igel
v1.0.0
コードを書かずにモデルのトレーニング/適合、テスト、使用を可能にする素晴らしい機械学習ツール
注記
また、人々のリクエストに基づいて、igel 用の GUI デスクトップ アプリの開発にも取り組んでいます。 Igel-UI の下にあります。
目次
プロジェクトの目標は、技術ユーザーと非技術ユーザーの両方に機械学習を提供することです。
時々、機械学習のプロトタイプを迅速に作成するために使用できるツールが必要になりました。概念実証を構築するか、要点を証明するための高速ドラフト モデルを作成するか、自動 ML を使用するか。私は定型的なコードを書くことに行き詰まり、どこから始めるべきかを考えすぎることがよくあります。そこで、このツールを作成することにしました。
igel は、他の ML フレームワークの上に構築されています。コードを 1 行も記述することなく、機械学習を使用する簡単な方法を提供します。 Igel は高度にカスタマイズ可能ですが、それは必要な場合に限られます。 Igel は、何もカスタマイズすることを強制しません。 igel は、デフォルト値に加えて、auto-ml 機能を使用して、データに最適なモデルを見つけることができます。
必要なのは、実行しようとしている内容を記述するyaml (またはjson ) ファイルだけです。それでおしまい!
Igel は回帰、分類、クラスタリングをサポートしています。 Igel は ImageClassification や TextClassification などの自動 ML 機能をサポートしています
Igel は、データ サイエンス分野で最もよく使用されるデータセット タイプをサポートしています。たとえば、入力データセットは、取得する CSV、TXT、Excel シート、JSON、または HTML ファイルにすることができます。 auto-ml 機能を使用している場合は、生データを igel にフィードすることもでき、igel はその処理方法を判断します。これについては後ほど例で詳しく説明します。
$ pip install -U igel Igel がサポートするモデル:
+--------------------+----------------------------+-------------------------+
| regression | classification | clustering |
+--------------------+----------------------------+-------------------------+
| LinearRegression | LogisticRegression | KMeans |
| Lasso | Ridge | AffinityPropagation |
| LassoLars | DecisionTree | Birch |
| BayesianRegression | ExtraTree | AgglomerativeClustering |
| HuberRegression | RandomForest | FeatureAgglomeration |
| Ridge | ExtraTrees | DBSCAN |
| PoissonRegression | SVM | MiniBatchKMeans |
| ARDRegression | LinearSVM | SpectralBiclustering |
| TweedieRegression | NuSVM | SpectralCoclustering |
| TheilSenRegression | NearestNeighbor | SpectralClustering |
| GammaRegression | NeuralNetwork | MeanShift |
| RANSACRegression | PassiveAgressiveClassifier | OPTICS |
| DecisionTree | Perceptron | KMedoids |
| ExtraTree | BernoulliRBM | ---- |
| RandomForest | BoltzmannMachine | ---- |
| ExtraTrees | CalibratedClassifier | ---- |
| SVM | Adaboost | ---- |
| LinearSVM | Bagging | ---- |
| NuSVM | GradientBoosting | ---- |
| NearestNeighbor | BernoulliNaiveBayes | ---- |
| NeuralNetwork | CategoricalNaiveBayes | ---- |
| ElasticNet | ComplementNaiveBayes | ---- |
| BernoulliRBM | GaussianNaiveBayes | ---- |
| BoltzmannMachine | MultinomialNaiveBayes | ---- |
| Adaboost | ---- | ---- |
| Bagging | ---- | ---- |
| GradientBoosting | ---- | ---- |
+--------------------+----------------------------+-------------------------+自動 ML の場合:
help コマンドは、サポートされているコマンドと対応する引数/オプションを確認するのに非常に便利です。
$ igel --helpサブコマンドでヘルプを実行することもできます。次に例を示します。
$ igel fit --helpIgel は高度にカスタマイズ可能です。必要なものがわかっていてモデルを手動で構成したい場合は、yaml または json 構成ファイルの作成方法を説明する次のセクションを確認してください。その後、igel に何をするか、データと設定ファイルの場所を指示するだけです。以下に例を示します。
$ igel fit --data_path ' path_to_your_csv_dataset.csv ' --yaml_path ' path_to_your_yaml_file.yaml 'ただし、auto-ml 機能を使用して igel にすべてを任せることもできます。この良い例は画像分類です。生画像のデータセットがすでにimagesというフォルダーに保存されていると仮定してみましょう。
あなたがしなければならないのは、実行することだけです:
$ igel auto-train --data_path ' path_to_your_images_folder ' --task ImageClassificationそれでおしまい! Igel はディレクトリから画像を読み取り、データセットを処理 (行列への変換、再スケール、分割など) し、データに対して適切に機能するモデルのトレーニング/最適化を開始します。ご覧のとおり、これは非常に簡単で、データへのパスと実行したいタスクを指定するだけです。
注記
igel は「最良の」モデルを見つけるために多くの異なるモデルを試し、そのパフォーマンスを比較するため、この機能は計算コストが高くなります。
help コマンドを実行して手順を確認できます。サブコマンドでヘルプを実行することもできます。
$ igel --help最初のステップは、yaml ファイルを提供することです (必要に応じて json を使用することもできます)
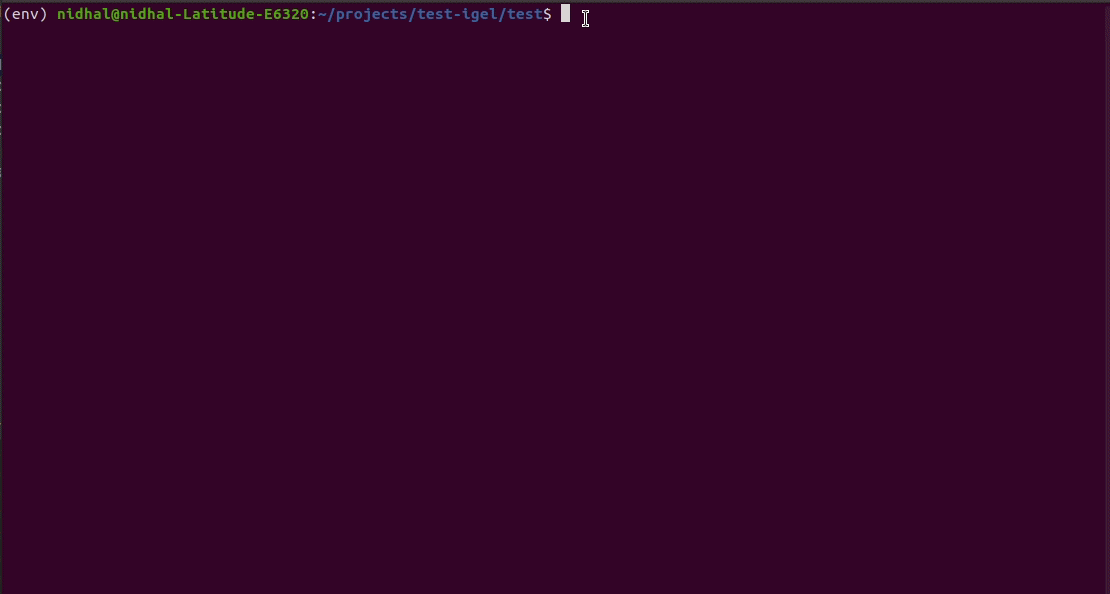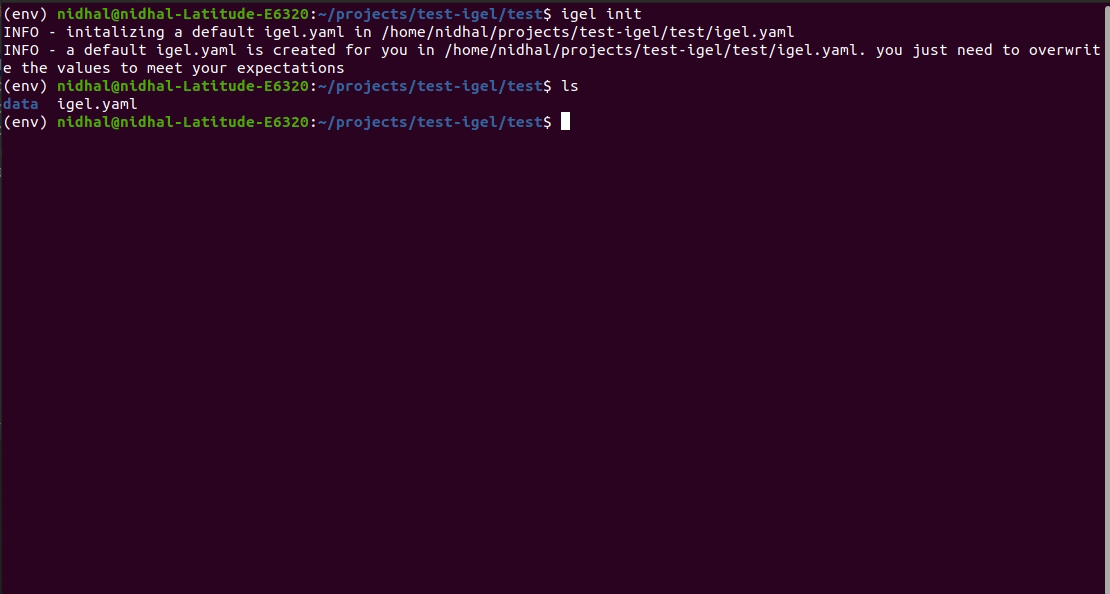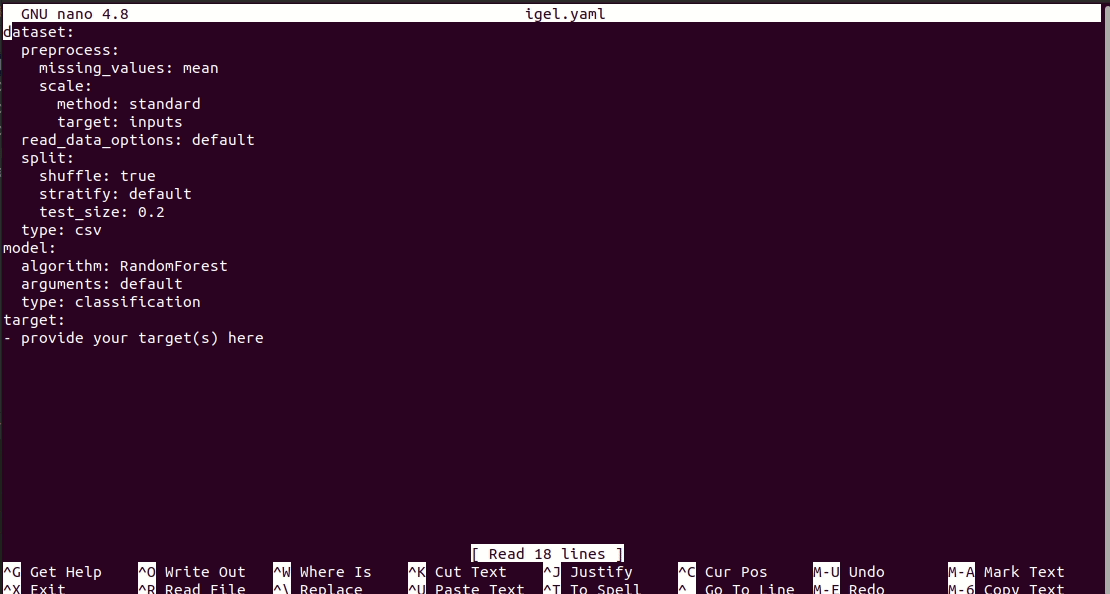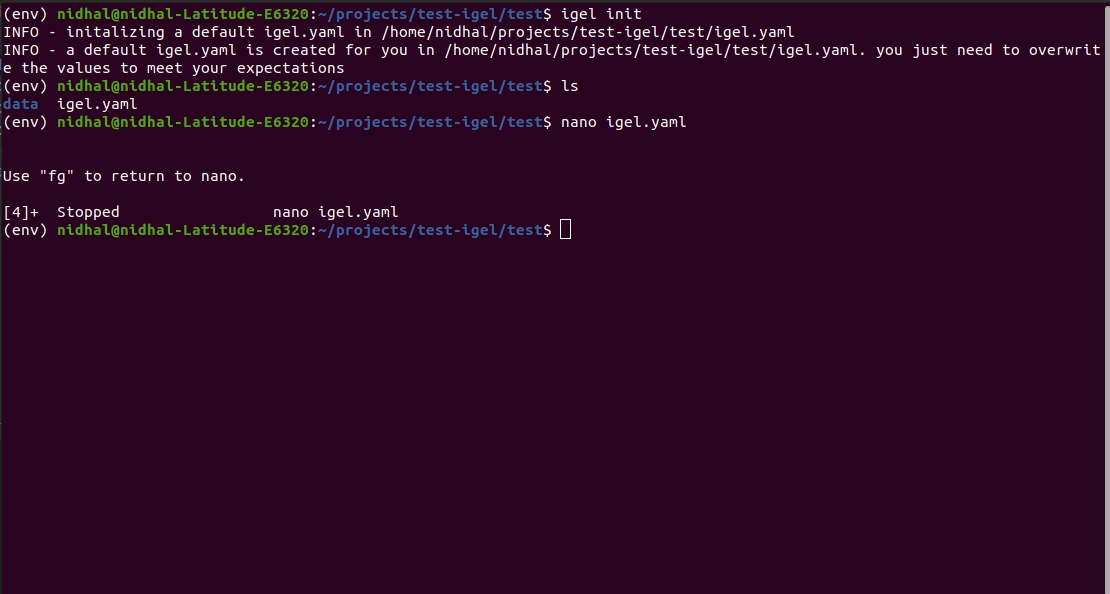
これを手動で行うには、.yaml ファイル (慣例では igel.yaml と呼ばれますが、任意の名前を付けることができます) を作成し、それを自分で編集します。ただし、あなたが怠け者であれば (おそらく私と同じようにそうでしょう:D)、 igel init コマンドを使用するとすぐに始めることができ、基本的な構成ファイルがその場で作成されます。
"""
igel init --help
Example:
If I want to use neural networks to classify whether someone is sick or not using the indian-diabetes dataset,
then I would use this command to initialize a yaml file n.b. you may need to rename outcome column in .csv to sick:
$ igel init -type " classification " -model " NeuralNetwork " -target " sick "
"""
$ igel initコマンドを実行すると、現在の作業ディレクトリに igel.yaml ファイルが作成されます。必要に応じてそれをチェックアウトして変更できます。そうでない場合は、すべてを最初から作成することもできます。
# model definition
model :
# in the type field, you can write the type of problem you want to solve. Whether regression, classification or clustering
# Then, provide the algorithm you want to use on the data. Here I'm using the random forest algorithm
type : classification
algorithm : RandomForest # make sure you write the name of the algorithm in pascal case
arguments :
n_estimators : 100 # here, I set the number of estimators (or trees) to 100
max_depth : 30 # set the max_depth of the tree
# target you want to predict
# Here, as an example, I'm using the famous indians-diabetes dataset, where I want to predict whether someone have diabetes or not.
# Depending on your data, you need to provide the target(s) you want to predict here
target :
- sick上の例では、ランダム フォレストを使用して、データセット内のいくつかの特徴に応じて、誰かが糖尿病であるかどうかを分類しています。この例のインド糖尿病データセットでは、有名なインドの糖尿病を使用しました)
n_estimatorsとmax_depth追加の引数としてモデルに渡したことに注目してください。引数を指定しない場合は、デフォルトが使用されます。各モデルの引数を覚える必要はありません。ターミナルでいつでもigel models実行できます。これにより対話モードになり、使用するモデルと解決したい問題の種類を入力するよう求められます。その後、Igel はモデルに関する情報と、使用可能な引数のリストとその使用方法を確認するためのリンクを表示します。
ターミナルでこのコマンドを実行してモデルを適合/トレーニングします。ここで、データセットへのパスとyaml ファイルへのパスを指定します。
$ igel fit --data_path ' path_to_your_csv_dataset.csv ' --yaml_path ' path_to_your_yaml_file.yaml '
# or shorter
$ igel fit -dp ' path_to_your_csv_dataset.csv ' -yml ' path_to_your_yaml_file.yaml '
"""
That's it. Your "trained" model can be now found in the model_results folder
(automatically created for you in your current working directory).
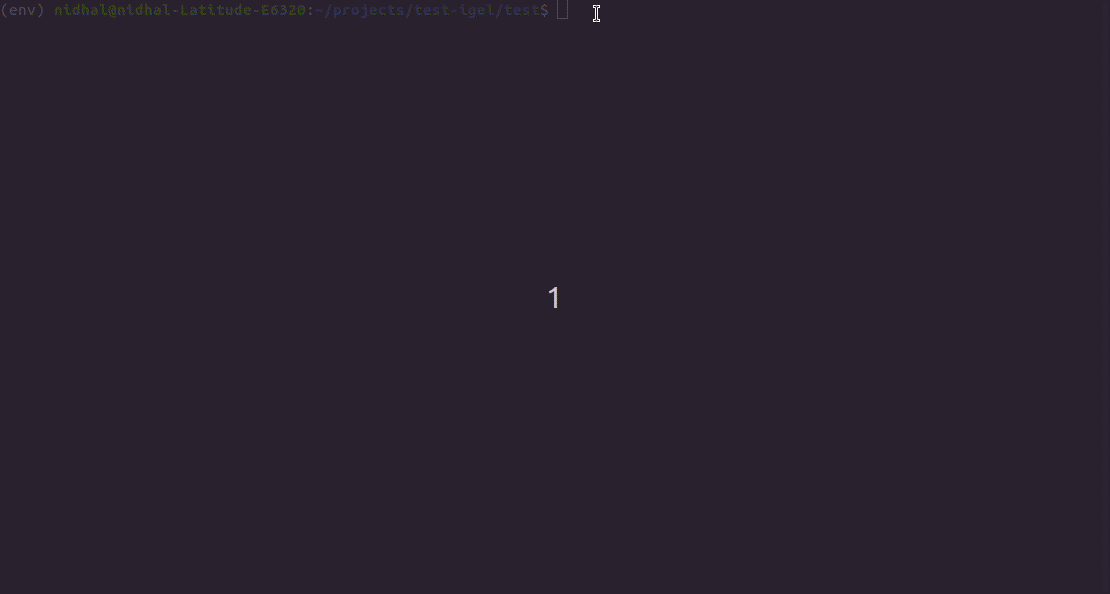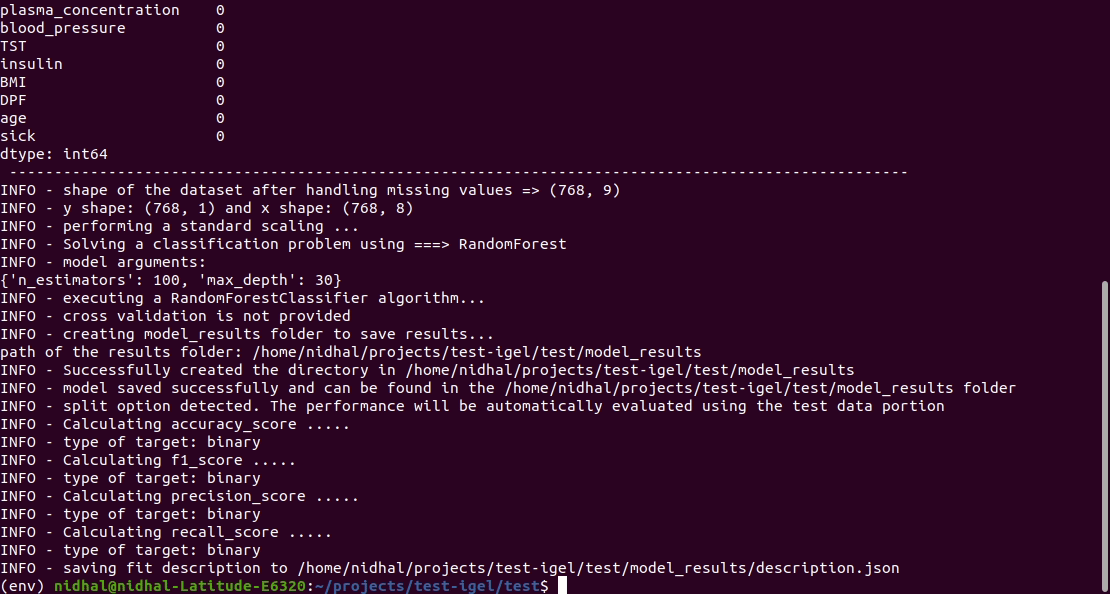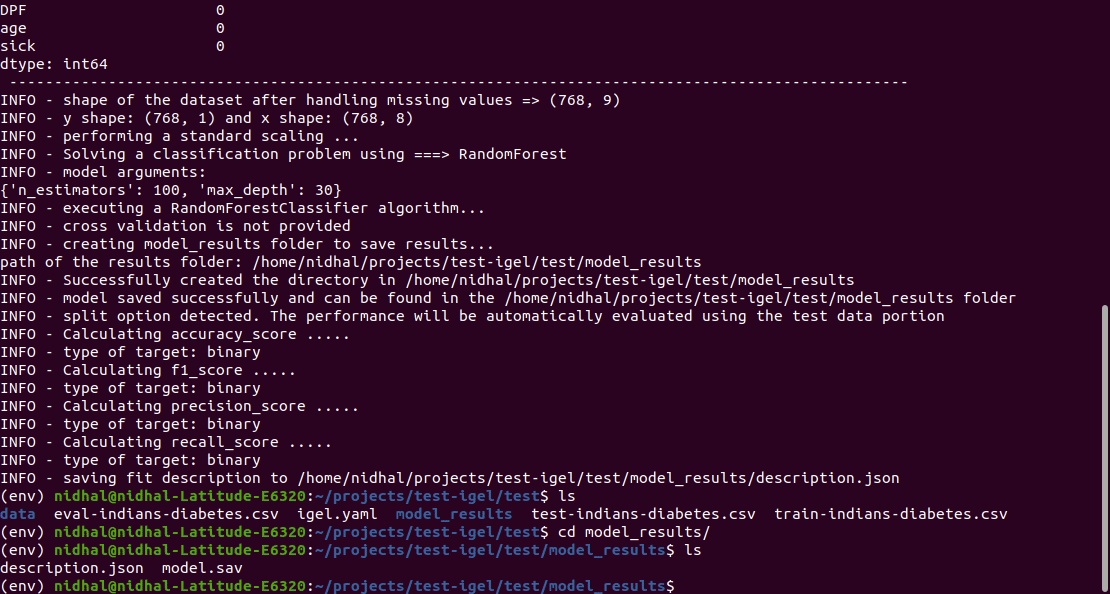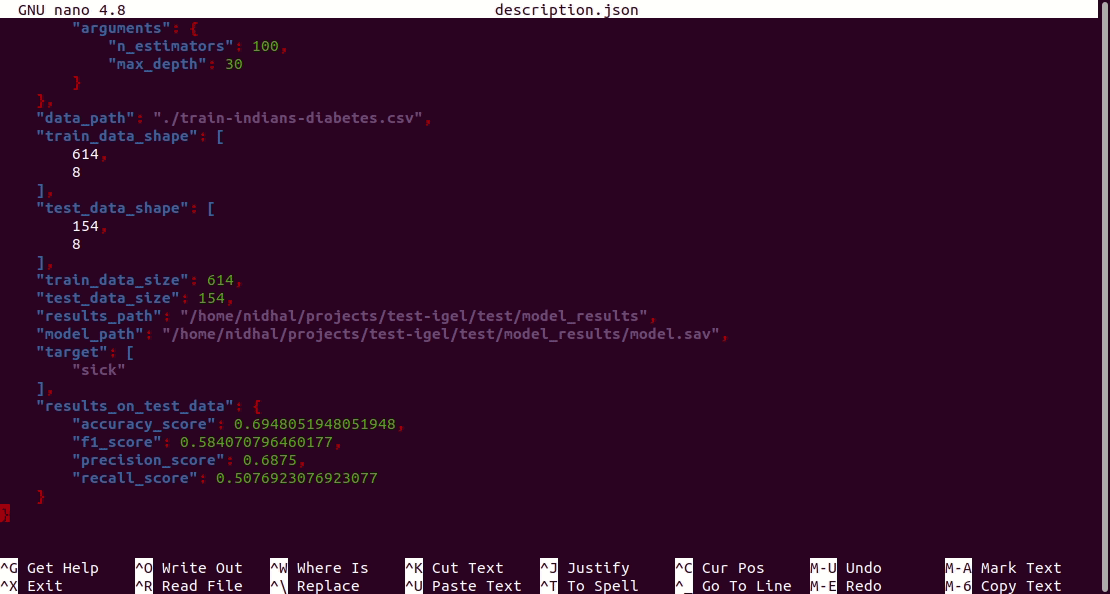
Furthermore, a description can be found in the description.json file inside the model_results folder.
"""
その後、トレーニング/事前適合されたモデルを評価できます。
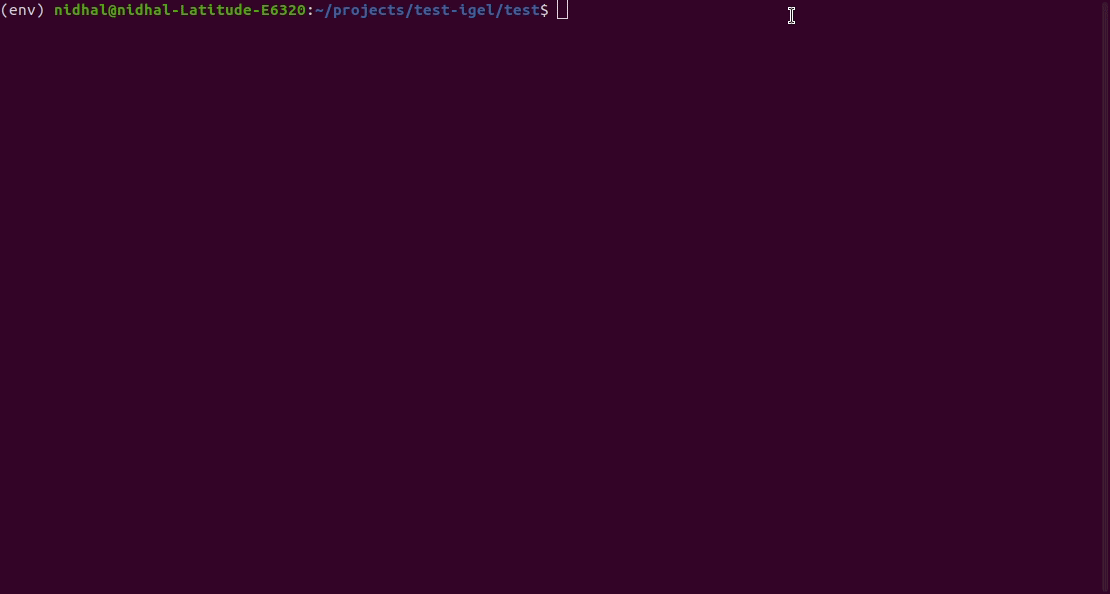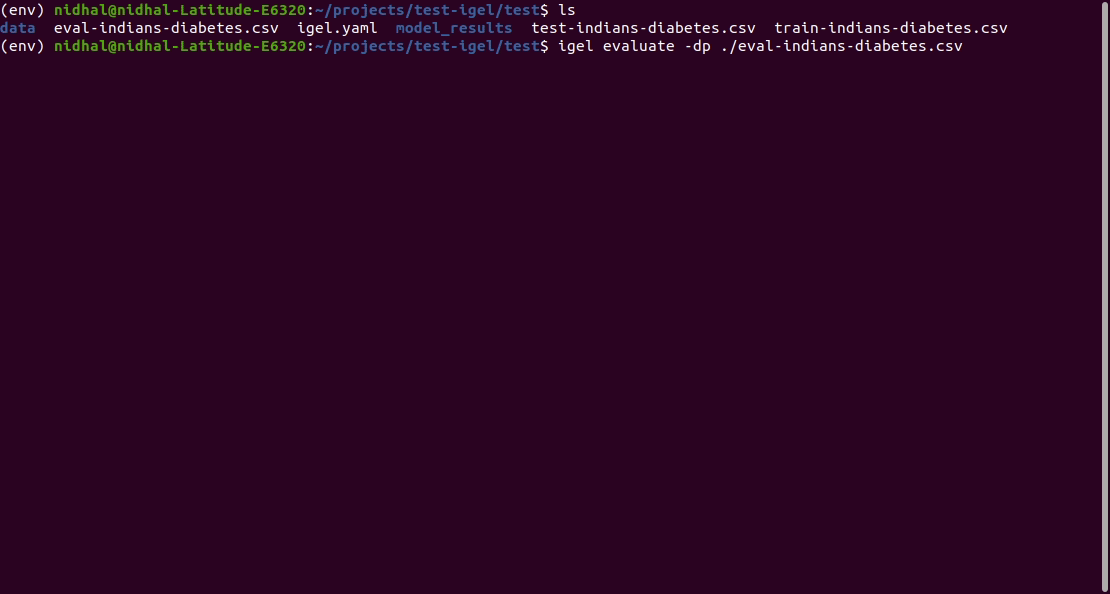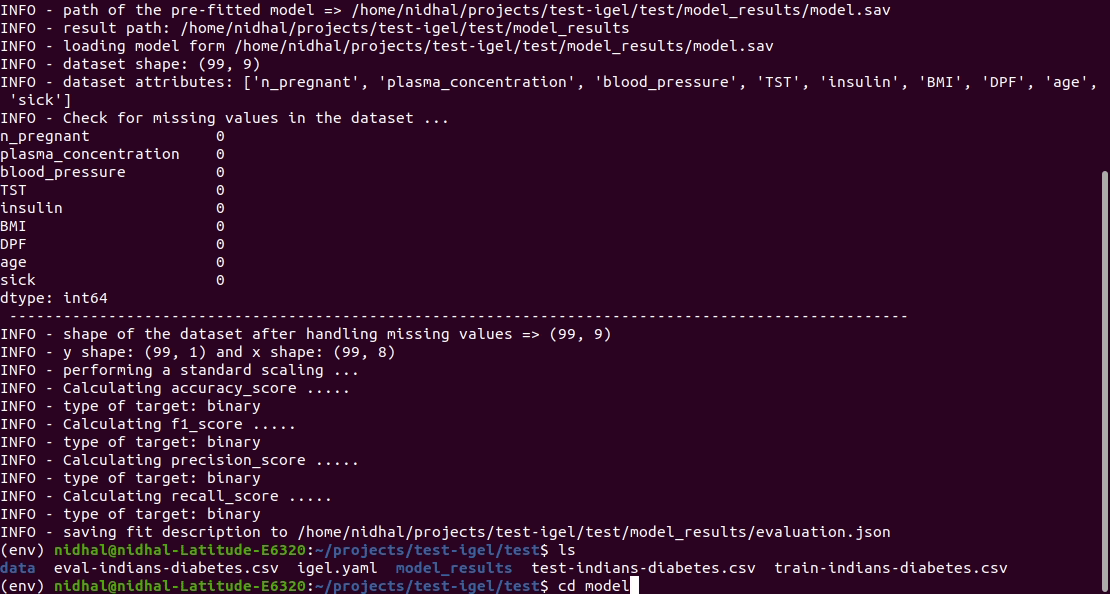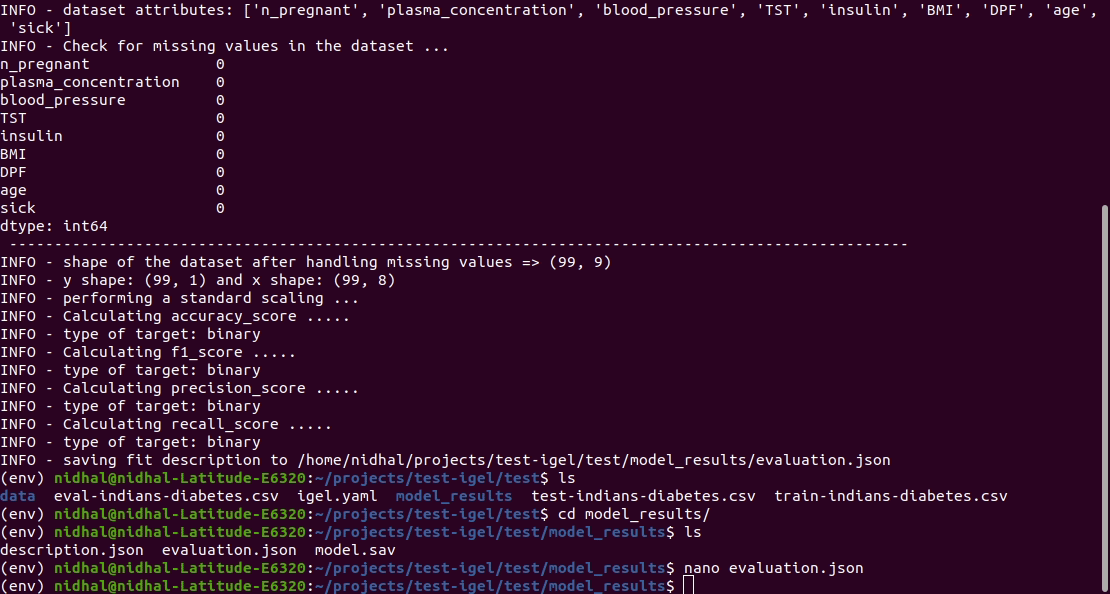
$ igel evaluate -dp ' path_to_your_evaluation_dataset.csv '
"""
This will automatically generate an evaluation.json file in the current directory, where all evaluation results are stored
"""
最後に、評価結果に満足したら、トレーニング/事前適合されたモデルを使用して予測を行うことができます。
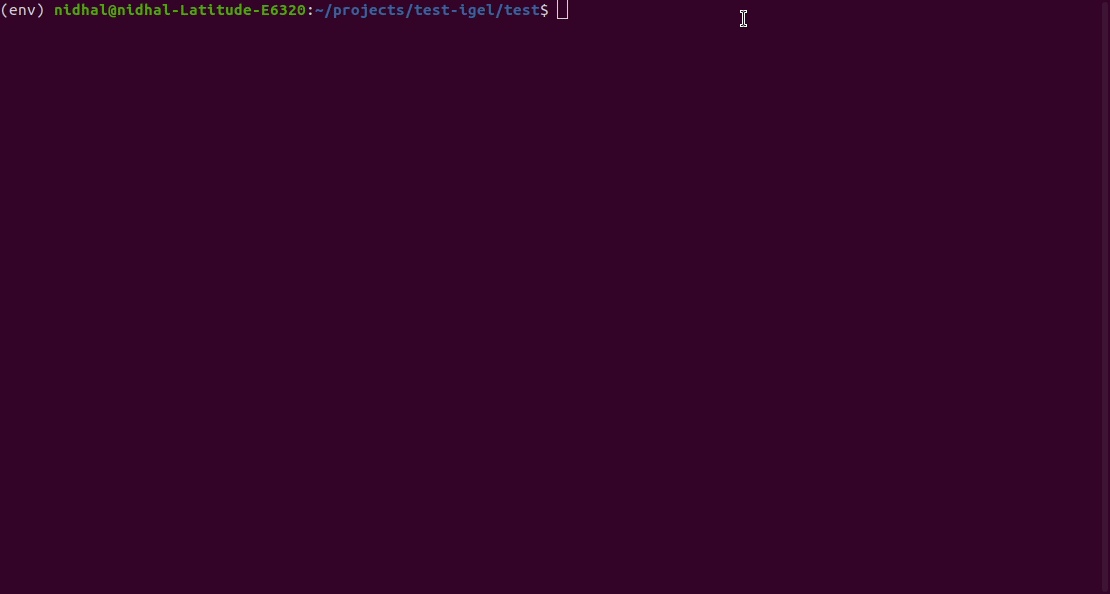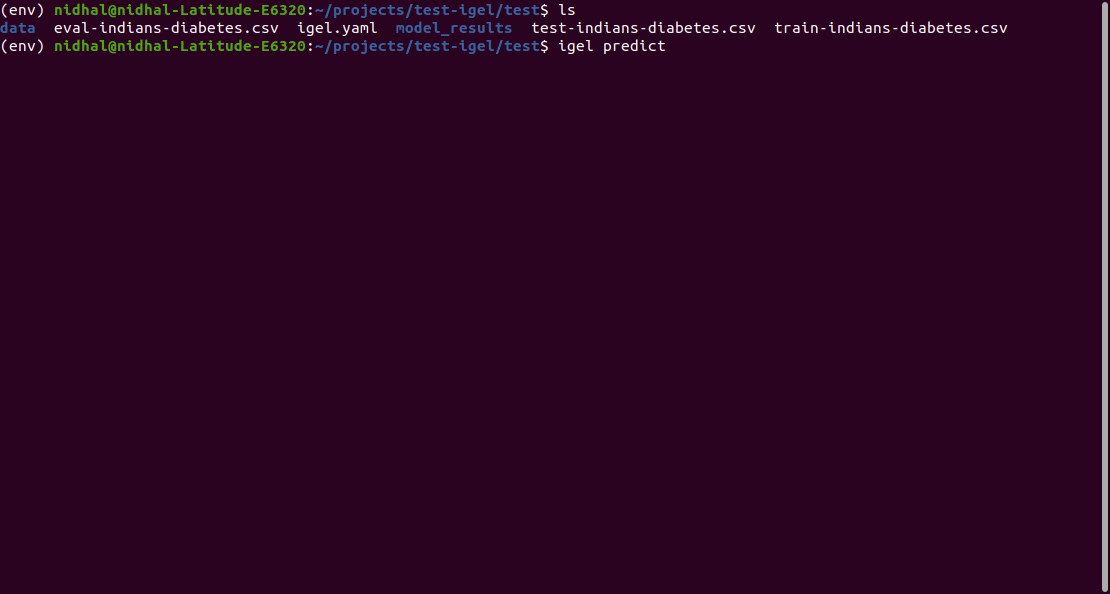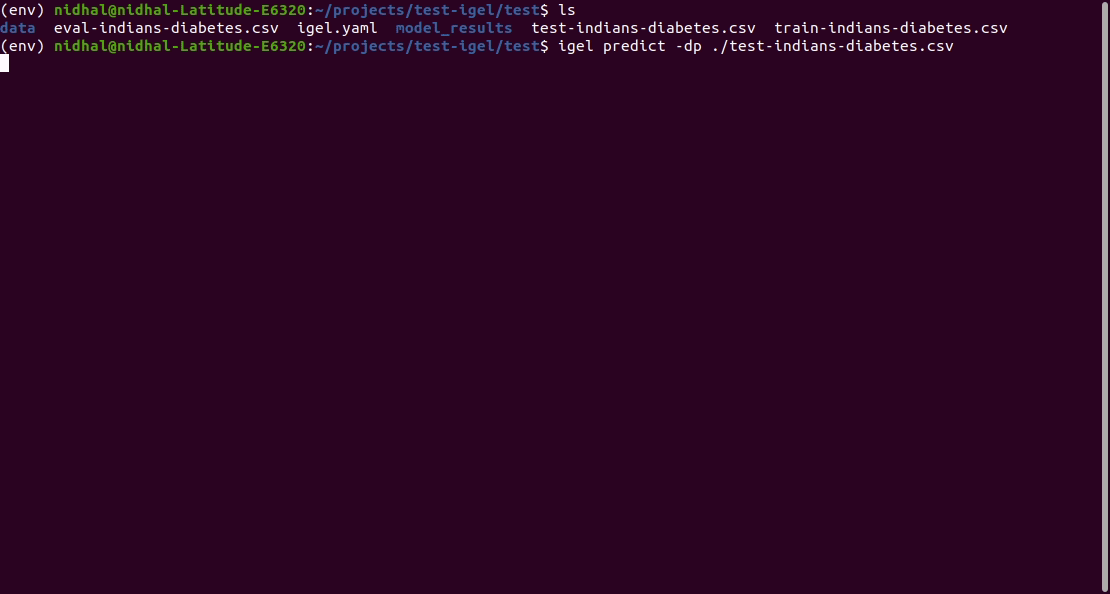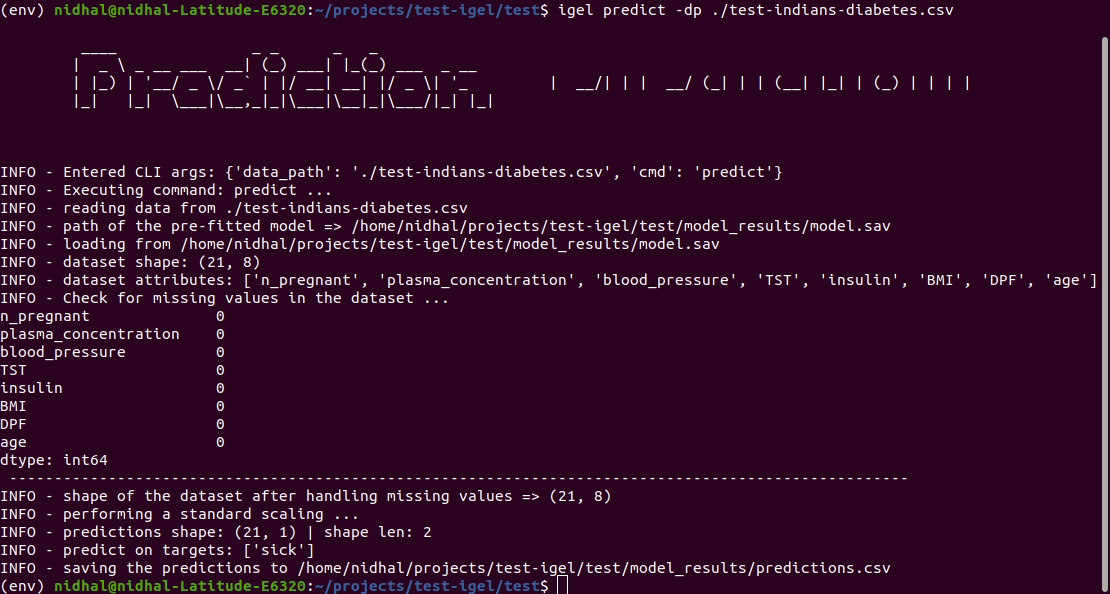
$ igel predict -dp ' path_to_your_test_dataset.csv '
"""
This will generate a predictions.csv file in your current directory, where all predictions are stored in a csv file
"""
トレーニング、評価、予測の各フェーズを、experiment という 1 つのコマンドを使用して組み合わせることができます。
$ igel experiment -DP " path_to_train_data path_to_eval_data path_to_test_data " -yml " path_to_yaml_file "
"""
This will run fit using train_data, evaluate using eval_data and further generate predictions using the test_data
"""
トレーニング済み/事前適合された sklearn モデルを ONNX にエクスポートできます。
$ igel export -dp " path_to_pre-fitted_sklearn_model "
"""
This will convert the sklearn model into ONNX
""" from igel import Igel
Igel ( cmd = "fit" , data_path = "path_to_your_dataset" , yaml_path = "path_to_your_yaml_file" )
"""
check the examples folder for more
"""次のステップは、実稼働環境でモデルを使用することです。 Igel は、serve コマンドを提供することで、このタスクにも役立ちます。 serve コマンドを実行すると、igel にモデルを提供するように指示されます。正確には、igel は REST サーバーを自動的に構築し、特定のホストとポート上でモデルを提供します。これは、これらを cli オプションとして渡すことで構成できます。
最も簡単な方法は次を実行することです。
$ igel serve --model_results_dir " path_to_model_results_directory "モデルをロードしてサーバーを起動するには、igel には--model_results_dirまたは短い -res_dir cli オプションが必要であることに注意してください。デフォルトでは、 igel はlocalhost:8000でモデルを提供しますが、ホストとポートの cli オプションを指定することでこれを簡単にオーバーライドできます。
$ igel serve --model_results_dir " path_to_model_results_directory " --host " 127.0.0.1 " --port 8000Igel は、最新の高性能フレームワークである REST サーバーの作成に FastAPI を使用し、それを内部で実行するために uvicorn を使用します。
この例は、事前トレーニング済みモデル (igel init --target sick -typeclassification の実行によって作成) と、examples/data にあるインドの糖尿病データセットを使用して実行されました。元の CSV の列のヘッダーは、「preg」、「plas」、「pres」、「skin」、「test」、「mass」、「pedi」、「age」です。
カール:
$ curl -X POST localhost:8080/predict --header " Content-Type:application/json " -d ' {"preg": 1, "plas": 180, "pres": 50, "skin": 12, "test": 1, "mass": 456, "pedi": 0.442, "age": 50} '
Outputs: {"prediction":[[0.0]]}$ curl -X POST localhost:8080/predict --header " Content-Type:application/json " -d ' {"preg": [1, 6, 10], "plas":[192, 52, 180], "pres": [40, 30, 50], "skin": [25, 35, 12], "test": [0, 1, 1], "mass": [456, 123, 155], "pedi": [0.442, 0.22, 0.19], "age": [50, 40, 29]} '
Outputs: {"prediction":[[1.0],[0.0],[0.0]]}注意事項/制限事項:
Python クライアントの使用例:
from python_client import IgelClient
# the client allows additional args with defaults:
# scheme="http", endpoint="predict", missing_values="mean"
client = IgelClient ( host = 'localhost' , port = 8080 )
# you can post other types of files compatible with what Igel data reading allows
client . post ( "my_batch_file_for_predicting.csv" )
Outputs : < Response 200 > : { "prediction" :[[ 1.0 ],[ 0.0 ],[ 0.0 ]]}igel の主な目標は、コードを書かずにモデルをトレーニング/適合、評価、使用する方法を提供することです。代わりに、必要なのは、単純な yaml ファイルで実行したい内容を指定/説明することだけです。
基本的に、yaml ファイル内に説明または設定をキーと値のペアとして指定します。 (現時点で) サポートされているすべての構成の概要は次のとおりです。
# dataset operations
dataset :
type : csv # [str] -> type of your dataset
read_data_options : # options you want to supply for reading your data (See the detailed overview about this in the next section)
sep : # [str] -> Delimiter to use.
delimiter : # [str] -> Alias for sep.
header : # [int, list of int] -> Row number(s) to use as the column names, and the start of the data.
names : # [list] -> List of column names to use
index_col : # [int, str, list of int, list of str, False] -> Column(s) to use as the row labels of the DataFrame,
usecols : # [list, callable] -> Return a subset of the columns
squeeze : # [bool] -> If the parsed data only contains one column then return a Series.
prefix : # [str] -> Prefix to add to column numbers when no header, e.g. ‘X’ for X0, X1, …
mangle_dupe_cols : # [bool] -> Duplicate columns will be specified as ‘X’, ‘X.1’, …’X.N’, rather than ‘X’…’X’. Passing in False will cause data to be overwritten if there are duplicate names in the columns.
dtype : # [Type name, dict maping column name to type] -> Data type for data or columns
engine : # [str] -> Parser engine to use. The C engine is faster while the python engine is currently more feature-complete.
converters : # [dict] -> Dict of functions for converting values in certain columns. Keys can either be integers or column labels.
true_values : # [list] -> Values to consider as True.
false_values : # [list] -> Values to consider as False.
skipinitialspace : # [bool] -> Skip spaces after delimiter.
skiprows : # [list-like] -> Line numbers to skip (0-indexed) or number of lines to skip (int) at the start of the file.
skipfooter : # [int] -> Number of lines at bottom of file to skip
nrows : # [int] -> Number of rows of file to read. Useful for reading pieces of large files.
na_values : # [scalar, str, list, dict] -> Additional strings to recognize as NA/NaN.
keep_default_na : # [bool] -> Whether or not to include the default NaN values when parsing the data.
na_filter : # [bool] -> Detect missing value markers (empty strings and the value of na_values). In data without any NAs, passing na_filter=False can improve the performance of reading a large file.
verbose : # [bool] -> Indicate number of NA values placed in non-numeric columns.
skip_blank_lines : # [bool] -> If True, skip over blank lines rather than interpreting as NaN values.
parse_dates : # [bool, list of int, list of str, list of lists, dict] -> try parsing the dates
infer_datetime_format : # [bool] -> If True and parse_dates is enabled, pandas will attempt to infer the format of the datetime strings in the columns, and if it can be inferred, switch to a faster method of parsing them.
keep_date_col : # [bool] -> If True and parse_dates specifies combining multiple columns then keep the original columns.
dayfirst : # [bool] -> DD/MM format dates, international and European format.
cache_dates : # [bool] -> If True, use a cache of unique, converted dates to apply the datetime conversion.
thousands : # [str] -> the thousands operator
decimal : # [str] -> Character to recognize as decimal point (e.g. use ‘,’ for European data).
lineterminator : # [str] -> Character to break file into lines.
escapechar : # [str] -> One-character string used to escape other characters.
comment : # [str] -> Indicates remainder of line should not be parsed. If found at the beginning of a line, the line will be ignored altogether. This parameter must be a single character.
encoding : # [str] -> Encoding to use for UTF when reading/writing (ex. ‘utf-8’).
dialect : # [str, csv.Dialect] -> If provided, this parameter will override values (default or not) for the following parameters: delimiter, doublequote, escapechar, skipinitialspace, quotechar, and quoting
delim_whitespace : # [bool] -> Specifies whether or not whitespace (e.g. ' ' or ' ') will be used as the sep
low_memory : # [bool] -> Internally process the file in chunks, resulting in lower memory use while parsing, but possibly mixed type inference.
memory_map : # [bool] -> If a filepath is provided for filepath_or_buffer, map the file object directly onto memory and access the data directly from there. Using this option can improve performance because there is no longer any I/O overhead.
random_numbers : # random numbers options in case you wanted to generate the same random numbers on each run
generate_reproducible : # [bool] -> set this to true to generate reproducible results
seed : # [int] -> the seed number is optional. A seed will be set up for you if you didn't provide any
split : # split options
test_size : 0.2 # [float] -> 0.2 means 20% for the test data, so 80% are automatically for training
shuffle : true # [bool] -> whether to shuffle the data before/while splitting
stratify : None # [list, None] -> If not None, data is split in a stratified fashion, using this as the class labels.
preprocess : # preprocessing options
missing_values : mean # [str] -> other possible values: [drop, median, most_frequent, constant] check the docs for more
encoding :
type : oneHotEncoding # [str] -> other possible values: [labelEncoding]
scale : # scaling options
method : standard # [str] -> standardization will scale values to have a 0 mean and 1 standard deviation | you can also try minmax
target : inputs # [str] -> scale inputs. | other possible values: [outputs, all] # if you choose all then all values in the dataset will be scaled
# model definition
model :
type : classification # [str] -> type of the problem you want to solve. | possible values: [regression, classification, clustering]
algorithm : NeuralNetwork # [str (notice the pascal case)] -> which algorithm you want to use. | type igel algorithms in the Terminal to know more
arguments : # model arguments: you can check the available arguments for each model by running igel help in your terminal
use_cv_estimator : false # [bool] -> if this is true, the CV class of the specific model will be used if it is supported
cross_validate :
cv : # [int] -> number of kfold (default 5)
n_jobs : # [signed int] -> The number of CPUs to use to do the computation (default None)
verbose : # [int] -> The verbosity level. (default 0)
hyperparameter_search :
method : grid_search # method you want to use: grid_search and random_search are supported
parameter_grid : # put your parameters grid here that you want to use, an example is provided below
param1 : [val1, val2]
param2 : [val1, val2]
arguments : # additional arguments you want to provide for the hyperparameter search
cv : 5 # number of folds
refit : true # whether to refit the model after the search
return_train_score : false # whether to return the train score
verbose : 0 # verbosity level
# target you want to predict
target : # list of strings: basically put here the column(s), you want to predict that exist in your csv dataset
- put the target you want to predict here
- you can assign many target if you are making a multioutput prediction 注記
igel は内部でパンダを使用してデータを読み取り、解析します。したがって、このデータのオプションのパラメーターは、パンダの公式ドキュメントにも記載されています。
yaml (または json) ファイルで指定できる構成の詳細な概要を以下に示します。データセットのすべての構成値が必要なわけではないことに注意してください。これらはオプションです。通常、igel はデータセットを読み取る方法を見つけます。
ただし、この read_data_options セクションを使用して追加のフィールドを提供することで、これを解決できます。たとえば、私の意見では、役立つ値の 1 つは「sep」です。これは、csv データセット内の列をどのように区切るかを定義します。一般に、CSV データセットはカンマで区切られます。これは、ここでのデフォルト値でもあります。ただし、場合によってはセミコロンで区切る場合があります。
したがって、これを read_data_options で指定できます。 sep: ";"を追加するだけです。 read_data_options の下にあります。
| パラメータ | タイプ | 説明 |
|---|---|---|
| 9月 | str、デフォルト ',' | 使用する区切り文字。 sep が None の場合、C エンジンはセパレータを自動的に検出できませんが、Python 解析エンジンは検出できます。つまり、後者が使用され、Python の組み込みスニファ ツール csv.Sniffer によってセパレータが自動的に検出されます。さらに、1 文字より長く、「s+」とは異なる区切り文字は正規表現として解釈され、Python 解析エンジンの使用も強制されます。正規表現の区切り文字は引用符で囲まれたデータを無視する傾向があることに注意してください。正規表現の例: 'rt'。 |
| デリミタ | デフォルト なし | 9月の別名。 |
| ヘッダ | int、int のリスト、デフォルトの 'infer' | 列名として使用する行番号とデータの開始。デフォルトの動作は列名を推測することです。名前が渡されない場合、動作は header=0 と同じになり、列名はファイルの最初の行から推測されます。列名が明示的に渡された場合、動作は header=None と同じになります。 。既存の名前を置き換えることができるようにするには、header=0 を明示的に渡します。ヘッダーは、列のマルチインデックスの行位置を指定する整数のリスト ([0,1,3] など) にすることができます。指定されていない間にある行はスキップされます (たとえば、この例では 2 がスキップされます)。 Skip_blank_lines=True の場合、このパラメータはコメント行と空行を無視するため、header=0 はファイルの最初の行ではなくデータの最初の行を示すことに注意してください。 |
| 名前 | 配列のような、オプション | 使用する列名のリスト。ファイルにヘッダー行が含まれている場合は、明示的に header=0 を渡して列名をオーバーライドする必要があります。このリストの重複は許可されません。 |
| インデックス列 | int、str、int / str のシーケンス、または False、デフォルトはなし | DataFrame の行ラベルとして使用する列。文字列名または列インデックスとして指定されます。 int / str のシーケンスが指定された場合は、MultiIndex が使用されます。注:index_col=False を使用すると、パンダに最初の列をインデックスとして使用させないよう強制できます。たとえば、各行の末尾に区切り文字が含まれる不正な形式のファイルがある場合です。 |
| usecols | リスト形式または呼び出し可能、オプション | 列のサブセットを返します。リストのような場合、すべての要素は位置 (つまり、ドキュメントの列への整数インデックス) であるか、ユーザーが名前で指定するかドキュメントのヘッダー行から推測される列名に対応する文字列である必要があります。たとえば、有効なリストのような usecols パラメータは [0, 1, 2] または ['foo', 'bar', 'baz'] になります。要素の順序は無視されるため、usecols=[0, 1] は [1, 0] と同じになります。要素の順序を保持してデータから DataFrame をインスタンス化するには、 ['foo', 'bar の列に対して pd.read_csv(data, usecols=['foo', 'bar'])[['foo', 'bar']] を使用します。 '] order または pd.read_csv(data, usecols=['foo', 'bar'])[['bar', 'foo']] for ['bar', 「ふー」] の注文。呼び出し可能な場合、呼び出し可能な関数は列名に対して評価され、呼び出し可能な関数が True と評価される名前を返します。有効な呼び出し可能な引数の例は、lambda x: x.upper() in ['AAA', 'BBB', 'DDD'] です。このパラメータを使用すると、解析時間が大幅に短縮され、メモリ使用量が削減されます。 |
| 絞る | ブール値、デフォルトは False | 解析されたデータに列が 1 つしか含まれていない場合は、Series を返します。 |
| 接頭語 | str、オプション | ヘッダーがない場合に列番号に追加するプレフィックス。たとえば、X0、X1、… の場合は「X」。 |
| mangle_dupe_cols | ブール値、デフォルトは True | 重複する列は、「X」…「X」ではなく、「X」、「X.1」、…「X.N」として指定されます。 False を渡すと、列に重複した名前がある場合にデータが上書きされます。 |
| dtype | {'c', 'python'}、オプション | 使用するパーサー エンジン。 C エンジンは高速ですが、現時点では Python エンジンの方が機能が充実しています。 |
| コンバーター | 辞書、オプション | 特定の列の値を変換するための関数の辞書。キーは整数または列ラベルのいずれかになります。 |
| true_values | リスト、オプション | True とみなされる値。 |
| false_values | リスト、オプション | False とみなされる値。 |
| スキップ初期スペース | ブール値、デフォルトは False | 区切り文字の後のスペースをスキップします。 |
| スキップロウ | リストのような、int または呼び出し可能、オプション | ファイルの先頭でスキップする行番号 (0 から始まるインデックス) またはスキップする行数 (int)。呼び出し可能な場合、呼び出し可能な関数は行インデックスに対して評価され、行をスキップする必要がある場合は True を返し、それ以外の場合は False を返します。有効な呼び出し可能な引数の例は、lambda x: x in [0, 2] です。 |
| スキップフッター | 整数、デフォルトは 0 | ファイルの下部でスキップする行数 (engine='c' ではサポートされません)。 |
| 狭い | 整数、オプション | 読み取るファイルの行数。大きなファイルの一部を読み取る場合に便利です。 |
| na_values | スカラー、str、リスト状、または辞書、オプション | NA/NaN として認識する追加の文字列。 dict が渡された場合、特定の列ごとの NA 値。デフォルトでは、次の値は NaN として解釈されます: ''、'#N/A'、'#N/AN/A'、'#NA'、'-1.#IND'、'-1.#QNAN'、 '-NaN'、'-nan'、'1.#IND'、'1.#QNAN'、'<NA>'、'N/A'、'NA'、'NULL'、 「NaN」、「n/a」、「nan」、「null」。 |
| keep_default_na | ブール値、デフォルトは True | データを解析するときにデフォルトの NaN 値を含めるかどうか。 na_values が渡されるかどうかに応じて、動作は次のようになります。 keep_default_na が True で、na_values が指定されている場合、解析に使用されるデフォルトの NaN 値に na_values が追加されます。 keep_default_na が True で、na_values が指定されていない場合は、デフォルトの NaN 値のみが解析に使用されます。 keep_default_na が False で、na_values が指定されている場合、na_values で指定された NaN 値のみが解析に使用されます。 keep_default_na が False で、na_values が指定されていない場合、文字列は NaN として解析されません。 na_filter が False として渡された場合、keep_default_na および na_values パラメータは無視されることに注意してください。 |
| na_filter | ブール値、デフォルトは True | 欠損値マーカー (空の文字列と na_values の値) を検出します。 NA のないデータでは、na_filter=False を渡すと、大きなファイルの読み取りパフォーマンスが向上します。 |
| 冗長な | ブール値、デフォルトは False | 数値以外の列に配置された NA 値の数を示します。 |
| スキップ_空白行 | ブール値、デフォルトは True | True の場合、NaN 値として解釈されるのではなく、空白行をスキップします。 |
| parse_dates | bool または int のリストまたは名前またはリストのリストまたは dict、デフォルトは False | 動作は次のとおりです: ブール値。 True の場合 -> インデックスの解析を試みます。 int または名前のリスト。たとえば、If [1, 2, 3] -> 列 1、2、3 をそれぞれ別の日付列として解析してみてください。リストのリスト。例: If [[1, 3]] -> 列 1 と 3 を結合し、単一の日付列として解析します。 dict、例: {'foo' : [1, 3]} -> 列 1、3 を日付として解析し、結果 'foo' を呼び出します。たとえば、解析できない値またはタイムゾーンが混在している場合、列またはインデックスは変更されずにオブジェクト データ型として返されます。 |
| infer_datetime_format | ブール値、デフォルトは False | True で parse_dates が有効な場合、pandas は列内の日時文字列の形式を推論しようとし、推論できる場合は、より高速な解析方法に切り替えます。場合によっては、これにより解析速度が 5 ~ 10 倍向上する可能性があります。 |
| keep_date_col | ブール値、デフォルトは False | True で parse_dates が複数の列の結合を指定している場合は、元の列を保持します。 |
| date_parser | 機能、オプション | 文字列列のシーケンスを日時インスタンスの配列に変換するために使用する関数。デフォルトでは、dateutil.parser.parser を使用して変換を実行します。 Pandas は 3 つの異なる方法で date_parser の呼び出しを試行し、例外が発生した場合は次の方法に進みます。 1) 1 つ以上の配列 (parse_dates で定義されたもの) を引数として渡します。 2) parse_dates で定義された列の文字列値を (行ごとに) 単一の配列に連結し、それを渡します。 3) 1 つ以上の文字列 (parse_dates で定義された列に対応) を引数として使用して、行ごとに date_parser を 1 回呼び出します。 |
| 初日 | ブール値、デフォルトは False | DD/MM 形式の日付、国際形式およびヨーロッパ形式。 |
| キャッシュ日付 | ブール値、デフォルトは True | True の場合、一意の変換された日付のキャッシュを使用して日時変換を適用します。重複した日付文字列、特にタイムゾーン オフセットを含む日付文字列を解析するときに、大幅な速度向上が生じる可能性があります。 |
| 何千もの | str、オプション | 千の位の区切り文字。 |
| 10進数 | str、デフォルトは '.' | 小数点として認識する文字 (ヨーロッパのデータには「,」を使用するなど)。 |
| ラインターミネータ | str (長さ 1)、オプション | ファイルを複数行に分割する文字。 C パーサーでのみ有効です。 |
| エスケープ文字 | str (長さ 1)、オプション | 他の文字をエスケープするために使用される 1 文字の文字列。 |
| コメント | str、オプション | 行の残りの部分を解析しないことを示します。行の先頭にある場合、その行は完全に無視されます。 |
| エンコーディング | str、オプション | 読み取り/書き込み時に UTF に使用するエンコーディング (例: 'utf-8')。 |
| 方言 | str または csv.Dialect、オプション | このパラメータを指定すると、delimiter、doublequote、escapechar、skipinitialspace、quotechar、および quoteing パラメータの値 (デフォルトかどうか) がオーバーライドされます。 |
| メモリ不足 | ブール値、デフォルトは True | ファイルを内部でチャンクに分けて処理するため、解析中のメモリ使用量は少なくなりますが、混合型推論が行われる可能性があります。型が混在しないようにするには、False を設定するか、dtype パラメーターで型を指定します。ファイル全体が単一の DataFrame に読み込まれることに注意してください。 |
| メモリマップ | ブール値、デフォルトは False | ファイル オブジェクトをメモリに直接マップし、そこからデータに直接アクセスします。このオプションを使用すると、I/O オーバーヘッドがなくなるため、パフォーマンスが向上します。 |
このセクションでは、 igelの機能を証明するための完全なエンドツーエンドのソリューションが提供されます。前に説明したように、yaml 構成ファイルを作成する必要があります。以下は、デシジョン ツリーアルゴリズムを使用して、誰かが糖尿病であるかどうかを予測するためのエンドツーエンドの例です。データセットは、examples フォルダーにあります。
model :
type : classification
algorithm : DecisionTree
target :
- sick $ igel fit -dp path_to_the_dataset -yml path_to_the_yaml_fileこれで、igel がモデルを適合させ、現在のディレクトリの model_results フォルダーに保存します。
事前適合モデルを評価します。 Igel は、model_results ディレクトリから事前適合モデルをロードし、それを評価します。必要なのは、evaluate コマンドを実行して、評価データへのパスを指定することだけです。
$ igel evaluate -dp path_to_the_evaluation_datasetそれでおしまい! Igel はモデルを評価し、model_results フォルダー内のevaluation.jsonファイルに統計/結果を保存します。
事前適合モデルを使用して、新しいデータを予測します。これは igel によって自動的に行われます。必要なのは、予測を使用するデータへのパスを指定することだけです。
$ igel predict -dp path_to_the_new_datasetそれでおしまい! Igel は、事前適合モデルを使用して予測を行い、model_results フォルダー内の予測.csvファイルに保存します。
一部の前処理メソッドやその他の操作を yaml ファイルで指定して実行することもできます。以下は、データがトレーニング用に 80%、検証/テスト用に 20% に分割される例です。また、分割時にはデータがシャッフルされます。
さらに、データは欠損値を平均値に置き換えることによって前処理されます (中央値、最頻値などを使用することもできます)。詳細については、このリンクを確認してください
# dataset operations
dataset :
split :
test_size : 0.2
shuffle : True
stratify : default
preprocess : # preprocessing options
missing_values : mean # other possible values: [drop, median, most_frequent, constant] check the docs for more
encoding :
type : oneHotEncoding # other possible values: [labelEncoding]
scale : # scaling options
method : standard # standardization will scale values to have a 0 mean and 1 standard deviation | you can also try minmax
target : inputs # scale inputs. | other possible values: [outputs, all] # if you choose all then all values in the dataset will be scaled
# model definition
model :
type : classification
algorithm : RandomForest
arguments :
# notice that this is the available args for the random forest model. check different available args for all supported models by running igel help
n_estimators : 100
max_depth : 20
# target you want to predict
target :
- sick次に、他の例に示すように igel コマンドを実行してモデルを当てはめることができます。
$ igel fit -dp path_to_the_dataset -yml path_to_the_yaml_file評価用
$ igel evaluate -dp path_to_the_evaluation_dataset生産用
$ igel predict -dp path_to_the_new_dataset リポジトリのサンプル フォルダーには、有名な indian-diabetes、iris データセット、linnerud (sklearn の) データセットが保存されているデータ フォルダーがあります。さらに、各フォルダー内にはエンドツーエンドの例があり、開始に役立つスクリプトと yaml ファイルが含まれています。
indian-diabetes-example フォルダーには、開始に役立つ 2 つの例が含まれています。
iris-example フォルダーには、ロジスティック回帰の例が含まれています。ここでは、igel の機能を詳しく示すために、ターゲット列に対して前処理 (ワン ホット エンコーディング) が実行されます。
さらに、multioutput-example には、複数出力回帰の例が含まれています。最後に、cv-example には、相互検証を使用した Ridge 分類器を使用する例が含まれています。
このフォルダーには、相互検証とハイパーパラメーター検索の例もあります。
サンプルと igel cli を試してみることをお勧めします。ただし、必要に応じて、fit.py、evaluate.py、predict.py を直接実行することもできます。
まず、画像のラベル/クラスに基づいてサブフォルダーに分類された画像のデータセットを作成または変更します。たとえば、犬と猫の画像がある場合は、2 つのサブフォルダーが必要になります。
これら 2 つのサブフォルダーが、images という 1 つの親フォルダーに含まれていると仮定すると、データを igel にフィードするだけです。
$ igel auto-train -dp ./images --task ImageClassificationIgel は、データの前処理からハイパーパラメーターの最適化まですべてを処理します。最終的に、最適なモデルが現在の作業ディレクトリに保存されます。
まず、テキスト ラベル/クラスに基づいてサブフォルダーに分類されるテキスト データセットを作成または変更します。たとえば、肯定的なフィードバックと否定的なフィードバックのテキスト データセットがある場合は、2 つのサブフォルダーが必要になります。
これら 2 つのサブフォルダーが text という 1 つの親フォルダーに含まれていると仮定すると、データを igel にフィードするだけです。
$ igel auto-train -dp ./texts --task TextClassificationIgel は、データの前処理からハイパーパラメーターの最適化まですべてを処理します。最終的に、最適なモデルが現在の作業ディレクトリに保存されます。
ターミナルに慣れていない場合は、igel UI を実行することもできます。上記のように igel をマシンにインストールするだけです。次に、ターミナルでこの 1 つのコマンドを実行します。
$ igel guiこれにより、非常に簡単に使用できる GUI が開きます。 GUI の外観と使用方法の例をここで確認してください: https://github.com/nidhaloff/igel-ui
最初に Docker Hub からイメージをプルできます
$ docker pull nidhaloff/igel次に、それを使用します。
$ docker run -it --rm -v $( pwd ) :/data nidhaloff/igel fit -yml ' your_file.yaml ' -dp ' your_dataset.csv '最初にイメージをビルドすることで、Docker 内で igel を実行できます。
$ docker build -t igel .次に、それを実行し、現在のディレクトリ (igel ディレクトリである必要はありません) をコンテナ内の /data (workdir) としてアタッチします。
$ docker run -it --rm -v $( pwd ) :/data igel fit -yml ' your_file.yaml ' -dp ' your_dataset.csv ' 問題が発生した場合は、お気軽に問題を開いてください。さらに、詳細な情報や質問については、著者に連絡することができます。
アイゲルは好きですか?次の方法でいつでもこのプロジェクトの開発を支援できます。
このプロジェクトは役に立つと思いますが、新しいアイデア、新機能、バグ修正を導入し、ドキュメントを拡張したいと考えていますか?
貢献はいつでも歓迎されます。まずはガイドラインを必ずお読みください
MITライセンス
著作権 (c) 2020 年現在、ニダル・バックーリ


