Extendible Hashing for DBMS
1.0.0
データベース システム用の拡張可能なハッシュの低レベル実装。
この方法はディレクトリとバケットを使用してデータをハッシュし、その柔軟性と計算時間の効率性で広く知られています。
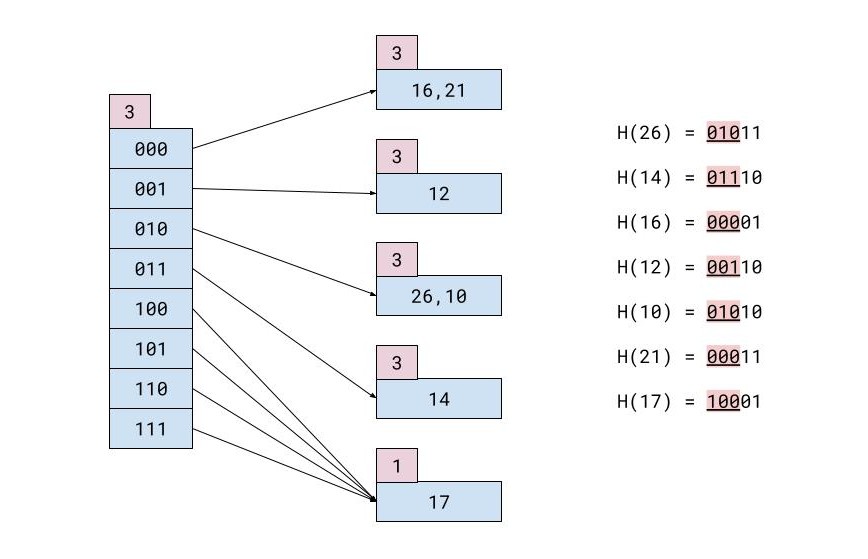
たとえば、次のようなレコードのテーブルがあります。
| ID | 名前 | 姓 | 市 |
|---|---|---|---|
| 26 | マリア | コロニス | 香港 |
| 14 | クリストフォロス | ガイタニス | 東京 |
| 16 | マリアンナ | カルヴォウナリ | マイアミ |
| 12 | テオフィロス | ニコロプロス | ロンドン |
| 10 | ヨシフ | スビンゴス | 東京 |
| 21 | テオフィロス | ミシャス | アテネ |
| 17 | ジョルゴス | ハラチス | ミュンヘン |
メモリの各ブロックに 2 つのレコードしか含めることができない場合、すべての挿入後のハッシュ ファイルは次のようになります。
プログラムは 2 つの異なる main 関数によって実行できます。この最初のコマンドはファイルに多数のレコードを挿入し、2 番目のコマンドはレコードを作成して 3 つの異なるファイルに同時に挿入します。
テストメイン1:
make main1
./build/runner
テストメイン2:
make main2
./build/runner