GroundingDINO
Grounding DINO SwinB

Idea-CVR、Idea-Research
Shilong Liu、Zhaoyang Zeng、Tianhe Ren、Feng Li、Hao Zhang、Jie Yang、Chunyuan Li、Jianwei Yang、Hang Su、Jun Zhu、Lei Zhang ? 。
[ Paper ] [ Demo ] [ BibTex ]
Dinoを接地するためのPytorchの実装と事前に守られたモデル。詳細については、紙の接地Dino:Dinoとの結婚とオープンセットオブジェクト検出のためのプリトレーニングと結婚してください。
2023/07/18 :セグメントセグメントモデルであるセマンティックサムをリリースして、セグメントを有効にして、任意の粒度で何かを認識します。コードとチェックポイントが利用可能です!2023/06/17 :Coco Zero-Shotのパフォーマンスに関する樹木を評価する例を示します。2023/04/15 :オープンセット認識に興味のある人のための野生の測定値のCVを参照してください!2023/04/08 :デモをリリースして、グラウンドディノとグリゲンを組み合わせて、より制御可能な画像編集を行います。2023/04/08 :デモをリリースして、グラウンドディノと画像編集用の安定した拡散を組み合わせます。2023/04/06 :グラウンド・セグメント・アニシングと名付けられたセグメント・アニシングと結婚することにより、グラウンド・ディンンノのセグメンテーションをサポートすることを目指して、新しいデモを構築します。2023/03/28 :Dinoと基本的なオブジェクト検出プロンプトエンジニアリングの接地に関するYouTubeビデオ。 [Skalskip]2023/03/28 :フェイススペースを抱き締めるデモを追加してください!2023/03/27 :CPUのみのモードをサポートします。これで、モデルはGPUなしでマシンで実行できます。2023/03/25 :Dinoを接地するためのデモがColabで入手できます。 [Skalskip]2023/03/22 :コードは今利用可能です! グラウンドディノとグリゲンの結婚
グラウンドディノとグリゲンの結婚(image, text)ペアを受け入れます。900 (デフォルトで)オブジェクトボックスを出力します。各ボックスには、すべての入力単語に類似したスコアがあります。 (以下の図に示すように。)box_thresholdよりも高いボックスを選択します。text_thresholdよりも高い単語を抽出します。dogs two dogs with a stick. 、最終的な出力としてdogsと最高のテキストの類似点を持つボックスを選択できます。.グラウンドディノのために。 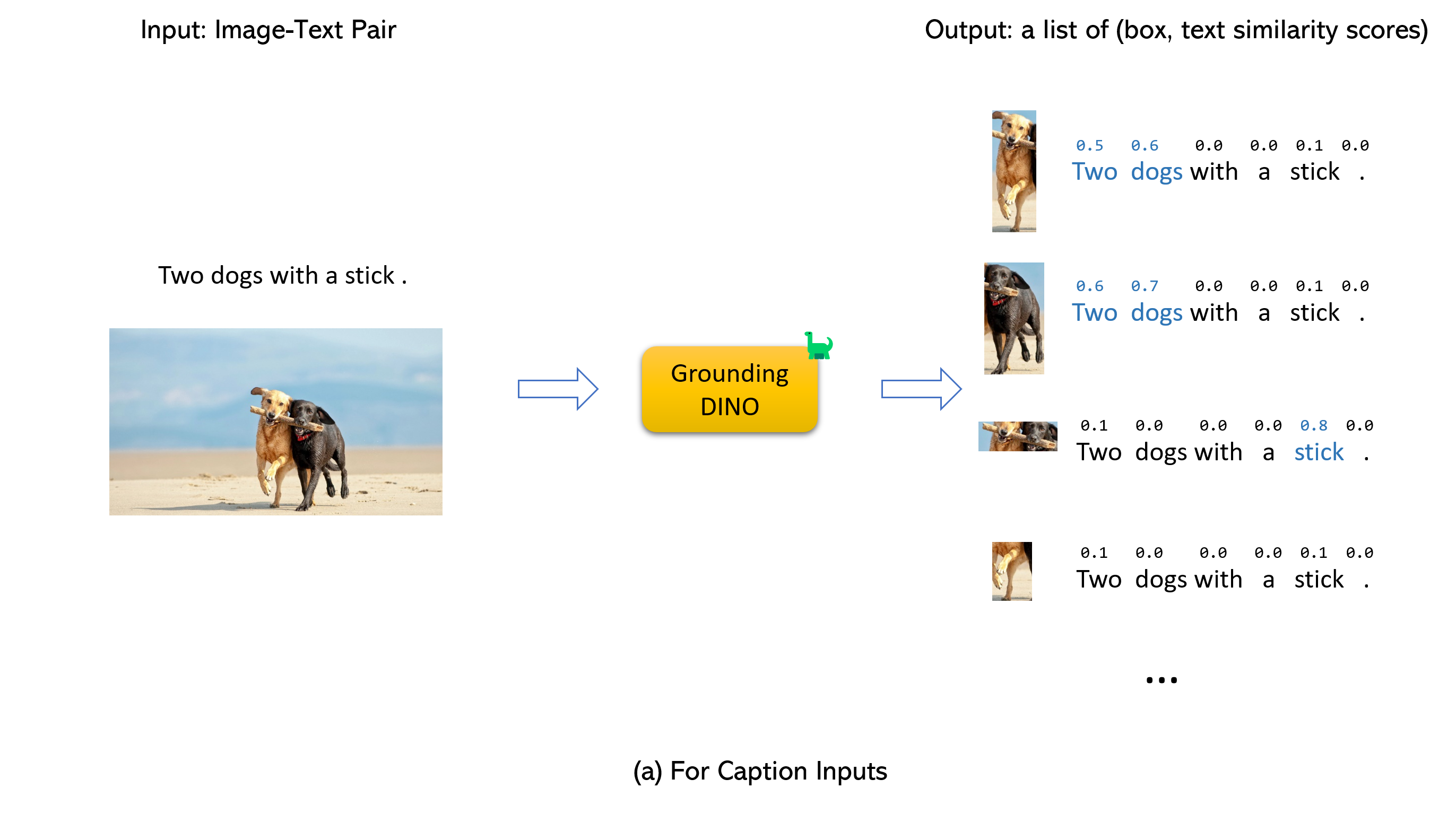
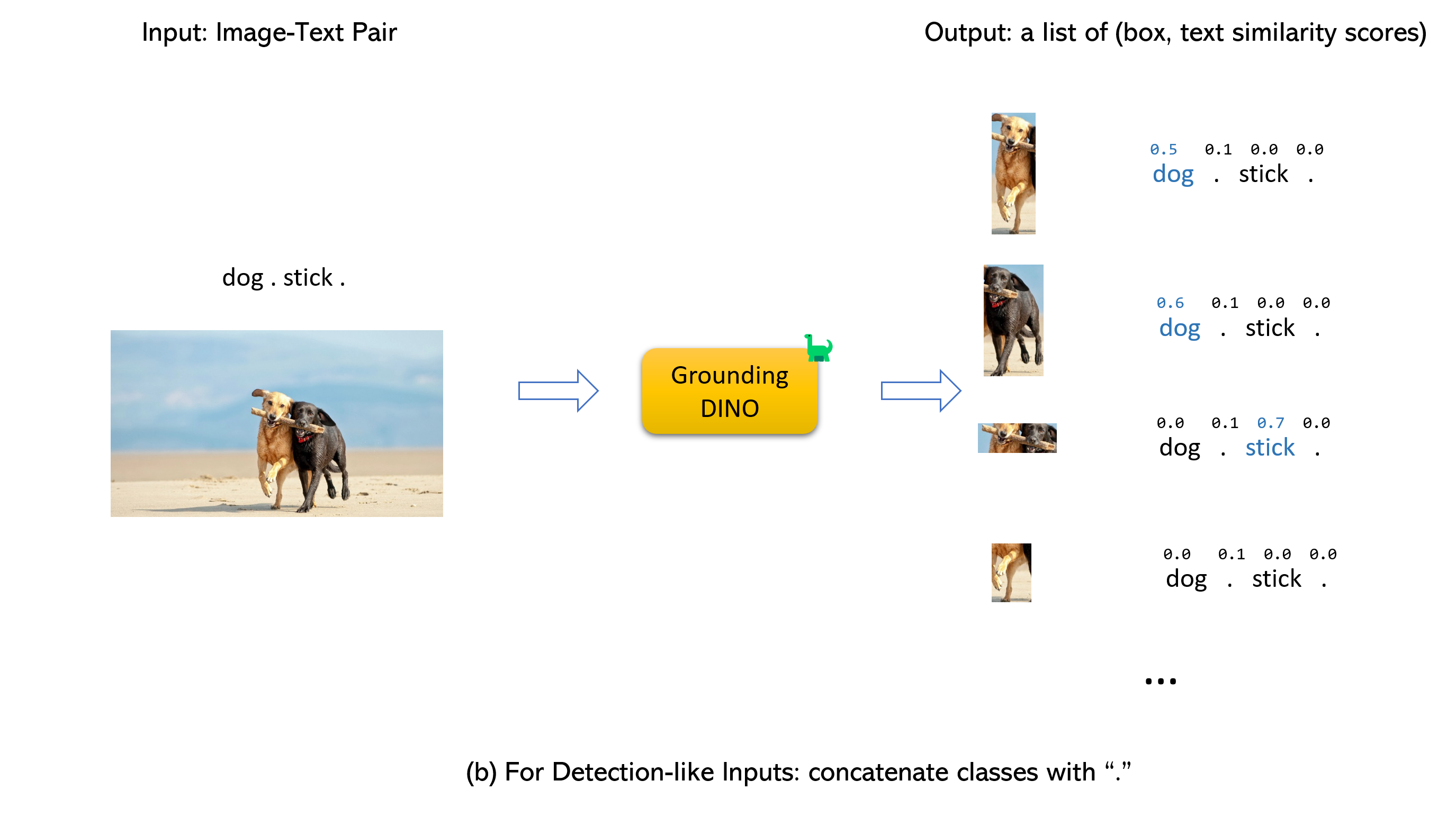
注記:
CUDA_HOMEが設定されていることを確認してください。 CUDAが利用できない場合、CPUのみのモードでコンパイルされます。インストール手順に厳密に従ってください。そうしないと、プログラムが作成する場合があります。
NameError: name ' _C ' is not definedこれが発生した場合は、Gitを再整理してGroundingDinoを再インストールし、すべてのインストール手順を再度実行してください。
echo $CUDA_HOME何も印刷していない場合、パスをセットアップしていないことを意味します/
これを実行して、環境変数が現在のシェルの下に設定されます。
export CUDA_HOME=/path/to/cuda-11.3CUDAのバージョンは、CUDAランタイムと一致する必要があることに注意してください。複数のCUDAが同時に存在する可能性があるためです。
cuda_homeを永続的に設定する場合は、以下を使用して保存します。
echo ' export CUDA_HOME=/path/to/cuda ' >> ~ /.bashrcその後、bashrcファイルをソースし、cuda_homeを確認します。
source ~ /.bashrc
echo $CUDA_HOMEこの例では、/path/to/cuda-11.3は、cudaツールキットがインストールされているパスに置き換える必要があります。これは、端末にどのNVCCを入力するかで見つけることができます。
たとえば、出力が/usr/local/cuda/bin/nvccの場合、次のとおりです。
export CUDA_HOME=/usr/local/cudaインストール:
1.GithubのGroundingDinoリポジトリをクローンします。
git clone https://github.com/IDEA-Research/GroundingDINO.git cd GroundingDINO/pip install -e .mkdir weights
cd weights
wget -q https://github.com/IDEA-Research/GroundingDINO/releases/download/v0.1.0-alpha/groundingdino_swint_ogc.pth
cd ..GPU IDを確認してください(GPUを使用している場合のみ)
nvidia-smi {GPU ID} 、 image_you_want_to_detect.jpgを置き換え、 "dir you want to save the output"という適切な値で次のコマンドに置き換えます
CUDA_VISIBLE_DEVICES={GPU ID} python demo/inference_on_a_image.py
-c groundingdino/config/GroundingDINO_SwinT_OGC.py
-p weights/groundingdino_swint_ogc.pth
-i image_you_want_to_detect.jpg
-o " dir you want to save the output "
-t " chair "
[--cpu-only] # open it for cpu mode検出するフレーズを指定したい場合は、ここにデモがあります。
CUDA_VISIBLE_DEVICES={GPU ID} python demo/inference_on_a_image.py
-c groundingdino/config/GroundingDINO_SwinT_OGC.py
-p ./groundingdino_swint_ogc.pth
-i .asset/cat_dog.jpeg
-o logs/1111
-t " There is a cat and a dog in the image . "
--token_spans " [[[9, 10], [11, 14]], [[19, 20], [21, 24]]] "
[--cpu-only] # open it for cpu mode token_spansは、フレーズの開始位置と終了位置を指定します。たとえば、最初のフレーズは[[9, 10], [11, 14]]です。 "There is a cat and a dog in the image ."[9:10] = 'a' 、 "There is a cat and a dog in the image ."[11:14] = 'cat' 。したがって、 a catフレーズを指します。同様に、 [[19, 20], [21, 24]]は、 a dogフレーズを指します。
詳細については、 demo/inference_on_a_image.pyを参照してください。
Pythonで実行:
from groundingdino . util . inference import load_model , load_image , predict , annotate
import cv2
model = load_model ( "groundingdino/config/GroundingDINO_SwinT_OGC.py" , "weights/groundingdino_swint_ogc.pth" )
IMAGE_PATH = "weights/dog-3.jpeg"
TEXT_PROMPT = "chair . person . dog ."
BOX_TRESHOLD = 0.35
TEXT_TRESHOLD = 0.25
image_source , image = load_image ( IMAGE_PATH )
boxes , logits , phrases = predict (
model = model ,
image = image ,
caption = TEXT_PROMPT ,
box_threshold = BOX_TRESHOLD ,
text_threshold = TEXT_TRESHOLD
)
annotated_frame = annotate ( image_source = image_source , boxes = boxes , logits = logits , phrases = phrases )
cv2 . imwrite ( "annotated_image.jpg" , annotated_frame )Web UI
また、グラウンドディノとGradio Web UIを統合するデモコードも提供しています。詳細については、ファイルのdemo/gradio_app.pyを参照してください。
ノートブック
ココでのDino Zero-Shotパフォーマンスを評価する例を示します。結果は48.5でなければなりません。
CUDA_VISIBLE_DEVICES=0
python demo/test_ap_on_coco.py
-c groundingdino/config/GroundingDINO_SwinT_OGC.py
-p weights/groundingdino_swint_ogc.pth
--anno_path /path/to/annoataions/ie/instances_val2017.json
--image_dir /path/to/imagedir/ie/val2017| 名前 | バックボーン | データ | ココのボックスAP | チェックポイント | config | |
|---|---|---|---|---|---|---|
| 1 | GroundingDino-T | swin-t | O365、Goldg、CAP4M | 48.4(ゼロショット) / 57.2(微調整) | GitHubリンク| HFリンク | リンク |
| 2 | GroundingDino-B | swin-b | Coco、O365、Goldg、Cap4M、OpenImage、Odinw-35、Refcoco | 56.7 | GitHubリンク| HFリンク | リンク |
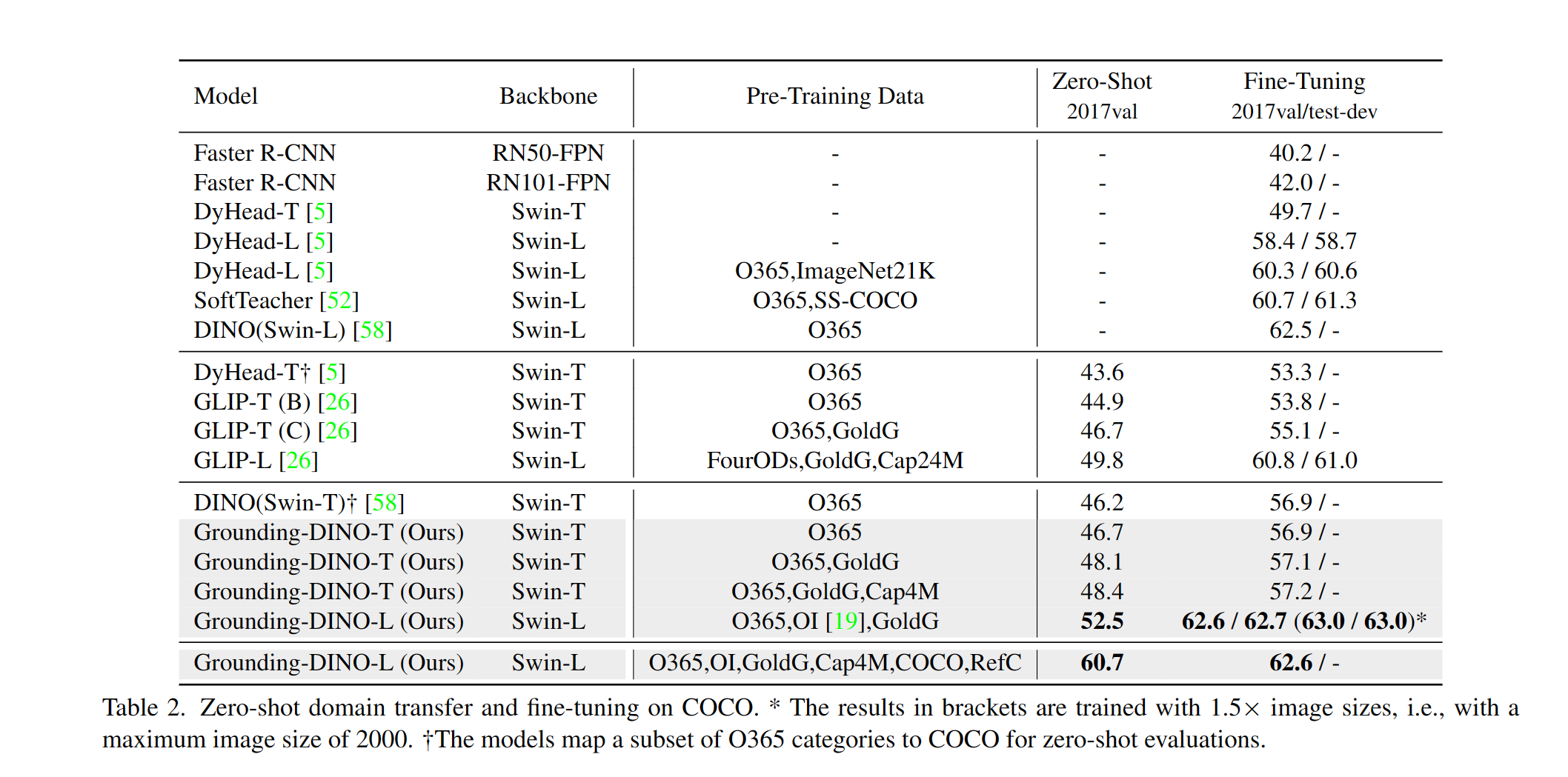
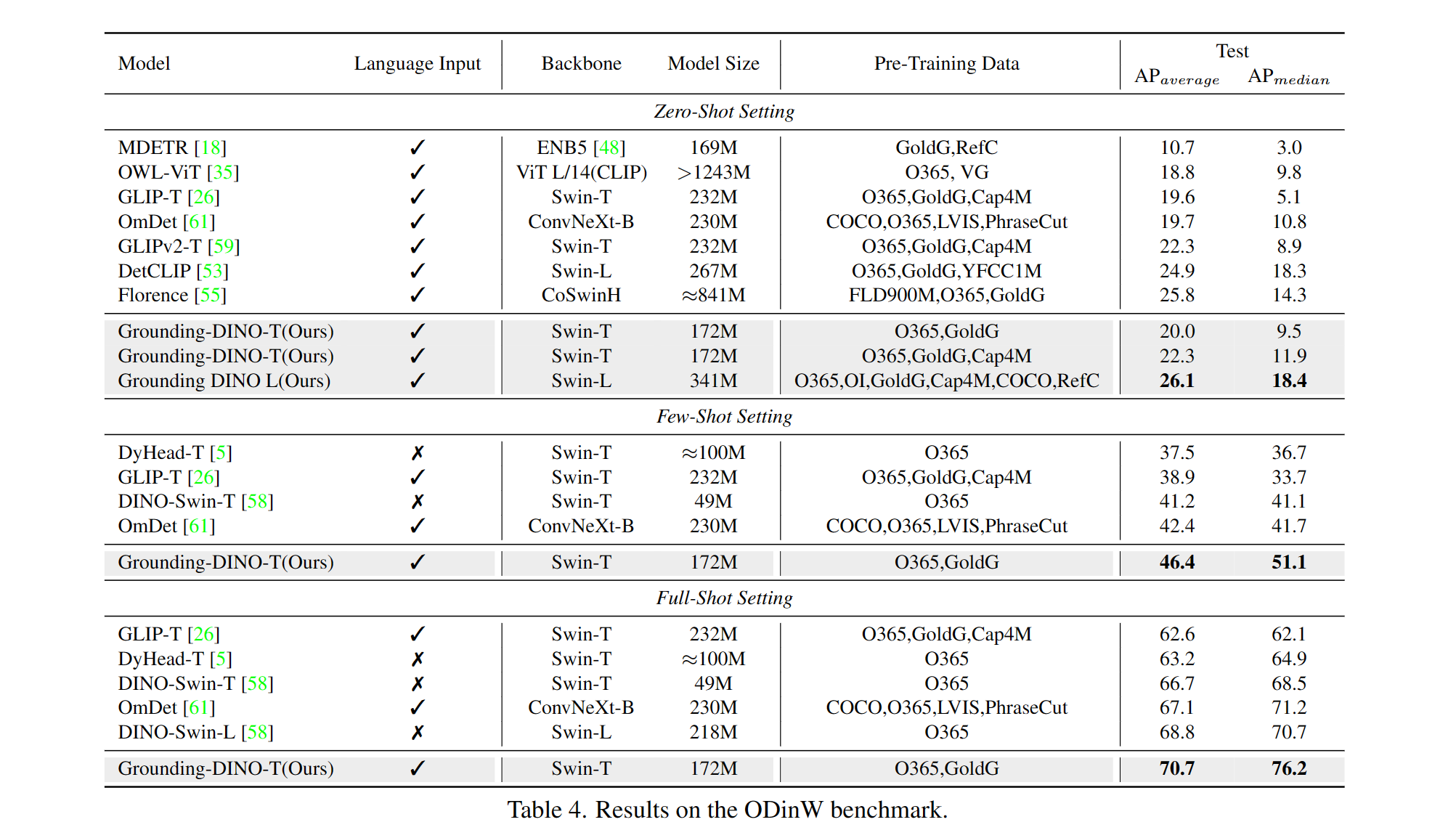

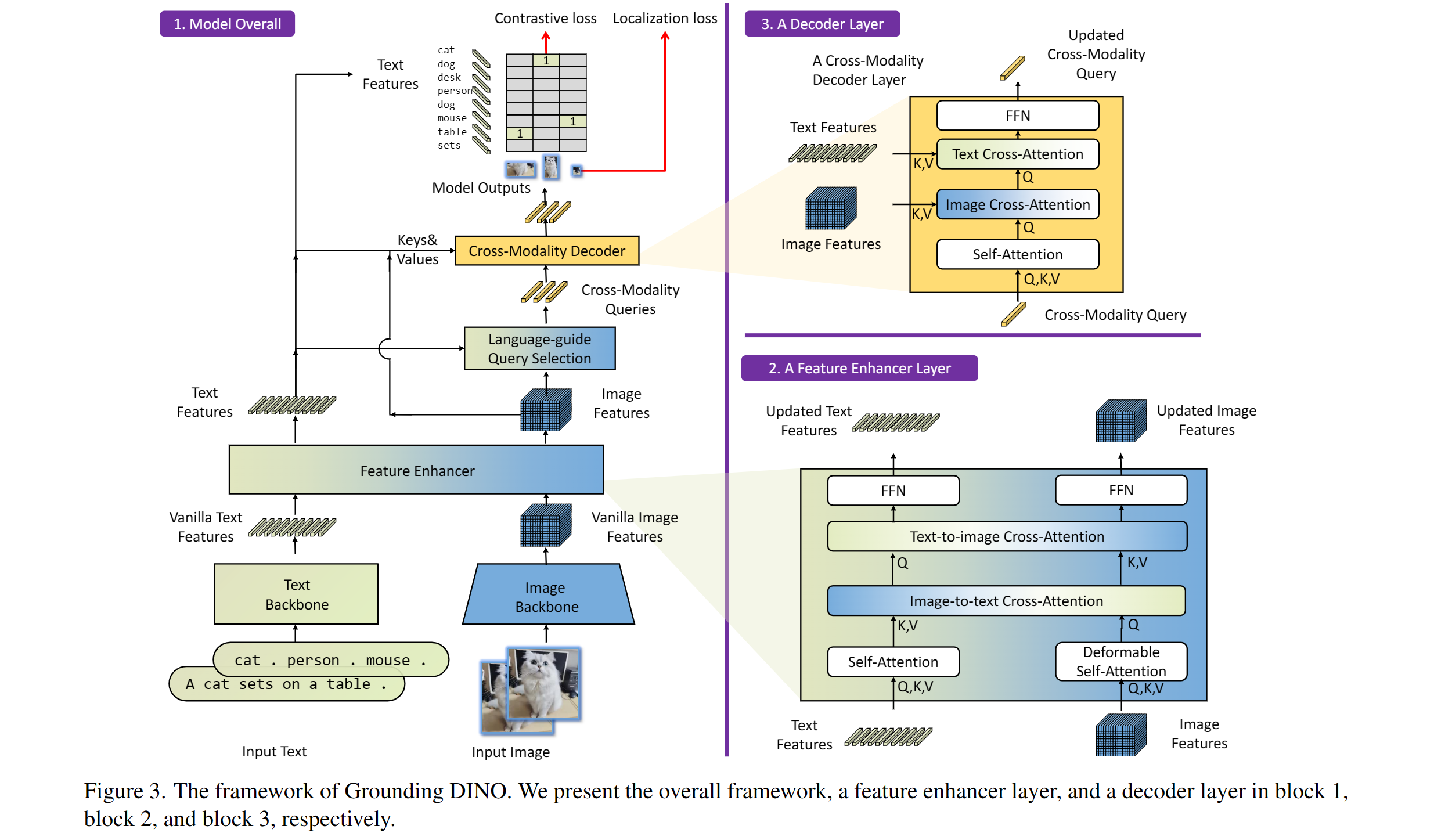
含まれるもの:テキストバックボーン、画像バックボーン、機能エンハンサー、言語誘導クエリの選択、クロスモダリティデコーダー。
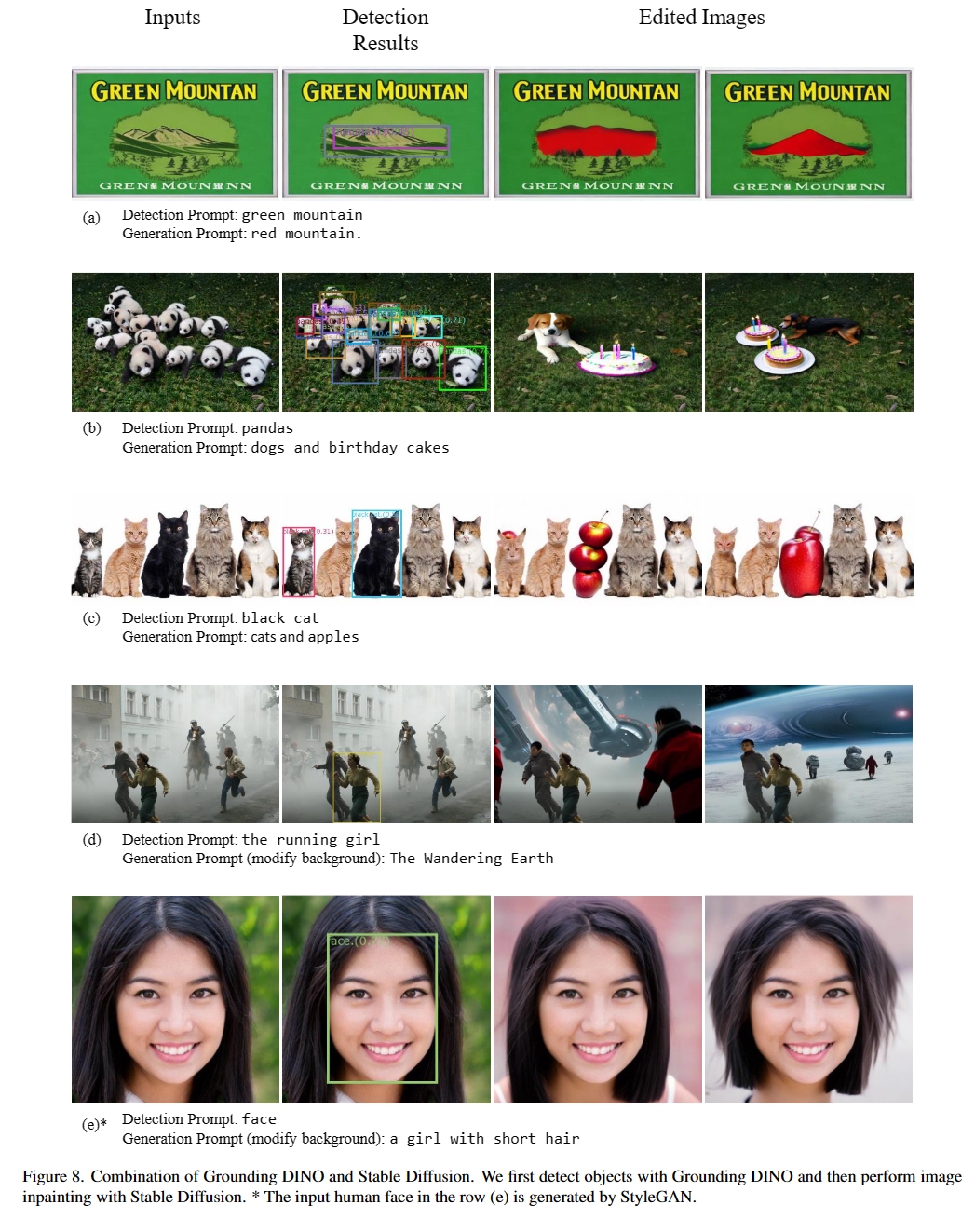
私たちのモデルはディノとグリップに関連しています。彼らの素晴らしい仕事をありがとう!
また、DETR、DERMORMABLE DETR、SMCA、条件付きDETR、アンカーDETR、ダイナミックデトル、DAB-DERT、DN-DERTなどを含む素晴らしい以前の作業にも感謝します。Awesom Detection Transformerでは、より関連する作業を利用できます。新しいToolbox DetRexも利用できます。
安定した拡散とグリゲンに感謝します。
私たちの研究があなたの研究に役立つと思うなら、次のBibtexエントリを引用することを検討してください。
@article { liu2023grounding ,
title = { Grounding dino: Marrying dino with grounded pre-training for open-set object detection } ,
author = { Liu, Shilong and Zeng, Zhaoyang and Ren, Tianhe and Li, Feng and Zhang, Hao and Yang, Jie and Li, Chunyuan and Yang, Jianwei and Su, Hang and Zhu, Jun and others } ,
journal = { arXiv preprint arXiv:2303.05499 } ,
year = { 2023 }
}

