효율적인 언어 감지기
3.0.0
효율적인 언어 감지기( Nito-ELD 또는 ELD )는 100% PHP로 작성된 빠르고 정확한 자연어 감지 소프트웨어로, 빠른 C++ 컴파일 감지기에 필적하는 속도와 현재 최고의 감지기 범위 내의 정확도를 제공합니다.
종속성이 없고 설치가 쉬우며 필요한 것은 mb 확장자를 가진 PHP뿐입니다.
ELD는 Javascript 및 Python에서도 사용할 수 있습니다(오래된 버전).
설치
사용방법
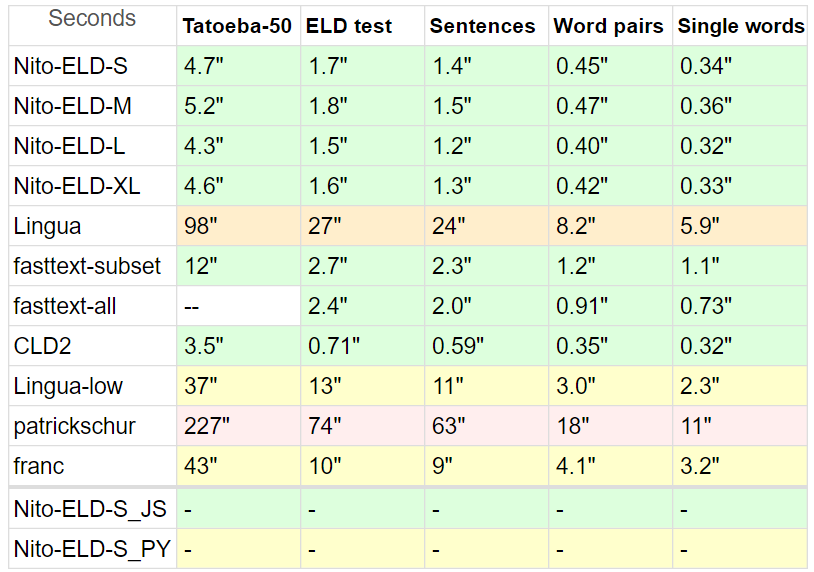
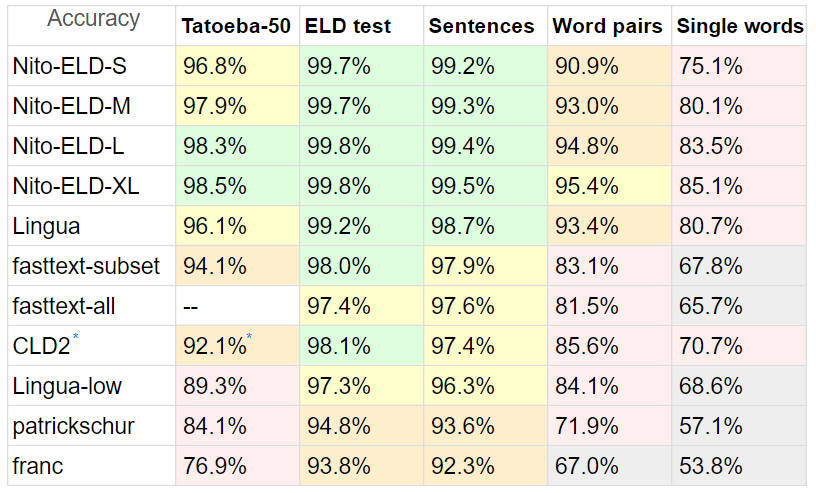
벤치마크
데이터베이스
테스트
언어
ELD v2에서 v3으로의 변경 사항:
detector()->언어는 이제
NULL대신 undetermined 에 대해 문자열'und'반환합니다.데이터베이스는 호환되지 않으며 더 큰, 중간 v2 ≒ 작은 v3
DynamicLangSubset() 함수가 제거되었습니다.
cleanText() 함수의 이름은 이제 활성화TextCleanup()입니다.
$ 작곡가에는 nitotm/효율적인 언어 감지기가 필요합니다.
--prefer-dist 테스트/ , 기타/ 및 벤치마킹/을 생략하거나 --prefer-source 사용하여 모든 것을 포함합니다.
마지막 불안정한 변경 사항을 시도하려면 nitotm/efficient-language-detector:dev-main 설치하세요.
또는 파일을 다운로드/복제해도 문제 없이 작동할 수 있습니다.
( 소형 DB만 설치 공사중)
특히 대규모 데이터베이스의 경우 로드 시간을 줄이기 위해 OPcache를 사용하는 것이 좋습니다.
각 데이터베이스에 대해 opcache.interned_strings_buffer , opcache.memory_consumption 충분히 높게 설정해야 합니다.
괄호 안은 권장 값입니다. 자세한 내용은 데이터베이스를 확인하세요.
| php.ini 설정 | 작은 | 중간 | 크기가 큰 | 특대화하다 |
|---|---|---|---|---|
memory_limit | >= 128 | >= 340 | >= 1060 | >= 2200 |
opcache.interned... | >= 8 (16) | >= 16 (32) | >= 60 (70) | >= 116 (128) |
opcache.memory | >= 64 (128) | >= 128 (230) | >= 360 (450) | >= 750 (820) |
detect() UTF-8 문자열을 예상하고 ISO 639-1 코드(또는 기타 선택된 형식)를 포함하는 language 속성이 있는 객체를 반환하거나, 결정되지 않은 언어의 경우 'und' 반환합니다.
// require_once 'manual_loader.php'; 오토로더 없이 ELD를 로드합니다. 경로 업데이트. NitotmEld{LanguageDetector, EldDataFile, EldFormat};// LanguageDetector(databaseFile: ?string, outputFormat: ?string)$eld = new LanguageDetector(EldDataFile::SMALL, EldFormat::ISO639_1);// 데이터베이스 파일: ' 소형', '중형', '대형', '특대형'. 메모리 요구 사항 확인// 형식: 'ISO639_1', 'ISO639_2T', 'ISO639_1_BCP47', 'ISO639_2T_BCP47' 및 'FULL_TEXT'// 상수는 필수가 아닙니다. LanguageDetector('small', 'ISO639_1'); 또한 작동합니다$eld->Detect('Hola, como te llamas?');// object( 언어 => string, Score() => array, isReliable() => bool )// ( 언어 => 'es', Score() => ['es' => 0.25, 'nl' => 0.05], isReliable() => true )$eld->Detect('안녕하세요, 라마가 있나요?') ->언어;// 'es' langSubset() 한 번 호출하면 하위 집합이 설정됩니다. 첫 번째 호출은 새 데이터베이스를 생성하므로 시간이 더 오래 걸립니다. 데이터베이스 파일을 저장하면(기본값) 다음에 동일한 하위 집합을 만들 때 로드됩니다.
추가 오버헤드 없이 하위 집합을 사용하려면 langSubset() 에 의해 저장되고 반환된 파일로 감지기를 인스턴스화하는 것이 올바른 방법입니다. 아래에서 사용 가능한 언어를 확인하세요.
// 항상 ISO 639-1 코드와 다른 경우 선택한 출력 형식을 허용합니다.// langSubset(언어: [], save: true, encode: true); 저장된 경우 하위 집합 파일 이름을 반환합니다.$eld->langSubset(['en', 'es', 'fr', 'it', 'nl', 'de']);// Object ( 성공 => bool, 언어 => ?array, error => ?string, file => ?string )// ( 성공 => true, 언어 => ['en', 'es'...], error => NULL, file => ' small_6_mfss...' )// 하위 집합을 제거하려면$eld->langSubset();// 하위 집합을 사용하는 가장 좋고 빠른 방법은 기본 데이터베이스처럼 로드하는 것입니다.$eld_subset = new NitotmEldLanguageDetector('small_6_mfss5z1t' );// 활성화TextCleanup(True)인 경우, discover()는 Urls, .com 도메인, 이메일, 영숫자를 제거합니다...// URL 및 도메인에는 정확도에 도움이 될 수 있는 언어 힌트가 포함되어 있으므로 권장되지 않습니다.$eld->enableTextCleanup(true ); // 기본값은 false입니다.// 필요한 경우 ELD 인스턴스의 언어, 데이터베이스 유형 등 정보를 얻을 수 있습니다.$eld->info();
PHP에는 ELD가 많지 않기 때문에 다양한 감지기와 ELD를 비교했습니다.
| URL | 버전 | 언어 |
|---|---|---|
| https://github.com/nitotm/효율적인-언어-검출기/ | 3.0.0 | PHP |
| https://github.com/pemistahl/lingua-py | 2.0.2 | 파이썬 |
| https://github.com/facebookresearch/fastText | 0.9.2 | C++ |
| https://github.com/CLD2Owners/cld2 | 2015년 8월 21일 | C++ |
| https://github.com/patrickschur/언어-감지 | 5.3.0 | PHP |
| https://github.com/wooorm/franc | 7.2.0 | 자바스크립트 |
벤치마크:
Tatoeba : 20MB , Tatoeba의 짧은 문장, 모든 경쟁자가 지원하는 50개 언어, 각각 최대 10,000줄.
Tatoeba의 경우 모든 탐지기를 50개 언어 하위 집합으로 제한하여 비교를 최대한 공정하게 만들었습니다.
또한 Tatoeba는 ELD 교육 데이터 세트(튜닝도 아님)의 일부가 아니지만 fasttext 용입니다.
ELD 테스트 : 10MB , ELD가 지원하는 60개 언어의 문장, 각각 1000줄. 60GB의 ELD 훈련 데이터에서 추출되었습니다.
문장 : 8MB , Lingua 벤치마크의 문장에서 지원되지 않는 언어와 문자가 깨진 요루바어를 뺀 것입니다.
단어 쌍은 1.5MB 이고 단일 단어는 870KB입니다 . 역시 Lingua에서 가져온 것이며 동일한 53개 언어입니다.


링구아는 54개 언어, 프랑크 는 58개, 패트릭슈어는 54개 언어로 참여합니다.
fasttext에는 하위 집합 옵션이 내장되어 있지 않으므로 정확성과 속도 잠재력을 보여주기 위해 두 가지 벤치마크를 만들었습니다. fasttext는 모든 테스트에서 하위 집합에 의해 제한되지 않습니다.
* Google의 CLD2 에도 하위 집합 옵션이 없으며 bestEffort = True 옵션을 사용해도 하위 집합을 만들기가 어렵습니다. 일반적으로 하나의 언어만 반환하므로 상대적인 단점이 있습니다.
시간은 정규화됩니다: (총 라인 * 시간) / 처리된 라인
| 작은 | 중간 | 크기가 큰 | 특대화하다 | |
|---|---|---|---|---|
| 장점 | 최저 메모리 | 평형화됨 | 가장 빠른 | 가장 정확함 |
| 단점 | 가장 정확하지 않음 | 가장 느림(그러나 빠름) | 높은 메모리 | 최고 메모리 |
| 파일 크기 | 3MB | 10MB | 32MB | 71MB |
| 메모리 사용량 | 76MB | 280MB | 977MB | 2083MB |
| 캐시된 메모리 사용량 | 0.4MB + OP | 0.4MB + OP | 0.4MB + OP | 0.4MB + OP |
| OPcache가 메모리를 사용함 | 21MB | 69MB | 244MB | 539MB |
| 인턴된 OPcache 사용 | 4MB | 10MB | 45MB | 98MB |
| 로드 시간 캐시되지 않음 | 0.14초 | 0.5초 | 1.5초 | 3.4초 |
| 로드 시간 캐시됨 | 0.0002초 | 0.0002초 | 0.0002초 | 0.0002초 |
| 설정 (권장) | ||||
memory_limit | >= 128 | >= 340 | >= 1060 | >= 2200 |
opcache.interned... * | >= 8 (16) | >= 16 (32) | >= 60 (70) | >= 116 (128) |
opcache.memory | >= 64 (128) | >= 128 (230) | >= 360 (450) | >= 750 (820) |
* 버퍼 오버플로 오류로 인해 서버 응답이 지연될 수 있으므로 interned_strings_buffer 충분히 많이 사용하는 것이 좋습니다.
모든 데이터베이스를 사용하려면 opcache.interned_strings_buffer 최소 160MB(170MB)여야 합니다.
메모리 양을 선택할 때 opcache.memory_consumption 에는 opcache.interned_strings_buffer 포함되어 있다는 점을 명심하세요.
OPcache 메모리가 230MB이고 interned_strings가 32MB이고 중간 DB가 69MB 캐시된 경우 다른 모든 항목에 대해 총 (230 -32 -69) = 129MB의 OPcache가 있습니다.
또한 기본 데이터베이스 외에 언어 하위 집합을 사용하거나 여러 하위 집합을 사용하려는 경우 즉시 로드되도록 하려면 그에 따라 opcache.memory 늘리십시오. 모든 기본 데이터베이스를 편안하게 캐시하려면 1200MB로 설정하는 것이 좋습니다.
기본 작성기 설치에는 이러한 파일이 포함되지 않을 수 있습니다. 이를 포함하려면 --prefer-source 사용하세요.
작곡가 "autoload-dev" (루트 전용)가 있는 개발 환경의 경우 다음과 같이 테스트가 실행됩니다.
새로운 NitotmEldTestsTestsAutoload();
또는 다음 파일을 실행하여 테스트를 실행할 수도 있습니다.
$ php 효율적인-언어-검출기/tests/tests.php # 업데이트 경로
정확도 벤치마크를 실행하려면 benchmark/bench.php 파일을 실행하세요.
이는 60개 언어를 포함하는 ISO 639-1 코드 입니다. 더하기 'und' (미정)
이는 기본 ELD 언어 형식입니다. outputFormat: 'ISO639_1'
am, ar, az, be, bg, bn, ca, cs, da, de, el, en, es, et, eu, fa, fi, fr, gu, he, hi, hr, hu, hy, is, it, ja, ka, kn, ko, ku, lo, lt, lv, ml, mr, ms, nl, no, 또는, pa, pl, pt, ro, ru, sk, sl, sq, sr, sv, ta, te, th, tl, tr, uk, ur, vi, yo, zh
Nito-ELD 에 지원되는 60개 언어는 다음과 같습니다. outputFormat: 'FULL_TEXT'
암하라어, 아랍어, 아제르바이잔어(라틴어), 벨로루시어, 불가리아어, 벵골어, 카탈로니아어, 체코어, 덴마크어, 독일어, 그리스어, 영어, 스페인어, 에스토니아어, 바스크어, 페르시아어, 핀란드어, 프랑스어, 구자라트어, 히브리어, 힌디어, 크로아티아어, 헝가리어, 아르메니아어 , 아이슬란드어, 이탈리아어, 일본어, 조지아어, 칸나다어, 한국어, 쿠르드어(아랍어), 라오스, 리투아니아어, 라트비아어, 말라얄람어, 마라티어, 말레이어(라틴어), 네덜란드어, 노르웨이어, 오리야어, 펀자브어, 폴란드어, 포르투갈어, 루마니아어, 러시아어, 슬로바키아어 , 슬로베니아어, 알바니아어, 세르비아어(키릴 자모), 스웨덴어, 타밀어, 텔루구어, 태국어, 타갈로그어, 터키어, 우크라이나어, 우르두어, 베트남어, 요루바어, 중국어
IETF BCP 47 스크립트 이름 태그가 포함된 ISO 639-1 코드 입니다. outputFormat: 'ISO639_1_BCP47'
am, ar, az-Latn, be, bg, bn, ca, cs, da, de, el, en, es, et, eu, fa, fi, fr, gu, he, hi, hr, hu, hy, is, it, ja, ka, kn, ko, ku-Arab, lo, lt, lv, ml, mr, ms-Latn, nl, no, 또는, pa, pl, pt, ro, ru, sk, sl, sq, sr-Cyrl, sv, ta, te, th, tl, tr, uk, ur, vi, yo, zh
ISO 639-2/T 코드(유효한 639-3 ) outputFormat: 'ISO639_2T' . BCP 47 ISO639_2T_BCP47 에서도 사용 가능
amh, ara, aze, bel, bul, ben, cat, ces, dan, deu, ell, eng, spa, est, eus, fas, fin, fra, guj, heb, hin, hrv, hun, hye, isl, ita, jpn, kat, kan, kor, kur, lao, lit, lav, mal, mar, msa, nld, nor, ori, pan, pol, por, ron, rus, slk, slv, sqi, srp, swe, 탐, 전화, 그쪽으로, tgl, tur, ukr, urd, vie, yor, zho
오픈 소스 개선을 위해 기부하거나, 개인 수정을 위해 나를 고용하거나, 대체 데이터 세트 교육을 요청하거나, 저에게 연락하려면 다음 링크를 사용하십시오: https://linktr.ee/nitotm