yoloface
1.0.0
YOLOv3 (You Only Look Once) は、最先端のリアルタイム物体検出アルゴリズムです。公開されたモデルは、画像とビデオ内の 80 の異なるオブジェクトを認識します。詳細については、この文書を参照してください。
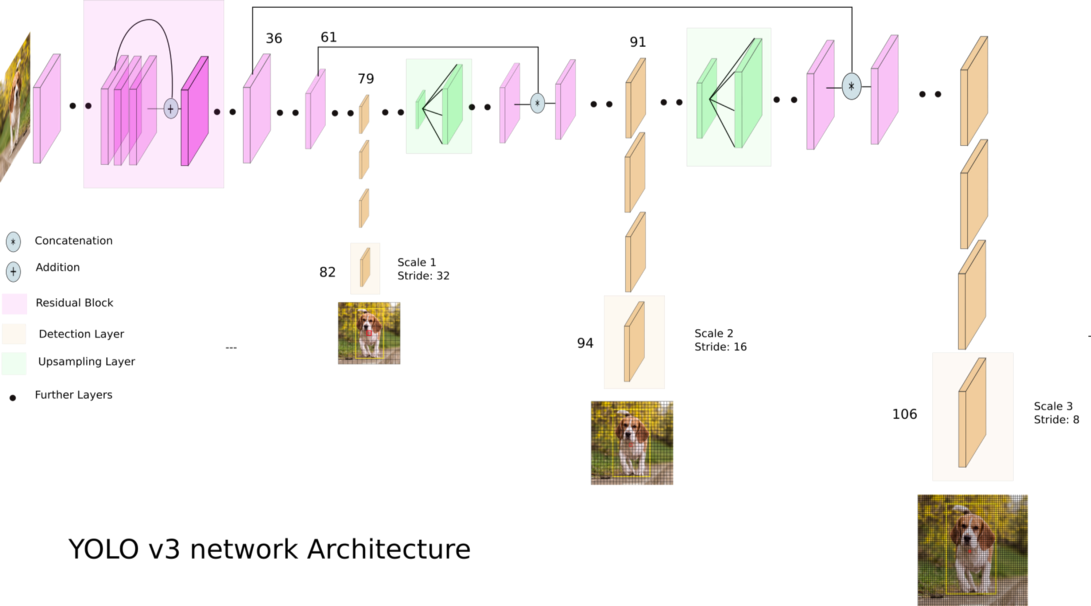
クレジット: Ayoosh Kathuria
OpenCV dnnモジュールは、TensorFlow、Torch、Darknet、Caffe などの一般的なフレームワークからの事前トレーニングされた深層学習モデルでの推論の実行をサポートします。
このプロジェクトの開発は Python 仮想環境で分離されます。これにより、さまざまなバージョンの依存関係を試すことができます。
virtual environment (virtualenv)インストールするにはさまざまな方法があります。さまざまなプラットフォームの Python 仮想環境: 入門ガイドを参照してください。ただし、ここではいくつかの方法を紹介します。
$ pip install virtualenv$ pip install --upgrade virtualenvこのプロジェクト用に Python 3.6 仮想環境を作成し、virtualenv をアクティブ化します。
$ virtualenv -p python3.6 yoloface
$ source ./yoloface/bin/activate次に、このプロジェクトの依存関係をインストールします。
$ pip install -r requirements.txt$ git clone https://github.com/sthanhng/yoloface顔検出の場合、このリンクから WIDER FACE: A Face Detection Benchmark データセットでトレーニングされた事前トレーニング済み YOLOv3 重みファイルをダウンロードし、 model-weights/ディレクトリに配置する必要があります。
次のコマンドを実行します。
画像入力
$ python yoloface.py --image samples/outside_000001.jpg --output-dir outputs/ビデオ入力
$ python yoloface.py --video samples/subway.mp4 --output-dir outputs/ウェブカメラ
$ python yoloface.py --src 1 --output-dir outputs/
このプロジェクトは MIT ライセンスに基づいてライセンスされています。詳細については、LICENSE.md ファイルを参照してください。


