datmo
1.0.0

| OS | masterでの CI テスト |
|---|---|
Datmo は、データ サイエンティスト向けのオープンソースの実稼働モデル管理ツールです。 datmo init使用して、任意のリポジトリを追跡可能な実験レコードに変えます。独自のクラウドを使用して同期します。
注: Datmo の現在のバージョンはアルファ版です。これは、コマンドが変更され、さらに多くの機能が追加される可能性があることを意味します。バグを見つけた場合は、貢献者が問題に対処できるよう、問題を追加して自由に貢献してください。
コマンド 1 つで環境セットアップ(言語、フレームワーク、パッケージなど)
モデル構成と結果の追跡とログ記録
プロジェクトのバージョン管理(モデル状態の追跡)
実験の再現性(タスクの再実行)
実験履歴の可視化 + エクスポート
(近日公開) 実験を視覚化するためのダッシュボード
| 特徴 | コマンド |
|---|---|
| プロジェクトの初期化 | $ datmo init |
| 新しい環境をセットアップする | $ datmo environment setup |
| 実験を実行する | $ datmo run "python filename.py" |
| 以前の実験を再現する | $ datmo ls (目的のIDを検索)$ datmo rerun EXPERIMENT_ID |
| ワークスペースを開く | $ datmo notebook (Jupyter ノートブック)$ datmo jupyterlab (ジュピターラボ)$ datmo rstudio (RStudio)$ datmo terminal (ターミナル) |
| プロジェクトの状態を記録する (ファイル、コード、環境、構成、統計) | $ datmo snapshot create -m "My first snapshot!" |
| プロジェクトの前の状態に切り替える | $ datmo snapshot ls (目的の ID を検索)$ datmo snapshot checkout SNAPSHOT_ID |
| プロジェクトの実体を視覚化する | $ datmo ls (実験)$ datmo snapshot ls (スナップショット)$ datmo environment ls (環境) |
要件
インストール
こんにちは世界
例
ドキュメント
現在のプロジェクトを変換する
共有
Datmoへの貢献
docker (開始前にインストールおよび実行) : Ubuntu、MacOS、Windows の手順
$ pip install datmo
Hello World ガイドには、環境のセットアップと変更、実験の再現性の表示が含まれています。こちらのドキュメントから入手できます。
/examplesフォルダーには、datmo の感触を得るために実行できるスクリプトがいくつかあります。 「サンプル」に移動すると、サンプルを実行して独自のプロジェクトを開始する方法について詳しく知ることができます。
より高度なチュートリアルについては、こちらの専用チュートリアル リポジトリをご覧ください。
datmo では環境のセットアップが非常に簡単です。初期化中に環境セットアップについて尋ねられたら、単にyと応答するか、いつでもdatmo environment setup使用してください。次に、表示されるプロンプトに従います。
CPU 要求/ドライバーを使用して Python 2.7 TensorFlow をセットアップする一例を以下に示します。 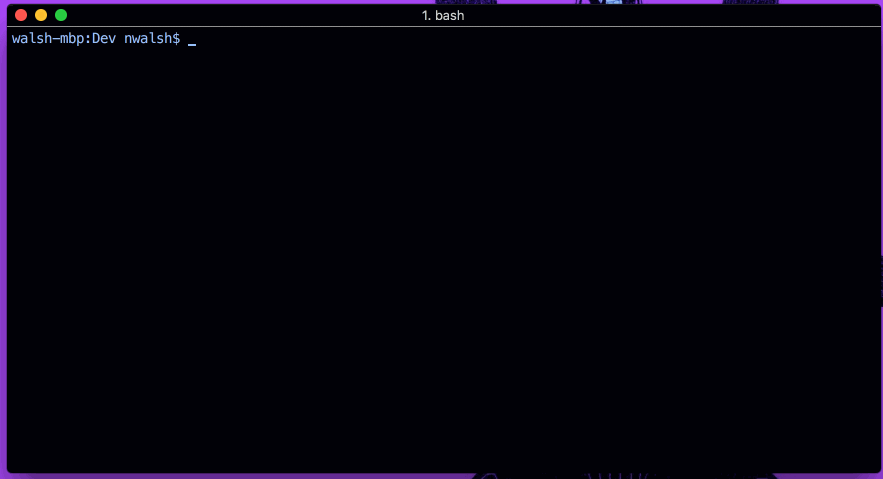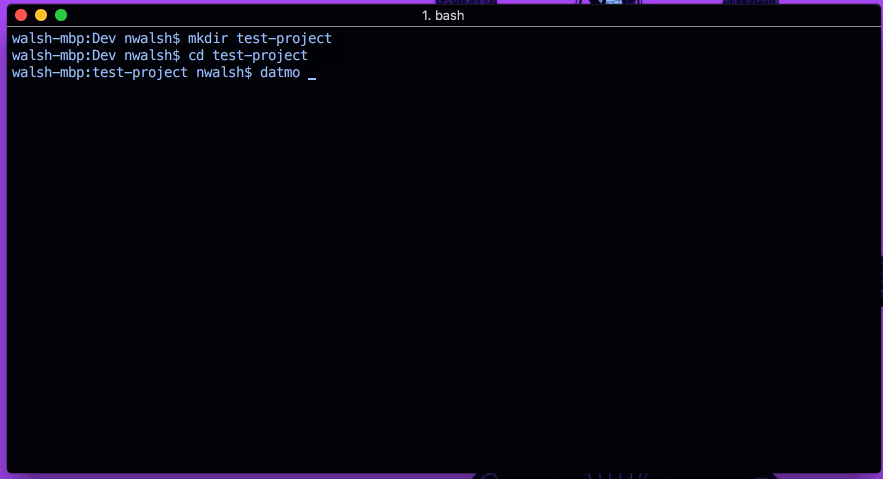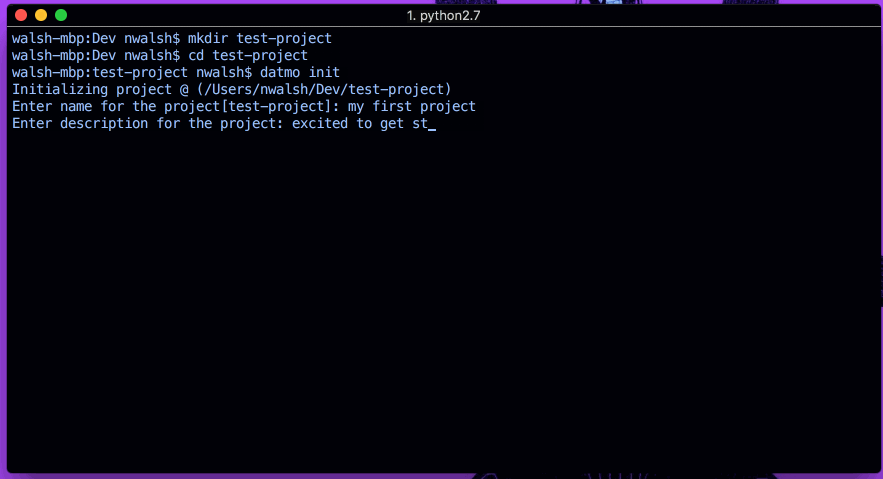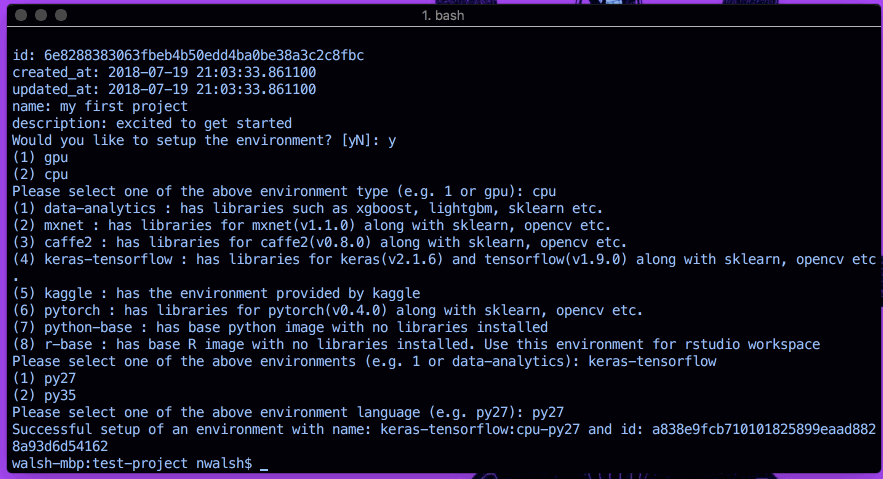
datmo を使用して環境をセットアップするための完全なガイドについては、こちらのドキュメントのこのページを参照してください。
環境をセットアップした後、ほとんどのデータ サイエンティストは、いわゆるワークスペース (IDE またはノートブック プログラミング環境) を開こうとします。
以下に、Jupyter Notebook をすばやく開き、TensorFlow のインポートが意図したとおりに動作していることを示す例を示します。 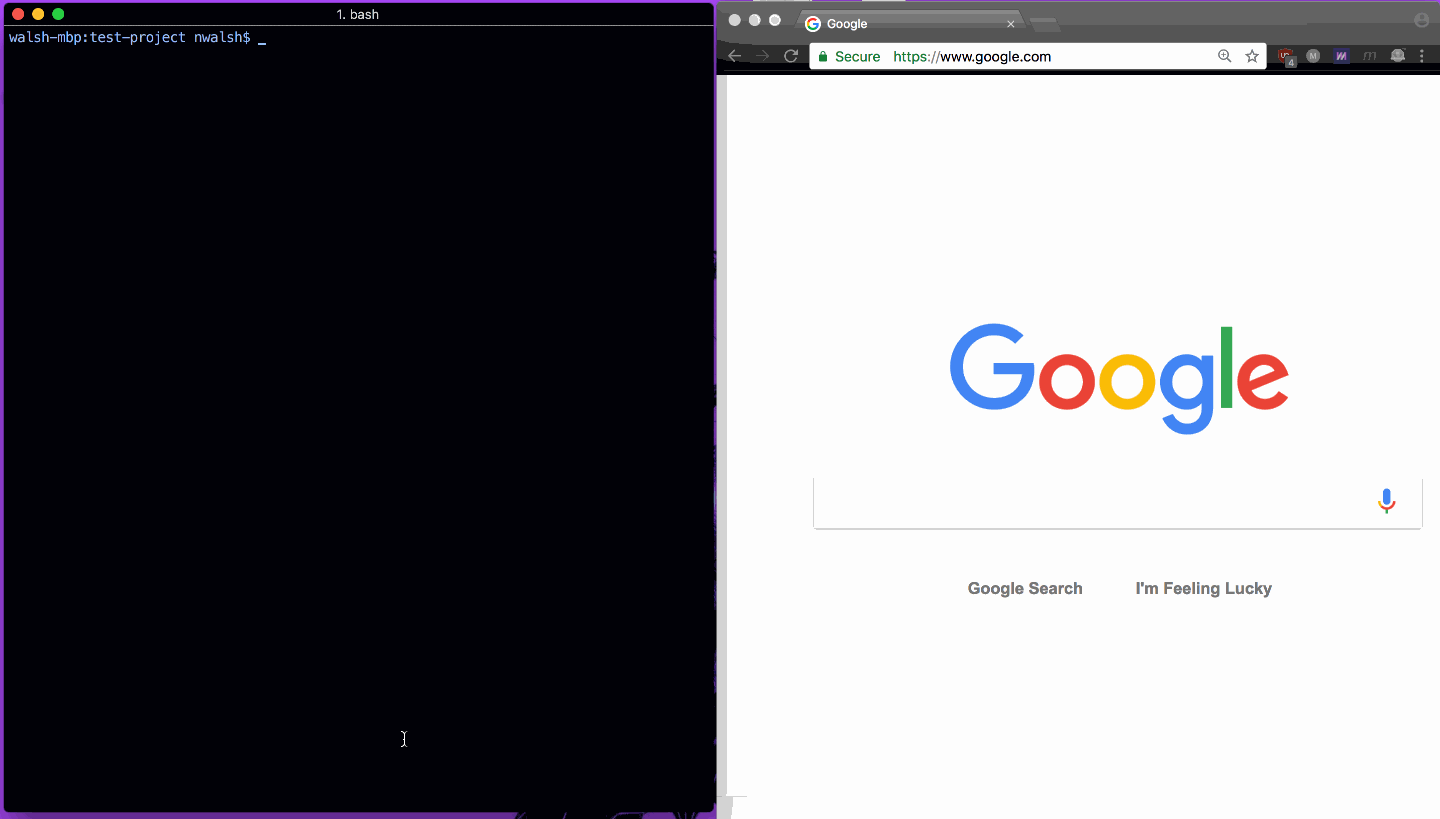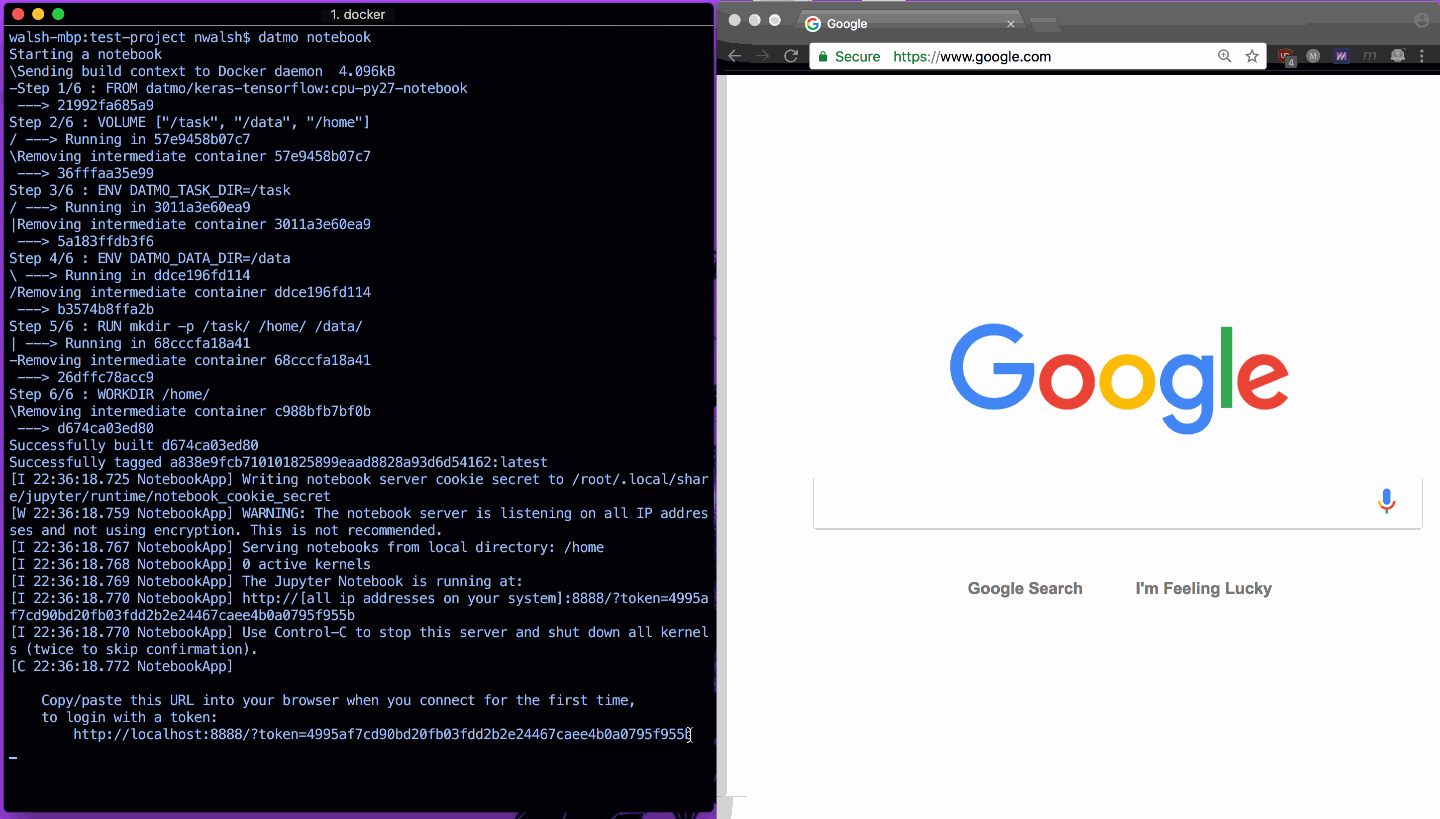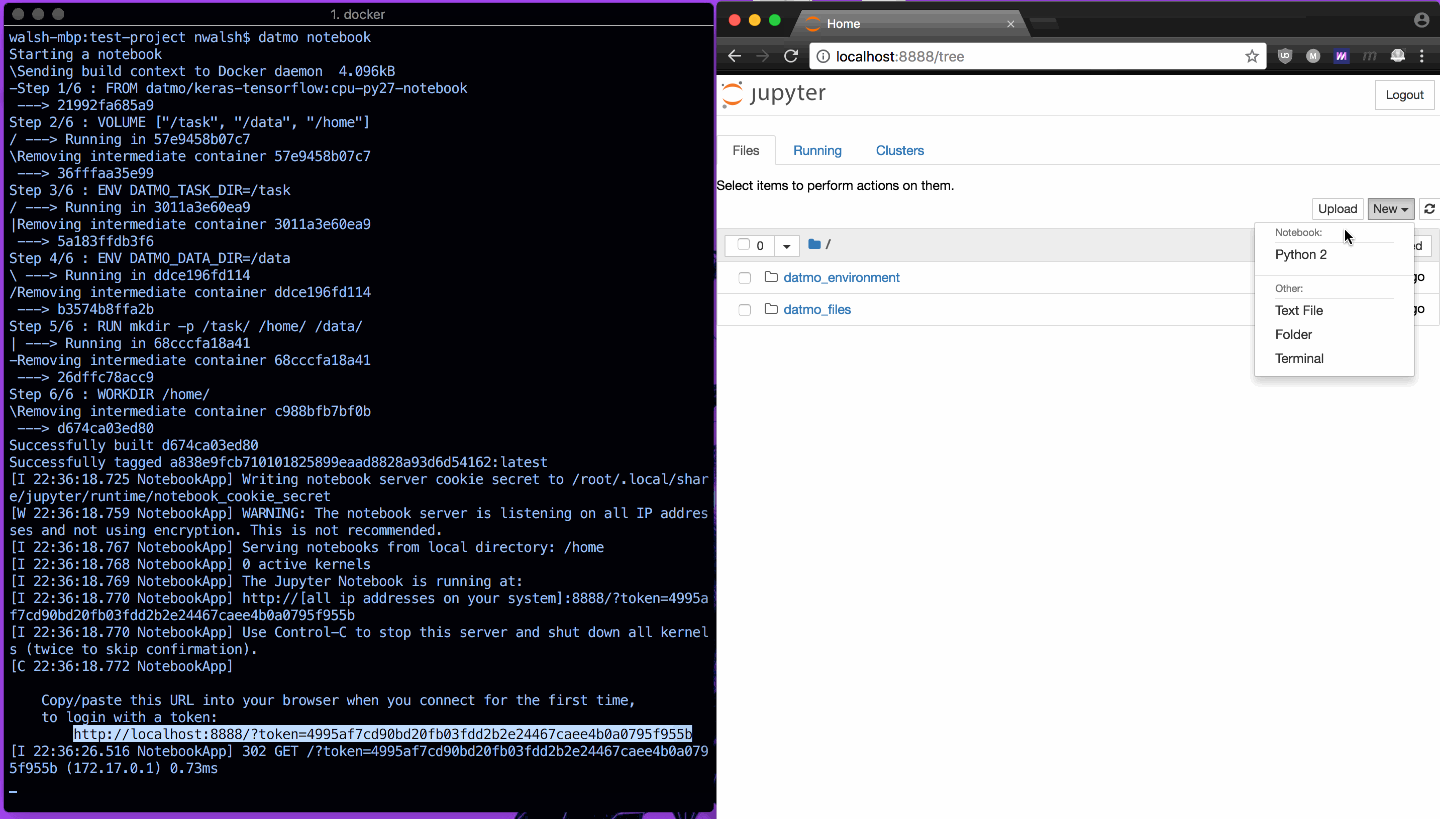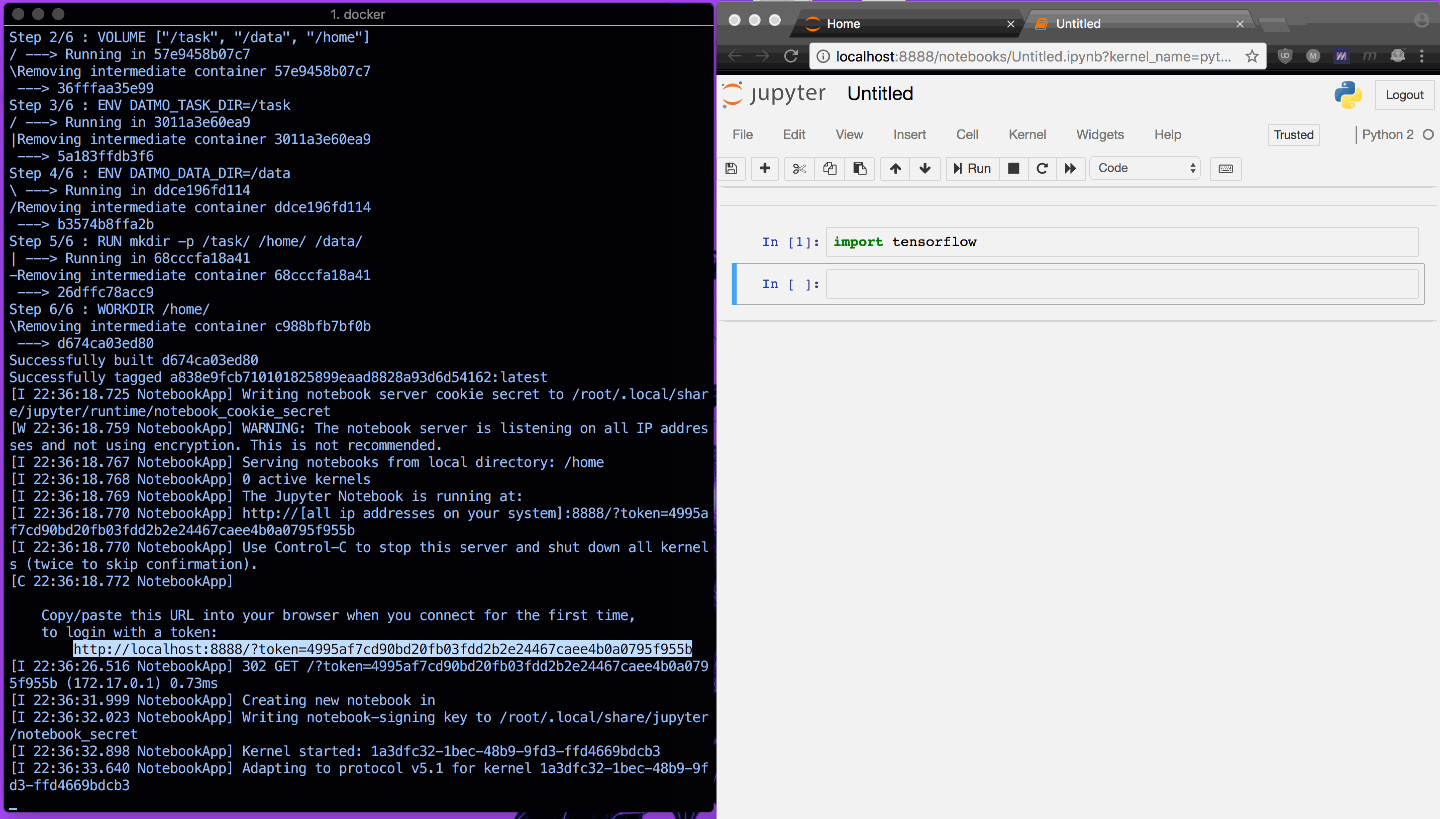
ここでは、一般的なロジスティック回帰モデルと Datmo を活用したモデルの比較を示します。
| 通常のスクリプト | ダトモと |
|---|---|
# train.py#from sklearn import datasetsfrom sklearn import Linear_model as lmfrom sklearn import model_selection as msfrom sklearn import externals as ex######iris_dataset = datasets.load_iris()X = iris_dataset.datay = iris_dataset.targetdata = ms.train_test_split (X, y)X_train、X_test、 y_train, y_test = data#model = lm.LogisticRegression(solver="newton-cg")model.fit(X_train, y_train)ex.joblib.dump(model, 'model.pkl')#train_acc = model.score(X_train) , y_train)test_acc = model.score(X_test, y_test)#print(train_acc)print(test_acc)######### | # train.py#from sklearn import datasetsfrom sklearn import line_model as lmfrom sklearn import model_selection as msfrom sklearn import externals as eximport datmo # extra line#config = {"solver": "newton-cg"} # extra line#iris_dataset = データセット。 load_iris()X = iris_dataset.datay = iris_dataset.targetdata = ms.train_test_split(X, y)X_train, X_test, y_train, y_test = data#model = lm.LogisticRegression(**config)model.fit(X_train, y_train)ex.joblib.dump(model, "model.pkl") #train_acc = model.score(X_train, y_train)test_acc = model.score(X_test, y_test)#stats = {"train_accuracy": train_acc,"test_accuracy": test_acc} # 追加行#datmo.snapshot.create(message="初めてのスナップショット",filepaths=["model.pkl"],config=config, stats=stats) # 追加行 |
上記のコードを実行するには、次のようにします。
プロジェクトのあるディレクトリに移動します
$ mkdir MY_PROJECT $ cd MY_PROJECT
datmo プロジェクトを初期化する
$ datmo init
上記の datmo コードをMY_PROJECTディレクトリのtrain.pyファイルにコピーします。
通常の Python で行うのと同じようにスクリプトを実行します
$ python train.py
おめでとうございます!最初のスナップショットを作成しました:) 次に、スナップショットに対して ls コマンドを実行して、最初のスナップショットを確認します。
$ datmo snapshot ls
datmo init実行すると、Datmo は、実行中のさまざまなエンティティをすべて追跡する非表示の.datmoディレクトリを追加します。これは、リポジトリを datmo 対応にするために必要です。
datmo で可動部分がどのように連携するかを確認するには、ドキュメントの概念ページを参照してください。
完全なドキュメントはここにホストされています。ドキュメント ( /docsにあるソース コード) に貢献したい場合は、 CONTRIBUTING.mdに概説されている手順に従ってください。
次のコマンドを使用して、既存のリポジトリを datmo 対応リポジトリに変換できます。
$ datmo init
datmo を削除したい場合は、リポジトリから.datmoディレクトリを削除するか、次のコマンドを実行します。
$ datmo cleanup
免責事項:これは現在正式にサポートされているオプションではなく、datmo プロジェクトを共有するための回避策として (構成で設定された) ファイルベースのストレージ レイヤーに対してのみ機能します。
datmo はローカルで変更を追跡するように作られていますが、次の手順でリモート サーバーにプッシュすることでプロジェクトを共有できます (これは git についてのみ示されています。別の SCM 追跡ツールを使用している場合は、同様のことができる可能性があります)。ファイルが大きすぎる場合、または SCM に追加できない場合、これは機能しない可能性があります。
以下は BASH 端末のみでテストされています。別の端末を使用している場合は、エラーが発生する可能性があります。
$ git add -f .datmo/* # add in .datmo to your scm $ git commit -m "adding .datmo to tracking" # commit it to your scm $ git push # push to remote $ git push origin +refs/datmo/*:refs/datmo/* # push datmo refs to remote
上記により、datmo の結果とエンティティを自分自身または他のマシン上の他の人と共有できるようになります。注: 他のマシンまたは別の場所で datmo の使用を開始するには、追跡から .datmo/ を削除する必要があります。別の場所に複製する方法については、以下の手順を参照してください。
$ git clone YOUR_REMOTE_URL $ cd YOUR_REPO $ echo '.datmo/*' > .git/info/exclude # include .datmo into your .git exclude $ git rm -r --cached .datmo # remove cached versions of .datmo from scm $ git commit -m "removed .datmo from tracking" # clean up your scm so datmo can work $ git pull origin +refs/datmo/*:refs/datmo/* # pull datmo refs from remote $ datmo init # This enables datmo in the new location. If you enter blanks, no project information will be updated
datmo プロトコルを使用した共有に興味がある場合は、Datmo の Web サイトにアクセスしてください。
Q: datmo stop --allが機能せず、ポートの再割り当てが原因で新しいコンテナを起動できない場合はどうすればよいですか?
A: これは、別の datmo プロジェクトまたは別のコンテナーから実行されているゴースト コンテナーが原因である可能性があります。 特定のポート割り当て (8888 以外) を使用して Docker イメージを作成し、 docker ps --allとdocker conntainer stop <ID>およびdocker container rm <ID>を使用して Docker イメージを見つけて停止し、削除することができます。または、マシン上で実行されているすべてのイメージを停止して削除することもできます [注: これはマシン上の他の docker プロセスに影響を与える可能性があるため、注意して続行してください] docker container stop $(docker ps -a -q)およびdocker container rm $(docker ps -a -q)


