LongNet
0.4.8

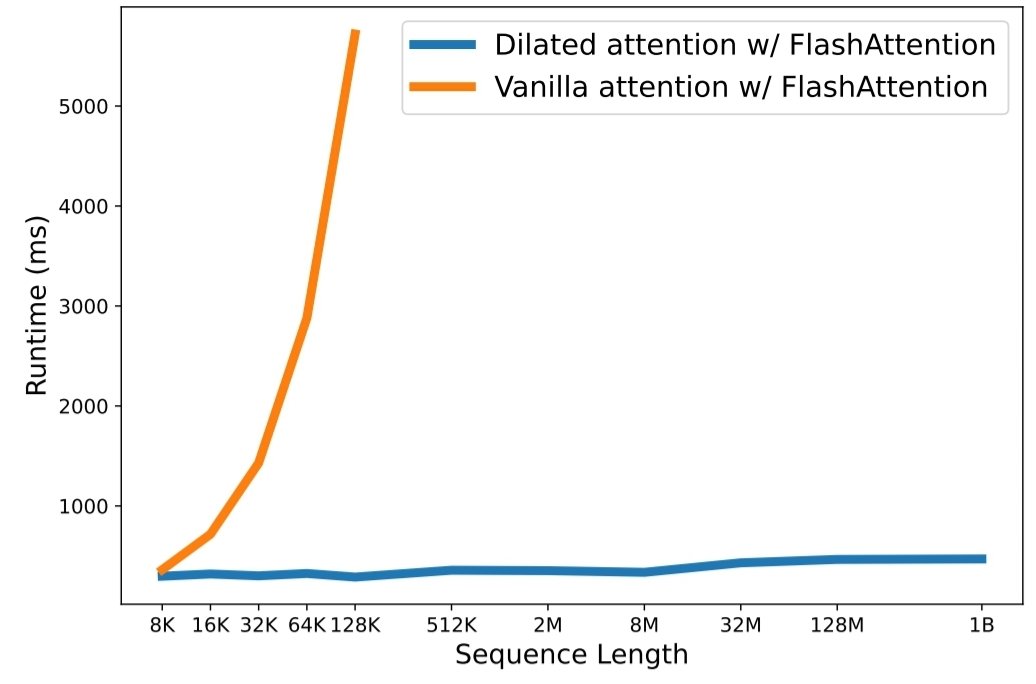
これは、Jiayu Ding、Shuming Ma、Li Dong、Xingxing Zhang、Shaohan Huang、Wenhui Wang、Furu Wei による論文「LongNet: Scaling Transformers to 1,000,000,000 Tokens」のオープンソース実装です。 LongNet は、より短いシーケンスのパフォーマンスを犠牲にすることなく、シーケンスの長さを最大 10 億トークン以上まで拡張するように設計された Transformer のバリアントです。
pip install longnetLongNet をインストールしたら、次のようにDilatedAttentionクラスを使用できます。
import torch
from long_net import DilatedAttention
# model config
dim = 512
heads = 8
dilation_rate = 2
segment_size = 64
# input data
batch_size = 32
seq_len = 8192
# create model and data
model = DilatedAttention ( dim , heads , dilation_rate , segment_size , qk_norm = True )
x = torch . randn (( batch_size , seq_len , dim ))
output = model ( x )
print ( output )
LongNetTransformerLayernorm、SWIGLU、および並列変換ブロックを使用したフィードフォワードを備えた拡張変換ブロックを備えた完全にトレーニング可能な変換モデル
import torch
from long_net . model import LongNetTransformer
longnet = LongNetTransformer (
num_tokens = 20000 ,
dim = 512 ,
depth = 6 ,
dim_head = 64 ,
heads = 8 ,
ff_mult = 4 ,
)
tokens = torch . randint ( 0 , 20000 , ( 1 , 512 ))
logits = longnet ( tokens )
print ( logits )
python3 train.py実行します。 シーケンスの長さのスケーリングは、大規模な言語モデルの時代における重大なボトルネックになっています。ただし、既存の方法は計算の複雑さまたはモデルの表現力に問題があり、シーケンスの最大長が制限されています。この論文では、短いシーケンスのパフォーマンスを犠牲にすることなく、シーケンス長を 10 億トークン以上に拡張できる Transformer のバリアントである LongNet を紹介します。具体的には、距離が伸びるにつれて注意のフィールドを指数関数的に拡大する拡張型注意を提案しています。
LongNet には次のような大きな利点があります。
実験結果は、LongNet が長いシーケンスのモデリングと一般的な言語タスクの両方で優れたパフォーマンスを発揮することを示しています。彼らの研究は、非常に長いシーケンスをモデル化するための新しい可能性を切り開きます。たとえば、コーパス全体、さらにはインターネット全体をシーケンスとして扱うことができます。
@inproceedings { ding2023longnet ,
title = { LongNet: Scaling Transformers to 1,000,000,000 Tokens } ,
author = { Ding, Jiayu and Ma, Shuming and Dong, Li and Zhang, Xingxing and Huang, Shaohan and Wang, Wenhui and Wei, Furu } ,
booktitle = { Proceedings of the 10th International Conference on Learning Representations } ,
year = { 2023 }
}

