reaver
1.0.0
プロジェクトのステータス:維持されなくなりました。
残念ながら、プロジェクトをさらに開発したりサポートを提供したりすることはできなくなりました。
Reaver は、StarCraft II ベースのさまざまなタスクに焦点を当てたモジュール式の深層強化学習フレームワークであり、人間のようなインターフェイスを備えた最新のビデオ ゲームのプレイというレンズを通してこの分野の最先端を推し進めている DeepMind の足跡をたどっています。制限。これには、人間のプレイヤーが知覚するものと同様の (同一ではないが) 視覚的特徴を観察すること、人間のプレイヤーが持つであろう同様のオプションのプールからアクションを選択することが含まれます。詳細については、「StarCraft II: 強化学習への新たな挑戦」の記事を参照してください。
開発は研究主導ですが、Reaver API の背後にある哲学は StarCraft II ゲーム自体に似ており、この分野の初心者と専門家の両方に提供するものがあります。 Reaver は、趣味のプログラマ向けに、エージェントのごく一部 (ハイパーパラメータなど) を変更するだけで DRL エージェントをトレーニングするために必要なすべてのツールを提供します。ベテラン研究者向けに、Reaver はモジュール式アーキテクチャを備えたシンプルだがパフォーマンスが最適化されたコードベースを提供します。エージェント、モデル、環境は分離されており、自由に交換できます。
Reaver は StarCraft II に重点を置いていますが、他の一般的な環境、特に Atari や MuJoCo も完全にサポートしています。 Reaver エージェントのアルゴリズムは参照結果に対して検証されます。たとえば、PPO エージェントは近接ポリシー最適化アルゴリズムと一致できます。詳細については、以下を参照してください。
Reaver をインストールする最も簡単な方法は、 PIPパッケージ マネージャーを使用することです。
pip install reaver
ヘルパー フラグを使用して追加のエクストラ ( gymサポートなど) をインストールすることもできます。
pip install reaver[gym,atari,mujoco]
Reaverコードベースを変更する予定がある場合は、ソースからインストールすることでモジュールの機能を保持できます。
$ git clone https://github.com/inoryy/reaver-pysc2
$ pip install -e reaver-pysc2/
-eフラグを指定してインストールすると、 Python site-packagesストレージではなく、指定されたフォルダーでreaverを検索するようになります。
Windows 上で Reaver をセットアップする詳細な手順については、wiki ページを参照してください。
ただし、パフォーマンスと安定性を考慮して、可能であれば代わりにLinux OSの使用を検討してください。フルグラフィックスを有効にしてエージェントの実行を確認したい場合は、エージェントのリプレイを Linux に保存し、Windows で開くことができます。このようにして、以下のビデオ録画が作成されました。
他のサポートされている環境で Reaver を使用したい場合は、関連するパッケージもインストールする必要があります。
たった 4 行のコードで、複数の StarCraft II 環境を並行して実行して DRL エージェントをトレーニングできます。
import reaver as rvr
env = rvr . envs . SC2Env ( map_name = 'MoveToBeacon' )
agent = rvr . agents . A2C ( env . obs_spec (), env . act_spec (), rvr . models . build_fully_conv , rvr . models . SC2MultiPolicy , n_envs = 4 )
agent . run ( env )さらに、Reaver には高度に構成可能なコマンドライン ツールが付属しているため、このタスクは短いワンライナーに短縮できます。
python -m reaver.run --env MoveToBeacon --agent a2c --n_envs 4 2> stderr.log上記の行により、Reaver は、特定の環境とエージェント向けに特別に最適化された、事前定義されたハイパーパラメーターのセットを使用してトレーニング手順を初期化します。しばらくすると、ターミナル画面にさまざまな有用な統計を含むログが表示され始めます。
| T 118 | Fr 51200 | Ep 212 | Up 100 | RMe 0.14 | RSd 0.49 | RMa 3.00 | RMi 0.00 | Pl 0.017 | Vl 0.008 | El 0.0225 | Gr 3.493 | Fps 433 |
| T 238 | Fr 102400 | Ep 424 | Up 200 | RMe 0.92 | RSd 0.97 | RMa 4.00 | RMi 0.00 | Pl -0.196 | Vl 0.012 | El 0.0249 | Gr 1.791 | Fps 430 |
| T 359 | Fr 153600 | Ep 640 | Up 300 | RMe 1.80 | RSd 1.30 | RMa 6.00 | RMi 0.00 | Pl -0.035 | Vl 0.041 | El 0.0253 | Gr 1.832 | Fps 427 |
...
| T 1578 | Fr 665600 | Ep 2772 | Up 1300 | RMe 24.26 | RSd 3.19 | RMa 29.00 | RMi 0.00 | Pl 0.050 | Vl 1.242 | El 0.0174 | Gr 4.814 | Fps 421 |
| T 1695 | Fr 716800 | Ep 2984 | Up 1400 | RMe 24.31 | RSd 2.55 | RMa 30.00 | RMi 16.00 | Pl 0.005 | Vl 0.202 | El 0.0178 | Gr 56.385 | Fps 422 |
| T 1812 | Fr 768000 | Ep 3200 | Up 1500 | RMe 24.97 | RSd 1.89 | RMa 31.00 | RMi 21.00 | Pl -0.075 | Vl 1.385 | El 0.0176 | Gr 17.619 | Fps 423 |
Reaver はすぐに約 25 ~ 26 RMe (エピソード報酬の平均) に収束するはずで、これはこの環境での DeepMind の結果と一致します。具体的なトレーニング時間はハードウェアによって異なります。上記のログは、Intel i5-7300HQ CPU (4 コア) と GTX 1050 GPU を搭載したラップトップで生成され、トレーニングには約 30 分かかりました。
Reaver のトレーニングが終了したら、ワンライナーに--testフラグと--renderフラグを追加することで、Reaver のパフォーマンスを確認できます。
python -m reaver.run --env MoveToBeacon --agent a2c --test --render 2> stderr.logReaver をオンラインで試すには、付属の Google Colab ノートブックを使用できます。
最新の DRL アルゴリズムの多くは、複数の環境で同時に並行して実行されることに依存しています。 Python には GIL があるため、この機能はマルチプロセッシングを通じて実装する必要があります。オープンソース実装の多くは、メッセージベースのアプローチ (例: Python multiprocessing.PipeまたはMPI ) でこのタスクを解決し、個々のプロセスが IPC を介してデータを送信することで通信します。これは、DeepMind や openAI などの企業が運営する大規模な分散アプローチにとって有効であり、おそらく唯一合理的なアプローチです。
ただし、典型的な研究者や愛好家にとっては、ラップトップであっても HPC クラスター上のノードであっても、単一のマシン環境にのみアクセスできるというシナリオがはるかに一般的です。 Reaver は、ロックフリーの方法で共有メモリを利用することで、このケースに特化して最適化されています。このアプローチにより、StarCraft II サンプリング レートで最大1.5 倍の高速化(一般的な場合は最大 100 倍の高速化) という大幅なパフォーマンス向上が実現しますが、ボトルネックとなっているのはほぼ GPU 入出力パイプラインだけです。
3 つのコア Reaver モジュール ( envs 、 models 、およびagentsは、互いにほぼ完全に分離されています。これにより、1 つのモジュールの拡張機能が他のモジュールにシームレスに統合されます。
すべての設定は gin-config を通じて処理され、 .ginファイルとして簡単に共有できます。これには、すべてのハイパーパラメータ、環境引数、モデル定義が含まれます。
新しいアイデアを実験するときは、フィードバックを迅速に得ることが重要ですが、StarCraft II のような複雑な環境では現実的ではないことがよくあります。 Reaver はモジュラー アーキテクチャで構築されているため、そのエージェント実装は実際には StarCraft II にまったく関連付けられていません。多くの人気のあるゲーム環境 (たとえば、 openAI gym ) のドロップイン置換を作成し、最初に実装がそれらの環境で動作することを確認できます。
python -m reaver.run --env CartPole-v0 --agent a2c 2> stderr.log import reaver as rvr
env = rvr . envs . GymEnv ( 'CartPole-v0' )
agent = rvr . agents . A2C ( env . obs_spec (), env . act_spec ())
agent . run ( env )現在、Reaver では次の環境がサポートされています。
CartPole-v0でテスト済み)PongNoFrameskip-v0でテスト済み)InvertedPendulum-v2およびHalfCheetah-v2でテスト済み) | 地図 | リーバー (A2C) | ディープマインド SC2LE | ディープマインド ReDRL | 人間の専門家 |
|---|---|---|---|---|
| ビーコンへ移動 | 26.3(1.8) [21、31] | 26 | 27 | 28 |
| ミネラルシャードを集める | 102.8(10.8) [81、135] | 103 | 196 | 177 |
| ゴキブリを倒す | 72.5(43.5) [21、283] | 100 | 303 | 215 |
| ザーグリングを見つけて倒す | 22.1 (3.6) [12、40] | 45 | 62 | 61 |
| ザーグリングとバネリングを倒す | 56.8(20.8) [21、154] | 62 | 736 | 727 |
| ミネラルとガスを集める | 2267.5 (488.8) [0, 3320] | 3,978 | 5,055 | 7,566 |
| ビルドマリーンズ | -- | 3 | 123 | 133 |
Human Expert結果は、グランドマスター レベルのプレーヤーから DeepMind によって収集されました。DeepMind ReDRL 、リレーショナル深層強化学習の記事で説明されている現在の最先端の結果を指します。DeepMind SC2LE 、「StarCraft II: 強化学習への新しい挑戦」の記事で公開された結果です。Reaver (A2C) reaver.agents.A2Cエージェントをトレーニングすることによって収集された結果であり、利用可能なハードウェア上でSC2LEアーキテクチャを可能な限り厳密に複製します。結果は、トレーニングされたエージェントを--testモードで100エピソードに対して実行し、エピソードの合計報酬を計算することによって収集されます。平均、標準偏差 (括弧内)、最小値と最大値 (角括弧内) がリストされています。| 地図 | サンプル | エピソード | 約時間 (時間) |
|---|---|---|---|
| ビーコンへ移動 | 563,200 | 2,304 | 0.5 |
| ミネラルシャードを集める | 74,752,000 | 311,426 | 50 |
| ゴキブリを倒す | 172,800,000 | 1,609,211 | 150 |
| ザーグリングを見つけて倒す | 29,760,000 | 89,654 | 20 |
| ザーグリングとバネリングを倒す | 10,496,000 | 273,463 | 15 |
| ミネラルとガスを集める | 16,864,000 | 20,544 | 10 |
| ビルドマリーンズ | - | - | - |
Samples 1 つの環境におけるobserve -> step -> rewardチェーンの合計数を指します。Episodes PySC2 によって返されるStepType.LASTフラグの総数を指します。Approx. Time 、Intel i5-7300HQ CPU (4 コア) とGTX 1050 GPU を搭載したlaptopでのおおよそのトレーニング時間です。ハイパーパラメータの調整にはあまり時間をかけず、サンプル効率を最大化することよりもエージェントが学習できるかどうかを確認することに主に重点を置いていることに注意してください。たとえば、 MoveToBeaconを単純に試してみたところ、約 400 万サンプルが必要でしたが、少し試してみたところ、PPO エージェントを使用してサンプルを 102,000 (約 40 倍の削減) まで減らすことができました。
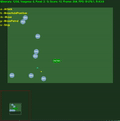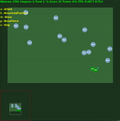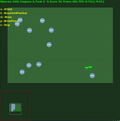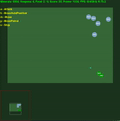
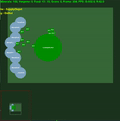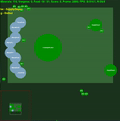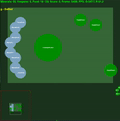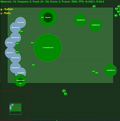
中間に std.dev が埋め込まれた平均エピソード報酬。クリックすると拡大します。
6 つのミニゲームすべてでエージェントが実行するビデオ録画は、https://youtu.be/gEyBzcPU5-w からオンラインで入手できます。左側のビデオでは、エージェントがランダムに初期化された重みを使用してトレーニングなしで動作していますが、右側のビデオでは、スコアを目標にするようにトレーニングされています。
研究の再現性の問題は、最近科学全般で多くの議論の対象となっており、強化学習も例外ではありません。科学プロジェクトとしての Reaver の目標の 1 つは、再現可能な研究を促進することです。この目的のために、Reaver にはプロセスを簡素化するさまざまなツールがバンドルされています。
再現性をリードするために、Reaver には、6 つのミニゲームすべてに対する事前トレーニング済みの重みと完全な Tensorboard サマリー ログがバンドルされています。 [リリース] タブから実験アーカイブをダウンロードし、 results/ディレクトリに解凍するだけです。
--experimentフラグをreaver.runコマンドに追加することで、事前トレーニングされた重みを使用できます。
python reaver.run --map <map_name> --experiment <map_name>_reaver --test 2> stderr.log
tensorboard --logidr=results/summariesを起動すると、Tensorboard ログが利用可能になります。
オーギーボードを介してオンラインで直接表示することもできます。
Reaver は、StarCraft ゲームの世界で非常に特別で主観的にかわいい Protoss ユニットです。ゲームの StarCraft: Brood War バージョンでは、リーバーは遅くて不器用で、バグのあるゲーム内 AI のせいで放っておくとほとんど役に立たないことがよくあることで悪名を得ていました。しかし、ユニットの習得に時間を費やした熱心なプレイヤーの手によって、リーバーはゲーム内で最も強力な資産の 1 つとなり、トーナメントで優勝するゲームで重要な役割を果たすことがよくありました。
Reaver の前身であるpysc2-rl-agent 、Ilya Kuzovkin と Tambet Matiisen の監督のもと、タルトゥ大学で学士論文の実践的な部分として開発されました。 v1.0 ブランチでは引き続きアクセスできます。
コードベース関連の問題が発生した場合は、GitHub でチケットを開き、できるだけ詳しく説明してください。もっと一般的な質問がある場合、または単にアドバイスが必要な場合は、お気軽にメールを送ってください。
私はまた、アクティブでフレンドリーな SC2AI オンライン コミュニティのメンバーであることを誇りに思っています。コミュニケーションには主に Discord を使用しています。あらゆる背景や専門レベルの人々が参加することを歓迎します。
Reaver が研究に役立つと思われた場合は、次の bibtex で引用することを検討してください。
@misc{reaver,
author = {Ring, Roman},
title = {Reaver: Modular Deep Reinforcement Learning Framework},
year = {2018},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/inoryy/reaver}},
}


