toyCarIRL
1.0.0
強化学習 (RL)は、試行錯誤学習の非常に基本的かつ最も直観的な形式であり、何らかの思考能力を持つほとんどの生物が学習する方法です。探検による学習とよく呼ばれるこれは、生まれたばかりの人間の赤ちゃんが最初の一歩を踏み出すことを学ぶ方法です。つまり、最初はランダムな行動をとり、次にゆっくりと前に歩く動作につながる行動を理解することです。
この投稿は強化学習フレームワークを十分に理解していることを前提としていることに注意してください。この素晴らしいオンライン コース AI_Berkeley の第 5 週と第 6 週を通して RL に慣れてください。
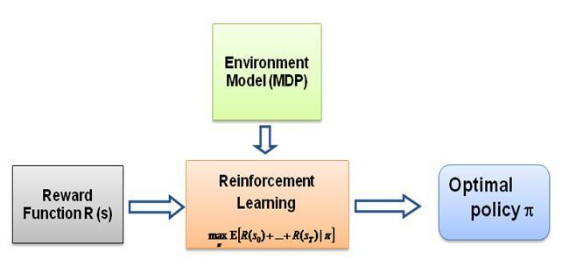
さて、私が自問し続けた疑問は、この種の学習の原動力は何なのか、エージェントが実行中の特定の動作を学習するよう強制するものは何なのかということです。 RL についてさらに詳しく学ぶうちに、報酬という考え方に出会いました。基本的に、エージェントは、その特定の行動から得られる報酬が最大化されるような方法で行動を選択しようとします。エージェントにさまざまな動作を実行させるには、報酬構造を変更/活用する必要があります。しかし、私たちが専門家の行動に関する知識だけを持っていると仮定すると、環境内の特定の行動を考慮して報酬構造をどのように推定すればよいでしょうか?さて、これは逆強化学習 (IRL)の問題そのものであり、最適なエキスパート ポリシー (実際には最適であると想定されている) が与えられた場合、基礎となる報酬構造を決定する必要があります。
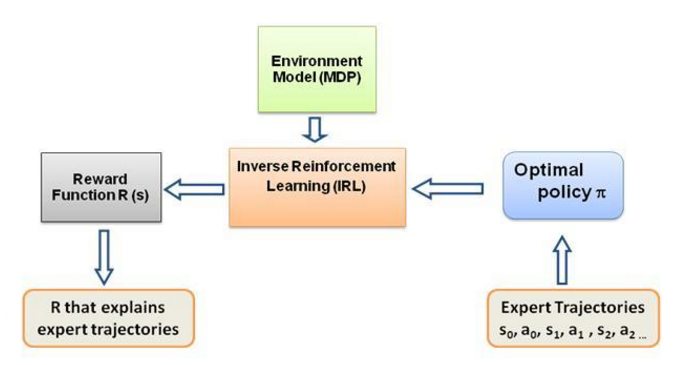
繰り返しになりますが、これは逆強化学習の紹介ではなく、むしろ独自の問題に対して逆強化学習フレームワークを使用/コード化する方法に関するチュートリアルですが、IRL はその中心にあり、それについて知ることが不可欠です。それを最初に。 IRL は過去に広範囲に研究されており、そのアルゴリズムが開発されています。詳細については、Ng と Russell、2000 年の論文、および Abbeel と Ng、2004 年の論文を参照してください。
この投稿では、Abbeel と Ng (2004) のアルゴリズムを IRL 問題を解決するために適応させています。
ここでのアイデアは、障害物でいっぱいの 2D 世界で単純なエージェントをプログラムして、環境内のさまざまな動作をコピー/クローンすることです。動作は、人間/コンピューターの専門家によって手動で与えられた専門家の軌跡の助けを借りて入力されます。専門家のデモンストレーションからのこの形式の学習は、科学文献では見習い学習と呼ばれています。その中心には逆強化学習があり、私たちはこれらのさまざまな行動に対するさまざまな報酬関数を理解しようとしているだけです。
一般に、はい、それらは同じものであり、デモンストレーションから学ぶことを意味します(LfD)。どちらの方法もデモンストレーションから学習しますが、学習する内容は異なります。
逆強化学習による見習い学習では、教師の目標を推測しようとします。言い換えれば、観察から報酬関数を学習し、強化学習で使用できるようになります。ハンマーで釘を打つことが目的だと分かれば、教師のまばたきや引っ掻きは目的に関係ないので無視します。
模倣学習 (別名行動クローニング) は、教師を直接コピーしようとします。これは教師あり学習のみで達成できます。 AI はあらゆる動作をコピーしようとします。たとえば、まばたきや引っ掻きなどの無関係な動作や、間違いさえもコピーしようとします。ここでも RL を使用できますが、報酬関数がある場合に限ります。
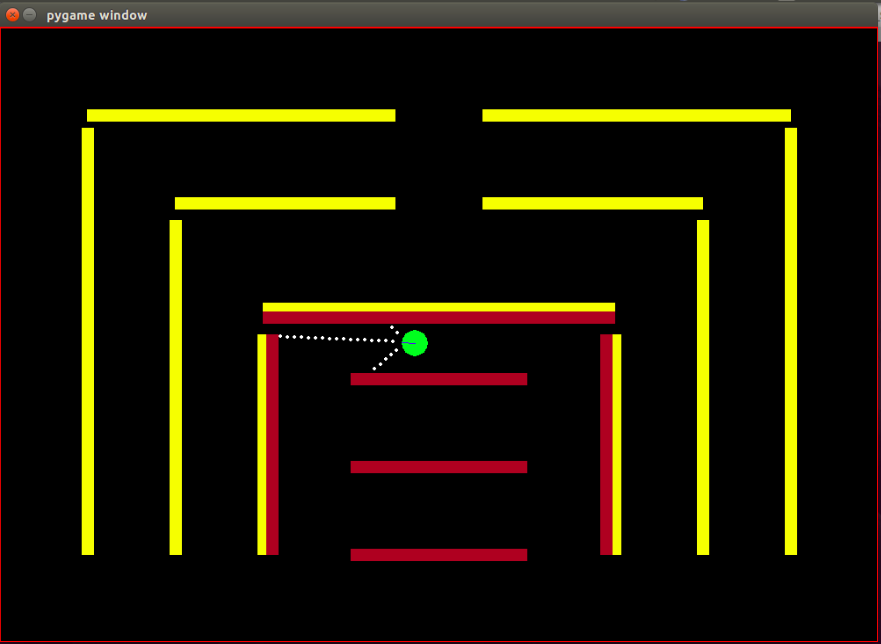
エージェント:エージェントは、青い線で示された進行方向を持つ小さな緑色の円です。
センサー:エージェントには 3 つの距離およびカラー センサーが装備されており、これがエージェントが環境に関して持つ唯一の情報です。
状態空間:エージェントの状態は 8 つの観察可能な特徴で構成されます。
正規化は、観測可能なすべての特徴値が [0,1] の範囲内にあることを保証するために行われることに注意してください。これは、IRL アルゴリズムが収束するための報酬の必要条件です。
報酬:各フレーム後の報酬は、それぞれのフレームで観察された特徴値の重み付き線形結合として計算されます。ここで、t 番目のフレームの報酬 r_t は、重みベクトル w と t 番目のフレームの特徴値のベクトル、つまり状態ベクトル phi_t の内積によって計算されます。 r_t = w^T x phi_t となります。
利用可能なアクション:新しいフレームごとに、エージェントは自動的に前に進みます。利用可能なアクションは、エージェントを左、右に回転させるか、単純な前進ステップである何もしないかのいずれかです。回転アクションには前進も含まれることに注意してください。インプレース回転ではありません。
障害物:環境は、意図的に異なる色で着色された硬い壁で構成されています。エージェントには、障害物の種類を区別するのに役立つ色検知機能があります。この環境は、IRL アルゴリズムを簡単にテストできるように設計されています。
IRL アルゴリズムによれば、開始状態がすべての反復で同じである必要があるため、ボットの開始位置 (状態) は固定されています。
RL アルゴリズムは、わずかな変更を加えて Matt Harvey によるこの投稿から完全に採用されていることに注意してください。そのため、私が行った変更について話すのは完全に理にかなっています。また、読者が RL に慣れている場合でも、一読することを強くお勧めします。強化学習がどのように行われているかを理解するためにその投稿を参照してください。
環境は大きく変わり、エージェントは3つのセンサーによる距離感知だけでなく、障害物の色も感知できるようになり、障害物を区別できるようになりました。また、解像度とパフォーマンスを向上させるために、エージェントのサイズが小さくなり、感知ドットが近くなりました。 IRL アルゴリズムのテスト プロセスを簡素化するために、現時点では障害物を静的にする必要がありました。これによりデータのオーバーフィッティングが発生する可能性が非常に高いですが、現時点ではそのことについては心配していません。上で説明したように、エージェントの状態にクラッシュ機能が含まれることにより、観測セットまたはエージェントの状態が 3 から 8 に増加しました。報酬構造が完全に変更され、報酬はこれら 8 つの特徴の加重線形結合になり、エージェントは障害物にぶつかっても -500 の報酬を受け取ることはなくなり、むしろ、ぶつかった場合の特徴値は +1 になり、ぶつからなかった場合の特徴値は 0 になります。専門家の行動に基づいて、この機能にどのような重みを割り当てるかを決定するのはアルゴリズムにあります。
Matt のブログで述べられているように、ここでの目的は RL エージェントに障害物を避けるように教えることだけではありません。つまり、なぜ報酬構造について何かを仮定する必要があるのか、専門家のデモンストレーションから得たアルゴリズムによって報酬構造を完全に決定させ、どのような動作が行われるかを確認することを意味します。特定の報酬設定で達成できます!
特徴または基底関数phi_i は、基本的に状態で観察可能なものです。現在の問題の機能については、上記の状態空間セクションで説明しています。 phi(s_t) を次のようなすべての特徴期待値 phi_i の合計として定義します。
報酬r_t - 各状態 s_t で観察されたこれらの特徴値の線形結合。
ポリシー pi の特徴期待値mu(pi) は、割引された特徴値 phi(s_t) の合計です。
ポリシーの機能期待値は重みとは独立しており、(ポリシーに従って) 実行中に訪問した状態と、0 から 1 までの数値の割引係数ガンマ (たとえば、この場合は 0.9) にのみ依存します。ポリシーの機能期待値を取得するには、エージェントを使用してリアルタイムでポリシーを実行し、訪問した状態と取得した機能値を記録する必要があります。
エキスパートのポリシー特徴期待値またはエキスパートの特徴期待値mu(pi_E) は、エキスパートの動作に従って実行されるアクションによって取得されます。基本的にこのポリシーを実行し、他のポリシーと同様に期待される機能を取得します。エキスパートの特徴期待値は IRL アルゴリズムに与えられ、重みに対応する報酬関数がエキスパートが (通常の RL 言語で) 最大化しようとしている基礎となる報酬関数に類似するような重みを見つけます。
ランダム ポリシー機能期待値- ランダム ポリシーを実行し、取得した機能期待値を使用して IRL を初期化します。
反復ごとに取得したポリシー機能の期待値のリストを維持します。
最初は pi^1 -> ランダムなポリシー機能の期待値しかありません。
凸最適化によって w^1 の最初の重みセットを見つけます。この問題は、エキスパート特徴量 exec に +1 ラベルを与えようとする SVM 分類器に似ています。および - 期待される他のすべてのポリシー機能に 1 つのラベルを付けます。
そのような、
終了条件:
さて、最適化を 1 回繰り返した後に重みを取得したら、つまり新しい報酬関数を取得したら、この報酬関数が生み出すポリシーを学習する必要があります。これは、この得られた報酬関数を最大化しようとするポリシーを見つけてくださいと言っているのと同じです。この新しいポリシーを見つけるには、この新しい報酬関数を使用して強化学習アルゴリズムをトレーニングし、Q 値が収束するまでトレーニングして、ポリシーの適切な推定値を取得する必要があります。
新しいポリシーを学習した後、この新しいポリシーに対応する機能の期待値を取得するために、このポリシーをオンラインでテストする必要があります。次に、これらの新しい機能の期待値を機能の期待値のリストに追加し、収束するまで IRL アルゴリズムの次の反復を行わずに続行します。
コードのコツを掴んでみましょう。完全なコードはこの git リポジトリで見つけてください。注意しなければならないファイルは主に 3 つあります -
ManualControl.py - エージェントを手動で移動することで、エキスパートが期待する機能を取得します。 「python3 ManualControl.py」を実行し、GUI がロードされるのを待ってから、矢印キーを使用して移動を開始します。コピーしたい動作を与えます (コピーすることが期待される動作は、指定された状態空間で妥当なものである必要があることに注意してください)。良いトリックは、エージェントの代わりに自分自身を想定し、現在の状態空間のみを考慮して特定の動作を区別できるかどうかを考えることです。詳細については、ソース ファイルを参照してください。
toy_car_IRL.py - メイン ファイル。ここに IRL コードが置かれます。コードをステップごとに見てみましょう。
{% 要点 51542f27e97eac1559a00f06b757df1a %}
依存関係をインポートし、重要なパラメーターを定義し、必要に応じて BEHAVIOR を変更します。 FRAMES は、RL アルゴリズムを実行するフレームの数です。 100K は問題なく、約 2 時間かかります。
{% 要点 49b602b9a3090773d492310175bb2e3f %}
使いやすい irlAgent クラスを作成します。このクラスは、ランダム動作とエキスパート動作、および図に示すその他の重要なパラメーターを受け取ります。
{% 要点 bc17c06a07ea3b915827e89f3c13a2ae %}
getRLAgentFE 関数は、強化学習器の IRL_helper を使用して新しいモデルをトレーニングし、そのモデルを 2000 回反復して再生することで機能の期待値を取得します。基本的に、取得した重み (W) のセットごとに特徴の期待値を返します。
{% 要点 ce0ef99adc652c7469f1bc4303a3af41 %}
取得したポリシーとそれぞれの t 値を保存する辞書を更新します。ここで、 t = (weights.tanspose)x(expert-newPolicy)。
{% 要点 be55a5d44e5b1ff13dfa68cc96f6b1b1 %}
メインの IRL アルゴリズムの実装。これについては上で説明しました。 {% 要点 9faee18596467ee33ac5d91fd0cb675f %}
新しいポリシーの受信時に重みを更新する凸型最適化では、基本的にエキスパート ポリシーに +1 ラベルを割り当て、他のすべてのポリシーに -1 ラベルを割り当て、前述の制約の下で重みを最適化します。この最適化について詳しくは、サイトをご覧ください。
{% 要点 30cf6c59b9915054f3cf6d278f8f8a11 %}
irlAgent を作成し、必要なパラメーターを渡し、重みを学習したいエキスパートの動作のタイプを選択して、optimalWeightFinder() 関数を実行します。赤、黄色、茶色の動作に対する期待される機能をすでに取得していることに注意してください。アルゴリズムが終了すると、選択したそれぞれの動作を含む重みのリストが「weights-red/ yellow/brown.txt」に取得されます。ここで、取得したすべての重みから可能な限り最良の動作を選択するために、saved-models_BEHAVIOR/evaluatedPolicies/ ディレクトリに保存されたモデルを再生します。モデルは次の形式で保存されます'saved-models_'+ BEHAVIOR +'/evaluatedPolicies/'+反復番号+ '-164-150-100-50000-100000' + '.h5' 。基本的に、異なる反復に対して異なる重みを取得します。最初にモデルを再生して、最もパフォーマンスが高いモデルを見つけます。次に、そのモデルの反復番号に注目します。この反復番号に対応して取得された重みが、エキスパートに最も近づく重みになります。行動。
そして、少なくともこの投稿の内容に関しては、おそらく更新/変更する必要のないファイルもあります -
約 10 ~ 15 回の反復の後、アルゴリズムは選択された 4 つの異なる動作すべてに収束し、次の結果が得られました。
| 重み | 黄色が大好きです | ブラウンが大好きです | レッドが大好きです | バンピングが大好きです |
|---|---|---|---|---|
| w1(左センサー距離) | -0.0880 | -0.2627 | 0.2816 | -0.5892 |
| w2(中央センサー距離) | -0.0624 | 0.0363 | -0.5547 | -0.3672 |
| w3(右センサー距離) | 0.0914 | 0.0931 | -0.2297 | -0.4660 |
| w4(黒色) | -0.0114 | 0.0046 | 0.6824 | -0.0299 |
| w5(黄色) | 0.6690 | -0.1829 | -0.3025 | -0.1528 |
| w6(ブラウン色) | -0.0771 | 0.6987 | 0.0004 | -0.0368 |
| w7(赤色) | -0.6650 | -0.5922 | 0.0525 | -0.5239 |
| w8 (クラッシュ) | -0.2897 | -0.2201 | -0.0075 | 0.0256 |
最初の 3 つの動作の衝突特徴に属する重みには、大きな負の値が割り当てられます。これは、これら 3 つのエキスパートの動作では、エージェントが障害物に衝突することが望ましくないためです。最後の動作、つまり Nasty ボットの同じ機能の重みはプラスですが、エキスパートの動作はバンピングを推奨しているためです。
明らかに、色の特徴の重みはエキスパートの動作に対応しており、その色が必要な場合は高く、そうでない場合は、明確な動作を得るためにかなり低い/負の値になります。
距離特徴量の重みは非常に曖昧で (直観に反する)、重みの中に意味のあるパターンを見つけることは非常に困難です。唯一指摘しておきたいのは、現在の設定では時計回りと反時計回りの動作を区別することも可能であり、距離機能にはこの情報が含まれるということです。
問題構造を設計する際に、人間として、与えられた動作と現在の状態セット (観測値) の利用可能性を区別できるかどうかを最初に考えることが非常に重要であることに注意してください。そうしないと、必要な情報を完全に提供せずに、アルゴリズムに異なる重みを検索させることになる可能性があります。
本当に IRL を使用したい場合は、実際にエージェントに新しい動作を教えてみることをお勧めします (現在の状態セットで考えられる個別の動作はすでに利用されているため、そのためには環境を変更する必要があるかもしれません)少なくとも私によれば)。
以下を使用して Pygame の依存関係をインストールします。
sudo apt install mercurial libfreetype6-dev libsdl-dev libsdl-image1.2-dev libsdl-ttf2.0-dev libsmpeg-dev libportmidi-dev libavformat-dev libsdl-mixer1.2-dev libswscale-dev libjpeg-dev
次に、Pygame 自体をインストールします。
pip3 install hg+http://bitbucket.org/pygame/pygame
これはシミュレーションで使用される物理エンジンです。かなり大幅な書き換え (v5) が行われたばかりなので、古い v4 バージョンを入手する必要があります。 v4 は Python 2 用に書かれているため、追加の手順がいくつかあります。
ホームに戻るか、ダウンロードして Pymunk 4 を入手します。
wget https://github.com/viblo/pymunk/archive/pymunk-4.0.0.tar.gz
開梱します。
tar zxvf pymunk-4.0.0.tar.gz
Python 2 から 3 に更新します。
cd pymunk-pymukn-4.0.0/pymunk
2to3 -w *.py
インストールします:
cd .. python3 setup.py install
次に、 reinforcement-learning-car複製した場所に戻り、簡単なpython3 learning.pyですべてが機能することを確認します。小さなドットが画面上を飛び回っているのが画面に表示されたら、準備は完了です。
まず、モデルをトレーニングする必要があります。これにより、ウェイトがsaved-modelsフォルダーに保存されます。を実行する前に、このフォルダーを作成する必要がある場合があります。以下を実行してモデルをトレーニングできます。
python3 learning.py
ネットワークの複雑さとサンプルのサイズに応じて、モデルのトレーニングには 1 時間から 36 時間かかる場合があります。ただし、25,000 フレームごとにウェイトを吐き出すため、はるかに短い時間で次のステップに進むことができます。
playing.pyファイルを編集して、ロードするモデルのパス名を変更します。申し訳ありませんが、これはコマンドライン引数でなければならないことはわかっています。
次に、車が障害物を避けて自動運転する様子を観察してください。
python3 playing.py
それだけです。


