RobustSAM
1.0.0
RobustSAM の公式リポジトリ: 劣化したイメージ上のあらゆるものを堅牢にセグメント化する
プロジェクトページ |紙 |ビデオ |データセット
2024 年 8 月: @jadechoghari が作成した Hugging Face モデル カードとデモを簡単に使用できるように、このリンクから参照できます。
2024 年 7 月: さまざまな ViT バックボーンのトレーニング コード、データ、モデル チェックポイントがリリースされました。
2024 年 6 月: 推論コードが公開されました。
2024 年 2 月: RobustSAM が CVPR 2024 に承認されました。
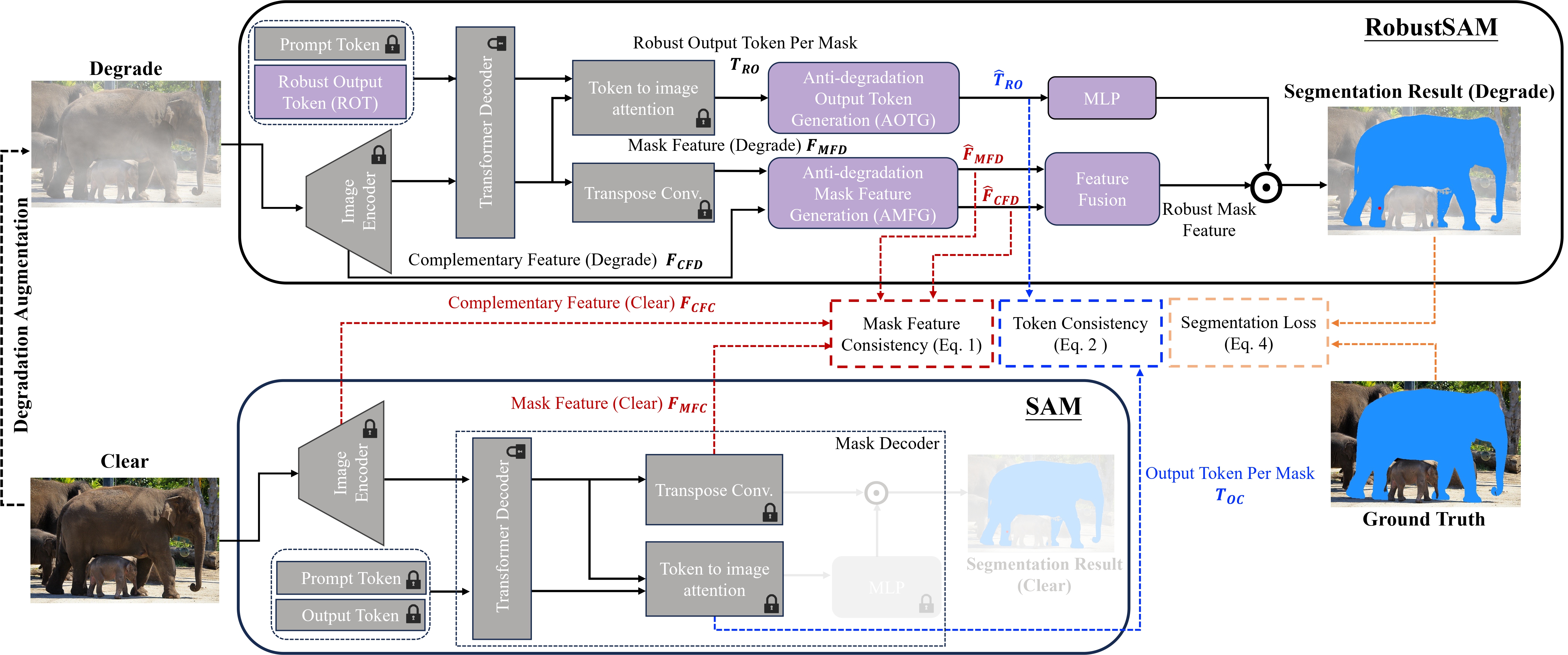
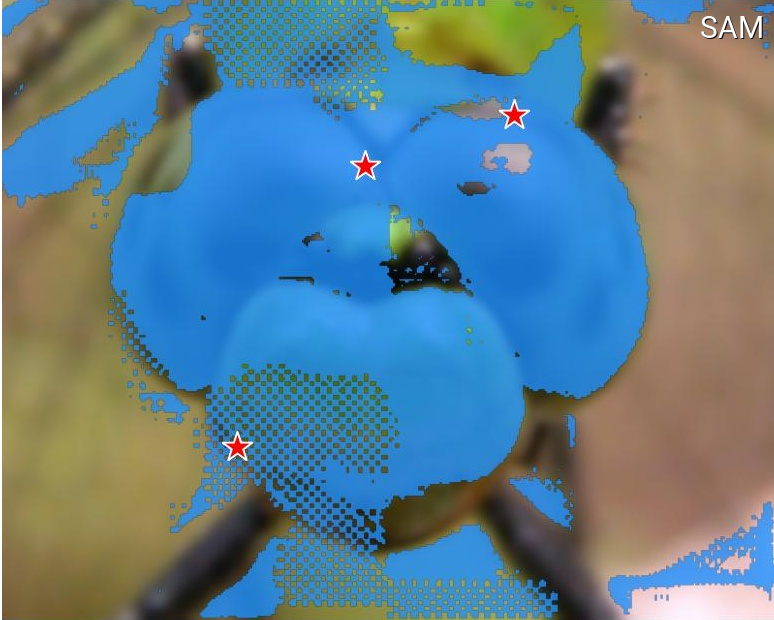
Segment Anything Model (SAM) は、画像セグメンテーションにおける革新的なアプローチとして登場し、その堅牢なゼロショット セグメンテーション機能と柔軟なプロンプト システムが高く評価されています。それにもかかわらず、画質が低下した画像によってそのパフォーマンスが低下します。この制限に対処するために、私たちはロバスト セグメント エニシング モデル (RobustSAM) を提案します。これは、即時性とゼロショット一般化を維持しながら、低品質画像での SAM のパフォーマンスを強化します。
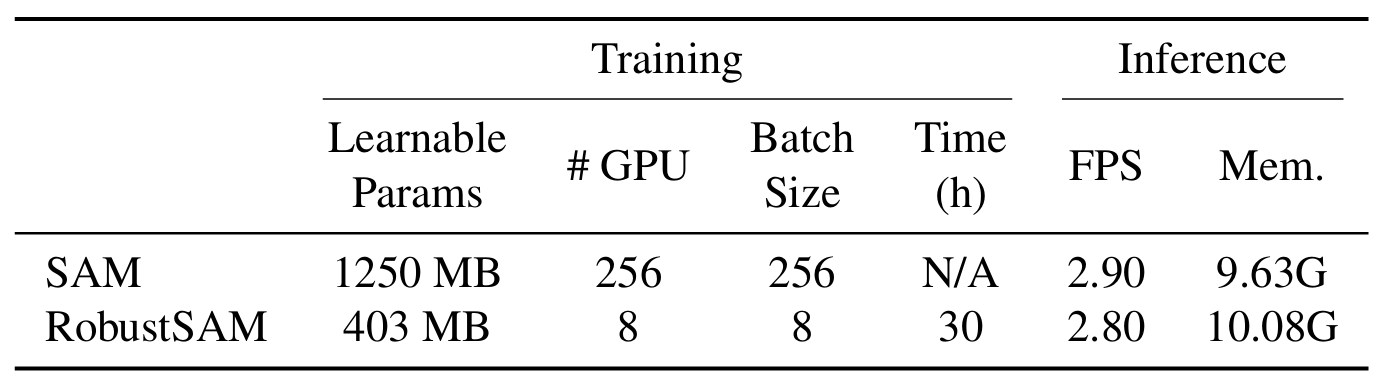
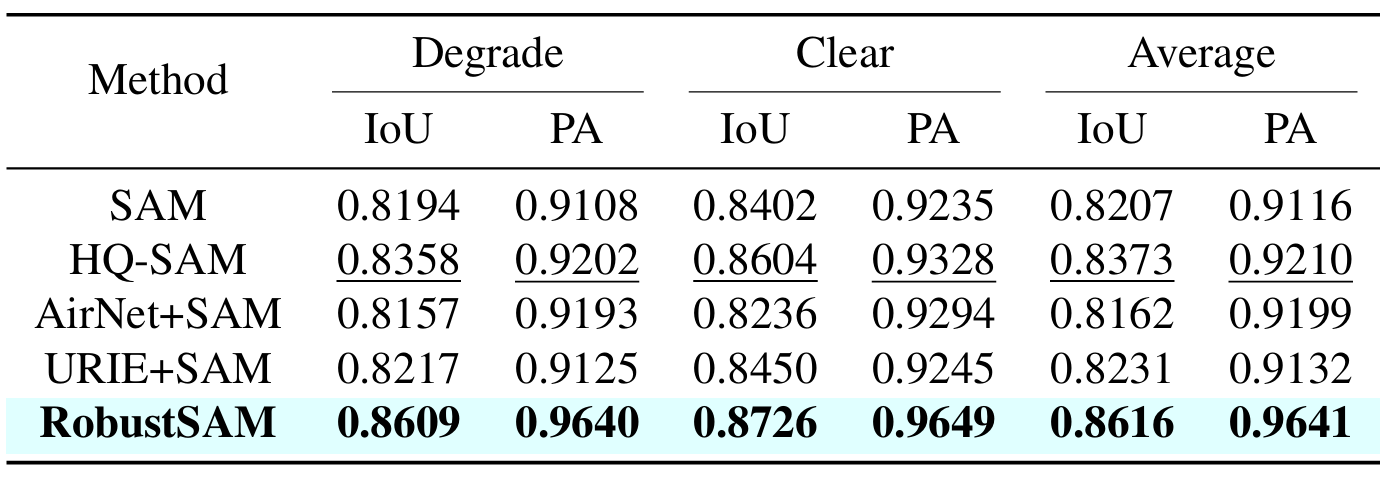
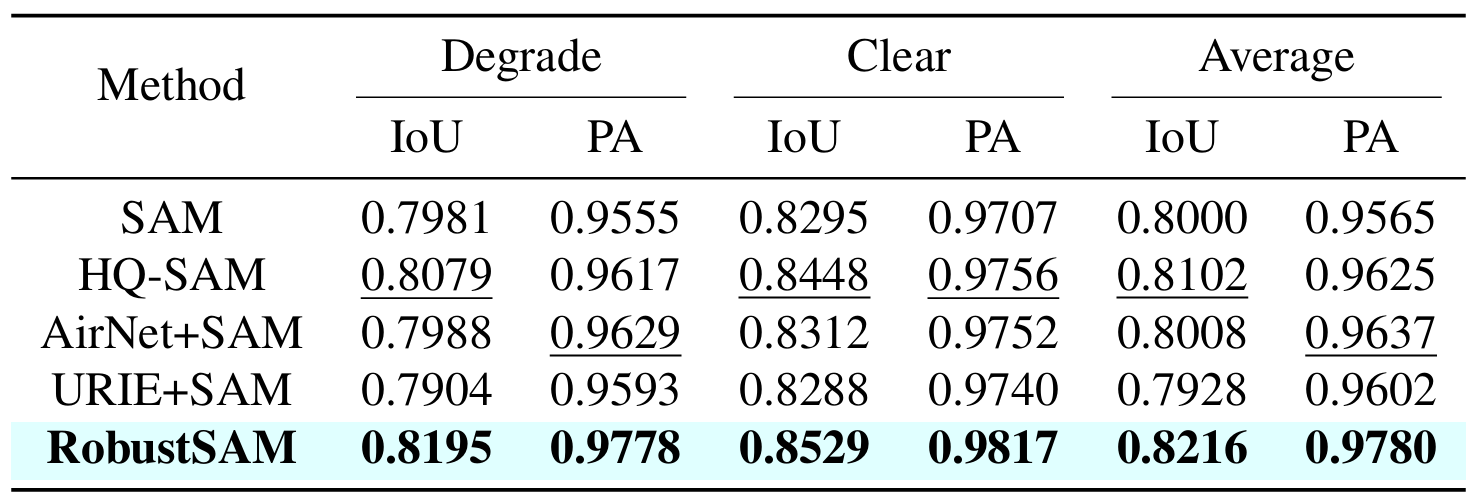
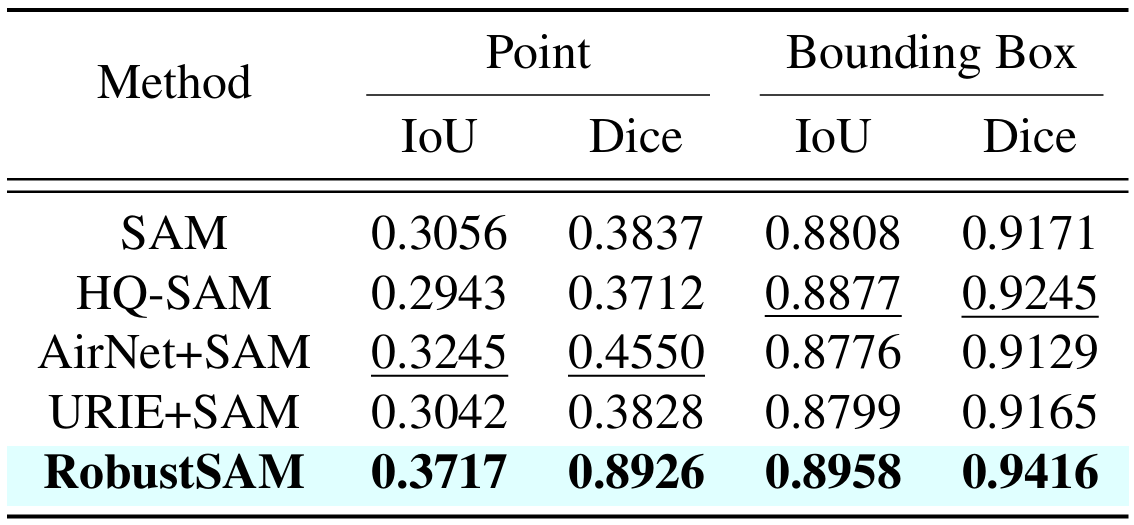
私たちの方法では、パラメータの増分と計算要件がわずかで、事前にトレーニングされた SAM モデルを利用します。 RobustSAM の追加パラメータは 8 つの GPU 上で 30 時間以内に最適化でき、一般的な研究室での実現可能性と実用性が実証されています。また、モデルを最適にトレーニングおよび評価するために設計された、さまざまな劣化を伴う 688K のイメージ マスク ペアのコレクションである Robust-Seg データセットも紹介します。さまざまなセグメンテーション タスクとデータセットにわたる広範な実験により、特にゼロショット条件下での RobustSAM の優れたパフォーマンスが確認され、広範な現実世界への応用の可能性が強調されています。さらに、私たちの方法は、単一画像のかすみ除去やぼけ除去などの SAM ベースの下流タスクのパフォーマンスを効果的に向上させることが示されています。
conda 環境を作成してアクティブ化します。
conda create --name robustsam python=3.10 -y conda activate robustsam
クローンを作成してリポジトリ ディレクトリに入ります。
git clone https://github.com/robustsam/RobustSAM cd RobustSAM
以下のコマンドを使用して CUDA のバージョンを確認します。
nvidia-smi
以下のコマンドで CUDA のバージョンを実際のバージョンに置き換えます。
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu[$YOUR_CUDA_VERSION] # For example: pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117 # cu117 = CUDA_version_11.7
残りの依存関係をインストールする
pip install -r requirements.txt
さまざまなサイズの事前トレーニング済み RobustSAM チェックポイントをダウンロードし、現在のディレクトリに配置します。
ViT-B RobustSAM チェックポイント
ViT-L RobustSAM チェックポイント
ViT-H RobustSAM チェックポイント
現在のディレクトリを「data」ディレクトリに変更します。
cd data
train、val、test、および追加の COCO & LVIS データセットをダウンロードします。 (注: train、val、test データセット内の画像は、LVIS、MSRA10K、ThinObject-5k、NDD20、STREETS、および FSS-1000 の画像で構成されています)
bash download.sh
前の手順でダウンロードされた鮮明な画像のみが存在します。以下のコマンドを使用して、対応する劣化イメージを生成します。
bash gen_data.sh
最初からトレーニングしたい場合は、以下のコマンドを使用します。
python -m torch.distributed.launch train_ddp.py --multiprocessing-distributed --exp_name [$YOUR_EXP_NAME] --model_size [$MODEL_SIZE] # Example usage: python -m torch.distributed.launch train_ddp.py --multiprocessing-distributed --exp_name test --model_size l
事前にトレーニングされたチェックポイントからトレーニングしたい場合は、以下のコマンドを使用します。
python -m torch.distributed.launch train_ddp.py --multiprocessing-distributed --exp_name [$YOUR_EXP_NAME] --model_size [$MODEL_SIZE] --load_model [$CHECKPOINT_PATH] # Example usage: python -m torch.distributed.launch train_ddp.py --multiprocessing-distributed --exp_name test --model_size l --load_model robustsam_checkpoint_l.pth
python gradio_app.py
デモの目的で、 demo_imagesフォルダーにいくつかの画像を用意しました。さらに、2 つのプロンプト モード (ボックス プロンプトとポイント プロンプト) が利用可能です。
ボックスプロンプトの場合:
python eval.py --bbox --model_size l
ポイントプロンプトの場合:
python eval.py --model_size l
デフォルトでは、デモの結果はdemo_result/[$PROMPT_TYPE]に保存されます。
 |  |
 |  |

この研究が役立つと思われる場合は、引用することをご検討ください。
@inproceedings{chen2024robustsam、title={RobustSAM: 劣化した画像でも堅牢にセグメント化}、author={Chen、Wei-Ting と Vong、Yu-Jiet と Kuo、Sy-Yen と Ma、Sizhou と Wang、Jian}、journal= {CVPR}、年={2024}}私たちのリポジトリのベースとなっている SAM の作成者に感謝します。


