OneForAll
1.0.0
論文:https://arxiv.org/abs/2310.00149
著者:Hao Liu、Jiarui Feng、Lecheng Kong、Ningyue Liang、Dacheng Tao、Yixin Chen、Muhan Zhang
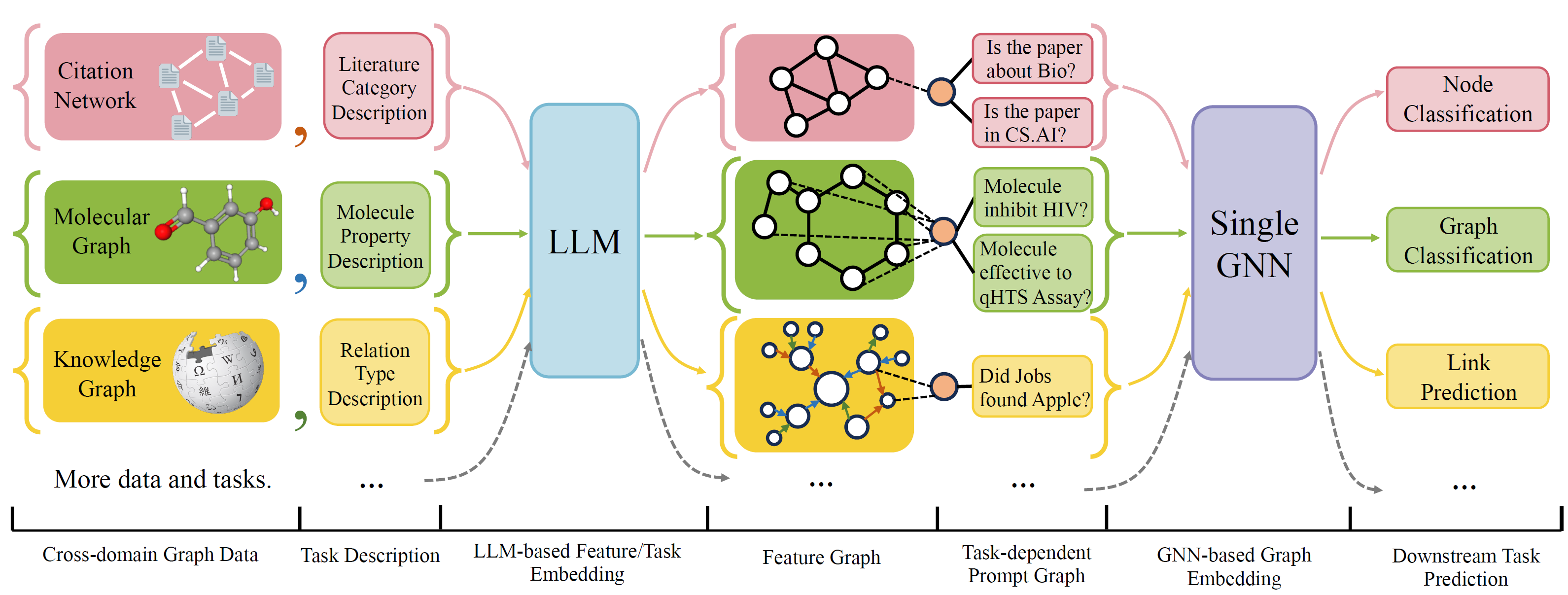
OFAは、単一のモデルと単一のパラメーターセットを備えた幅広いグラフ分類タスクを解決できる一般的なグラフ分類フレームワークです。タスクは、クロスドメイン(例えば、引用ネットワーク、分子グラフなど)とクロスタスク(例えば、少数のショット、ゼロショット、グラフレベル、ノードレーブ、...)です。
自然言語を使用してすべてのグラフを記述し、LLMを使用してすべての説明を同じ埋め込みスペースに埋め込み、単一のモデルを使用してクロスドメイントレーニングを可能にします。
OFAは、すべてのタスク情報がプロンプトグラフに変換されることをプロンプトパラディアグムに提案します。したがって、サブシーケンスモデルは、モデルパラメーターとアーキテクチャを調整することなく、タスク情報を読み取り、それに応じてリリーブターゲットを予測することができます。したがって、単一のモデルはクロスタスクにすることができます。
OFAは、異なるソースとドメインからグラフデータセットのリストをキュレーションし、体系的な減少プロトコルを使用してグラフのノード/エッジを説明しました。 OGB、Gimlet、Moleculenet、Graphllm、Villmowなど、以前の作品に感謝します。
OneForAllは大規模な改訂を受け、コードをクリーンアップし、報告されたいくつかのバグを修正しました。主要な更新は次のとおりです。
以前にリポジトリを使用した場合は、古い生成された機能/テキストファイルをプルして削除して再生してください。ご不便をおかけして申し訳ありません。
コンドラを使用してプロジェクトの要件をインストールするには:
conda env create -f environment.yml
収集されたすべてのデータセットでの共同エンドツーエンドの実験の場合、実行します
python run_cdm.py --override e2e_all_config.yaml
すべての引数は、ようなスペース分離値によって変更できます
python run_cdm.py --override e2e_all_config.yaml num_layers 7 batch_size 512 dropout 0.15 JK none
ユーザーは、 ./e2e_all_config.yamlのtask_names変数を変更して、トレーニング中に含まれるデータセットを制御できます。 task_names 、 d_multiple 、およびd_min_ratioの長さは同じでなければなりません。また、コンマ分離値によってコマンドライン引数で指定することもできます。
例えば
python run_cdm.py task_names cora_link,arxiv d_multiple 1,1 d_min_ratio 1,1
ofa-indはによって指定できます
python run_cdm.py task_names cora_link d_multiple 1 d_min_ratio 1
少数のショットとゼロショットの実験を実行します
python run_cdm.py --override lr_all_config.yaml
各タスクの構成を定義します。各タスク構成には、いくつかのデータセット構成が含まれています。
タスク構成は./configs/task_config.yamlに保存されます。タスクは通常、データセットのいくつかの分割(必ずしも同じデータセットではありません)になります。たとえば、通常のエンドツーエンドのCORAノード分類タスクには、列車データセットとして列車の分割、有効なデータセットの1つとしてCORAデータセットの有効な分割、同様にテスト分割のために列車が分割されます。また、検証/テストデータセットの1つとしてCORAの列車分割を指定することにより、より多くの検証/テストを受けることもできます。具体的には、タスク構成は次のようになります
arxiv :
eval_pool_mode : mean
dataset : arxiv # dataset name
eval_set_constructs :
- stage : train # a task should have one and only one train stage dataset
split_name : train
- stage : valid
split_name : valid
dataset : cora # replace the default dataset for zero-shot tasks
- stage : valid
split_name : valid
- stage : test
split_name : test
- stage : test
split_name : train # test the train splitデータセット構成は./configs/task_config.yamlに保存されます。データセット構成は、データセットの構築方法を定義します。具体的には、
arxiv :
task_level : e2e_node
preprocess : null # name of the preprocess function defined in task_constructor.py
construct : ConstructNodeCls # name of the dataset construction function defined in task_constructor.py
args : # additional arguments to construct function
walk_length : null
single_prompt_edge : True
eval_metric : acc # evaluation metric
eval_func : classification_func # evaluation function that process model output and batch to input to evaluator
eval_mode : max # evaluation mode (min/max)
dataset_name : arxiv # name of the OFAPygDataset
dataset_splitter : ArxivSplitter # splitting function defined in task_constructor.py
process_label_func : process_pth_label # name of process label function that transform original label to the binary labels
num_classes : 40 Cora/PubMed/Arxivなどのデータセットを実装している場合は、データ/single_graph/$ customized_data $の下に$ customized_data $のデータのディレクトリを追加することをお勧めします。例としてのpy。
データが作成されたら、ここにデータセット名を登録し、こちらのようなスプリッターを実装する必要があります。ゼロショット/少ないショットタスクを行っている場合は、ここでもコンストラクターゼロショット/少数のショット分割を分割できます。
最後に、configs/data_config.yamlに構成エントリを登録します。たとえば、エンドツーエンドのノード分類の場合
$data_name$ :
<< : *E2E-node
dataset_name : $data_name$
dataset_splitter : $splitter$
process_label_func : ... # usually processs_pth_label should work
num_classes : $number of classes$process_label_funcは、ターゲットラベルをバイナリラベルに変換し、クラスの埋め込みを変換します。タスクがゼロショット/少数のショットであり、クラスノードの数が固定されていません。 Avalailable Process_label_funcのリストはこちらです。すべてのクラスが埋め込まれ、正しいラベルが必要です。出力はタプルです:(ラベル、class_node_embeding、binary/one-hotラベル)。
より柔軟性が必要な場合は、カスタマイズされたデータセットを追加するには、ofapygdatasetのカスタマイズされたサブクラスの実装が必要です。テンプレートはこちらです。
class CustomizedOFADataset ( OFAPygDataset ):
def gen_data ( self ):
"""
Returns a tuple of the following format
(data, text, extra)
data: a list of Pyg Data, if you only have a one large graph, you should still wrap it with the list.
text: a list of list of texts. e.g. [node_text, edge_text, label_text] this is will be converted to pooled vector representation.
extra: any extra data (e.g. split information) you want to save.
"""
def add_text_emb ( self , data_list , text_emb ):
"""
This function assigns generated embedding to member variables of the graph
data_list: data list returned in self.gen_data.
text_emb: list of torch text tensor corresponding to the returned text in self.gen_data. text_emb[0] = llm_encode(text[0])
"""
data_list [ 0 ]. node_text_feat = ... # corresponding node features
data_list [ 0 ]. edge_text_feat = ... # corresponding edge features
data_list [ 0 ]. class_node_text_feat = ... # class node features
data_list [ 0 ]. prompt_edge_text_feat = ... # edge features used in prompt node
data_list [ 0 ]. noi_node_text_feat = ... # noi node features, refer to the paper for the definition
return self . collate ( data_list )
def get_idx_split ( self ):
"""
Return the split information required to split the dataset, this optional, you can further split the dataset in task_constructor.py
"""
def get_task_map ( self ):
"""
Because a dataset can have multiple different tasks that requires different prompt/class text embedding. This function returns a task map that maps a task name to the desired text embedding. Specifically, a task map is of the following format.
prompt_text_map = {task_name1: {"noi_node_text_feat": ["noi_node_text_feat", [$Index in data[0].noi_node_text_feat$]],
"class_node_text_feat": ["class_node_text_feat",
[$Index in data[0].class_node_text_feat$]],
"prompt_edge_text_feat": ["prompt_edge_text_feat", [$Index in data[0].prompt_edge_text_feat$]]},
task_name2: similar to task_name 1}
Please refer to examples in data/ for details.
"""
return self . side_data [ - 1 ]
def get_edge_list ( self , mode = "e2e" ):
"""
Defines how to construct prompt graph
f2n: noi nodes to noi prompt node
n2f: noi prompt node to noi nodes
n2c: noi prompt node to class nodes
c2n: class nodes to noi prompt node
For different task/mode you might want to use different prompt graph construction, you can do so by returning a dictionary. For example
{"f2n":[1,0], "n2c":[2,0]} means you only want f2n and n2c edges, f2n edges have edge type 1, and its text embedding feature is data[0].prompt_edge_text_feat[0]
"""
if mode == "e2e_link" :
return { "f2n" : [ 1 , 0 ], "n2f" : [ 3 , 0 ], "n2c" : [ 2 , 0 ], "c2n" : [ 4 , 0 ]}
elif mode == "lr_link" :
return { "f2n" : [ 1 , 0 ], "n2f" : [ 3 , 0 ]}

