Coqui-ai/TTSのXTTSモジュール用のカスタムComfyuiノード!
英語(en)、スペイン語(es)、フランス語(fr)、ドイツ語(de)、イタリア語(it)、ポルトガル語(pt)、ポーランド語(pl)、トルコ語(tr)、ロシア語(ru)、オランダ語(nl)、チェコ(CS)、アラビア語(AR)、中国(ZH-CN)、日本(JA)、ハンガリー(HU)、韓国(KO)ヒンディー語(HI)
コードベースの違法な使用については、DMCAおよびその他の責任を参照してください。
srtファイルがサポートされましたsrtによって推論でサポートされましたffmpegがLinuxのコマンドラインで機能していることを確認してください
apt update
apt install ffmpeg
Windowsの場合、WinetUIのffmpeg自動的にインストールできます
それから!
git clone https://github.com/AIFSH/ComfyUI-XTTS.git
cd ComfyUI-XTTS
pip install -r requirements.txt
weights自動的にハグFaceからダウンロードされます。
または、重量ファイルをダウンロードして減圧し、 pretrained_modelsのフォルダー全体をComfyUI-XTTSディレクトリに入れます
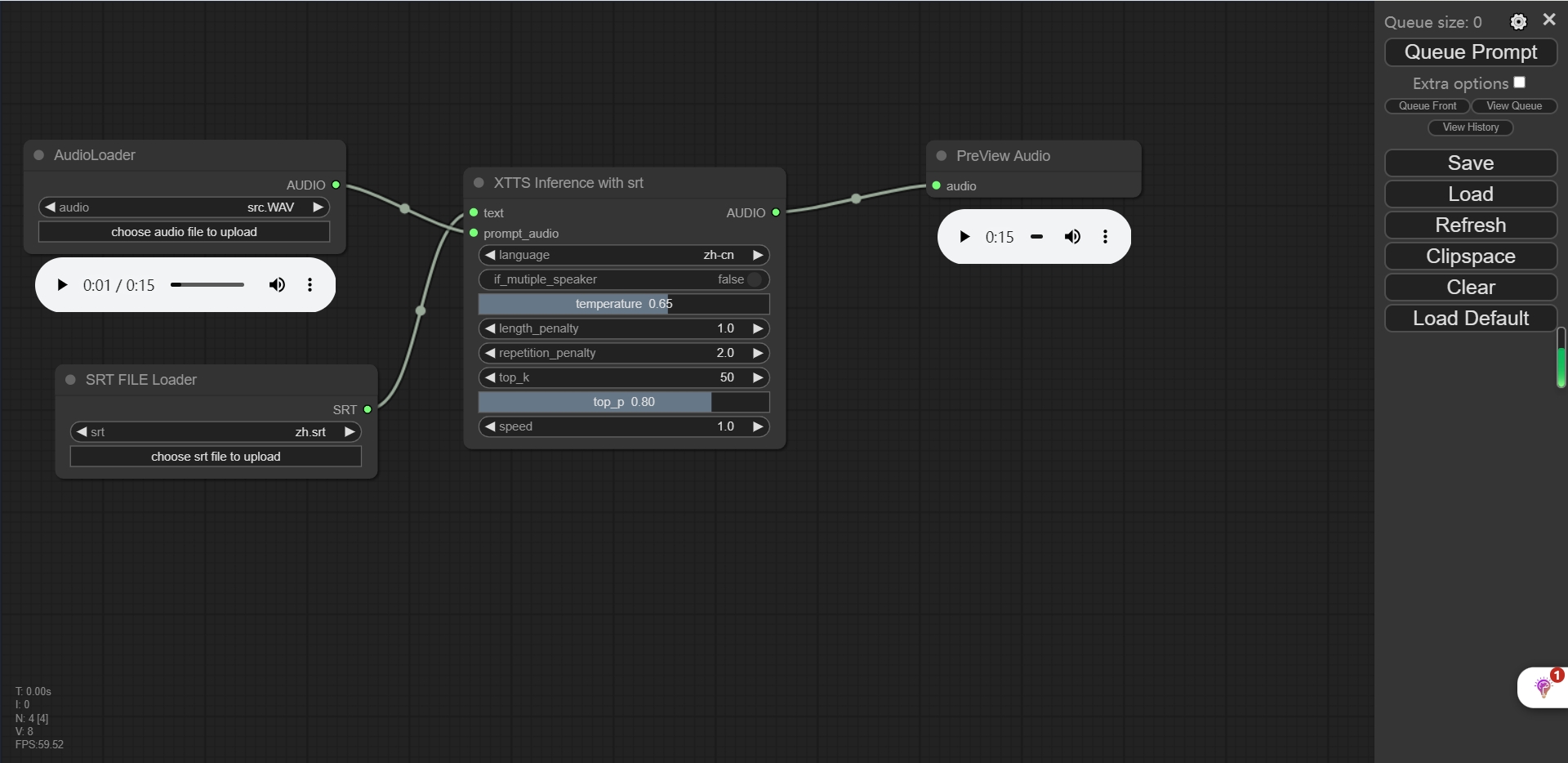
デモ
temperature :自己回帰モデルのソフトマックス温度は0.65です。
length_penalty :自動回復デコーダーに適用される長さのペナルティにより、モデルがより多くのデフォルトが生成されます。
repetition_penalty :自己回帰デコーダーがデコード中に繰り返されるのを防ぐペナルティを使用して、長い沈黙または「uhhhhhhs」などを減らすことができます。デフォルトは2.0です。
top_k :低い値は、デコーダーがより多くの「退屈な」出力を生成することを意味します。
top_p :低い値は、デコーダーがより多くの「退屈な」出力を生成することを意味します。
speed :生成されたオーディオの速度は1.0から生成できます。


Coqui-ai/tts


