liuli
v0.2.0
簡単に説明してみましょう:
Collector : フォローしている公開アカウント、書籍、ブログ ソースなどのカスタマイズされた読書ソースを監視し、入力ソースとして統一された標準形式でLiuliに流入します。
プロセッサ: 機械学習を使用して過去の広告データに基づいて広告分類子に自動的にラベルを付ける、または関連ノードで実行するフック関数を導入するなど、ターゲット コンテンツをカスタマイズします。
ディストリビューター: インターフェイス層に依存してデータのリクエストと応答を実行し、ユーザーにパーソナライズされた構成を提供し、構成に従って自動的に配布し、クリーンな記事を WeChat、DingTalk、TG、RSS クライアント、さらには自作の Web サイトに流し込みます。
Backer : 処理された記事をデータベースや GitHub などに永続化するなどしてバックアップします。
これにより、クリーンな読書環境の構築が実現し、得られたデータをもとにさまざまなアイデアを広げることができます。
開発進捗ダッシュボード:
v0.2.0: 一般的なシナリオのソリューションを確実に適用できるようにするための基本機能を実装します。
v0.3.0: コレクターのカスタマイズを実装し、ユーザーは表示されているものを収集できます
モデルの認識精度を向上させるために、皆さんがいくつかの広告サンプルを提供できることを願っています。サンプル ファイル: .files/datasets/ads.csv を次のように設定しました。
| タイトル | URL | is_process |
|---|---|---|
| 広告記事タイトル | 広告記事リンク | 0 |
フィールドの説明:
タイトル: 記事のタイトル
url: 記事リンク。WeChat 記事を使用したい場合は、まず無効かどうかを確認してください。
is_process: サンプル処理を実行するかどうかを示します。デフォルトでは0を入力します。
例を挙げてみましょう:
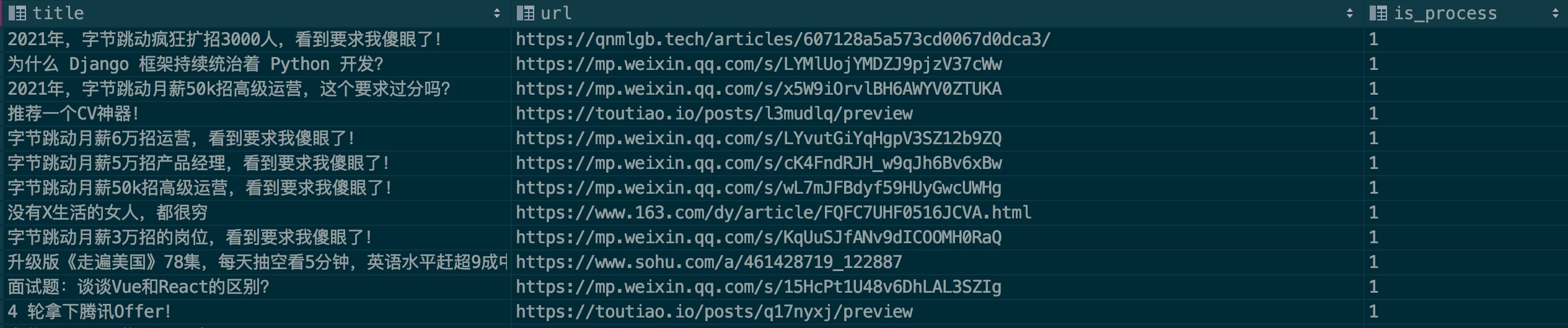
通常、広告は複数の公開アカウントに繰り返し掲載されます。記入する際は、このレコードが存在するかどうかを確認してください。皆さんも協力して PR に貢献していただければ幸いです。
次のオープンソース プロジェクトのおかげで:
Flask: Web フレームワーク
Vue: プログレッシブ JavaScript フレームワーク
Ruia: 非同期クローラー フレームワーク (自社開発および使用)
playwright: ブラウザを使用したデータ スクレイピング
上記では、コアのオープンソース依存関係のみをリストしています。その他のサードパーティ依存関係については、Pipfile ファイルを参照してください。
あなたが受け取ったすべての PR は、 Liuliプロジェクトへの強力なサポートとなります。次の開発者の貢献に非常に感謝しています (順不同)。
一緒にコミュニケーションをとることを歓迎します (グループをフォローしてください):


