。
Feathr は AI モデリングで特に役立ちます。AI モデリングでは、特徴変換を自動的に計算してトレーニング データに結合し、ポイントインタイムの正しいセマンティクスを使用してデータ漏洩を回避し、本番環境でオンラインで使用するための特徴の具体化とデプロイをサポートします。
Feathr を試す最も簡単な方法は、Feathr サンドボックスを使用することです。これは、Feathr のほとんどの機能を備えた自己完結型コンテナであり、5 分で生産性が向上します。これを使用するには、次のコマンドを実行するだけです。
# 80: Feathr UI, 8888: Jupyter, 7080: Interpret
docker run -it --rm -p 8888:8888 -p 8081:80 -p 7080:7080 -e GRANT_SUDO=yes feathrfeaturestore/feathr-sandbox:releases-v1.0.0また、Feathr クイックスタート jupyter ノートブックを表示できます。
http://localhost:8888/lab/workspaces/auto-w/tree/local_quickstart_notebook.ipynbノートブックを実行すると、すべての機能が UI に登録され、次の場所から Feather UI にアクセスできます。
http://localhost:8081Feathr クライアントを Python 環境にインストールする場合は、これを使用します。
pip install feathrまたは、GitHub から最新のコードを使用します。
pip install git+https://github.com/feathr-ai/feathr.git#subdirectory=feathr_projectFeathr には、Databricks および Azure Synapse とのネイティブ統合があります。
Feathr ARM デプロイ ガイドに従って、Azure で Feathr を実行します。これにより、Azure Resource Manager テンプレートを使用して自動デプロイをすぐに開始できるようになります。
すべてを手動でセットアップする場合は、Azure で Feathr を実行するための Feathr CLI デプロイ ガイドを確認してください。これにより、何が起こっているかを理解し、一度に 1 つのリソースを設定できます。
| 名前 | 説明 | プラットフォーム |
|---|---|---|
| ニューヨーク市のタクシーデモ | ニューヨーク市のタクシー料金予測サンプル データを使用してフィーチャを定義、具体化、登録する方法を紹介するクイックスタート ノートブック。 | Azure Synapse、Databricks、ローカル Spark |
| Databricks クイックスタート NYC タクシー デモ | ニューヨーク市のタクシー料金予測サンプル データを含むクイックスタート Databricks ノートブック。 | データブリック |
| 機能の埋め込み | 事前トレーニング済みの Transformer モデルとホテル レビュー サンプル データを使用して機能埋め込みを定義および使用する方法を示す Feathr UDF の例。 | データブリック |
| 不正行為検出のデモ | ユーザー アカウントやトランザクション データなどの複数のデータ ソースを使用して、Feature Store をデモンストレーションする例。 | Azure Synapse、Databricks、ローカル Spark |
| 製品推奨デモ | 製品推奨シナリオを含む Feather フィーチャー ストアのサンプル ノートブック | Azure Synapse、Databricks、ローカル Spark |
その他の例については、「Feather の完全な機能」を参照してください。以下に厳選したものをいくつか示します。
Feathr は直感的な UI を提供するため、利用可能なすべての機能とそれに対応する系統を検索して探索できます。
Feathr UI を使用して、フィーチャの検索、データ ソースの特定、フィーチャ リネージの追跡、アクセス制御の管理を行うことができます。ここで最新のライブデモをチェックして、Feathr UI で何ができるかを確認してください。ログインを求められたら、次のいずれかのアカウントを使用します。
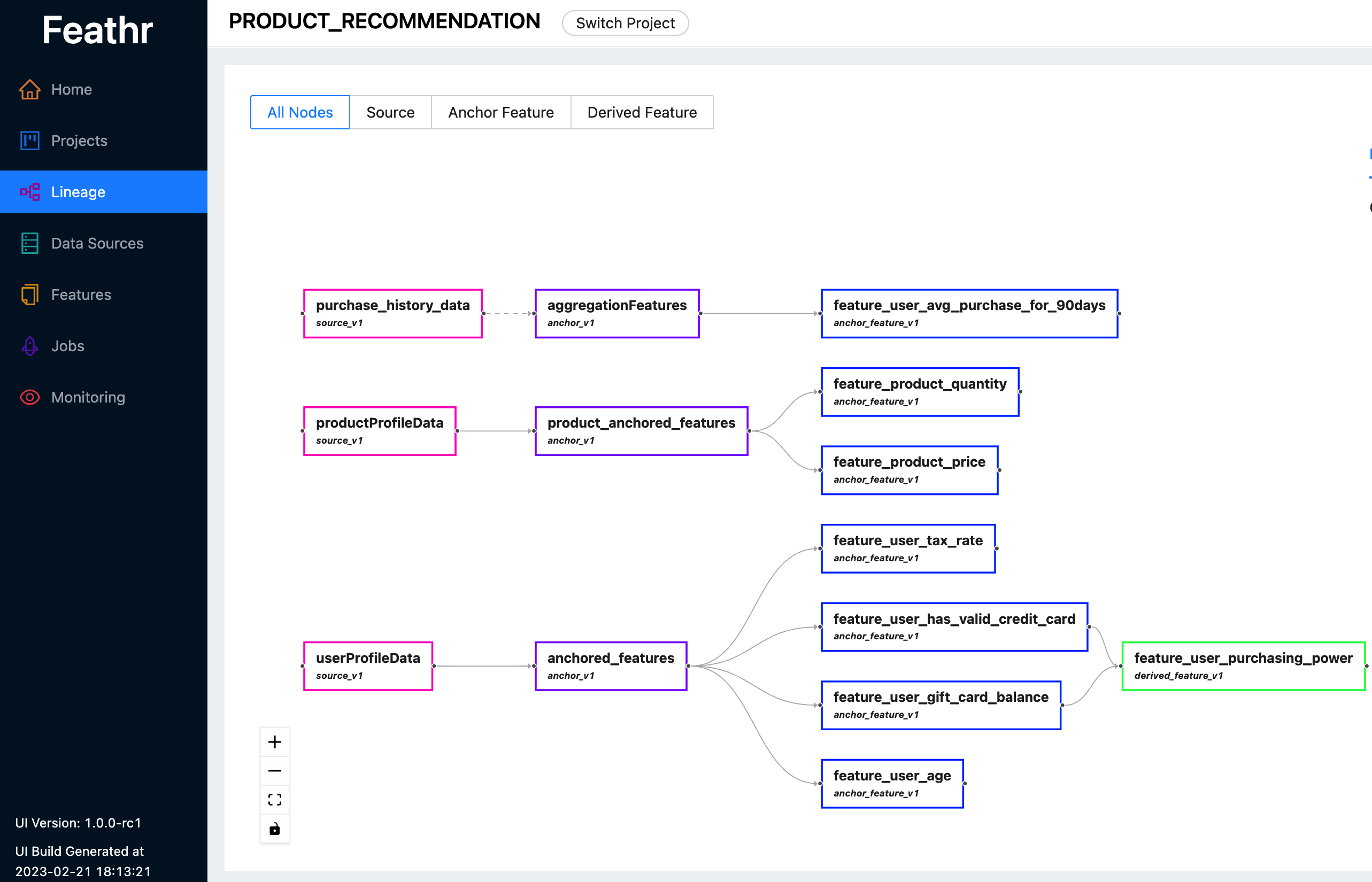
Feathr UI とその背後にあるレジストリの詳細については、「Feathr 機能レジストリ」を参照してください。
Feathr には、ネイティブ PySpark と Spark SQL の統合を備えた高度にカスタマイズ可能な UDF があり、データ サイエンティストの学習曲線を短縮します。
def add_new_dropoff_and_fare_amount_column ( df : DataFrame ):
df = df . withColumn ( "f_day_of_week" , dayofweek ( "lpep_dropoff_datetime" ))
df = df . withColumn ( "fare_amount_cents" , df . fare_amount . cast ( 'double' ) * 100 )
return df
batch_source = HdfsSource ( name = "nycTaxiBatchSource" ,
path = "abfss://[email protected]/demo_data/green_tripdata_2020-04.csv" ,
preprocessing = add_new_dropoff_and_fare_amount_column ,
event_timestamp_column = "new_lpep_dropoff_datetime" ,
timestamp_format = "yyyy-MM-dd HH:mm:ss" ) agg_features = [ Feature ( name = "f_location_avg_fare" ,
key = location_id , # Query/join key of the feature(group)
feature_type = FLOAT ,
transform = WindowAggTransformation ( # Window Aggregation transformation
agg_expr = "cast_float(fare_amount)" ,
agg_func = "AVG" , # Apply average aggregation over the window
window = "90d" )), # Over a 90-day window
]
agg_anchor = FeatureAnchor ( name = "aggregationFeatures" ,
source = batch_source ,
features = agg_features ) # Compute a new feature(a.k.a. derived feature) on top of an existing feature
derived_feature = DerivedFeature ( name = "f_trip_time_distance" ,
feature_type = FLOAT ,
key = trip_key ,
input_features = [ f_trip_distance , f_trip_time_duration ],
transform = "f_trip_distance * f_trip_time_duration" )
# Another example to compute embedding similarity
user_embedding = Feature ( name = "user_embedding" , feature_type = DENSE_VECTOR , key = user_key )
item_embedding = Feature ( name = "item_embedding" , feature_type = DENSE_VECTOR , key = item_key )
user_item_similarity = DerivedFeature ( name = "user_item_similarity" ,
feature_type = FLOAT ,
key = [ user_key , item_key ],
input_features = [ user_embedding , item_embedding ],
transform = "cosine_similarity(user_embedding, item_embedding)" )詳細については、「ストリーミング ソース インジェスト ガイド」を参照してください。
詳細については、「Feather のポイントインタイムの正確性とポイントインタイムの結合」を参照してください。
クイック スタート Jupyter Notebook に従って試してください。付属のクイック スタート ガイドにも、ノートブックに関するもう少し詳しい説明が含まれています。
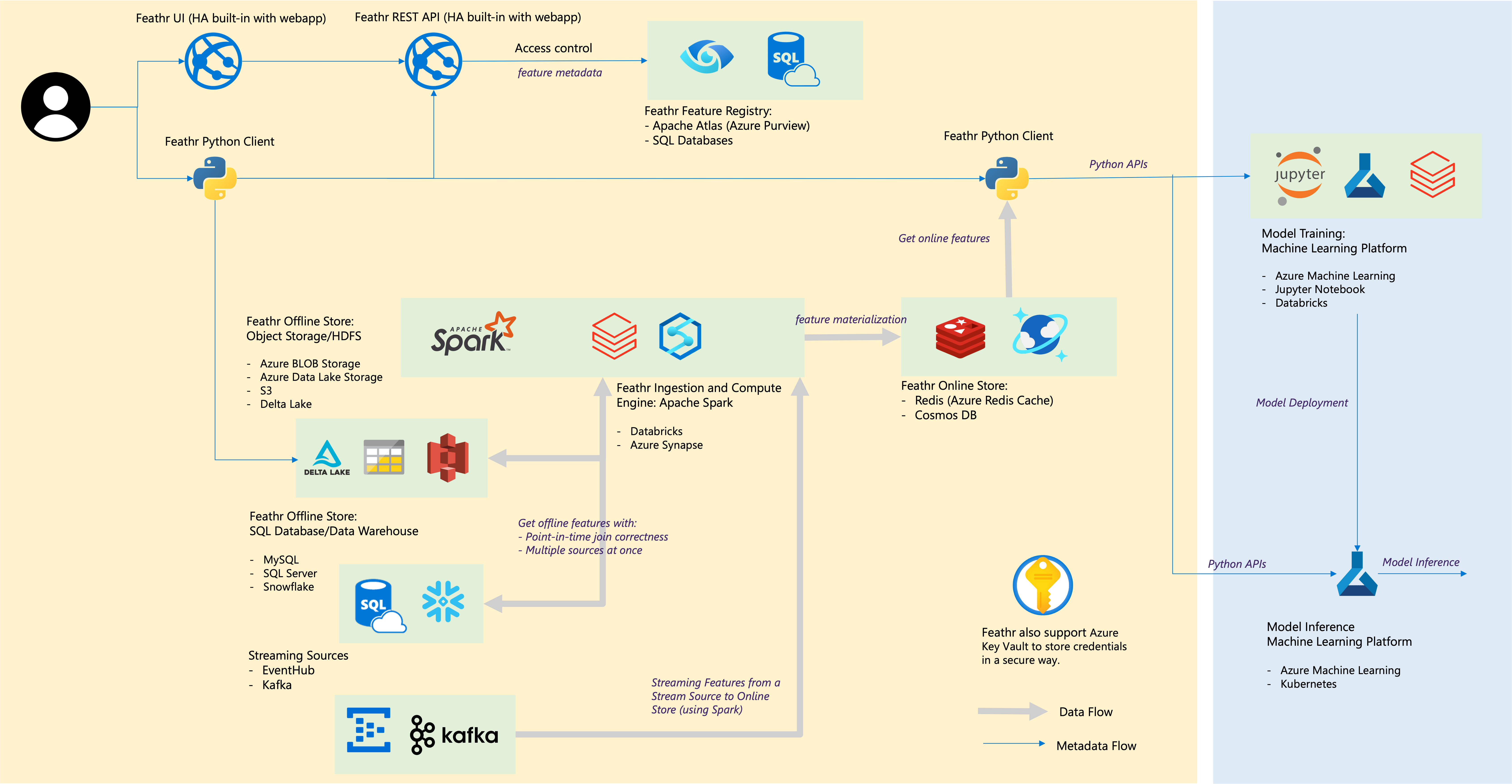
| 羽根成分 | クラウド統合 |
|---|---|
| オフライン ストア – オブジェクト ストア | Azure Blob Storage、Azure ADLS Gen2、AWS S3 |
| オフライン ストア – SQL | Azure SQL DB、Azure Synapse 専用 SQL プール、VM 内の Azure SQL、Snowflake |
| ストリーミングソース | カフカ、イベントハブ |
| オンラインストア | Redis、Azure Cosmos DB |
| 機能レジストリとガバナンス | Azure Purview、Azure SQL Server などの ANSI SQL |
| コンピューティング エンジン | Azure Synapse Spark プール、Databricks |
| 機械学習プラットフォーム | Azure Machine Learning、Jupyter Notebook、Databricks Notebook |
| ファイル形式 | 寄木細工、ORC、Avro、JSON、デルタ湖、CSV |
| 資格 | Azure Key Vault |
コミュニティのために構築し、コミュニティによって構築します。コミュニティガイドラインを確認してください。
Slack チャンネルに参加して質問やディスカッションを行ってください (または招待リンクをクリックしてください)。


