RoboFlamingo
1.0.0
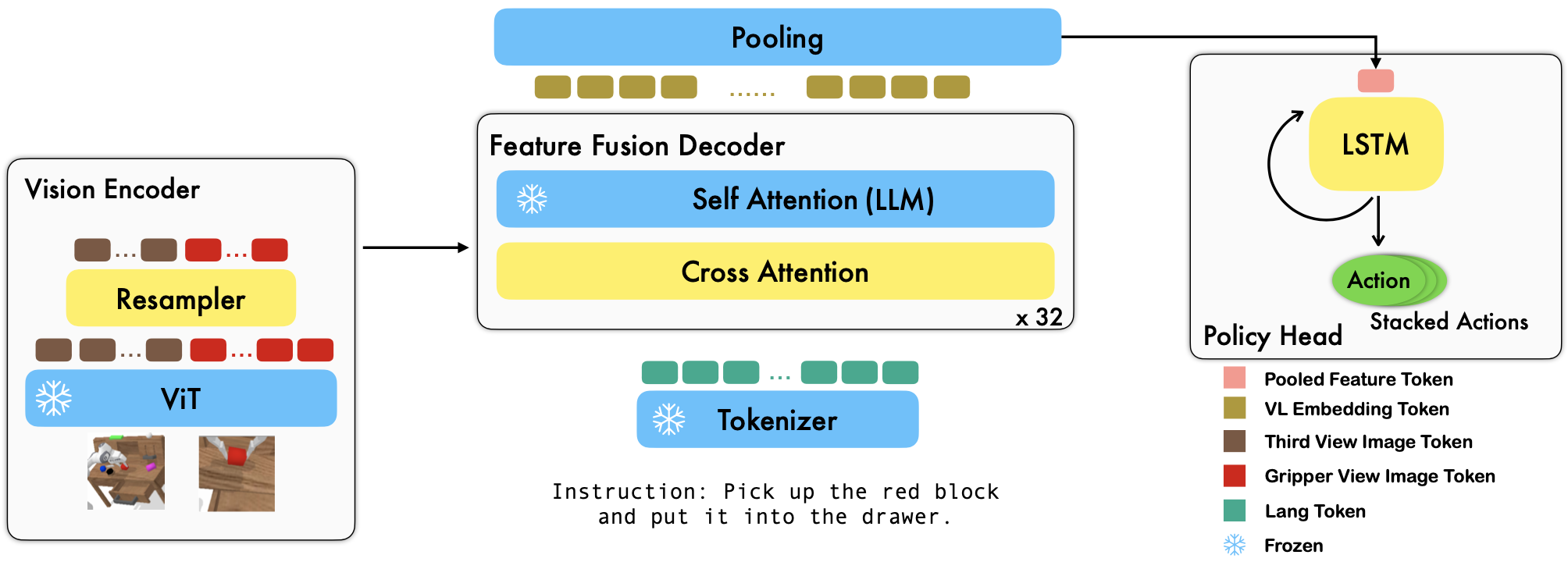
RoboFlamingoは、オフラインの自由形式模倣データセットを微調整することで、言語条件付きのさまざまなロボット スキルを学習する、事前トレーニング済みの VLM ベースのロボット学習フレームワークです。 CALVIN ベンチマークで最先端のパフォーマンスを大幅に上回り、RoboFlamingo が VLM をロボット制御に適応させるための効果的で競争力のある代替手段となり得ることを示しています。私たちの広範な実験結果は、操作タスクにおけるさまざまな事前トレーニング済み VLM の動作に関するいくつかの興味深い結論も明らかにしています。 RoboFlamingo は、単一の GPU サーバー上でトレーニングまたは評価できます(GPU メモリ要件はモデルのサイズによって異なります)。RoboFlamingo は、コスト効率が高く、使いやすいロボット操作ソリューションとなる可能性があり、誰もが独自のロボット工学ポリシーを微調整する能力。
これは、論文「効果的なロボット模倣者としての視覚言語基盤モデル」の公式コード リポジトリでもあります。
すべての実験は、8 つの Nvidia A100 GPU (80G) を備えた単一の GPU サーバーで実行されます。
事前トレーニング済みモデルは Hugging Face で入手できます。
OpenAI の事前トレーニング済みモデルを含む OpenCLIP パッケージの事前トレーニング済みビジョン エンコーダーをサポートしています。 MPT、RedPajama、LLaMA、OPT、GPT-Neo、GPT-J、Pythia モデルなど、 transformersパッケージの事前トレーニング済み言語モデルもサポートしています。
from robot_flamingo . factor import create_model_and_transforms
model , image_processor , tokenizer = create_model_and_transforms (
clip_vision_encoder_path = "ViT-L-14" ,
clip_vision_encoder_pretrained = "openai" ,
lang_encoder_path = "PATH/TO/LLM/DIR" ,
tokenizer_path = "PATH/TO/LLM/DIR" ,
cross_attn_every_n_layers = 1 ,
decoder_type = 'lstm' ,
) cross_attn_every_n_layers引数は、クロスアテンション レイヤーが適用される頻度を制御し、VLM と一致する必要があります。 decoder_type引数はデコーダのタイプを制御します。現在、 lstm 、 fc 、 diffusion (データローダーにバグが存在します)、およびGPTサポートしています。
CALVIN ベンチマークの結果を報告します。
| 方法 | トレーニングデータ | テスト分割 | 1 | 2 | 3 | 4 | 5 | 平均レン |
|---|---|---|---|---|---|---|---|---|
| MCIL | ABCD (フル) | D | 0.373 | 0.027 | 0.002 | 0.000 | 0.000 | 0.40 |
| ハルク | ABCD (フル) | D | 0.889 | 0.733 | 0.587 | 0.475 | 0.383 | 3.06 |
| ハルク(再訓練済み) | ABCD (ラング) | D | 0.892 | 0.701 | 0.548 | 0.420 | 0.335 | 2.90 |
| RT-1 (再訓練済み) | ABCD (ラング) | D | 0.844 | 0.617 | 0.438 | 0.323 | 0.227 | 2.45 |
| 私たちのもの | ABCD (ラング) | D | 0.964 | 0.896 | 0.824 | 0.740 | 0.66 | 4.09 |
| MCIL | ABC (フル) | D | 0.304 | 0.013 | 0.002 | 0.000 | 0.000 | 0.31 |
| ハルク | ABC (フル) | D | 0.418 | 0.165 | 0.057 | 0.019 | 0.011 | 0.67 |
| RT-1 (再訓練済み) | ABC (ラング) | D | 0.533 | 0.222 | 0.094 | 0.038 | 0.013 | 0.90 |
| 私たちのもの | ABC (ラング) | D | 0.824 | 0.619 | 0.466 | 0.331 | 0.235 | 2.48 |
| ハルク | ABCD (フル) | D(充実) | 0.715 | 0.470 | 0.308 | 0.199 | 0.130 | 1.82 |
| RT-1 (再訓練済み) | ABCD (ラング) | D(充実) | 0.494 | 0.222 | 0.086 | 0.036 | 0.017 | 0.86 |
| 私たちのもの | ABCD (ラング) | D(充実) | 0.720 | 0.480 | 0.299 | 0.211 | 0.144 | 1.85 |
| 私たちのもの (フリーズエンブ) | ABCD (ラング) | D(充実) | 0.737 | 0.530 | 0.385 | 0.275 | 0.192 | 2.12 |
OpenFlamingo と CALVIN の手順に従って、必要なデータセットと VLM 事前トレーニング済みモデルをダウンロードします。
CALVIN データセットをダウンロードし、次の分割を選択します。
cd $HULC_ROOT /dataset
sh download_data.sh D | ABC | ABCD | debugリリースされた OpenFlamingo モデルをダウンロードします。
| # パラメータ | 言語モデル | ビジョンエンコーダ | Xattn間隔* | COCO 4ショットサイダー | VQAv2 4 ショット精度 | 平均レン | 重み |
|---|---|---|---|---|---|---|---|
| 3B | anas-awadalla/mpt-1b-redpajama-200b | オープンアイクリップ ViT-L/14 | 1 | 77.3 | 45.8 | 3.94 | リンク |
| 3B | anas-awadalla/mpt-1b-redpajama-200b-dolly | オープンアイクリップ ViT-L/14 | 1 | 82.7 | 45.7 | 4.09 | リンク |
| 4B | togethercomputer/RedPajama-INCITE-Base-3B-v1 | オープンアイクリップ ViT-L/14 | 2 | 81.8 | 49.0 | 3.67 | リンク |
| 4B | togethercomputer/RedPajama-INCITE-Instruct-3B-v1 | オープンアイクリップ ViT-L/14 | 2 | 85.8 | 49.0 | 3.79 | リンク |
| 9B | アナス・アワダラ/mpt-7b | オープンアイクリップ ViT-L/14 | 4 | 89.0 | 54.8 | 3.97 | リンク |
各事前トレーニング済み VLM のrobot_flamingo/models/factory.py内のパス ディクショナリ (例: mpt_dict ) の${lang_encoder_path}と${tokenizer_path}独自のパスに置き換えます。
このリポジトリのクローンを作成します
git clone https://github.com/RoboFlamingo/RoboFlamingo.git
必要なパッケージをインストールします。
cd RoboFlamingo
conda create -n RoboFlamingo python=3.8
source activate RoboFlamingo
pip install -r requirements.txt
torchrun --nnodes=1 --nproc_per_node=8 --master_port=6042 robot_flamingo/train/train_calvin.py
--report_to_wandb
--llm_name mpt_dolly_3b
--traj_cons
--use_gripper
--fusion_mode post
--rgb_pad 10
--gripper_pad 4
--precision fp32
--num_epochs 5
--gradient_accumulation_steps 1
--batch_size_calvin 6
--run_name RobotFlamingoDBG
--calvin_dataset ${calvin_dataset_path}
--lm_path ${lm_path}
--tokenizer_path ${tokenizer_path}
--openflamingo_checkpoint ${openflamingo_checkpoint}
--cross_attn_every_n_layers 4
--dataset_resampled
--loss_multiplier_calvin 1.0
--workers 1
--lr_scheduler constant
--warmup_steps 5000
--learning_rate 1e-4
--save_every_iter 10000
--from_scratch
--window_size 12 > ${log_file} 2>&1
${calvin_dataset_path} CALVIN データセットへのパスです。
${lm_path}事前トレーニングされた LLM へのパスです。
${tokenizer_path} VLM トークナイザーへのパスです。
${openflamingo_checkpoint} OpenFlamingo の事前トレーニング済みモデルへのパスです。
${log_file}ログ ファイルへのパスです。
トレーニングを開始するためのrobot_flamingo/pt_run_gripper_post_ws_12_traj_aug_mpt_dolly_3b.bashも提供します。この bash は、OpenFlamingo モデルのMPT-3B-IFTバージョンを微調整します。これには、モデルをトレーニングするためのデフォルトのハイパーパラメーターが含まれており、論文内の最良の結果に対応します。
python eval_ckpts.py
チェックポイント名とディレクトリをeval_ckpts.pyに追加すると、スクリプトはモデルを自動的にロードして評価します。たとえば、パス「your-checkpoint-path」のチェックポイントを評価する場合、eval_ckpts.py のckpt_dir変数とckpt_names変数を変更すると、評価結果が「logs/your-checkpoint-prefix」として保存されます。ログ'。
以下に示す結果は、共同トレーニングにより、VL タスクでは VLM バックボーンのほとんどの能力が維持されるが、ロボット タスクではパフォーマンスが若干失われることを示しています。
使用
bash robot_flamingo/pt_run_gripper_post_ws_12_traj_aug_mpt_dolly_3b_co_train.bash
RoboFlamingo を CoCO、VQAV2、CALVIN と共同トレーニングするために立ち上げます。 robot_flamingo/data/data.pyのget_coco_datasetおよびget_vqa_datasetの CoCO パスと VQA パスを更新する必要があります。
| スプリット | SR1 | SR2 | SR3 | SR4 | SR5 | 平均レン |
|---|---|---|---|---|---|---|
| 共同トレーニング | ABC->D | 82.9% | 63.6% | 45.3% | 32.1% | 23.4% |
| 微調整 | ABC->D | 82.4% | 61.9% | 46.6% | 33.1% | 23.5% |
| 共同トレーニング | ABCD->D | 95.7% | 85.8% | 73.7% | 64.5% | 56.1% |
| 微調整 | ABCD->D | 96.4% | 89.6% | 82.4% | 74.0% | 66.2% |
| 共同トレーニング | ABCD->D (充実) | 67.8% | 45.2% | 29.4% | 18.9% | 11.7% |
| 微調整 | ABCD->D (充実) | 72.0% | 48.0% | 29.9% | 21.1% | 14.4% |
| ココ | VQA | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| ブルー-1 | ブルー-2 | ブルー-3 | ブルー-4 | 流星 | ルージュ_L | サイダー | スパイス | ACC | |
| 微調整(3B、ゼロショット) | 0.156 | 0.051 | 0.018 | 0.007 | 0.038 | 0.148 | 0.004 | 0.006 | 4.09 |
| 微調整(3B、4ショット) | 0.166 | 0.056 | 0.020 | 0.008 | 0.042 | 0.158 | 0.004 | 0.008 | 3.87 |
| コ・トレイン(3B、ゼロショット) | 0.225 | 0.158 | 0.107 | 0.072 | 0.124 | 0.334 | 0.345 | 0.085 | 36.37 |
| オリジナルフラミンゴ (80B、微調整) | - | - | - | - | - | - | 1.381 | - | 82.0 |
ロゴは MidJourney を使用して生成されます
この作業では、次のオープンソース プロジェクトとデータセットのコードを使用します。
原文: https://github.com/mees/calvin ライセンス: MIT
オリジナル: https://github.com/openai/CLIP ライセンス: MIT
原文: https://github.com/mlfoundations/open_flamingo ライセンス: MIT
@article{li2023vision,
title = {Vision-Language Foundation Models as Effective Robot Imitators},
author = {Li, Xinghang and Liu, Minghuan and Zhang, Hanbo and Yu, Cunjun and Xu, Jie and Wu, Hongtao and Cheang, Chilam and Jing, Ya and Zhang, Weinan and Liu, Huaping and Li, Hang and Kong, Tao},
journal={arXiv preprint arXiv:2311.01378},
year={2023}


