paper2slides
1.0.0
ARXIVペーパーを大規模な言語モデル(LLMS)を使用してスライドに変換します!このツールは、研究論文の主なアイデアをすばやく把握するのに役立ちます。
生成されたスライドのいくつかの例は、Word2vec、Gan、Transformer、VIT、Chain-of-Ofthought、Star、DPO、およびAI科学者です。デモで生成されたスライドの他の多くの例を参照してください。
スクリプトは、インターネット(ARXIV)からファイルをダウンロードし、OpenAI APIに情報を送信し、ローカルでコンパイルします。共有されているコンテンツと潜在的なリスクについて注意してください。興味がある特定のARXIV IDがあり、自分でコードを実行したくない場合は、「ディスカッション」でお知らせください。スライドをデモリストに追加していただければ幸いです。
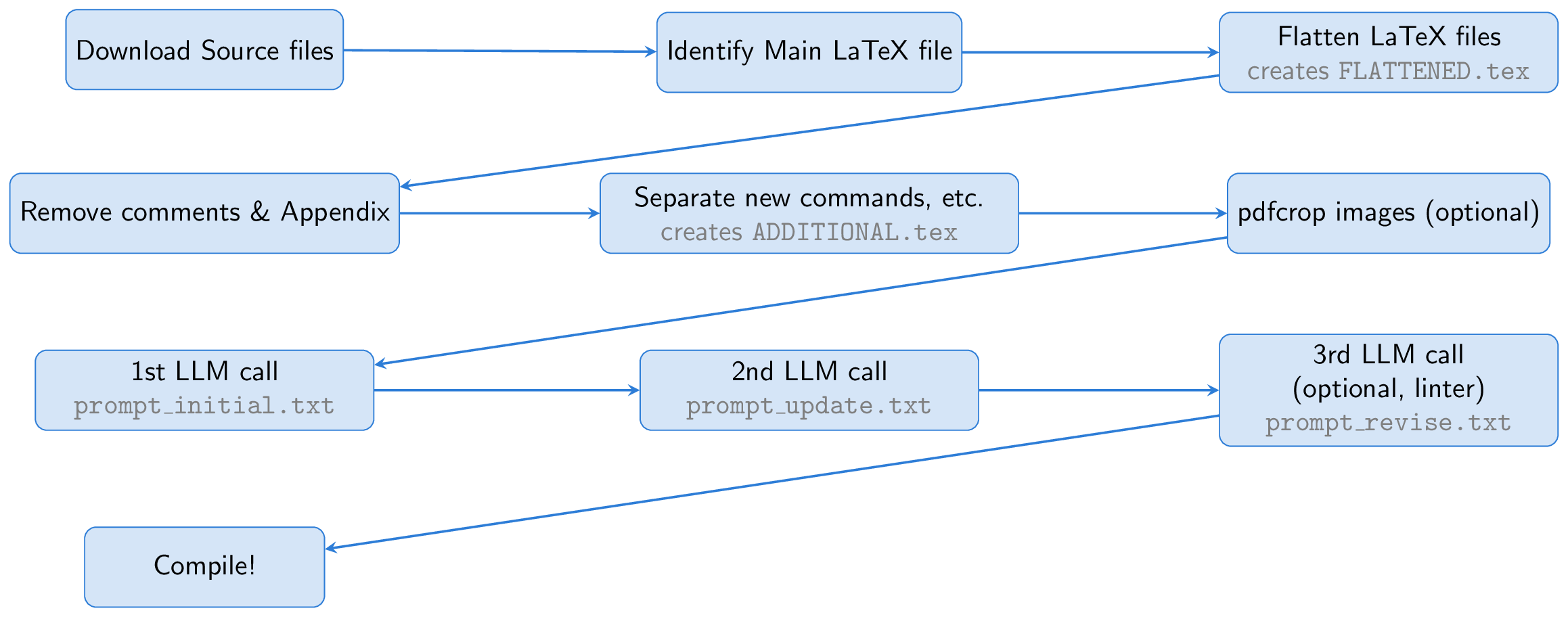
このプロセスは、ARXIVペーパーのソースファイルをダウンロードすることから始まります。メインラテックスファイルが識別され、フラット化され、すべての入力ファイルを単一のドキュメント( FLATTENED.tex )にマージします。コメントと付録を削除することにより、このマージされたファイルを事前に処理します。この前処理されたファイルは、優れたスライドを作成するための指示とともに、プロンプトの基礎を形成します。
重要なアイデアの1つは、スライド作成にビーマーを使用して、ラテックスエコシステム内に完全にとどまることができることです。このアプローチは、基本的にタスクを要約演習に変えます。長いラテックス紙を簡潔なビーマーのラテックスに変換します。 LLMは、キャプションから数字の内容を推測し、スライドにそれらを含めることができ、ビジョン能力の必要性を排除できます。
LLMを支援するために、必要なすべてのパッケージ、 newCommand定義、およびペーパーで使用されるその他のラテックス設定を含む追加のADDITIONAL.texというファイルを作成します。プロンプトのinput{ADDITIONAL.tex}を使用したこのファイルを含めると、特に多くのカスタムコマンドを備えた理論論文の場合、生成スライドがより信頼性を高めます。
LLMはラテックスソースからビーマーコードを生成しますが、最初の実行には問題が発生する可能性があるため、LLMに出力を自己検討して改良するように依頼します。オプションでは、3番目のステップでは、リナーを使用して生成されたコードを確認し、結果がLLMに供給され、さらに修正されます(このリナーステップはAI科学者に触発されました)。最後に、BeamerコードはPDFLATEXを使用してPDFプレゼンテーションにコンパイルされます。
all.zshスクリプトはプロセス全体を自動化し、通常、1つのペーパーでGPT-4oで数分以内に完了します。
要件は次のとおりです。
requestsarxivライブラリopenaiライブラリarxiv-latex-cleanerライブラリpdflatexの実用的なインストールインストールの手順:
このリポジトリをクローンします:
git clone https://github.com/takashiishida/paper2slides.git
cd paper2slides必要なPythonパッケージをインストールします。
pip install requests arxiv openai arxiv-latex-cleaner pdflatexがインストールされ、システムのパスで利用可能になっていることを確認してください。オプションで、 pdflatex test.texによってサンプルtest.texをコンパイルできるかどうかを確認します。 test.pdfが正しく生成されているかどうかを確認してください。オプションで、 chktexとpdfcropが動作していることを確認します。
Openai APIキーを設定します:
export OPENAI_API_KEY= ' your-api-key ' all.shスクリプトを使用しますこのスクリプトは、ARXIVペーパーをダウンロードし、処理し、ビーマープレゼンテーションに変換するプロセスを自動化します。
bash all.sh < arxiv_id > <arxiv_id>目的のARXIVペーパーIDに置き換えます。 IDは、 xxxx.xxxx https://arxiv.org/abs/xxxx.xxxxのIDのURLから識別できます。
Pythonスクリプトを個別に実行して、より多くの制御を行うこともできます。
ARXIVソースファイルをダウンロードして処理します
python arxiv2tex.py < arxiv_id >このスクリプトは、指定されたArxivペーパーのソースファイルをダウンロードし、それらを抽出し、メインのLaTexファイルを処理します。結果はsource/<arxiv_id>/FLATTENED.texおよびsource/<arxiv_id>/ADDITIONAL.texに保存されます。
ラテックスをビーマーに変換します
python tex2beamer.py --arxiv_id < arxiv_id >このスクリプトは、処理されたラテックスファイルを読み取り、ビーマースライドを準備します。これは、OpenAI APIを使用している場所です。最初に2回電話して、ビーマーコードを生成し、次にビーマーコードを自己検査します。オプションで次の--use_linterを使用し--use_pdfcrop 。 LLMに送信されたプロンプトとLLMからの応答は、 tex2beamer.logで保存されます。リナーログはsource/<arxiv_id>/linter.logに保存されます。
ビーマーをPDFに変換します
python beamer2pdf.py < arxiv_id >このスクリプトは、BeamerファイルをPDFプレゼンテーションにコンパイルします。
プロンプトは、 prompt_initial.txt 、 prompt_update.txt 、およびprompt_revise.txtに保存されますが、ニーズに合わせて自由に調整してください。 PLACEHOLDER_FOR_FIGURE_PATHSというプレースホルダーが含まれています。これは、論文で使用されているフィギュアパスに置き換えられます。パスがビーマーコードで正しく使用されていることを確認したいと考えています。 LLMはしばしば間違いを犯すため、これをプロンプトに明示的に含めます。
私の経験では、成功率は約90%です(コンパイルが失敗する可能性があるか、場合によっては画像パスが間違っている可能性があります)。問題が発生したり、改善の提案がある場合は、お気軽にお知らせください!


