py spider for wechat
1.0.0
二次開発やPR投稿も歓迎します?
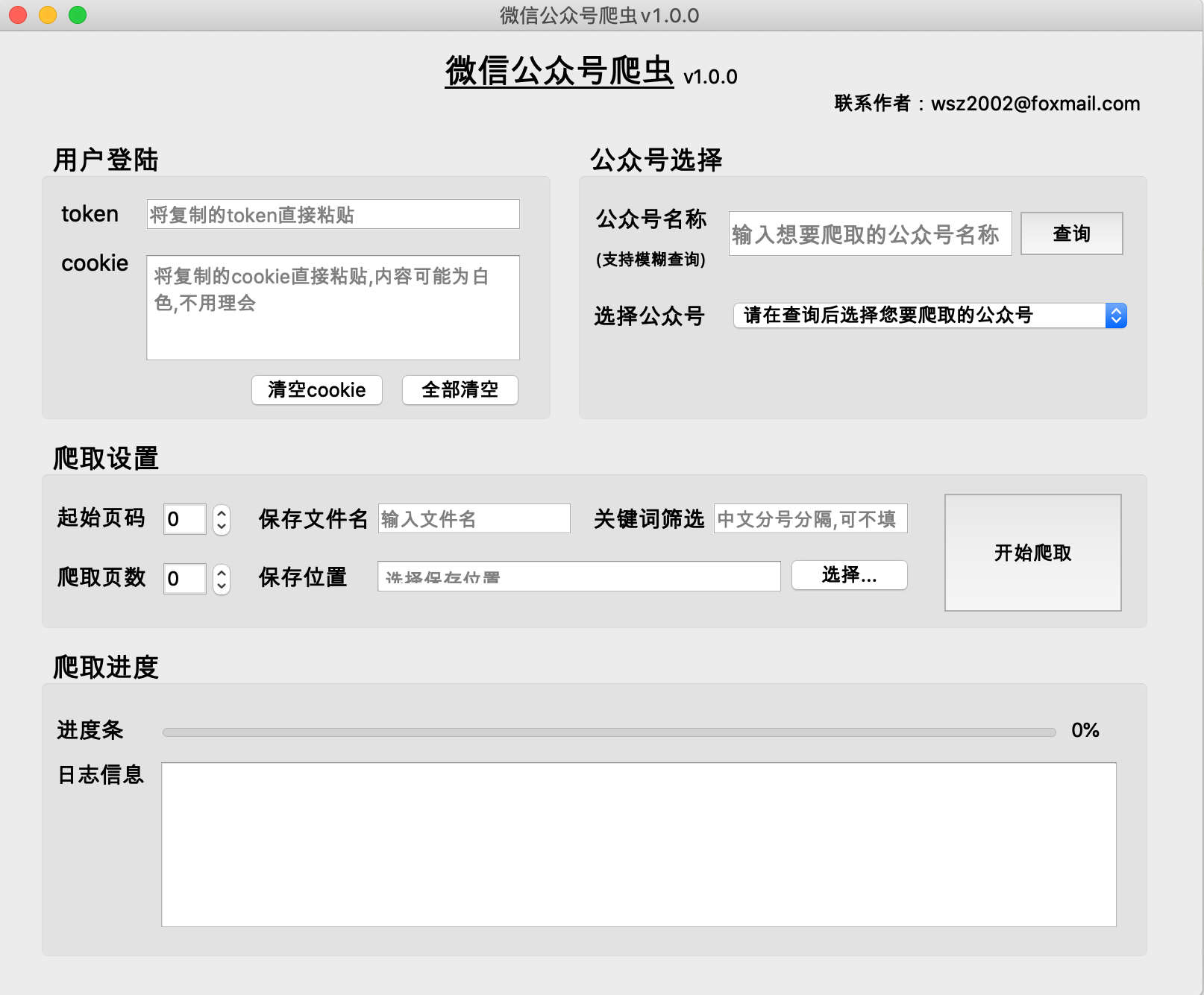
Python を使用して、指定された公開アカウントの履歴記事とコンテンツをクロールするクローラーを構築し、キーワードを使用した記事のフィルター処理をサポートします。
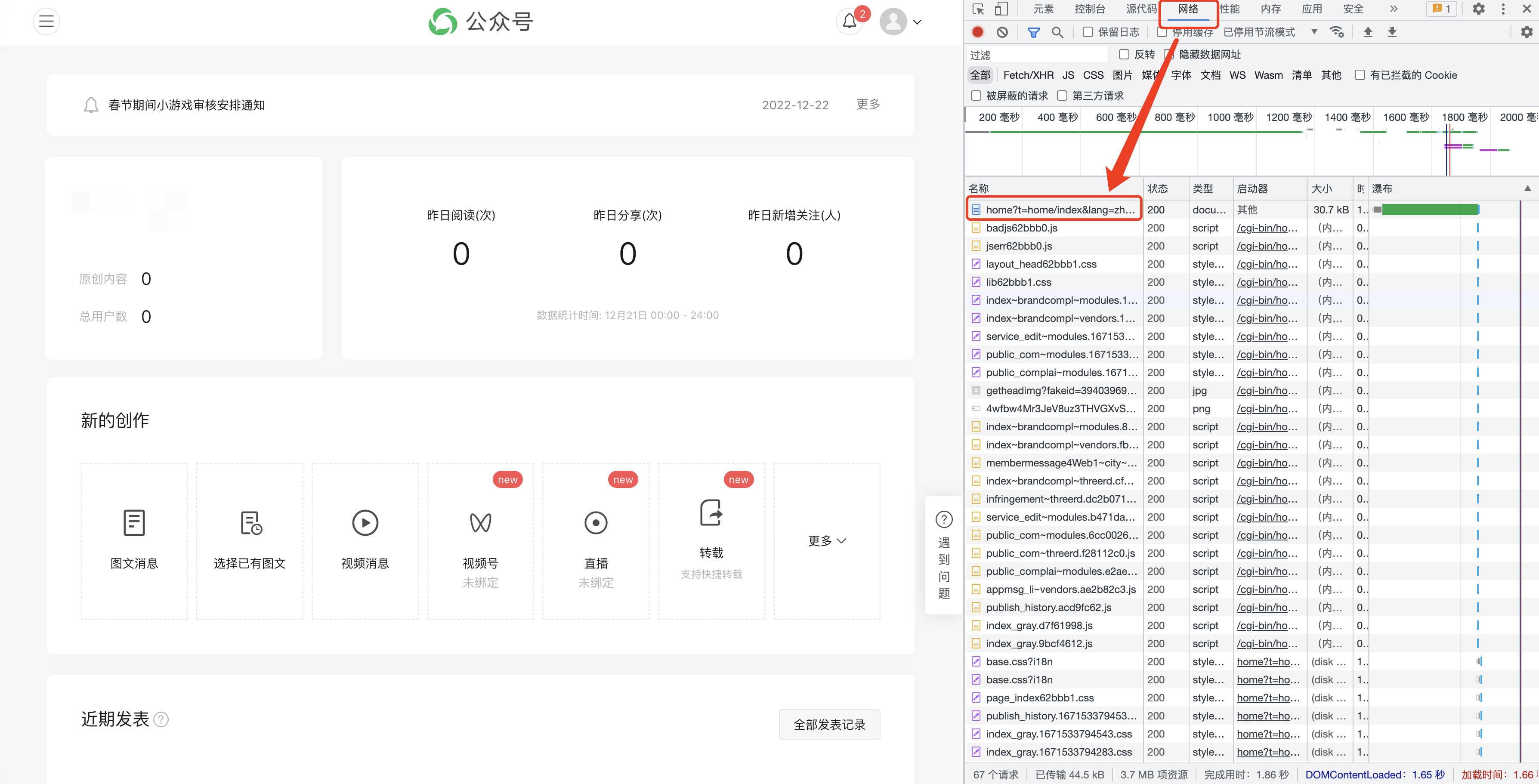
F12を押して次のインターフェイスを開き、[ネットワーク]に切り替えます。 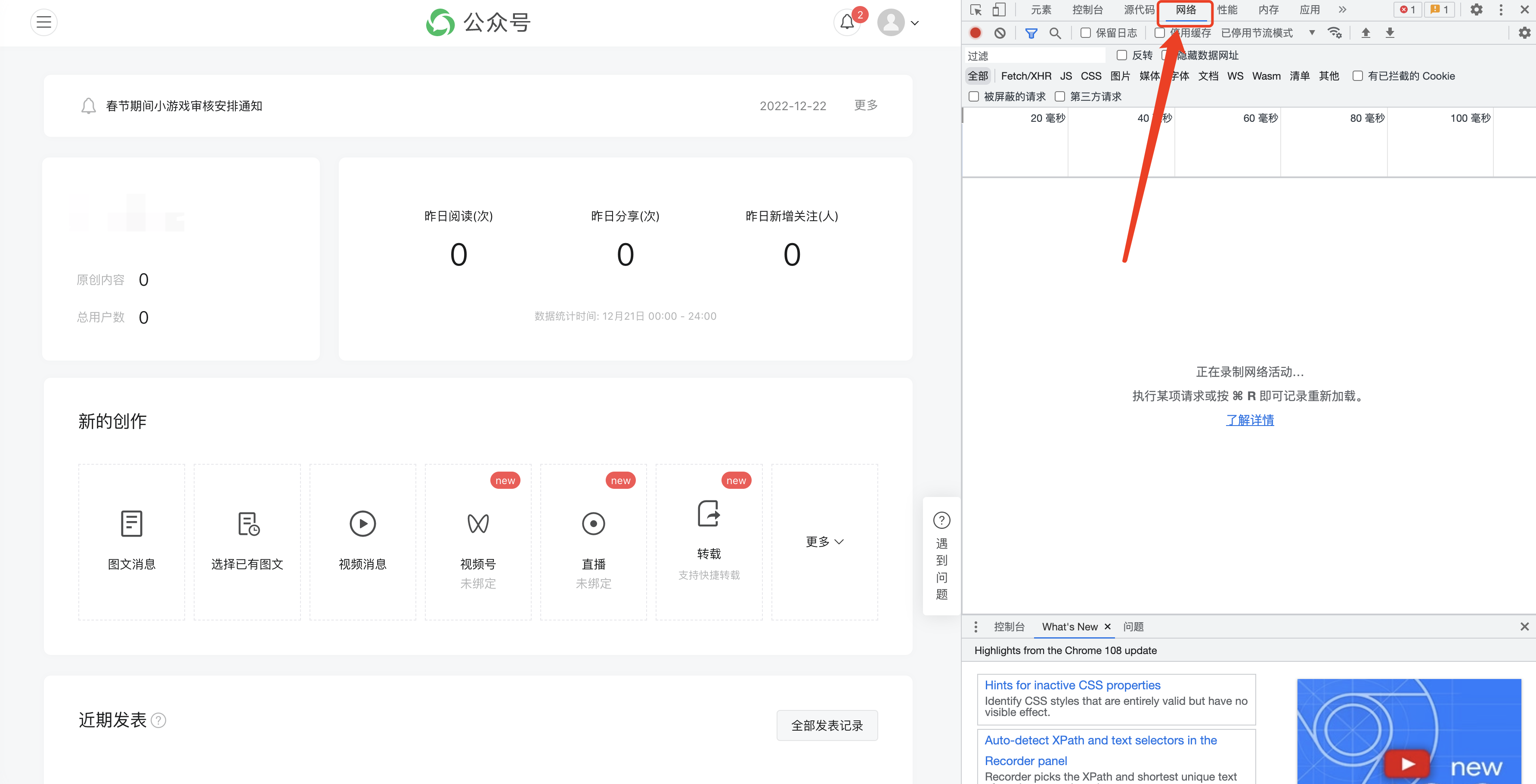
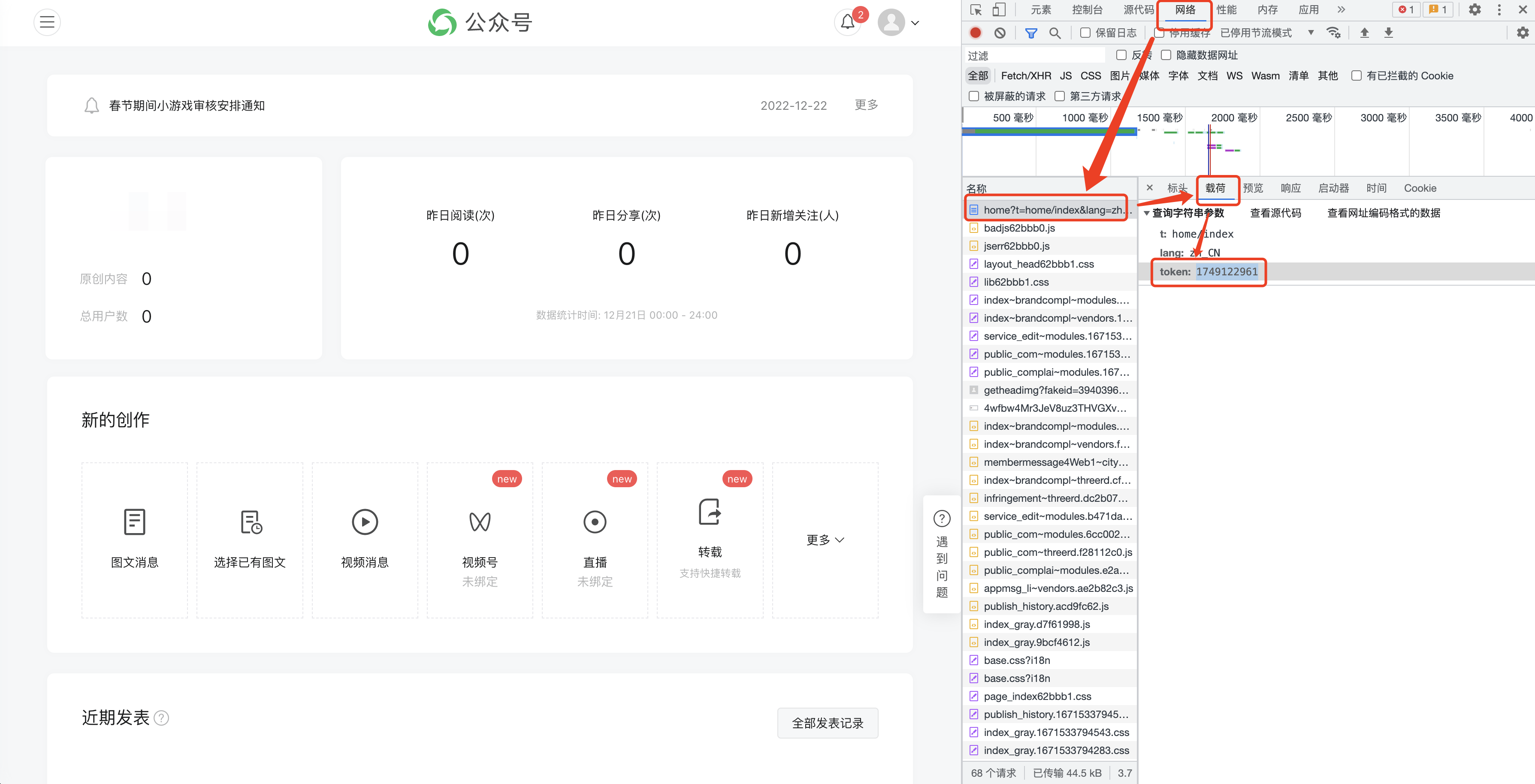
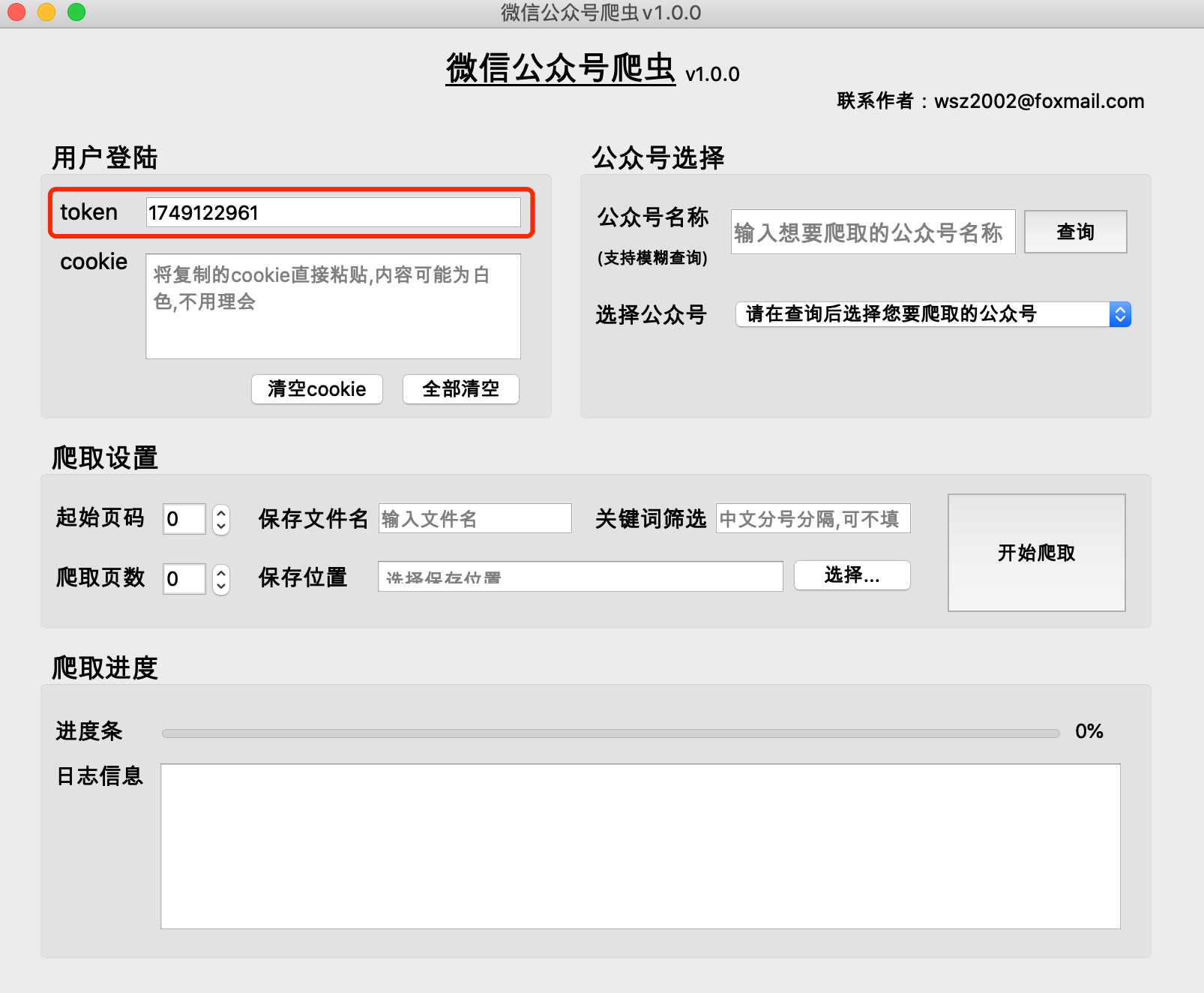
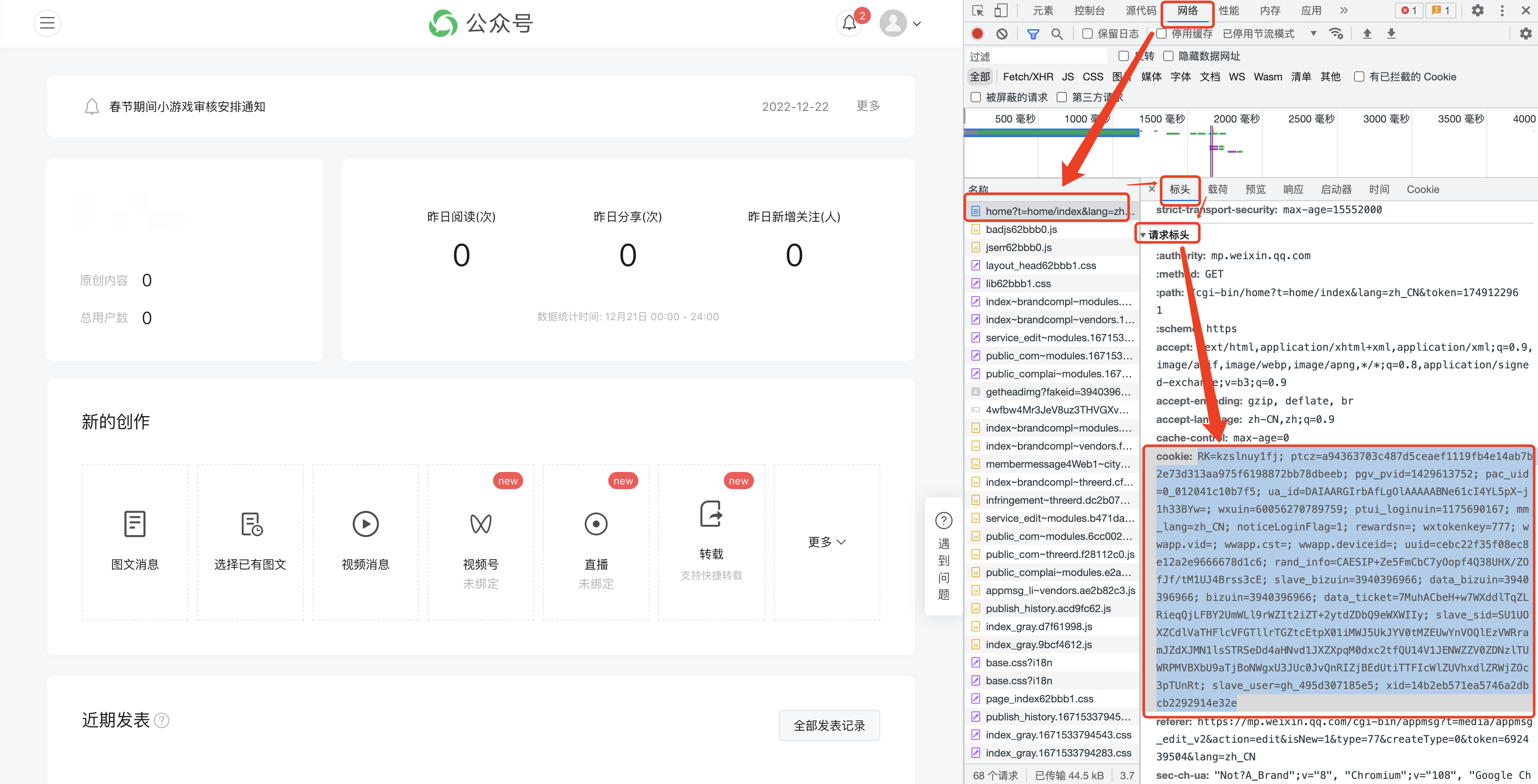
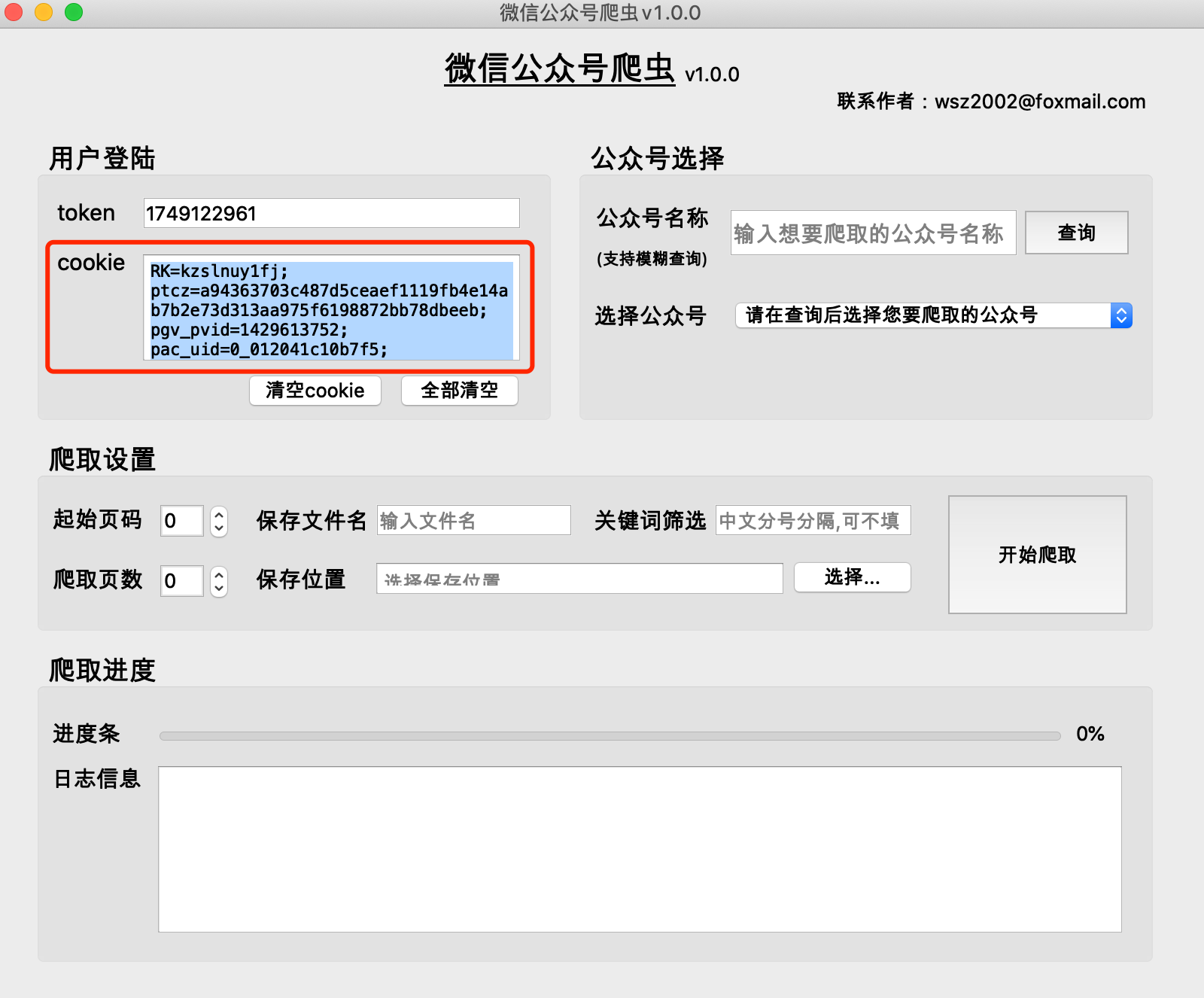
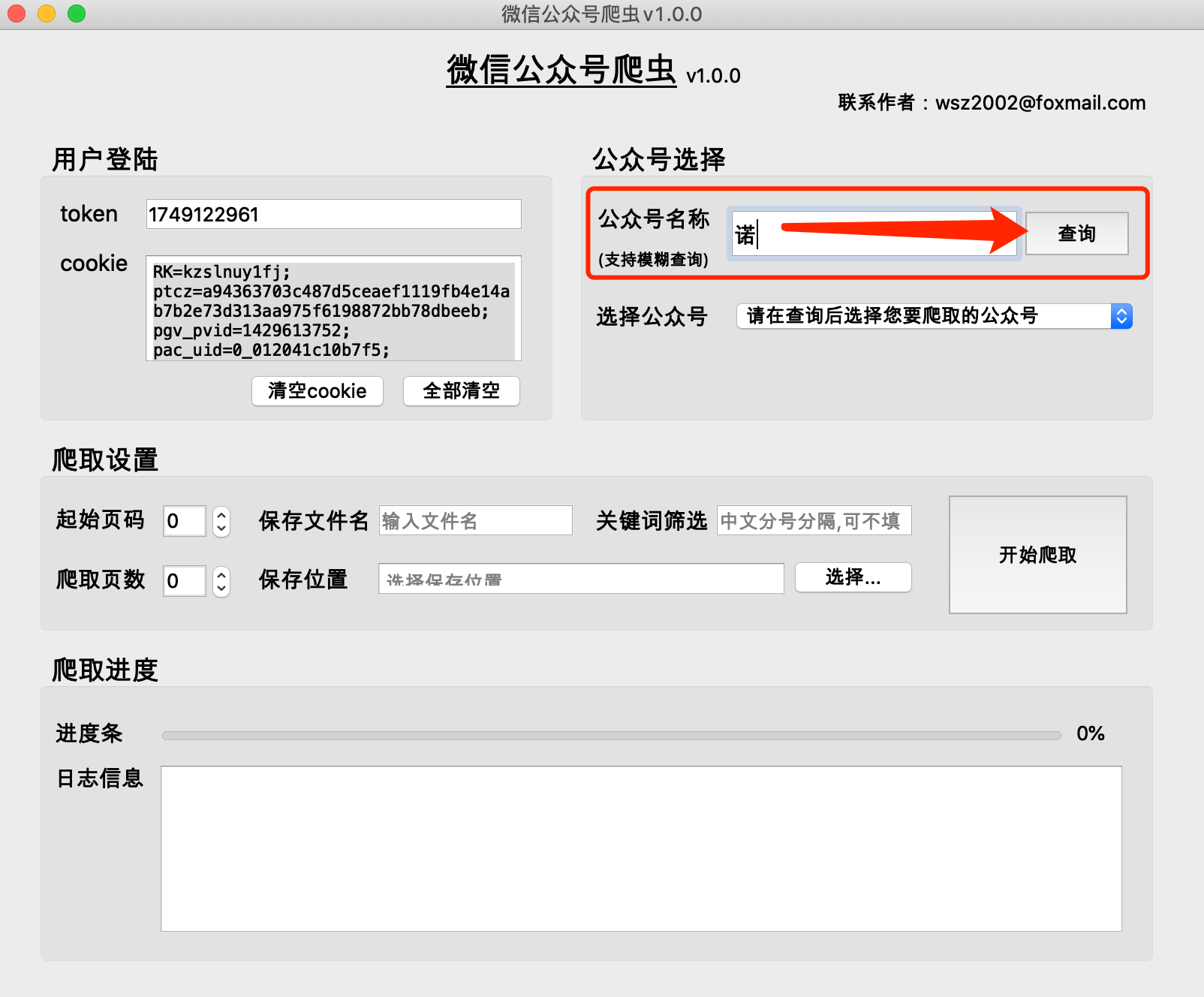
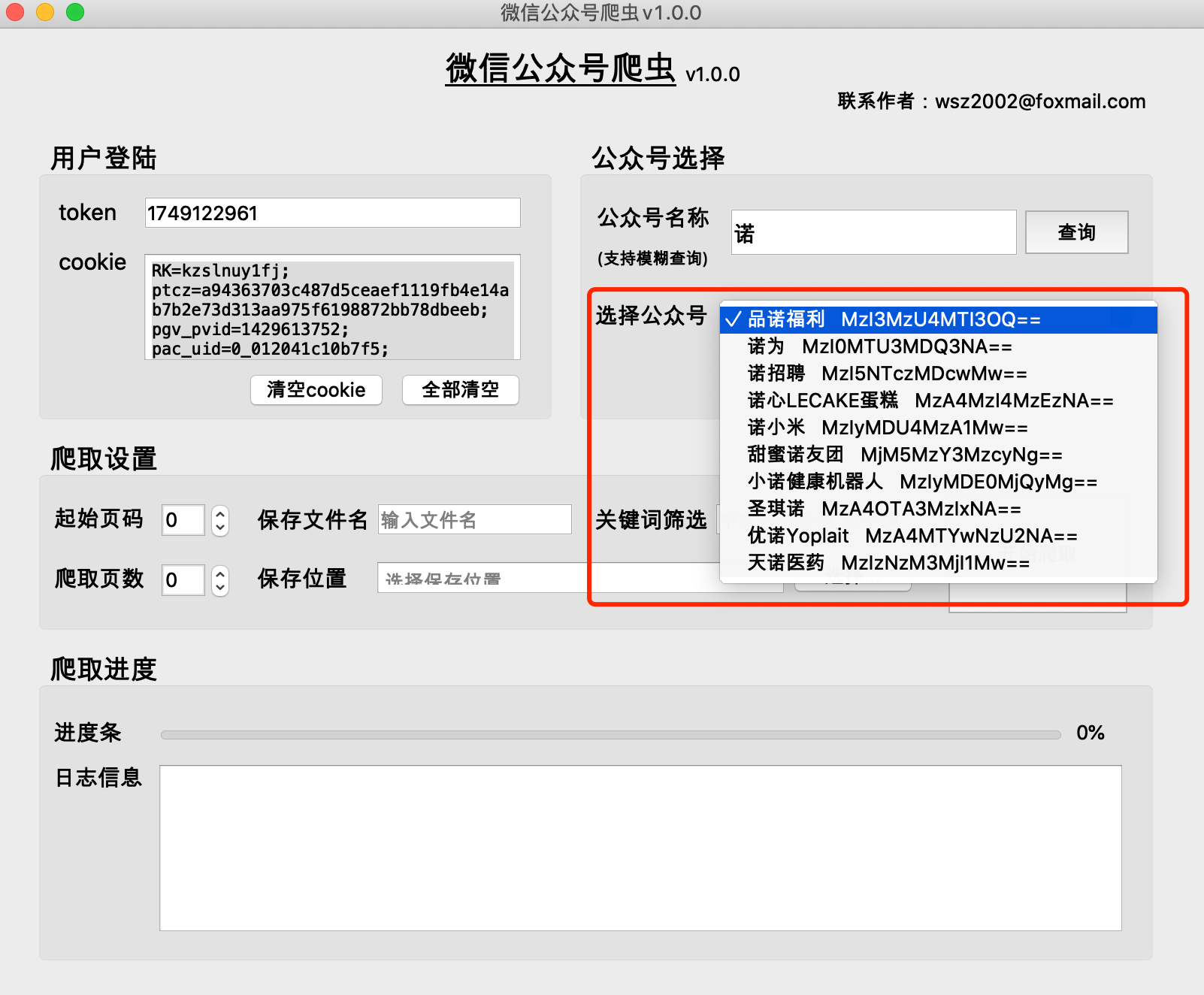
(1) 公開アカウントの履歴記事は、通常、1 ページに 5 ~ 10 件のページ単位で取得されます。
(2) 公開アカウントの過去記事のページ番号が小さいほど、ページ 0 には最新の記事が格納されます。
(3) 開始ページ番号は0から始まることを推奨します。
(4) クロールされたページ数を 0 にすることはできません。0 にしないと、クロール結果が空になります。
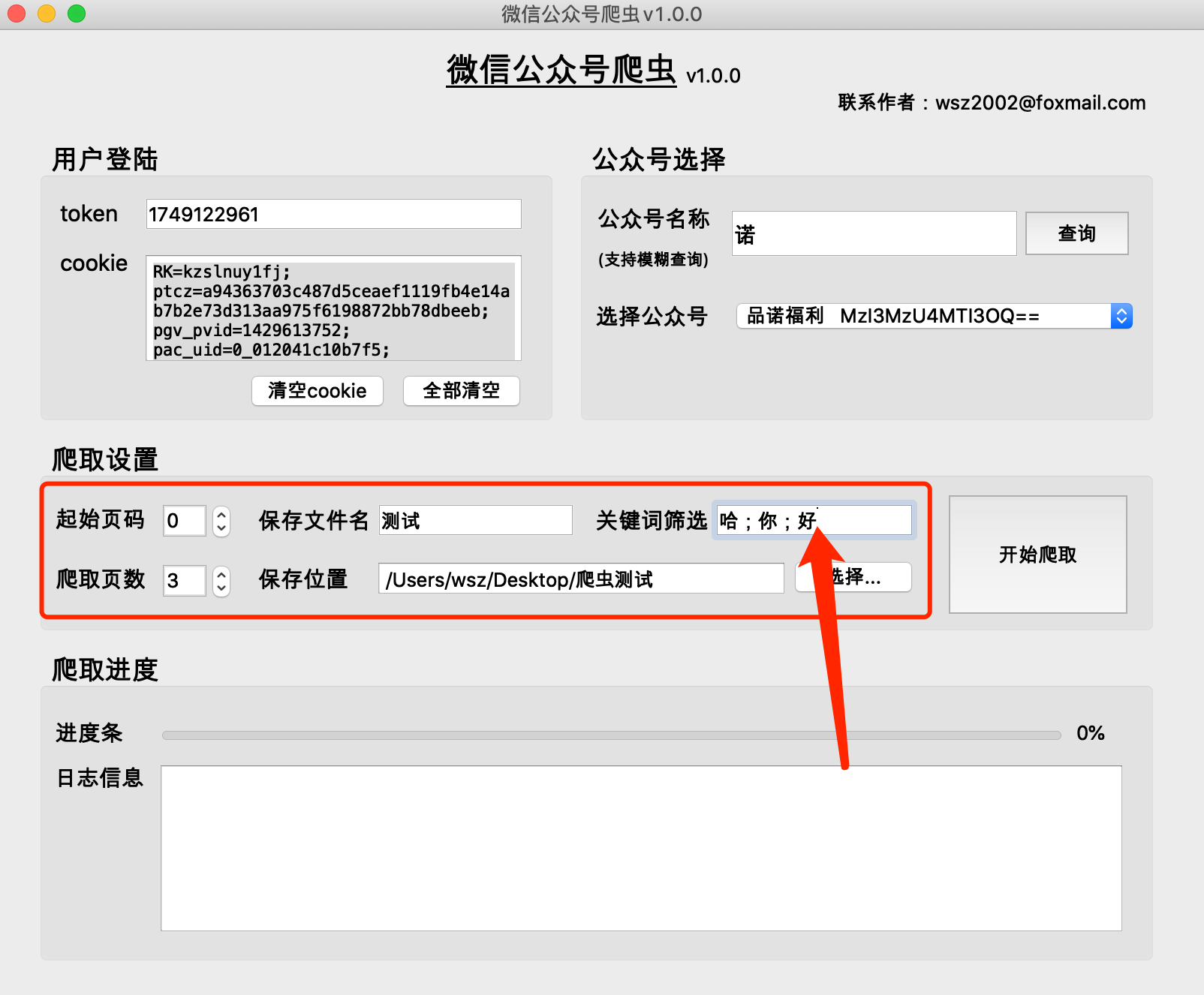
正しいファイル名を入力し、ファイルの場所を選択します。
(1) 機能:記事をキーワードで絞り込み、記事タイトルにキーワードを含む記事を取得するために使用します。入力しない場合は、すべての記事が検索されます。
(2)形式:关键词1;关键词2;关键词3
[中国語のセミコロン] で区切ります。最後のキーワードの後にはセミコロンは必要ありません
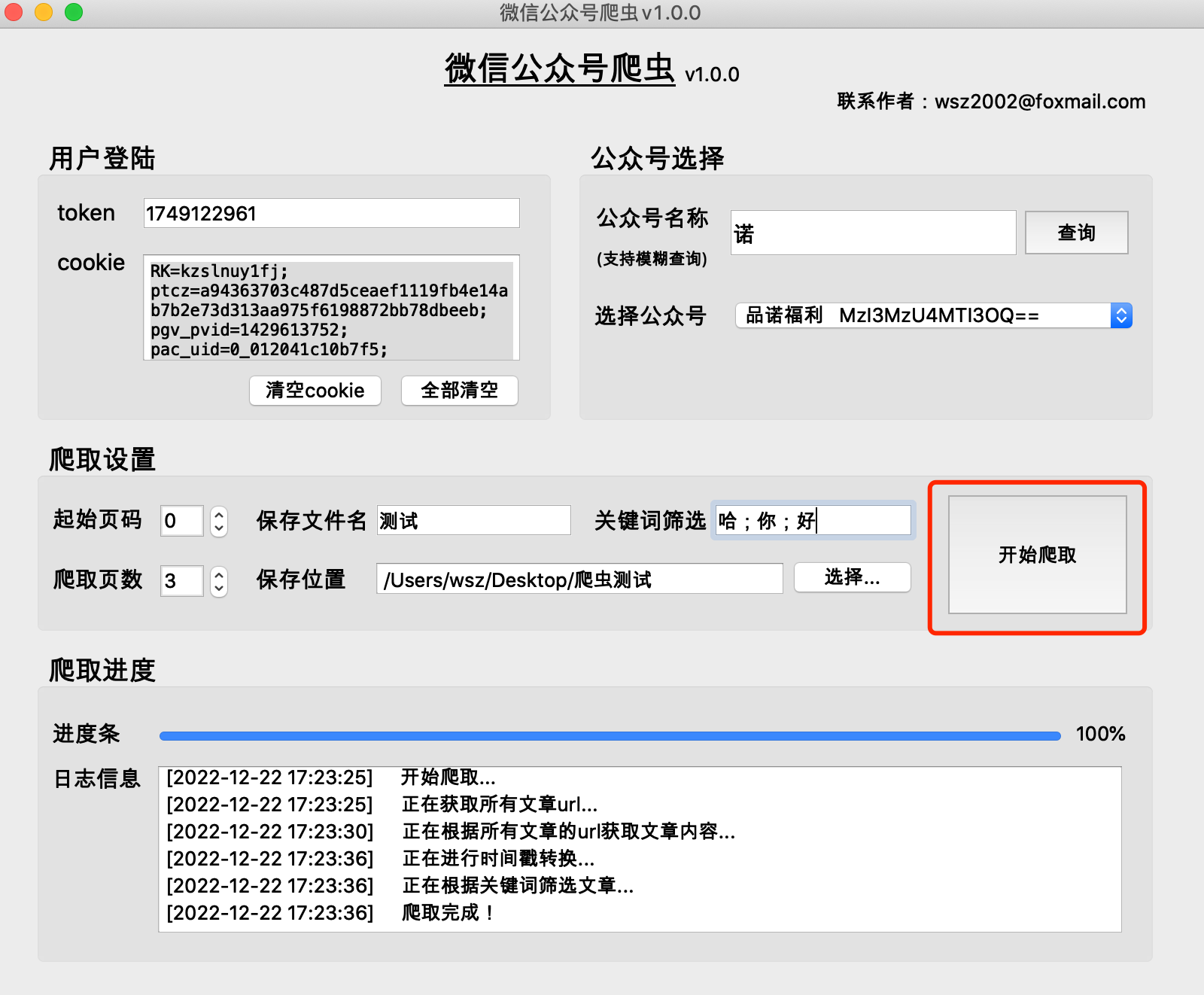
(1) プログラムは、選択したファイル保存場所ディレクトリに保存文件名_当日日期のフォルダーを生成し、クロールされたコンテンツをこのフォルダーに保存します。
(2) rawフォルダーの内容は、クローリング プロセス中に生成されるキャッシュ ファイルであり、削除することができます。