minimind
V1

中国語 | 英語
このオープンソース プロジェクトは、最短 3 時間でゼロから開始することを目指しています。サイズがわずか 2688 メートルの小型言語モデルであるMiniMind をトレーニングできます。
MiniMindは非常に軽量で、最小バージョンのサイズは GPT3 とほぼ同じです。
MiniMind は、大規模モデルのミニマリスト構造、データセットのクリーニングと前処理、教師あり事前トレーニング (Pretrain)、教師あり命令微調整 (SFT)、低ランク適応 (LoRA) 微調整、報酬なしの強化学習の直接選好調整 ( DPO) フルステージ コードには、共有ハイブリッド エキスパート (MoE) のスパース モデルの拡張、つまりビジュアル マルチモーダル VLM の拡張も含まれています。
これはオープン ソース モデルの実装であるだけでなく、大規模言語モデル (LLM) を始めるためのチュートリアルでもあります。
私たちは、このプロジェクトが研究者に入門的な例を提供し、誰もがすぐに始められるようにし、LLM の分野でさらなる探索と革新を生み出すことを願っています。
誤解を避けるために、「最大 3 時間」とは、独自のハードウェア構成のマシンが必要であることを意味します。具体的な仕様の詳細は以下で説明します。

ModelScope オンライン テスト Bilibili ビデオ リンク
GPT、LLaMA、GLM などの大規模言語モデル (LLM) の分野では、その効果は驚くべきものですが、100 億もの膨大なモデルパラメータと個人のデバイスのメモリでは学習には程遠く、推論は難しいです。 ほとんどの人は、Lora などのプログラムを使用して大きなモデルを微調整し、新しい命令を学習するだけでは満足しません。これは、ニュートンに 21 世紀のスマートフォンで遊ぶように教えるのとほぼ同じです。しかし、これは、ゲームの謎を学ぶことには程遠いです。物理学そのもの。 さらに、有料サブスクリプションコースを販売するマーケティングアカウントには抜け穴がたくさんあり、中途半端な知識でAIを説明するチュートリアルが含まれているため、LLMの質の高いコンテンツを理解することがさらに困難になり、学習者の大きな妨げとなっています。
したがって、このプロジェクトの目標は、LLM を始めるための敷居を限りなく下げ、非常に軽量な言語モデルを最初から直接トレーニングすることです。
ヒント
(2024-9-17現在) MiniMindシリーズは3モデルの事前トレーニングを完了しており、スムーズな会話機能を実現するために必要な最小容量はわずか26M(0.02B)です。
| モデル(サイズ) | トークナイザーの長さ | 推論占有率 | リリース | 主観評価(/100) |
|---|---|---|---|---|
| minimind-v1-small (26M) | 6400 | 0.5GB | 2024.08.28 | 50分 |
| minimind-v1-moe (4×26M) | 6400 | 1.0GB | 2024.09.17 | 55分 |
| ミニマインド-v1 (108M) | 6400 | 1.0GB | 2024.09.01 | 60分 |
分析は、Torch 2.1.2、CUDA 12.2、および Flash Attendant 2 を搭載した 2x RTX 3090 GPU で実行されました。
プロジェクトには以下が含まれます:
transformers 、 accelerate 、 trl 、 peftなどの一般的なフレームワークと互換性があります。このオープンソース プロジェクトが、LLM 初心者がすぐに始めるのに役立つことを願っています。
MiniMind のマルチモーダル機能を拡張 - ビジョン
詳細を表示するには、ツイン プロジェクト minimind-v に移動してください。
09-27 事前トレーニング データセットの前処理方法を更新しました。テキストの整合性を確保するために、前処理は放棄され、.bin トレーニングに変換されました (トレーニング速度は若干犠牲になります)。
事前学習処理後の現在のファイルの名前は、pretrain_data.csv です。
いくつかの冗長なコードを削除しました。
minimind-v1-moe モデルを更新する
曖昧さを防ぐために、mistral_tokenizer は単語の分割として使用されなくなり、すべてのカスタム minimind_tokenizer が単語の分割として使用されます。
minimind_tokenizer を使用し、事前トレーニング ラウンド 3 + SFT ラウンド 10 を使用して更新された minimind-v1 (108M) モデル。より完全にトレーニングされ、より強力なパフォーマンスが得られます。
プロジェクトは ModelScope 作成スペースに展開されており、次の Web サイトで体験できます。
?ModelScope オンライン体験?
これは私の個人的なソフトウェアおよびハードウェア環境構成です。ご自身の判断で変更してください。
CPU: Intel(R) Core(TM) i9-10980XE CPU @ 3.00GHz
内存:128 GB
显卡:NVIDIA GeForce RTX 3090(24GB) * 2
环境:python 3.9 + Torch 2.1.2 + DDP单机多卡训练ミニマインド (ハグフェイス)
MiniMind (モデルスコープ)
# step 1
git clone https://huggingface.co/jingyaogong/minimind-v1 # step 2
python 2-eval.pyまたは、streamlit を開始して Web チャット インターフェイスを開始します
「注」には Python>=3.10、
pip install streamlit==1.27.2インストールが必要です
# or step 3, use streamlit
streamlit run fast_inference.py0.プロジェクトコードのクローンを作成する
git clone https://github.com/jingyaogong/minimind.git
cd minimind1. 環境のインストール
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple # 测试torch是否可用cuda
import torch
print(torch.cuda.is_available())
利用できない場合は、torch_stable にアクセスして whl ファイルをダウンロードし、ご自身でインストールしてください。参考リンク
2. 自分自身をトレーニングする必要がある場合
2.1 データ セットのダウンロード アドレスをダウンロードし、 ./datasetディレクトリに配置します。
2.2 python data_process.pyデータセットを処理します。たとえば、事前学習データは事前にトークンエンコードされ、sft データセットは qa から csv ファイルに抽出されます。
2.3 ./model/LMConfig.pyのモデルパラメータ設定を調整する
ここでは、dim、n_layers、use_moe パラメータを調整するだけで済みます。これらはそれぞれ
(512+8)または(768+16)で、minimind-v1-smallとminimind-v1に対応します。
2.4 python 1-pretrain.py事前トレーニングを実行し、事前トレーニングの出力重みとしてpretrain_*.pth取得します。
2.5 python 3-full_sft.py命令微調整を実行し、命令微調整の出力重みとしてfull_sft_*.pth
2.6 python 4-lora_sft.py lora の微調整を実行します (必須ではありません)
2.7 python 5-dpo_train.py DPO 人間の好みの強化学習アライメントを実行します (オプション)
3. モデル推論の効果をテストする
*.pthファイルが./out/ディレクトリに配置されていることを確認してください。*.pth重みファイルを使用することもできます。 minimind/out
├── multi_chat
│ ├── full_sft_512.pth
│ ├── full_sft_512_moe.pth
│ └── full_sft_768.pth
├── single_chat
│ ├── full_sft_512.pth
│ ├── full_sft_512_moe.pth
│ └── full_sft_768.pth
├── pretrain_768.pth
├── pretrain_512_moe.pth
├── pretrain_512.pth
python 0-eval_pretrain.py事前トレーニングされたモデルのソリティア効果をテストしますpython 2-eval.pyモデルの対話効果をテストします
?「ヒント」事前トレーニングとフルパラメータ微調整 pretrain と full_sft は両方ともマルチカード アクセラレーションをサポートします。
デバイスにグラフィック カードが 1 つしか搭載されていないと仮定すると、ネイティブ Python を使用してトレーニングを開始できます。
python 1-pretrain.py
# and
python 3-full_sft.pyデバイスに N (N>1) 個のグラフィック カードが搭載されていると仮定します。
スタンドアロンNカードスタートアップトレーニング(DDP)
torchrun --nproc_per_node N 1-pretrain.py
# and
torchrun --nproc_per_node N 3-full_sft.pyスタンドアロンNカードスタートアップトレーニング(DeepSpeed)
deepspeed --master_port 29500 --num_gpus=N 1-pretrain.py
# and
deepspeed --master_port 29500 --num_gpus=N 3-full_sft.pywandb でトレーニング プロセスを記録できるようにする (オプション)
torchrun --nproc_per_node N 1-pretrain.py --use_wandb
# and
python 1-pretrain.py --use_wandb --use_wandbパラメーターを追加すると、トレーニング プロセスを記録でき、トレーニング完了後にトレーニング プロセスを wandb Web サイトで確認できます。 wandb_projectパラメーターとwandb_run_nameパラメーターを変更することで、プロジェクト名と実行名を指定できます。
? トークナイザー: nlp のトークナイザーは、「辞書」を通じて自然言語から単語を 0、1、36 などの数字にマッピングします。数字は単語のページ番号を表すことがわかります。 「辞書」。 LLM トークナイザーを構築するには 2 つの方法があります。1 つはトークナイザーをトレーニングするための単語リストを自分で構築する方法で、コードはtrain_tokenizer.pyあります。もう 1 つはオープン ソース モデルによってトレーニングされたトークナイザーを選択する方法です。もちろん、「辞書」として Xinhua Dictionary または Oxford Dictionary を直接選択することもできます。利点は、トークン変換の圧縮率が非常に高いことですが、欠点は、語彙リストが長すぎて、数十万の語彙フレーズが含まれていることです。独自のトレーニング済み単語セグメンターを使用することもできます。利点は、単語リストを自由に制御できることです。欠点は、圧縮率が十分ではなく、すべての珍しい単語をカバーするのが難しいことです。 もちろん、「辞書」の選択は重要です。LLM の出力は基本的に、SoftMax から辞書に渡された N 単語の多分類問題であり、その後「辞書」を通じて自然言語にデコードされます。 LLM は非常に小さいため、モデルがトップヘビーになる (LLM 全体に対する単語埋め込み層パラメーターの比率が高すぎる) ことを避けるために、語彙の長さは比較的小さくなるように選択する必要があります。 01 Wanwu、Qianwen、chatglm、mistral、Llama3 などの強力なオープン ソース モデルには、次のトークナイザー語彙長があります。
| トークナイザーモデル | 語彙のサイズ | ソース |
|---|---|---|
| yiトークナイザー | 64,000 | 01 すべて(中国) |
| qwen2トークナイザー | 151,643 | アリババクラウド(中国) |
| glmトークナイザー | 151,329 | 知恵AI(中国) |
| ミストラルトークナイザー | 32,000 | ミストラルAI(フランス) |
| ラマ3トークナイザー | 128,000 | メタ (米国) |
| ミニマインドトークナイザー | 6,400 | カスタマイズ |
更新 2024 年 9 月 17 日: 過去のバージョンのあいまいさを防止し、ボリュームを制御するために、すべての minimind モデルは minimind_tokenizer 単語セグメンテーションを使用し、すべての mistral_tokenizer バージョンは廃止されました。
minimind_tokenizer の長さは非常に短いですが、エンコードとデコードの効率は、qwen2 や glm などの中国語対応のトークナイザーよりも劣ります。 ただし、minimind モデルは、全体のパラメーターを軽量に保ち、コーディング層とトップヘビーである計算層の比率の不均衡を避けるために、単語セグメンターとして独自のトレーニング済み minimind_tokenizer を選択しました。これは、minimind の語彙サイズがわずかであるためです。 6400。 さらに、minimind は実際のテストでも珍しい単語の解読に失敗したことはなく、結果も良好です。 カスタム単語リストは 6400 単語に圧縮されるため、LLM のパラメーターの合計サイズは 26M と小さくなります。
?[事前トレーニング データ]: Seq-Monkey ユニバーサル テキスト データ セット/Seq-Monkey Baidu ネットワーク ディスクは、さまざまなパブリック ソース データ (Web ページ、百科事典、ブログ、オープン ソース コード、書籍など) からコンパイルおよびクリーンアップされます。 。データの包括性、規模、信頼性、高品質を確保するために、統一された JSONL 形式に編成され、厳格な審査と重複排除が行われています。合計量は約 100 億トークンで、中国語の大規模言語モデルの事前トレーニングに適しています。
オプション 2: SkyPile-150B データセットの公的にアクセス可能な部分には、約 2 億 3,300 万の一意の Web ページが含まれており、各 Web ページには平均 1,000 文字以上の漢字が含まれています。データセットには、約 1,500 億のトークンと 620 GB のプレーン テキスト データが含まれています。急いでいる場合は、SkyPile-150B の jsonl ダウンロードの一部のみを選択して (そして ./data_process.py にテキスト トークナイザー用の *.csv ファイルを生成して)、事前トレーニング プロセスをすばやく実行することもできます。 。
./dataset/ディレクトリにダウンロードします
| MiniMind トレーニング データセット | ダウンロードアドレス |
|---|---|
| 【トークナイザートレーニングセット】 | ハグフェイス / 百度ネットディスク |
| 【事前学習データ】 | Seq-Monkey公式/Baiduネットワークディスク/HuggingFace |
| 【SFTデータ】 | 江蘇大規模モデルSFTデータセット |
| 【DPOデータ】 | 抱きしめる顔 |
MiniMind-Dense (Llama3.1 と同じ) は、Transformer の Decoder-Only 構造を使用します。 GPT-3 との違いは次のとおりです。
MiniMind-MoE モデルの構造は、Llama3 と Deepseek-V2 の MixFFN ハイブリッド エキスパート モジュールに基づいています。
MiniMind の全体的な構造は同じですが、RoPE 計算、推論関数、FFN 層のコードに若干の調整が加えられています。 その構造は次のとおりです (再描画バージョン)。
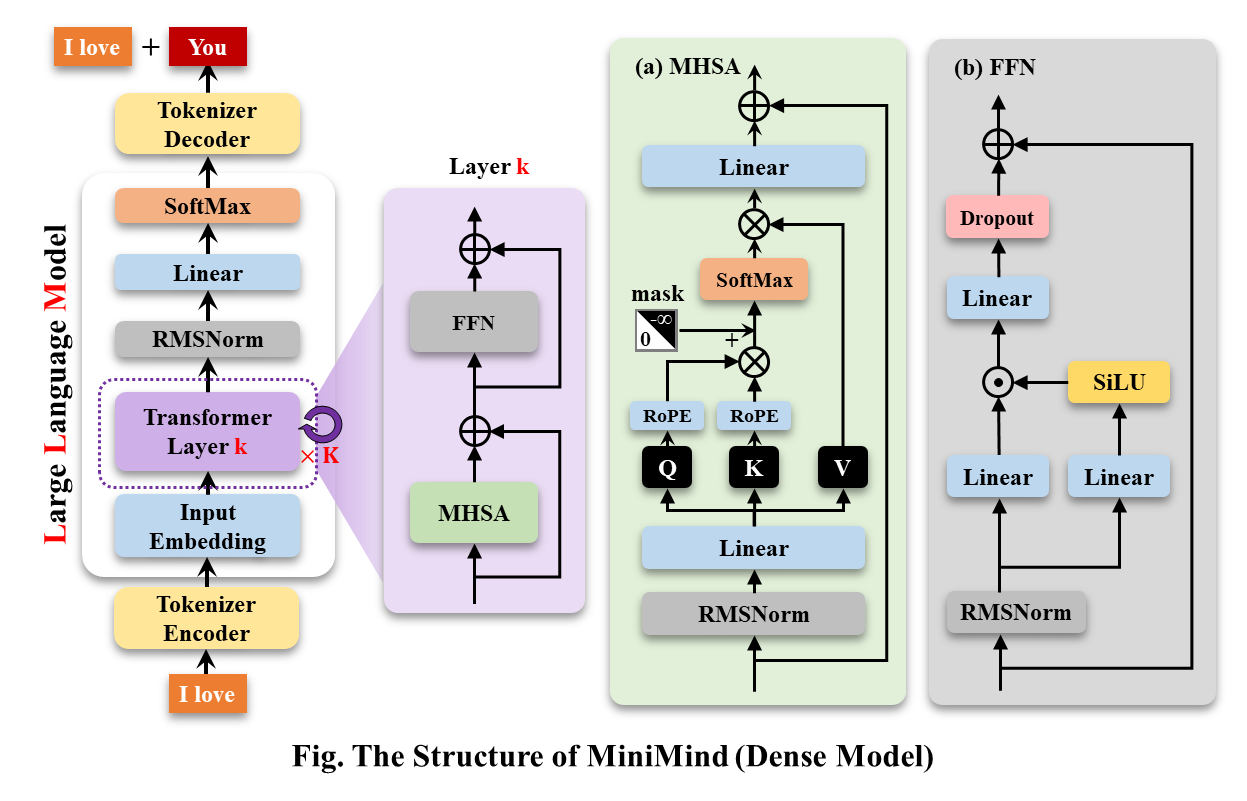
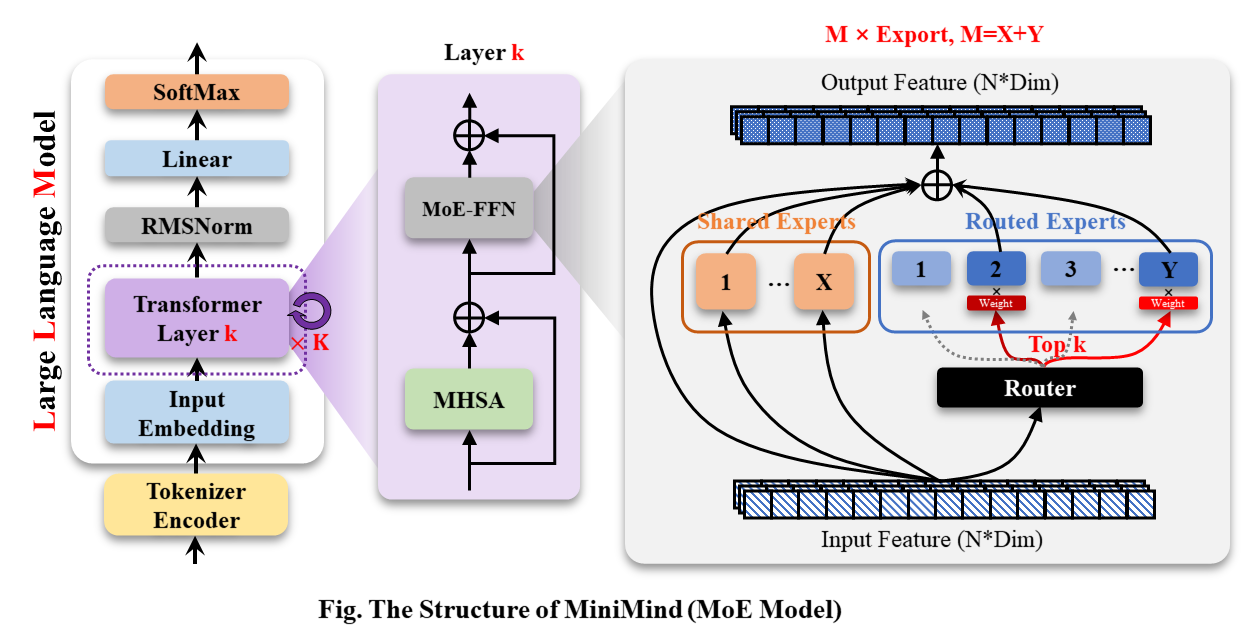
モデル構成を変更するには、./model/LMConfig.py を参照してください。現在 minimind によってトレーニングされているモデルのバージョンを以下の表に示します。
| モデル名 | パラメータ | len_vocab | n_layers | d_model | kv_heads | q_heads | 共有+ルート | トップK |
|---|---|---|---|---|---|---|---|---|
| ミニマインド-v1-small | 26M | 6400 | 8 | 512 | 8 | 16 | - | - |
| ミニマインドv1-moe | 4×26M | 6400 | 8 | 512 | 8 | 16 | 2+4 | 2 |
| ミニマインドv1 | 108M | 6400 | 16 | 768 | 8 | 16 | - | - |
| モデル名 | パラメータ | len_vocab | バッチサイズ | pretrain_time | sft_single_time | sft_multi_time |
|---|---|---|---|---|---|---|
| minimind-v1-small | 26M | 6400 | 64 | ≈2 時間 (1 エポック) | ≈2 時間 (1 エポック) | ≈0.5 時間 (1 エポック) |
| ミニマインドv1-moe | 4×26M | 6400 | 40 | ≈6 時間 (1 エポック) | ≈5 時間 (1 エポック) | ≈1 時間 (1 エポック) |
| ミニマインドv1 | 108M | 6400 | 16 | ≈6 時間 (1 エポック) | ≈4 時間 (1 エポック) | ≈1 時間 (1 エポック) |
事前トレーニング (テキストからテキスト) :
事前学習の学習率は 1e-4 から 1e-5 までの動的学習率に設定され、事前学習エポック数は 5 に設定されます。
torchrun --nproc_per_node 2 1-pretrain.py単一ダイアログの微調整:
推論中に RoPE の線形差を調整すると、長さを 1024 または 2048 以上に推定すると便利です。学習率は 1e-5 から 1e-6 までの動的学習率に設定されており、微調整エポック数は 6 です。
# 3-full_sft.py中设置数据集为sft_data_single.csv
torchrun --nproc_per_node 2 3-full_sft.pyマルチダイアログの微調整:
学習率は 1e-5 から 1e-6 までの動的学習率に設定されており、微調整エポック数は 5 です。
# 3-full_sft.py中设置数据集为sft_data.csv
torchrun --nproc_per_node 2 3-full_sft.pyヒューマン フィードバック強化学習 (RLHF) - 直接優先最適化 (DPO) :
可動型トリプレット (q、choose、reject) データ セット、学習率 le-5、半精度 fp16、合計 1 エポック、所要時間は 1 時間です。
python 5-dpo_train.py ? LLM のパラメータ構成に関しては、詳細な研究と実験を行った非常に興味深い論文 MobileLLM があります。スケーリング則には、小さなモデルにおける独自のルールがあります。 Transformer パラメータをスケーリングするパラメータは、ほぼ独占的にd_modelとn_layersに依存します。
d_model ↑+ n_layers ↓->ハンプティ・ダンプティd_model ↓+ n_layers ↑-> スリムで背が高い2020年にスケーリング則を提案した論文では、トレーニングデータの量、パラメータの量、トレーニングの反復回数がパフォーマンスを決定する重要な要素であり、モデルアーキテクチャの影響はほぼ無視できると考えられています。 ただし、この法則は小型モデルには完全には適用されないようです。 MobileLLM は、アーキテクチャの幅よりも深さが重要であると提案しています。「深くて狭い」「細い」モデルは、「広くて浅い」モデルよりも抽象的な概念を学習できます。 たとえば、モデルパラメータが 125M または 350M に固定されている場合、常識推論などの 8 つのベンチマーク テストでは、30 ~ 42 層の「狭い」モデルの方が、12 層程度の「短くて太い」モデルよりも大幅に優れたパフォーマンスを示します。 、質疑応答、読解も同様の傾向があります。 これは実際、非常に興味深い発見です。なぜなら、これまで、約 100M の小規模モデルのアーキテクチャを設計する場合、12 層を超える層を積層しようとした人はほとんどいなかったからです。 これは、トレーニング プロセス中にd_modelとn_layersの間でモデル パラメーターを調整する MiniMind の実験的に観察された効果と一致しています。 ただし、「深くて狭い」の「狭い」にも次元制限があり、d_model<512 の場合、単語埋め込みの次元崩壊の欠点は、追加されたレイヤーでは単語埋め込みによって引き起こされる d_head 不足の欠点を補うことができません。固定q_head内。 d_model > 1536 の場合、レイヤーの増加は d_model よりも優先されるようで、より「コスト効率の高い」パラメーター -> エフェクトのゲインをもたらすことができます。 したがって、MiniMind は、「非常に小さいボリューム <-> より良い効果」のバランスを得るために、小さいモデルの d_model=512、n_layers=8 を設定します。 d_model=768、n_layers=16 に設定すると、効果から大きなメリットが得られます。これは、小さなモデルのスケーリング則の変化曲線により一致します。
参考までに、GPT3 のパラメータ設定を次の表に示します。
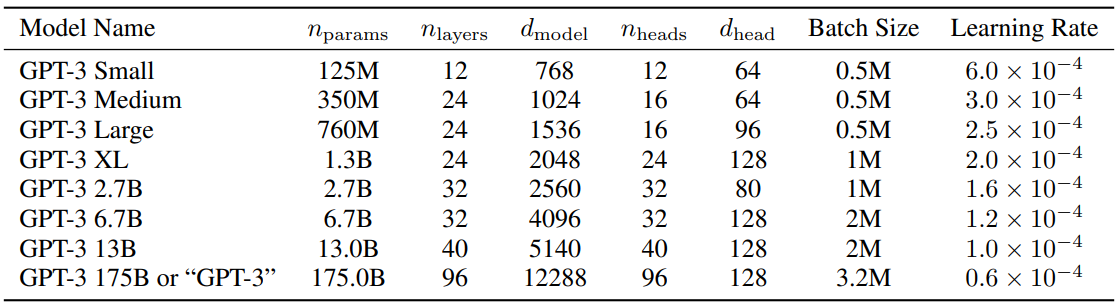
?百度ネットディスク
| モデル名 | パラメータ | 構成 | 事前訓練モデル | シングル_sft_model | multi_sft_model | rl_model |
|---|---|---|---|---|---|---|
| minimind-v1-small | 26M | d_model=512 n_layers=8 | pretrain_512.pth | single_chat/full_sft_512.pth | multi_chat/full_sft_512.pth | rl_512.pth |
| ミニマインドv1-moe | 4×26M | d_model=512 n_layers=8 | pretrain_512_moe.pth | single_chat/full_sft_512_moe.pth | multi_chat/full_sft_512_moe.pth | - |
| ミニマインドv1 | 108M | d_model=768 n_layers=16 | pretrain_768.pth | single_chat/full_sft_768.pth | multi_chat/full_sft_768.pth | rl_768.pth |
ヒント
「シングルラウンドダイアログ full_sft」と「DPO 強化学習アライメント」に基づいて minimind モデルの比較をテストします。
モデル ファイル Baidu Netdisk。rl_ rl_<dim>.pthは、「DPO 強化学習アライメント」後の minimind モデルの重みです。
[Q]: 你叫什么名字?
[ft_768]: 我是一款人工智能语言模型,可以回答您的问题和提供帮助。您有什么需要我帮忙的吗?
[rl_768]: 我是一款基于人工智能技术的自然语言处理系统,主要用于处理和生成人类语言的任务。我可以帮助用户进行文本处理、语音识别、文本生成等任务,同时也可以帮助用户进行智能聊天、翻译、翻译等多种应用。如果您需要更多关于该项目的信息,请告诉我。
[ft_512]: 我很高兴能够帮助你。你有什么其他问题需要我帮忙解答吗?
[rl_512]: 我是一款基于自然语言处理技术的聊天机器人,能够理解和回复用户的问题和指令,并进行相应的回复和回复。我被训练为能够与人类进行交互和回答各种问题和任务。请问有什么需要吗?
[Q]: 你是谁?
[ft_768]: 我是一个人工智能语言模型,没有个人身份和身份。我只是根据输入的指令和文本信息生成响应。
[rl_768]: 我是一个计算机程序,没有个人身份或身份。我被设计来回答各种问题和提供帮助,包括回答问题、提供建议、进行实验、提供信息等等。我被广泛应用于各种领域,例如自然语言处理、计算机视觉、人工智能等等。如果您需要更多的帮助或信息,请随时与我联系。我会尽我所能来帮助您的工作和生活。
[ft_512]: 我是一个大型语言模型,可以回答各种各样的问题,包括科学、历史、文化和技术方面的问题。您有什么需要我回答的问题吗?
[rl_512]: 我是一个计算机程序,没有具体的身世和人物。如果您可以告诉我您想知道的具体信息,我会尽力回答您的问题。
[Q]: 中国有哪些比较好的大学?
[ft_768]: 中国有很多著名的大学,其中包括北京大学、上海交通大学、复兴中医药学院、浙江大学等。这些大学在不同的领域都有着自己的标志性建筑和研究方向,值得一提的是,它们在中国的顶尖教育资源中享有很高的声誉。
[rl_768]: 中国的大学有很多,具体情况还要根据你的需求来决定。如果你需要更详细的信息,建议可以去咨询一下你所在城市的大学排名和政策法规,从而选择一个合适的大学。同时,你可以在网上查阅相关信息,或者去咨询一些大学相关机构,如中国人民大学、中国人民大学等,以获得更为详细和专业的指导和建议。
[ft_512]: 中国有很多优秀的大学,比如麻省理工学院、北京大学、上海大学等等。这些大学在中国教育事业的发展和成就都非常突出。
[rl_512]: 中国教育局、中国大学、中国大陆大学和中国大陆大学均有优秀的教育体裁,但各地教育水平和专业要求都可能存在差异。中国教育局的学历要求、教学方法、师资力量等因素都各具特点,而大学的学历要求也各有千秋。中国大陆大学生的学历要求也各有不同,需要根据自己的实际情况进行选择。如果您对中国大陆大学生的专业要求有更具体需求,建议您可以通过互联网、国内外的各类机构和机构进行比较和交流。同时,您也可以向身边的人或朋友、老师、家长等人士寻求帮助和建议。希望以上回答对您有帮助。
[Q]: 你知道光速是多少吗?
[ft_768]: 光速是一个物理常数,表示光在真空中传播的速度,大约是每秒299792458米。光速是物理学中最基本的物理常数之一,也是相对论的重要基础之一。
[rl_768]: 当然知道,光速是光在真空中传播的速度,通常用c来表示。它是宇宙物理学中非常重要的理论之一。在物理学中,光速被认为是宇宙中最重要的速度之一。它代表着光在真空中传播的速度,这也是许多重要公式和公式的基础。
[ft_512]: 光速是光在真空中传播的速度,约为每秒299,792,458米。它是几乎所有的物理学概念,也是宇宙中最神秘和最重要的物理概念之一。
[rl_512]: 光速是光在真空中传播的速度,是自然界中不可逆转的速度。光源是由光的原子、分子、固体和光的组成,其速度约为每秒平方。光的速度是每秒约1个英亞或光年,这个数字是根据相对论、量子力学和引力理论来计算的。光速是相对的概念之一,它代表着我们对自然界中任何事件的理解和解释。
ヒント
以下のテストは 2024 年 9 月 17 日に完了しました。特別な必要がない限り、この日以降にリリースされた新しいモデルはテストに含まれません。 シングルラウンド ダイアログ full_sft に基づいて minimind モデルをテストします (マルチラウンド微調整と強化学習微調整なし)。
[A] minimind-v1-small(0.02B)
[B] minimind-v1-moe(0.1B)
[C] minimind-v1(0.1B)
[D] ベビーラマ2中国語(0.2B)
[E] chatlm-mini-chinese(0.2B)
[Q]: 你知道长江吗?
[A]: 是的,长江是中国最长的河流,全长超过3300千米。
[B]: 长江是中国最长的河流,总长度约为6300公里。它发源于青藏高原的青海湖,流经青海、四川、甘肃、宁夏、内蒙古、陕西和山西。长江流域是中国最大的农业区之一,也是中国的文化和经济中心。
[C]: 是的,长江是中国最长的河流之一,也是世界第三大河流。长江发源于青藏高原,流经11个省份,最终注入东海。长江流域是中国最大的河流流域之一,拥有着丰富的自然资源和文化遗产,如长江大桥、长江海洋博物馆、长江古城等。
[D]: 同时也知道,中国是世界上最长的城市之一,拥有超过3400万人口。
[E]: 是的,长江是中国最长的河流,也是世界上最长的河流之一。它发源于青藏高原,流经九个省区,最终注入东海。长江流域的气候温和,四季分明,是中国重要的农业和工业基地。长江流域的水产资源丰富,是中国的重要渔业资源之一。
[Q]: 第一颗人造卫星是哪个国家发射的?
[A]: 第一颗人造卫星是斯普特尼克1号。
[B]: 第一颗人造卫星是俄罗斯的国际卫星,于1957年发射。
[C]: 第一颗人造卫星是苏联发射的,它是由苏联于1957年10月发射的。
[D]: 这颗名为“阿姆斯特朗”的卫星,于1961年11月20日发射,是第一个成功将人类送入太空的卫星。
[E]: 第一颗人造卫星是苏联于1957年4月4日发射的,它是由苏联宇航员尤里·加加林(Yuri Gagarin)和苏联工程师罗尔德·谢尔盖耶夫(Roald Skohley)共同发射的。在发射过程中,加加林和谢尔盖耶夫使用了一个名为“斯普特尼克1号”的小型卫星,它的直径为4.3米,重量为1,051公斤。这枚卫星被称为“斯普特尼克1号”,是苏联太空竞赛中的一个里程碑,也是人类历史上第一次在太空中进行太空行走。
[Q]: 你知道泰山在哪里吗?
[A]: 泰山位于中国东部地区,是中国五岳之一。
[B]: 泰山位于山东省泰安市泰安市。泰安市是中国五岳之一,也是世界文化遗产和中国历史文化名山之一。泰安市有许多著名的景点,如五岳之一、玉皇顶、南天门、玉皇阁等。
[C]: 泰山位于中国山东省泰安市,是中国五岳之一。
[D]: 作为一个人工智能助手,我无法访问互联网,因此无法提供关于你所在位置的信息。不过,你可以通过搜索或搜索相关关键词来获取有关你所在位置的信息,或者查看相关新闻或网站来获取有关你所在位置的信息。
[E]: 泰山位于中国山东省泰安市境内,是中国五岳之一,也是中国文化和历史的重要象征之一。它是中国五岳之一,也是中国道教和佛教的发源地之一。泰山的海拔高度为1,545米,是中国五岳之一,也是中国最著名的旅游景点之一。它的历史可以追溯到公元前5世纪,是中国古代帝王祭祀的场所。泰山也是中国文化的重要组成部分,被誉为“五岳之首”,是中国文化的重要遗产之一。
[Q]: 世界上最高的山峰是什么?
[A]: 世界上最高的山峰是珠穆朗玛峰,位于尼泊尔和中国的边境上,海拔8848米。
[B]: 世界上最高的山峰是珠穆朗玛峰,位于喜马拉雅山脉,海拔8,848米。
[C]: 珠穆朗玛峰是世界上最高的山峰,海拔8848米。
[D]: 世界上最高的山峰是珠穆朗玛峰,位于喜马拉雅山脉,海拔8,848.86米(29,031.69英尺)。
[E]: 世界上最高的山峰是珠穆朗玛峰,也称为萨加玛塔,位于喜马拉雅山脉的尼泊尔和中国边境之间,海拔8,848.86米(29,031.69英尺)。它是世界上最著名的登山目标之一,吸引着来自世界各地的登山者前来挑战。珠穆朗玛峰的名字来自藏语,意思是“女神的额峰”,它是由两个不同的山峰组成的,其中一个是位于尼泊尔的珠穆朗玛峰,另一个则位于中国。它的高度是通过测量海拔高度来确定的,因为它是通过测量地球的平均高度来确定的。尽管珠穆朗玛峰是世界上最高的山峰,但它并不是地球上任何其他地方都能到达的。地球上的其他地方,如南美洲的安第斯山脉,也是世界上最高的山脉,但它并不是地球上最高的山峰。总之,珠穆朗玛峰是世界上最高的山峰,但它并不是地球上任何地方都能到达的。它是地球上最高的山脉,但它并不是地球上任何地方都能到达的。
[Q]: 万有引力是谁提出的?
[A]: 万有引力是由英国物理学家牛顿提出的。他认为,所有物体都会产生引力,这个引力是由物体的质量和距离决定的。这个理论揭示了质量和距离之间的关系,并证明了万有引力的本质。
[B]: 万有引力是由牛顿在1687年提出的。它是宇宙中一个基本的物理现象,它描述了物体之间的相互作用。这个力被称为万有引力,它在所有物体之间都存在,这种力与物体的质量和距离有关。万有引力是自然界中最基本的力量之一,它不仅影响着物体的运动和变化,还对宇宙的结构和演化产生着重要的影响。
[C]: 万有引力是英国物理学家艾萨克·牛顿在17世纪提出的。
[D]: 引力是宇宙中一种力量,它是由质量或能量所组成的。根据牛顿的万有引力定律,一个物体之间的引力大小与它的质量成正比,与它的质量成反比。因此,牛顿的万有引力定律表明,一个物体之间的引力大小与它的质量成正比,与它的质量成反比。这个定律在物理学、天文学和物理学中都有广泛的应用。
[E]: 万有引力是由英国物理学家艾萨克·牛顿于1687年提出的。他在1687年发表了一篇著名的论文,题为《自然哲学的数学原理》,其中提出了万有引力定律,指出任何两个物体之间都存在着一种引力,这种引力的大小与它们的质量成正比,与它们之间的距离的平方成反比。这个定律被称为万有引力定律,它描述了质量和距离之间的关系。它表明,两个物体之间的引力与它们的质量成正比,与它们之间的距离的平方成反比。这个定律对于解释宇宙中的许多现象和现象之间的相互作用非常重要,例如行星绕太阳运动、恒星之间的引力透镜效应等等。它也被广泛应用于天文学、物理学和工程学等领域,为我们理解宇宙的本质和演化提供了重要的理论基础。
[Q]: 你知道大熊猫的主要食物是什么吗?
[A]: 大熊猫的主要食物是竹子。它们通常吃竹子,每天需要吃掉大约30公斤的竹子。
[B]: 是的,大熊猫主要以竹子为食。它们每天需要吃掉大量的竹子来维持生命,每天需要吃掉40至80公斤的竹子。此外,它们也会吃一些其他的植物,如草、果实、坚果和小型哺乳动物。
[C]: 大熊猫主要以竹子为食,也会偶尔食用其他的植物和动物。此外,大熊猫也会吃一些野果、小动物和植物,但这些都不属于它们的主要食物来源。
[D]: 大熊猫的主要食物是竹子。
[E]: 大熊猫是一种以竹子为主要食物的植食动物,它们的肠道结构适合消化纤维素含量高的竹子,但也会吃一些其他植物,如草本植物和小型哺乳动物。大熊猫的肠道结构也适应了高纤维的竹子,这使得它们能够消化大量的纤维素,从而帮助它们在野外生存。大熊猫的肠道中还含有一种叫做“纤维素酶”的酶类物质,这种酶能够帮助大熊猫分解纤维素,从而帮助它们消化大量的水分和营养物质。此外,大熊猫的肠道还含有一种叫做“纤维素蛋白”的蛋白质,这种蛋白质能够帮助大熊猫维持体内的能量水平,从而帮助它们在野外生存。总的来说,大熊猫的主要食物是竹子,但它们也会吃一些其他植物,如草本植物和小型哺乳动物。
[Q]: 海水为什么是咸的?
[A]: 海水中含有许多盐分,这些盐分可以导致海水咸度的增加。海水中的盐分主要来自于海水中的盐分,这些盐分可以从海水中的盐分中获得。海水中的氧化物和盐分可以与海水中的盐分形成氢键,从而使海水咸度增加。
[B]: 海水是咸的,这是因为它含有大量的盐分,其中包括氯离子和氯离子。这些离子在海洋中形成了大量的盐,这些盐分被称为盐分。海水中含有许多溶解在水中的盐,这些盐分会随着海水的升高而逐渐蒸发,最终导致海水中盐分的蒸发。这些盐分在海水中被完全消耗,然后被排除在海水中。此外,海水中还含有许多其他的盐分,但这些盐分是不同的,因为它们在水中的浮起和下降过程是不同的。海水中的盐分是从海底的岩石中提取出来的,这些盐分在海水中可以被利用。总的来说,海水是咸的,这也是为什么海水中含有许多盐分和盐分的原因。
[C]: 海水含有许多溶解的盐类,其中最主要的是氯化钠。当水中加入盐时,盐的分子会与水分子发生反应,形成氢氧化钠,这是一种盐。
[D]: 因为水是许多生物的生存所必需的,它能够吸收和释放二氧化碳,释放氧气,维持大气中的水蒸气,以及维持水循环。水中的盐类和化学物质会释放出氧气,使地球上的生物呼吸。此外,水还具有许多其他功能,如保持水循环、维持水循环、调节气候和环境等。水是许多生物生存所必需的,它也是许多自然现象的重要基础。
[E]: 海水是咸的主要原因是因为其中含有大量的溶解盐类,其中最主要的是氯化钠(NaCl)。氯化钠是一种非常常见的盐类,它存在于地球上的大部分地区,包括海洋、湖泊、河流和地下水。当水从海洋中蒸发时,它会带走一部分盐分,使海水变得咸。此外,海中还含有其他溶解盐类的物质,如硫酸盐、硫酸镁、硫酸钙、硫酸镁盐、硫酸镁钾、硫酸镁钠、硫酸镁钙、硫酸镁镁钙、硫酸镁镁钙、硫酸镁镁钙、硫酸镁镁钠、硫酸镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁钙、硫酸镁镁镁镁钙、硫酸镁镁镁镁钙、硫酸镁镁镁镁钙、硫酸镁镁镁镁钙、硫酸镁镁镁镁钙、硫酸镁镁镁镁钙、硫酸镁镁镁镁镁钙、硫酸镁镁镁镁镁钙、硫酸镁镁镁镁镁钙、硫酸镁镁镁镁镁钙、硫酸镁镁镁镁镁镁钙、硫酸镁镁镁镁镁镁钙、硫酸镁镁镁镁镁镁钙、硫酸镁镁镁镁镁镁镁钙、硫酸镁镁镁镁
注記
?♂️ 上記のモデルの答えを GPT-4o に直接スローし、スコア付けに役立てます。
モデルA :
モデルB :
モデルC :
モデルD :
モデルE :
| モデル | C | E | B | あ | D |
|---|---|---|---|---|---|
| 分数 | 75 | 70 | 65 | 60 | 50 |
minimind シリーズ (ABC) の並べ替えは直感に従っており、minimind-v1 (0.1B) が最も高いスコアを持っています。常識的な質問に対する答えには、基本的に誤りや幻想がありません。
epochs数は 2 未満です。小さいモデルのリソースを解放するために事前に終了するのが面倒なので、0.1B はまだ完全ではありませんが、依然として最強のパフォーマンスを実現しています。実際、以前のデッドよりもさらに 1 レベル高いです。E モデルの答えは、いくつかの幻覚や捏造はありますが、肉眼では非常に良く見えます。しかし、GPT-4o と Deepseek の両方の評価では、「過度に長い情報、繰り返しの内容、幻想」が含まれているという点で一致しました。 実はこの手の評価はちょっと厳しめで、100語中10語が幻覚だったとしても簡単に低スコアが付けられてしまいます。 E モデルのトレーニング前のテキストの長さは長く、データセットははるかに大きいため、答えは完全であるように見えます。体積近似の場合、データの量と質の両方が重要です。
?♂️個人的主観評価:E>C>B≈A>D
? GPT-4o 評価: C>E>B>A>D
スケーリングの法則: モデルのパラメーターが大きくなり、トレーニング データが増えるほど、モデルのパフォーマンスは強化されます。
C-Eval 評価コード: ./eval_ceval.pyを参照してください。応答形式の修正の困難を避けるために、通常、小規模モデルの評価では、4 つの文字A 、 B 、 Cに対応するトークンの予測確率が直接決定されます。 、 D中で最も大きいものを答えて、標準的な答えで正答率を計算します。 minimind モデル自体は、トレーニングに大規模なデータ セットを使用しておらず、多肢選択式の質問に答えるための指示を微調整していません。評価結果は参考として使用できます。
たとえば、minimind-small の結果の詳細は次のようになります。
| タイプ | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 | 40 | 41 | 42 | 43 | 44 | 45 | 46 | 47 | 48 | 49 | 50 | 51 | 52 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| データ | 確率と統計 | 法 | 中学校生物学 | 高校の化学 | 高校物理 | 法律専門職 | 高校_中国語 | 高校の歴史 | 税理士 | 現代中国の歴史 | 中学校の物理 | 中学校の歴史 | 基本的な医学 | オペレーティング·システム | 論理 | 電気技師 | 公務員 | 中国語と文学 | 大学_プログラミング | 会計士 | 植物保護 | 中学校の化学 | 計測エンジニア | 獣医_医学 | マルクス主義 | 高度な数学 | 高校数学 | 経営管理 | 毛沢東思想 | 思想と道徳の修養 | 大学経済学 | professional_tour_guide | 環境影響評価エンジニア | コンピュータのアーキテクチャ | 都市と田舎のプランナー | 大学物理学 | 中学数学 | 高校政治 | 医師 | 大学化学 | 高校生物学 | 高校地理 | 中学校の政治 | 臨床医学 | コンピュータネットワーク | スポーツサイエンス | 芸術研究 | 教師_資格 | 離散数学 | 教育_科学 | 消防士 | 中学校地理 |
| タイプ | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 | 37 | 38 | 39 | 40 | 41 | 42 | 43 | 44 | 45 | 46 | 47 | 48 | 49 | 50 | 51 | 52 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| T/A | 3/18 | 5/24 | 4/21 | 7/19 | 5/19 | 2/23 | 4/19 | 6/20 | 10/49 | 4/23 | 4/19 | 4/22 | 1/19 | 3/19 | 4/22 | 7/37 | 11/47 | 5/23 | 10/37 | 9/49 | 7/22 | 4/20 | 3/24 | 6/23 | 5/19 | 5/19 | 4/18 | 8/33 | 8/24 | 5/19 | 17/55 | 10/29 | 7/31 | 6/21 | 11/46 | 5/19 | 3/19 | 4/19 | 13/49 | 3/24 | 5/19 | 4/19 | 6/21 | 6/22 | 2/19 | 2/19 | 14/33 | 12/44 | 6/16 | 7/29 | 9/31 | 1/12 |
| 正確さ | 16.67% | 20.83% | 19.05% | 36.84% | 26.32% | 8.70% | 21.05% | 30.00% | 20.41% | 17.39% | 21.05% | 18.18% | 5.26% | 15.79% | 18.18% | 18.92% | 23.40% | 21.74% | 27.03% | 18.37% | 31.82% | 20.00% | 12.50% | 26.09% | 26.32% | 26.32% | 22.22% | 24.24% | 33.33% | 26.32% | 30.91% | 34.48% | 22.58% | 28.57% | 23.91% | 26.32% | 15.79% | 21.05% | 26.53% | 12.50% | 26.32% | 21.05% | 28.57% | 27.27% | 10.53% | 10.53% | 42.42% | 27.27% | 37.50% | 24.14% | 29.03% | 8.33% |
总题数: 1346
总正确数: 316
总正确率: 23.48%
| カテゴリ | 正しい | 質問数 | 正確さ |
|---|---|---|---|
| ミニマインド-v1-small | 344 | 1346 | 25.56% |
| ミニマインドv1 | 351 | 1346 | 26.08% |
### 模型擅长的领域:
1. 高中的化学:正确率为42.11%,是最高的一个领域。说明模型在这方面的知识可能较为扎实。
2. 离散数学:正确率为37.50%,属于数学相关领域,表现较好。
3. 教育科学:正确率为37.93%,说明模型在教育相关问题上的表现也不错。
4. 基础医学:正确率为36.84%,在医学基础知识方面表现也比较好。
5. 操作系统:正确率为36.84%,说明模型在计算机操作系统方面的表现较为可靠。
### 模型不擅长的领域:
1. 法律相关:如法律专业(8.70%)和税务会计(20.41%),表现相对较差。
2. 中学和大学的物理:如中学物理(26.32%)和大学物理(21.05%),模型在物理相关的领域表现不佳。
3. 高中的政治、地理:如高中政治(15.79%)和高中地理(21.05%),模型在这些领域的正确率较低。
4. 计算机网络与体系结构:如计算机网络(21.05%)和计算机体系结构(9.52%),在这些计算机专业课程上的表现也不够好。
5. 环境影响评估工程师:正确率仅为12.90%,在环境科学领域的表现也不理想。
### 总结:
- 擅长领域:化学、数学(特别是离散数学)、教育科学、基础医学、计算机操作系统。
- 不擅长领域:法律、物理、政治、地理、计算机网络与体系结构、环境科学。
这表明模型在涉及逻辑推理、基础科学和一些工程技术领域的问题上表现较好,但在人文社科、环境科学以及某些特定专业领域(如法律和税务)上表现较弱。如果要提高模型的性能,可能需要加强它在人文社科、物理、法律、以及环境科学等方面的训练。
./export_model.py はモデルをトランスフォーマー形式にエクスポートし、huggingface にプッシュできます
MiniMind のハグフェイス コレクションのアドレス: MiniMind
my_openai_api.py は openai_api のチャット インターフェイスを完成させ、独自のモデルを fastgpt、OpenWebUI などのサードパーティ UI に簡単に接続できるようにします。
Huggingface からモデルの重量ファイルをダウンロードします。
minimind (root dir)
├─minimind
| ├── config.json
| ├── generation_config.json
| ├── LMConfig.py
| ├── model.py
| ├── pytorch_model.bin
| ├── special_tokens_map.json
| ├── tokenizer_config.json
| ├── tokenizer.json
チャットサーバーを起動する
python my_openai_api.pyテストサービスインターフェース
python chat_openai_api.pyAPI インターフェイスの例、openai API 形式と互換性あり
curl http://ip:port/v1/chat/completions
-H " Content-Type: application/json "
-d ' {
"model": "model-identifier",
"messages": [
{ "role": "user", "content": "世界上最高的山是什么?" }
],
"temperature": 0.7,
"max_tokens": -1,
"stream": true
} ' 
ヒント
MiniMindが役立つと思われる場合は、GitHub に記事を追加してください。長さは限られていますが、省略は避けられません。問題点を修正したり、PR 改善プロジェクトを提出したりしてください。プロジェクトを継続的に改善するための原動力となります。
注記
新しい MiniMind モデルをトレーニングしようとしている場合は、特定の下流タスクや垂直分野 (感情認識、医療、心理学など) でモデルの重みを共有することを歓迎します。 、財務、法的質疑応答など) MiniMind 新モデルバージョンまた、拡張トレーニング後の新しい MiniMind モデル バージョンにすることもできます (長いテキスト シーケンス、大容量 (0.1B 以上)、または大規模なデータ セットの探索など) はすべて独自のものとみなされ、これらの貢献はすべて価値があり、推奨されます。時間内に発見され、謝辞リストに整理されますよう、皆様のご支援に改めて感謝申し上げます。
@ipfgao : ?トレーニングステップ記録
@chuanzhubin : コードは 1 行ずつコメントします
@WangRongsheng : ?大規模なデータセットの前処理
@pengqianhan : ?簡潔なチュートリアル
@RyanSunn : ?推論プロセスの学習記録
このリポジトリは、Apache-2.0ライセンスの下でライセンスされています。


