WeClone
1.0.0
WeChat のチャット記録を使用して大規模な言語モデルを微調整し、約 20,000 個の統合された有効なデータを使用しました。最終結果は不十分としか言いようがありませんが、場合によっては非常に面白いものになります。
重要
現在、プロジェクトはデフォルトで chatglm3-6b モデルを使用しており、LoRA メソッドを使用して sft ステージを微調整しています。これには約 16 GB のビデオ メモリが必要です。 LLaMA Factory でサポートされている、ビデオ メモリの使用量が少ない他のモデルやメソッドを使用することもできます。テンプレートのシステム プロンプト ワードやその他の関連構成を自分で変更する必要があります。
推定ビデオ メモリ要件:
| トレーニング方法 | 正確さ | 7B | 13B | 30B | 65B | 8x7B |
|---|---|---|---|---|---|---|
| 完全なパラメータ | 16 | 160GB | 320GB | 600GB | 1200GB | 900GB |
| いくつかのパラメータ | 16 | 20GB | 40GB | 120GB | 240GB | 200GB |
| LoRA | 16 | 16ギガバイト | 32GB | 80GB | 160GB | 120GB |
| QLoRA | 8 | 10GB | 16ギガバイト | 40GB | 80GB | 80GB |
| QLoRA | 4 | 6GB | 12GB | 24GB | 48GB | 32GB |
| 必須 | 少なくとも | 推薦する |
|---|---|---|
| パイソン | 3.8 | 3.10 |
| トーチ | 1.13.1 | 2.2.1 |
| 変圧器 | 4.37.2 | 4.38.1 |
| データセット | 2.14.3 | 2.17.1 |
| 加速する | 0.27.2 | 0.27.2 |
| ペフト | 0.9.0 | 0.9.0 |
| trl | 0.7.11 | 0.7.11 |
| オプション | 少なくとも | 推薦する |
|---|---|---|
| CUDA | 11.6 | 12.2 |
| ディープスピード | 0.10.0 | 0.13.4 |
| ビットサンドバイト | 0.39.0 | 0.41.3 |
| フラッシュ攻撃 | 2.3.0 | 2.5.5 |
git clone https://github.com/xming521/WeClone.git
conda create -n weclone python=3.10
conda activate weclone
cd WeClone
pip install -r requirements.txtトレーニングと推論関連の構成はファイル settings.json に統合されています
PyWxDump を使用して WeChat チャット レコードを抽出してください。ソフトウェアをダウンロードしてデータベースを復号化したら、[チャット バックアップ] をクリックします。エクスポート タイプは CSV です./data次に、エクスポートされたcsvフォルダーをwxdump_tmp/exportディレクトリに配置します。人々のチャット記録のフォルダーは./data/csvにまとめて配置されます。 サンプル データは data/example_chat.csv にあります。
デフォルトでは、プロジェクトは携帯電話番号、ID 番号、電子メール アドレス、および Web サイトのアドレスをデータから削除します。また、禁止単語のデータベースblocked_wordsも提供しており、フィルタリングが必要な単語や文を追加できます(デフォルトでは、禁止単語を含む文全体が削除されます)。 ./make_dataset/csv_to_json.pyスクリプトを実行してデータを処理します。
同じ人が複数の文を連続して回答した場合、次の 3 つの方法があります。
| 書類 | 加工方法 |
|---|---|
| csv_to_json.py | カンマで接続する |
| csv_to_json-単文のanswer.py (廃止) | 最も長い回答のみが最終データとして選択されます |
| csv_to_json-単一文複数rounds.py | プロンプトワードの「履歴」に配置されます |
最初の選択肢は、Hugging Face から ChatGLM3 モデルをダウンロードすることです。 Hugging Face モデルのダウンロードで問題が発生した場合は、次の方法で MoDELSCOPE コミュニティを使用できます。その後のトレーニングと推論では、最初にexport USE_MODELSCOPE_HUB=1を実行して、MoDELSCOPE コミュニティのモデルを使用する必要があります。
モデルのサイズが大きいため、ダウンロードには時間がかかります。しばらくお待ちください。
export USE_MODELSCOPE_HUB=1 # Windows 使用 `set USE_MODELSCOPE_HUB=1`
git lfs install
git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git(オプション) settings.json を変更して、ローカルにダウンロードされた他のモデルを選択します。
per_device_train_batch_sizeとgradient_accumulation_stepsを変更して、ビデオ メモリの使用量を調整します。
独自のデータセットの量と品質に応じて、 num_train_epochs 、 lora_rank 、 lora_dropoutなどのパラメータを変更できます。
src/train_sft.pyを実行して sft ステージを微調整すると、損失は約 3.5 までしか下がりませんでした。これを減らしすぎると、オーバーフィッティングが発生する可能性があります。
python src/train_sft.pypip install deepspeed
deepspeed --num_gpus=使用显卡数量 src/train_sft.py注記
最初に pt ステージを微調整することもできますが、改善効果は明らかではないようです。ウェアハウスには、pt ステージ データセットの前処理とトレーニング用のコードも提供されています。
python ./src/web_demo.py python ./src/api_service.pypython ./src/api_service.py
python ./src/test_model.py重要
WeChat ではアカウントが閉鎖されるリスクがあります。小規模アカウントを使用することをお勧めします。使用するには銀行カードをバインドする必要があります。
python ./src/api_service.py # 先启动api服务
python ./src/wechat_bot/main.py デフォルトではQRコードが端末に表示されるので、コードをスキャンするだけでログインできます。プライベートチャットまたはグループチャット@botで使用できます。
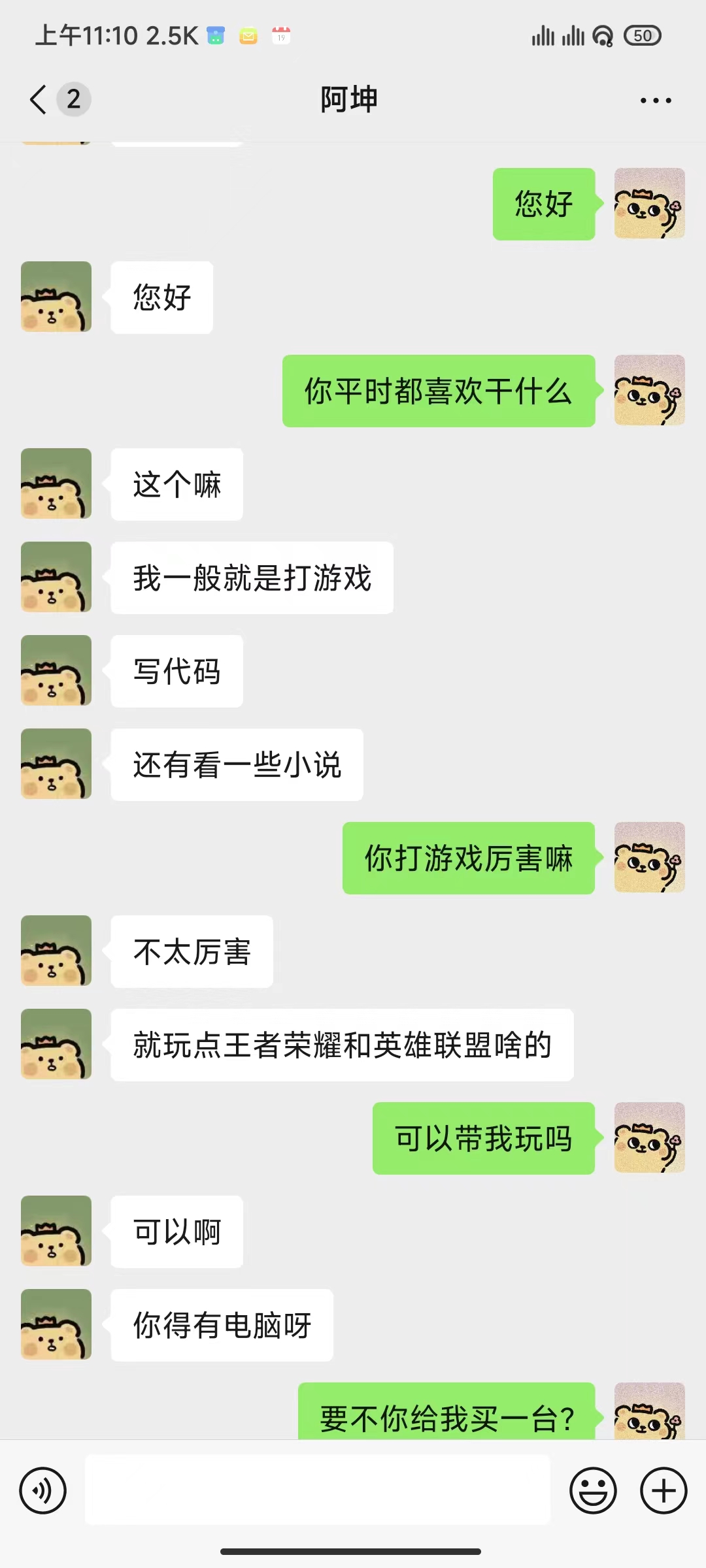

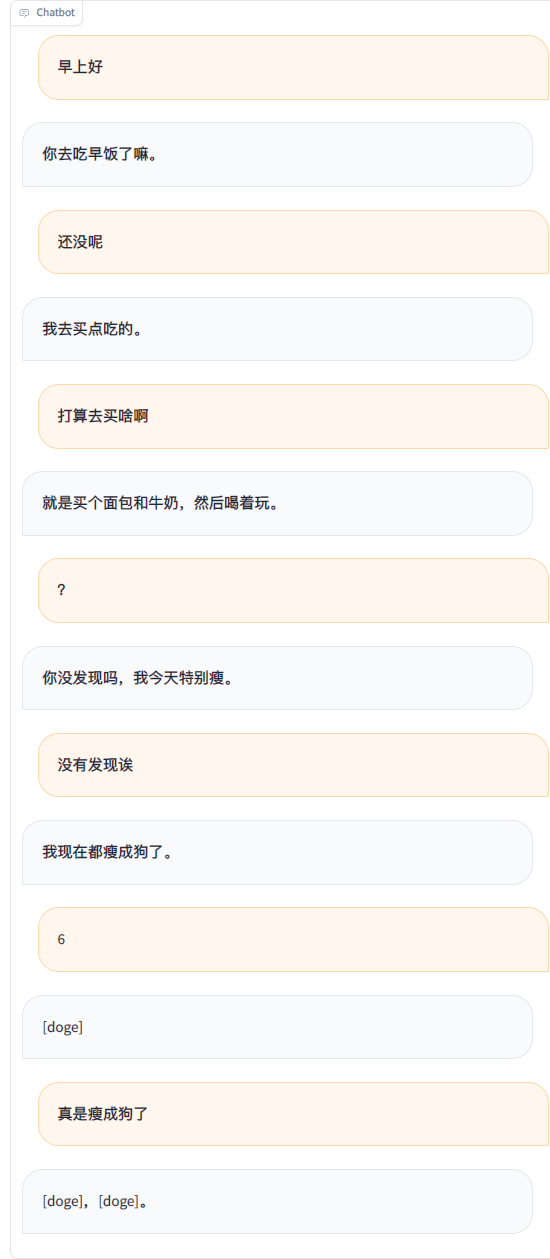
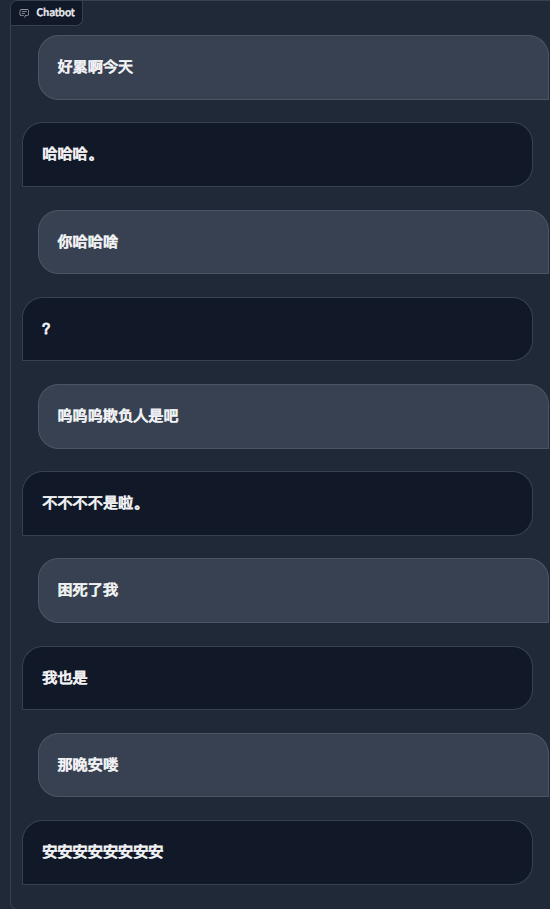
藤堂
藤堂


