논문: 비전 언어 모델의 테스트 시간 제로 샷 일반화: 실제로 즉각적인 학습이 필요한가요? .
저자: Maxime Zanella, Ismail Ben Ayed.
이것은 CVPR '24에서 승인된 우리 논문의 공식 GitHub 저장소입니다. 이 연구에서는 즉각적인 학습이 필요 없이 Vision-Language 모델을 활용하는 MeanShift Test-time Augmentation(MTA) 방법을 소개합니다. 우리의 방법은 단일 이미지를 N개의 확대된 뷰로 무작위로 확대한 다음 두 가지 주요 단계를 번갈아 가며 수행합니다(코드 섹션의 mta.py 및 세부 정보 참조).
이 단계에는 관련성과 품질(인라이어니스 점수)을 평가하기 위해 각 증강 뷰에 대한 점수를 계산하는 작업이 포함됩니다.
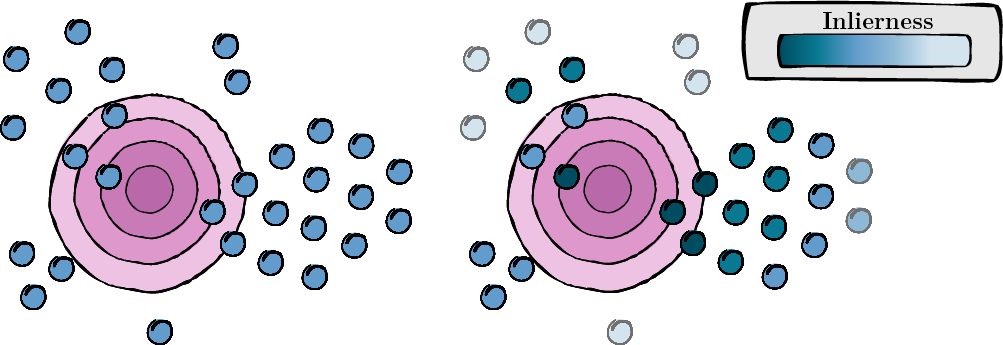
그림 1: 각 증강 보기에 대한 점수 계산.
이전 단계에서 계산된 점수를 기반으로 데이터 포인트의 모드(MeanShift)를 찾습니다.
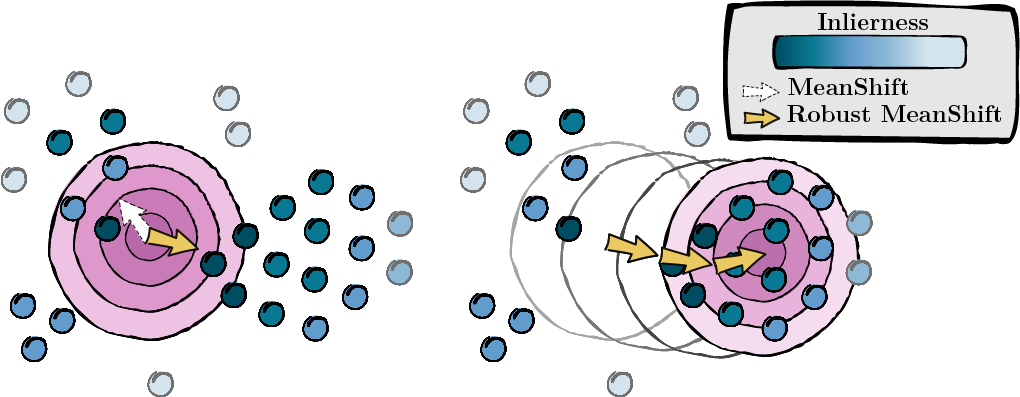
그림 2: inlierness 점수에 따라 가중치가 부여된 모드 탐색.
우리는 TPT 설치 및 전처리를 따릅니다. 이렇게 하면 데이터세트의 형식이 적절하게 지정됩니다. 여기에서 해당 저장소를 찾을 수 있습니다. 더 편리하다면 data/datautils.py(20행)의 ID_to_DIRNAME 사전에서 각 데이터세트의 폴더 이름을 변경할 수 있습니다.
다음 명령을 입력하여 임의 시드 1과 'a photo of a' 프롬프트를 사용하여 ImageNet 데이터세트에서 MTA를 실행합니다.
python main.py --data /path/to/your/data --mta --testsets I --seed 1또는 한 번에 15개의 데이터세트를 실행합니다.
python main.py --data /path/to/your/data --mta --testsets I/A/R/V/K/DTD/Flower102/Food101/Cars/SUN397/Aircraft/Pets/Caltech101/UCF101/eurosat --seed 1절차에 대한 자세한 내용은 mta.py를 참조하세요.
gaussian_kernelsolve_mtay )의 초기값을 균일하게 설정합니다.이 프로젝트가 유용하다고 생각되면 다음과 같이 인용해 주세요.
@inproceedings { zanella2024test ,
title = { On the test-time zero-shot generalization of vision-language models: Do we really need prompt learning? } ,
author = { Zanella, Maxime and Ben Ayed, Ismail } ,
booktitle = { Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition } ,
pages = { 23783--23793 } ,
year = { 2024 }
}우리는 오픈 소스 기여에 대해 TPT 작성자에게 감사를 표합니다. 여기에서 해당 저장소를 찾을 수 있습니다.


